


python——爬取中国研究生信息网调剂信息
代码如下:
from DrawStu.DrawStu import DrawStu; import time; import io import sys sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #初始化class 得到对象 draw=DrawStu(); if __name__ == '__main__': print('爬取研究生调剂信息'); size=draw.get_page_size(); print(size) for x in range(size): start=x*50; print(start); #print(); created_url='https://yz.chsi.com.cn/kyzx/tjxx/?start='+str(start); draw.draw_base_list(created_url); pass
import sqlite3; class DB(object): """数据库访问方法的实现""" """初始化api 产生数据操作的对象 conect 操作的游标""" def __init__(self): self.conn={}; self.cus={}; #初始化数据库链接的api #1产生数据库链接对象 self.conn=sqlite3.connect(r'Test.db'); #2.产生操作的游标 self.cus=self.conn.cursor(); pass; def create_table(self): sql = " CREATE TABLE if not exists mynews (CrawlTime char,Title char,Content char,PublishTime char,Origin char)" self.conn.execute(sql) self.conn.commit() print('create table successfully') def insert_into_news(self,ops): self.conn.execute('insert into mynews(CrawlTime,Title,Content,PublishTime,Origin) values(?,?,?,?,?)',(ops['CrawlTime'],ops['Title'],ops['Content'],ops['PublishTime'],ops['Origin'],)); self.conn.commit(); pass
#要求使用urllib3 import urllib.request; from bs4 import BeautifulSoup; from DB.DB import DB; db=DB(); import time; """爬取核心的核心模块,功能只负责爬取研究生调剂信息""" class DrawStu(): """docstring for DrawStu""" def __init__(self): self.baseurl='https://yz.chsi.com.cn/kyzx/tjxx/'; db.create_table(); pass; #提取公共的爬取信息的api def commonsdk(self,url): response=urllib.request.urlopen(url);#注意 写在内部以后 变成了形参 html=response.read();#read进行乱码处理 print(html); doc=BeautifulSoup(html); return doc; #爬取基本列表 def draw_base_list(self,url): print('url is:::',url); doc=self.commonsdk(url); lilist=doc.find('ul',{'class':'news-list'}).findAll('li'); #print(lilist); #爬取一级参数 for x in lilist: Title=x.find('a').text; Time=x.find('span').text Link='https://yz.chsi.com.cn'+x.find('a').get('href'); #print(Link); self.draw_detail_list(Link,Title,Time); pass pass #爬取二级详情的信息参数 def draw_detail_list(self,url,Title,Time): doc=self.commonsdk(url); from_info=doc.find('span',{'class':'news-from'}).text; content=doc.find('div',{'class':'content-l detail'}).text; ctime=time.strftime('%Y-%m-%d %H:%M:%S',time.localtime()); #将数据 拼合成字典 交给数据库存储的api data={ 'CrawlTime':ctime, 'Title':Title, 'Content':content, 'PublishTime':Time, 'Origin':from_info } print(data); print('插入数据库中'); db.insert_into_news(data); pass #爬取页面的总页数 def get_page_size(self): requesturl=self.baseurl; pcxt=self.commonsdk(requesturl).find('div',{'class':'pageC'}).findAll('span')[0].text; print(pcxt); #re正则表达式 字符串截取api pagesize=pcxt.strip(); pagearr=pagesize.split('/'); pagestr=pagearr[1]; return int(pagestr[0:2]); pass
F12查看网页元素
爬取结果:
转化成数据库表格形式,采用database net软件,效果如下:
新建查询输入:select *from mynews
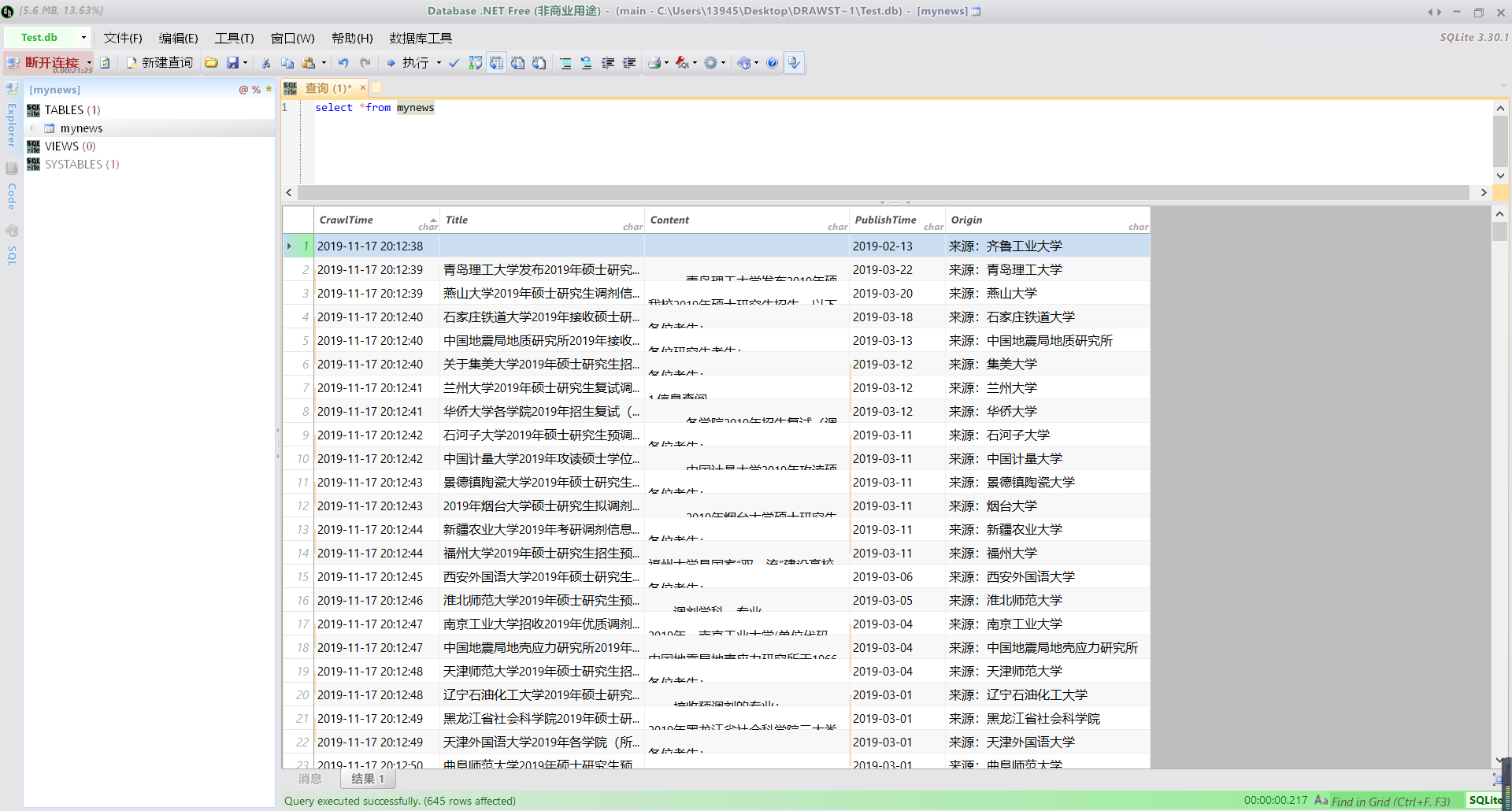
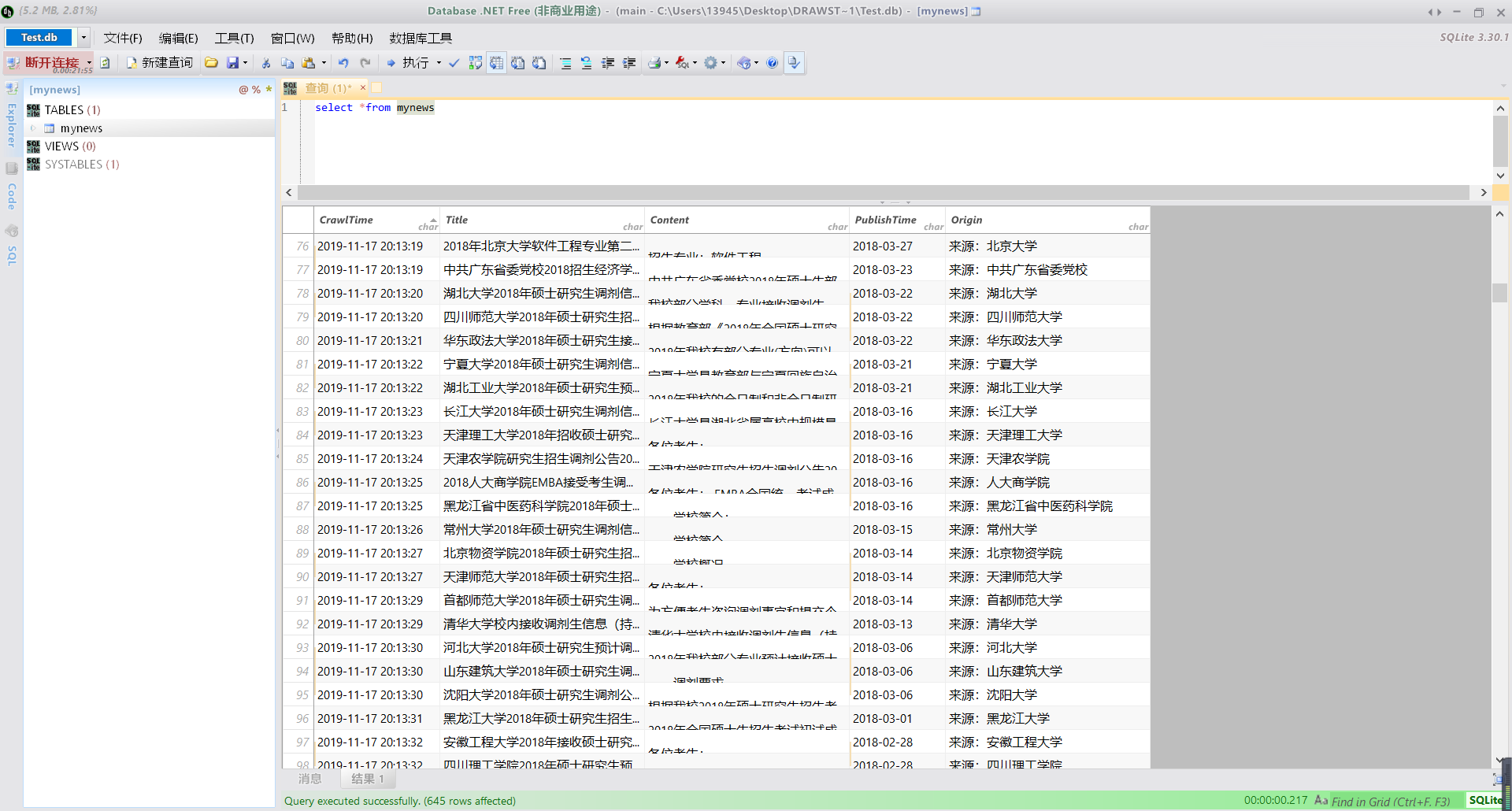
其中在录每一个学校的信息都能查询
