

python——爬取游戏排名信息
爬取游戏排名前100的游戏,代码如下:
import requests import bs4 from bs4 import BeautifulSoup import re def main(): a = [] #定义空列表 url = "http://top.baidu.com/buzz?b=62" html = getHTMLText(url) collectlist(a,html) printlist(a,50) def getHTMLText(url): try: #伪装浏览器 headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} r = requests.get(url,headers = headers,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "error" def collectlist(plist,html): soup = BeautifulSoup(html,'html.parser') #找到<table>下的所有<tr>,返回的是列表 s = soup.find('table').find_all('tr') for i in s: if i.find('td',class_='first') != None: #需要找到符合条件的<td>,再进行操作 con = i.find('td',class_='first').text #排名 con1 = re.search(r'\d+',con) #text类型需要正则匹配,返回的是列表,每一次只有一个元素 con2 = i.find('td',class_="keyword").find('a',class_="list-title").string #游戏名,string类型则可以直接append到数组中 con3 = i.find('td',class_="last").find('span').string #指数 plist.append([con1[0],con2,con3]) #返回元素 def printlist(plist,num): tplt = "{0:^10}\t{1:{3}^10}\t{2:^20}" #游戏名称为纯文字情况 tplt1 = "{0:^10}\t{1:^20}\t{2:^20}" #游戏名称出现字母情况 tplt2 = "{0:^10}\t{1:{3}^10}\t{2:{3}^10}" #第一栏主题项 print(tplt2.format("排名","游戏名称","搜索指数",chr(12288))) for i in range(num): p = plist[i] if re.match(r'[a-z]',p[1]) == None: #正则匹配p[1]纯文字情况 print(tplt.format(p[0],p[1],p[2],chr(12288))) else: print(tplt1.format(p[0],p[1],p[2],chr(12288))) main()
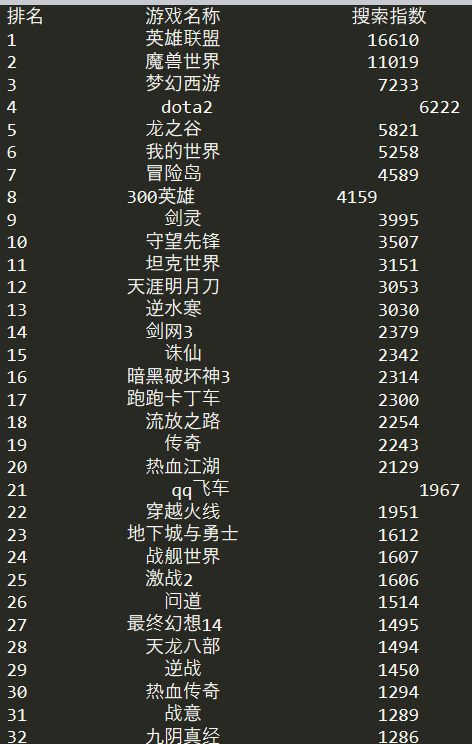
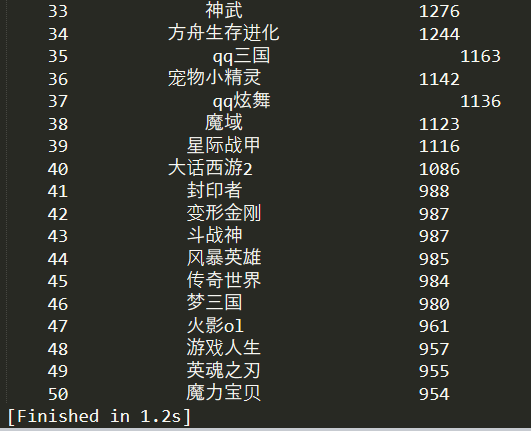
总结下小问题:
1、find()和find_all()的区别
find()返回对象的第一个元素
find_all()返回所有元素
2、.text形式可以返回多层标签中的文本,.string则只能返回当层标签中下的文本。但是使用.text时需要注意如果不是当层标签下的文本,其返回的类型为数组类型,还需提取其中的元素,即str[0],表示数组中第1个元素;而.string是当层标签下的文本,自然就是返回的是string。
3、f12查看网页元素组成
