

kafka单机版的安装、集群部署 及使用
1.安装kafka(单机版)
1.1上传 kafka_2.11-2.0.0.tgz 到 /root/Downloads
1.2解压 tar 包
tar -zxvf kafka_2.11-2.0.0.tgz
解压后:kafka_2.11-2.0.0
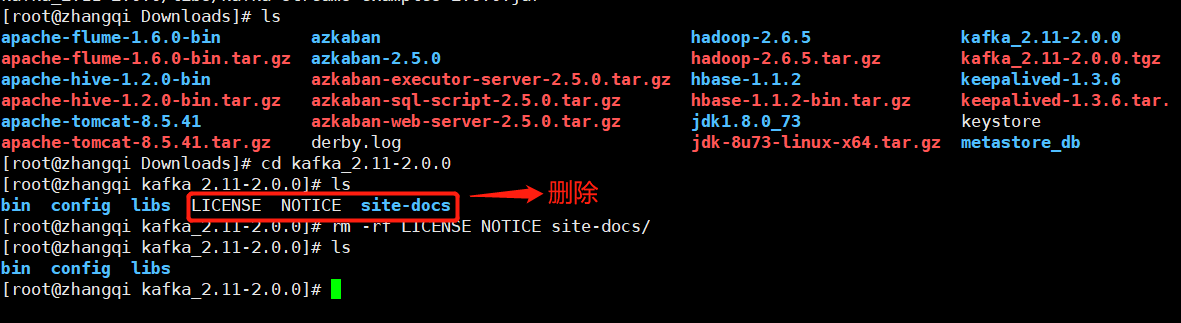
1.3删除 LICENSE、NOTICE 、site-docs
rm -rf LICENSE NOTICE site-docs
1.4
1.4.1启动kafka单机版的命令(在启动kafka之前先启动zookeeper)

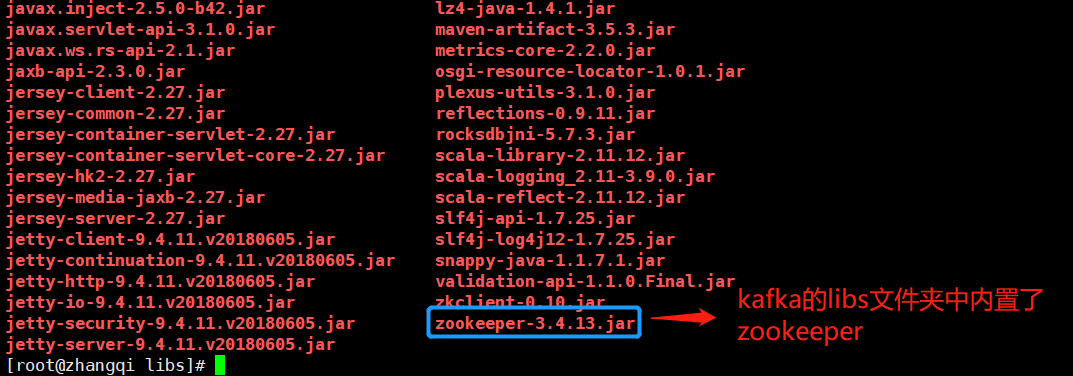
kafka的libs文件夹中内置了zookeeper
1.4.2 在kafka的bin目录下启动
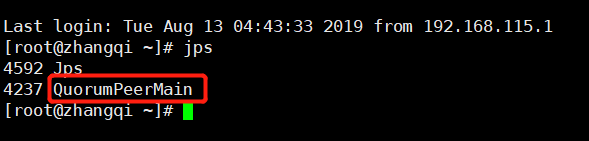
./zookeeper-server-start.sh ../config/zookeeper.properties
在启动该命令之后,可以在该虚拟机上查看进程
1.4.3接下来,在bin目录下启动kafka
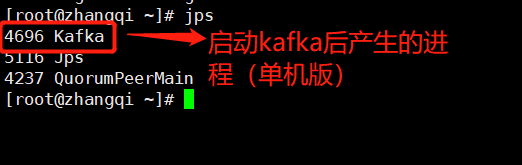
./kafka-server-start.sh ../config/server.properties
再次查看进程
1.5 开始使用kafka
1.5.1 topic是用来放消息的,也可以做消息分类
创建topic,在bin目录下
./kafka-topics.sh --create --zookeeper zhangqi:2181 --replication-factor 1 --partitions 1 --topic test
1.5.2 查看topic
./kafka-topics.sh --list --zookeeper zhangqi:2181
1.5.3 启动生产者
./kafka-console-producer.sh --broker-list zhangqi:9092 --topic test
启动消费者
./kafka-console-consumer.sh --bootstrap-server zhangqi:9092 --topic test
生产者的作用:往topic里生产数据。生产者可以是java客户端、flume等
消费者的作用:消费topic里的数据。消费者可以是java客户端、spark streaming等
什么叫broker(代理)?安装了kafka服务的机器


1.5.4 消费者可以接收,生成者生成的数据
消费者可以接收,生成者生成的数据,如果不指定 --from-beginning 那么消费者消费的是最新的数据。指定了之后也可以消费以前的数据
1.5.5 消费者,可以消费之前产生的数据
./kafka-console-consumer.sh --bootstrap-server zhangqi:9092 --topic test --from-beginning

2.kafka集群部署
分别往192.168.115.11、192.168.115.12、192.168.115.13这三台虚拟机上安装kafka
2.1 将安装好的一台分别拷贝到其余2台
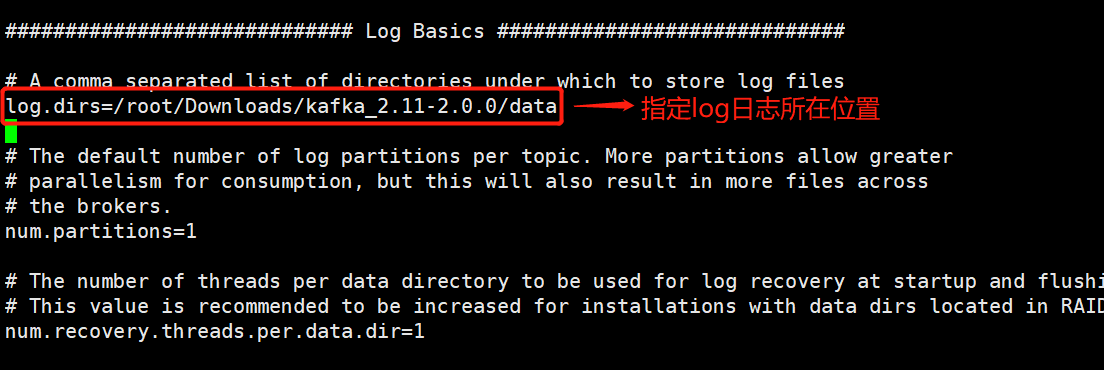
2.2 修改 /root/Downloads/kafka_2.11-2.0.0/config/server.properties文件里的broker.id

修改kafka运行日志存放的路径
配置连接zookeeper集群地址
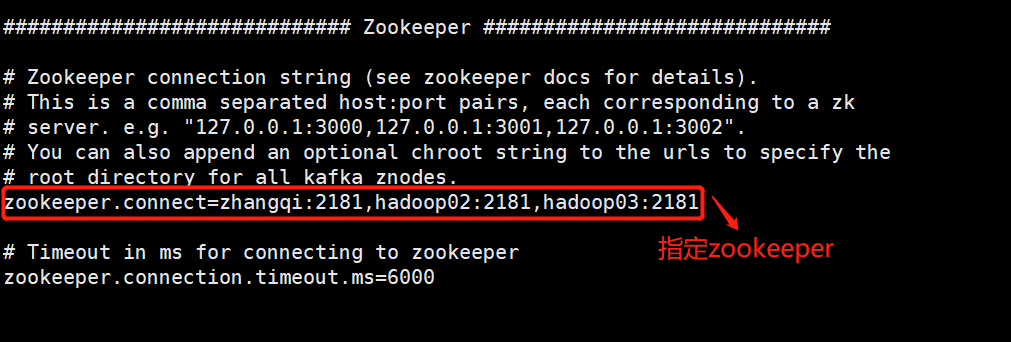
2.3集群配置成功

