
shell高级用法,mkfifo管道,创建管道,多任务多并发
转自:https://www.cnblogs.com/bulh/articles/12765789.html
转自:https://blog.csdn.net/qq_34409701/article/details/52488964
转自:https://zhuanlan.zhihu.com/p/623276458 最能解释管道
Linux mkfifo命令
mkfifo命令基本上可以让你创建FIFO(又名命名管道)。 以下是该命令的语法:
mkfifo [OPTION]... NAME...
什么是命名管道?
要理解这一点,你应该首先意识到基本管道的概念。 你会看到包含竖线(|)的命令。 这个栏被称为管道。 它所做的是创建两个进程之间的通信通道(执行完整命令时)。
例如:
ls | grep .txt
上面提到的命令由两个程序组成: ls和grep 。 这两个程序都由管道( | )分开。 所以这里的管道是什么,它创建了这些程序之间的通信通道 - 当执行上述命令时,ls的输出将作为输入提供给grep。 最后,在终端上显示的输出只包含那些在其中包含'.txt'字符串的条目。
现在有了命名管道的概念。 正如名字本身所暗示的那样,这些名字就是管道。 您可以使用mkfifo命令创建一个命名管道。 例如:
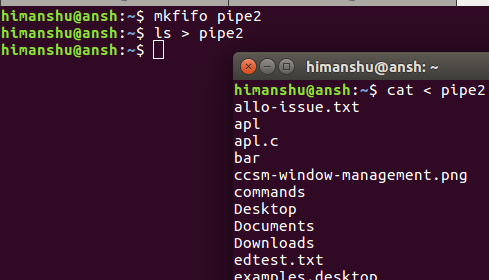
mkfifo pipe2
所以'pipe2'现在是一个命名管道。 现在问题是如何命名管道更有用? 那么,考虑一下在终端中运行进程并生成输出的情况,并且您想要的是将该输出信道化到不同的终端。 所以在这里,一个命名管道可以有很大的帮助。
例如,假设ls是在第一个终端中运行的进程,并且您希望在不同的终端中查看它的输出结果,那么您可以执行以下操作:
ls > pipe2
以下是您可以在第二个终端中执行的操作:
cat < pipe2

# 创建有名管道 mkfifo mypipe # 查看管道文件的类型:p 表示管道 ls -l mypipe # 在一个进程中向管道中写入数据 echo "hello, world" > mypipe # 在另一个进程中从管道中读取数据 cat < mypipe # 删除管道文件 rm mypipe
上述代码中,首先使用 mkfifo 命令创建了一个名为 mypipe 的有名管道文件。可以通过 ls -l 命令来查看管道文件的类型,其类型为 p,表示为管道。然后在一个进程中使用 echo 命令向管道中写入了字符串 "hello, world",而在另一个进程中使用 cat 命令从管道中读取了这个字符串。最后,使用 rm 命令删除了管道文件。
需要注意的是,有名管道在使用完毕后需要主动删除,否则会一直存在于文件系统中,占用空间。也可以使用 mkfifo 命令的 -m 选项来设置管道的权限,以保护管道不被非授权访问或修改。
理解:管道就是将数据写入到一个文件中,由另一个程序来读取,管道可以先建立,往内部写文件,另一个程序,直接调用读取,会自动输出内容,并且删除管道内的缓存,利用生产者消费者,生产了然后被消费了,就为空了。
如何识别命名管道?
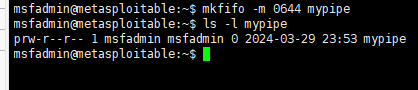
命名管道可以像文件一样正常访问。 这意味着你可以使用ls命令来访问它们。 如果您看到命名管道的访问权限,您会在开始时看到“p”。 这表示相关文件是命名管道。 这是一个例子:

如何设置自定义访问权限?
正如您在前面的问答中所看到的那样,命名管道的默认访问权限分别为'rw','rw'和'r'(分别针对用户,组和其他人)。 但是,如果您愿意,也可以设置自定义权限,您可以使用-m选项执行某些操作。
例如:
mkfifo pipe3 -m 0644
以下屏幕截图确认设置了自定义权限:
要了解更多有关mkfifo的信息,可以使用--halp和--version选项。
并发与多线程
默认的情况下,Shell脚本中的命令是串行执行的,必须等到前一条命令执行完后才执行接下来的命令,但是如果我有一大批的的命令需要执行,而且互相又没有影响的情况下(有影响的话就比较复杂了),那么就要使用命令的并发执行了。
如下:
#!/bin/bash IPLIST=/home/meta/ipinfo/iplist for i in $(cat ${IPLIST} |grep -viE "^#|备机|ts"|awk '{print $1}') do ssh $i "cd ~/update/;tar zxf patch-20160909.tgz -C ~/LMDG/ && echo '/$i ok' || echo '/$i bad'" done >> result.txt echo "resutl"|mutt -a result.txt -s update-result meta@126.com
对于上面的代码,因为 iplist 中有好多ip,每个”tar zxf”都挺耗时的,所以打算使用并发编程,这样就可以节省大量时间了。
修改如下:
#!/bin/bash IPLIST=/home/meta/ipinfo/iplist for i in $(cat ${IPLIST} |grep -viE "^#|备机|ts"|awk '{print $1}') do ssh $i "cd ~/update/;tar zxf patch-20160909.tgz -C ~/LMDG/ && echo '/$i ok' || echo '/$i bad'" & done >> result.txt echo "resutl"|mutt -a result.txt -s update-result meta@126.com
加上“&” 之后 “tar zxf”就可以并行执行了。 实质是将”tar zxf” 作为后台进程在执行,这样该命令就不会占用当前bash,其他命令也不用等待前面命令执行完再继续了,而且可以放入多个任务到后台,这样就实现了多任务并发。
我本来目的是让”tar zxf”这个循环都执行结束后,再“mutt”前面的结果。如果像上面这样写的话,在”tar zxf”都还没结束时就已经开始执行“mutt”了,得到了错误的结果,因此需要做如下修改:
#!/bin/bash IPLIST=/home/meta/ipinfo/iplist for i in $(cat ${IPLIST} |grep -viE "^#|备机|ts"|awk '{print $1}') do ssh $i "cd ~/update/;tar zxf patch-20160909.tgz -C ~/LMDG/ && echo '/$i ok' || echo '/$i bad'" & done >> result.txt wait echo "resutl"|mutt -a result.txt -s update-result meta@126.com
这里添加了“wait” 之后就可以达到我们预期的效果了,wait的作用就是等待子任务都执行完之后在结束父任务,继而执行下面的任务。
但是,紧接着又有问题了,如果这个iplist中的量巨大,这样一口气都放到后台,系统超出负载后,会有性能变差或者宕机风险,因此我们需要一个控制并发数的机制。
因此我们引入了任务队列的概念,有点类似之前socket举例中的消费者生产者模型,通过消息队列来调节供需的不平衡
修改如下:
#!/bin/bash IPLIST=/home/meta/ipinfo/iplist #任务(消费者) THREAD=50 #声明并发线程并发个数,这个是此应用的关键,也就是设置管道的最大任务数 TMPFIFO=/tmp/$$.fifo #声明管道名称,'$$'表示脚本当前运行的进程PID mkfifo $TMPFIFO #创建管道 exec 5<>${TMPFIFO} #创建文件标示符“5”,这个数字可以为除“0”、“1”、“2”之外的所有未声明过的字符,以读写模式操作管道文件;系统调用exec是以新的进程去代替原来的进程,但进程的PID保持不变,换句话说就是在调用进程内部执行一个可执行文件 rm -rf ${TMPFIFO} #清除创建的管道文件 #为并发线程创建同样个数的占位 for((i=1;i<=$THREAD;i++)) do echo ; #借用read命令一次读取一行的特性,使用一个echo默认输出一个换行符,来确保每一行只有一个线程占位;这里让人联想到生产者&消费者模型,管道文件充当消息队列,来记录消费者的需求,然后由生产者去领任务,并完成任务,这里运用了异步解耦的思想。 done >&5 #将占位信息写入管道 for i in $(cat ${IPLIST} |grep -viE "^#|备机|ts"|awk '{print $1}') #从任务队列中依次读取任务 do read -u5 #从文件描述符管道中,获取一个管道的线程占位然后开始执行操作;read中 -u 后面跟fd,表示从文件描述符中读入,该文件描述符可以是exec新开启的。 { echo $(cat ~/ipinfo/iplist|grep $i|awk '{print $2}'); ssh -oConnectTimeout=10 -oConnectionAttempts=3 $i "cd /home/Log/;grep 'MIL' mission_2016-08-03*.log |awk -F, '{if(\$19==1370) print \$0}'| awk -F, '{if(\$20==0) print \$0}'>miss_info.txt" echo "" >&5 #任务执行完后在fd5中写入一个占位符,以保证这个线程执行完后,线程继续保持占位,继而维持管道中永远是50个线程数,&表示该部分命令/任务放入后台不占当前的bash,实现并行处理 } & done wait #等待父进程的子进程都执行结束后再结束父进程 exec 5>&- #关闭fd5的管道 exit 0



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?