
hadoop全分布式的搭建
步骤
1.修改 hadoop-env.sh
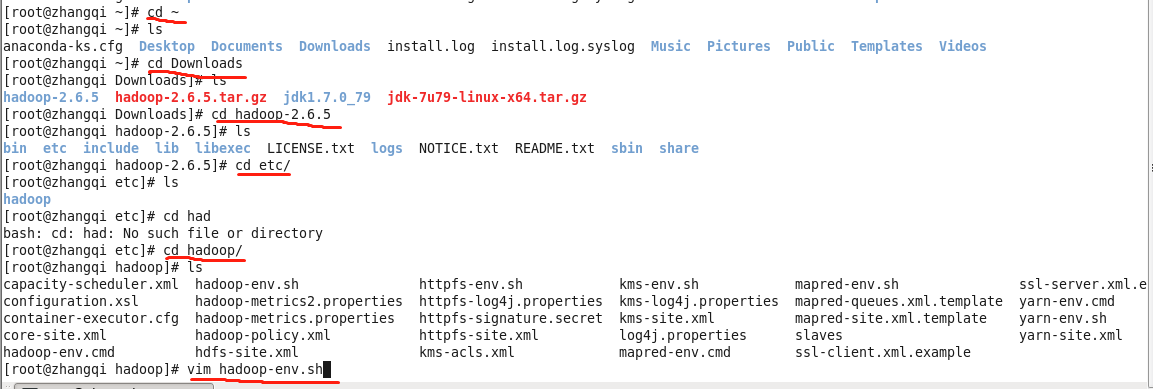

export JAVA_HOME=/root/Downloads/jdk1.7.0_79
export HADOOP_HOME=/root/Downloads/hadoop-2.6.5
2.修改core-site.xml

<property>
<name>fs.defaultFS</name>
<value>hdfs://zhangqi:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmpdir</value>
</property>
3.修改 hdfs-site.xml


<!--#放置的是namenode中的fsimage-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/tmpdir/name</value>
</property>
<!--#namenode访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>zhangqi:50070</value>
</property>
<!--#namenode的edits日志文件地址-->
<property>
<name>dfs.namenode.edits.dir</name>
<value>/hadoop/tmpdir/nameedits</value>
</property>
<!--#snm的fsimage的地址-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/hadoop/tmpdir/secondary</value>
</property>
<!--#snm的edits日志文件地址-->
<property>
<name>dfs.namenode.edits.checkpoint.edits.dir</name>
<value>/hadoop/tmpdir/secondaryedits</value>
</property>
4.修改yarn-site.xml

<!--#rm启动地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>zhangqi</value>
</property>
<!--#是否需要shuffle 可以切换本地模式和集群模式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--#resourcemanager分配的端口地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>zhangqi:8032</value>
</property>
<!--#RPC的地址,并且用于分配资源的端口-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>zhangqi:8030</value>
</property>
<!--#对nodemanager暴漏的地址(资源追踪器)心跳机制端口-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>zhangqi:8031</value>
</property>
<!--#resourcemanager的admin模块的通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>zhangqi:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<!--web服务器的端口 -->
<value>zhangqi:8088</value>
</property>
5.修改mapred-site.xml
5.1 注意* 要修改 mapred-site.xml.template 文件的名字为 mapred-site.xml

5.2


<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<!--#启动历史服务器-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>zhangqi:10020</value>
</property>
<!--#历史服务器web访问地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>zhangqi:19888</value>
</property>
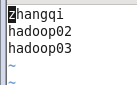
6.修改slaves(主从节点配置)

7.分发

scp -r hadoop/ root@hadoop02:/root/Downloads/hadoop-2.6.5/etc
分发成功

8.先格式化集群
目的:创建镜像文件,日志文件
hdfs namenode -format
9.配置免密
9.1生成秘钥:ssh-keygen -t rsa
9.2转发秘钥:ssh-copy-id hadoop02
9.3删除秘钥 :rm -rf .ssh


10.启动机器
10.1启动全部的线程start-all.sh
10.2启动dfs的线程 (hdfs,yarn) start-dfs.sh
10.3启动yarn线程 start-yarn.sh
10.4查看运行的线程 jps
11.在windows上查看启动的进程
11.1主机名:50070
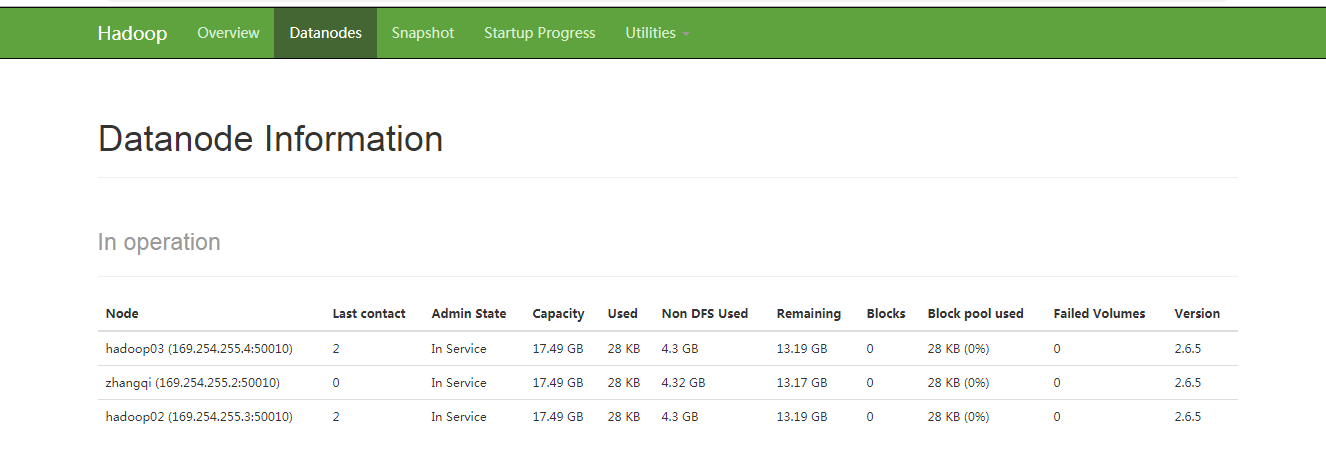
主机名:8088
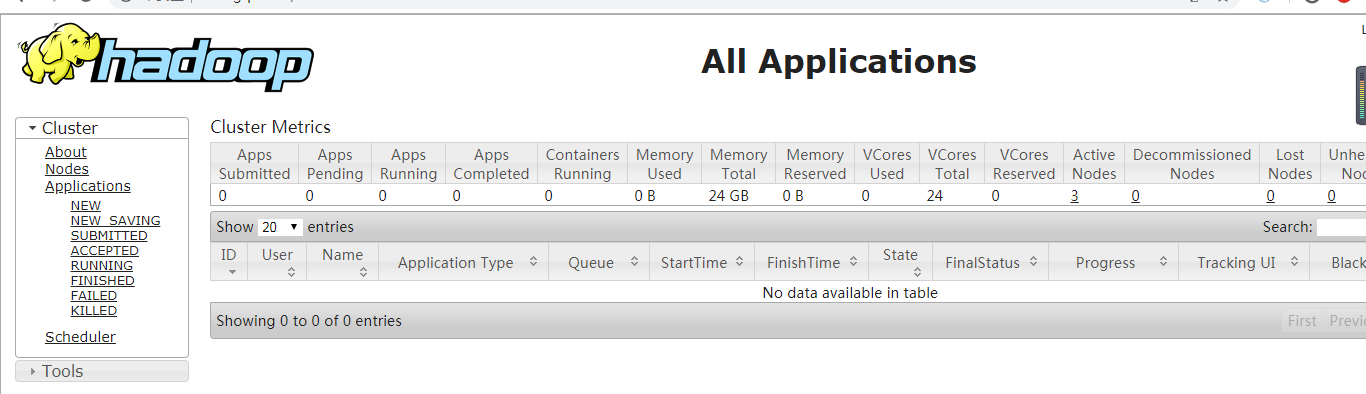
11.2在windows上配置访问linux系统
C:\Windows\System32\drivers\etc-hosts


 浙公网安备 33010602011771号
浙公网安备 33010602011771号