剑指offer_35_复杂链表的复制
复杂链表的复制
题目链接:https://leetcode-cn.com/problems/fu-za-lian-biao-de-fu-zhi-lcof/
题目内容:请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个结点除了有一个 next指针指向下一个结点,还有一个 random 指针指向链表中的任意结点或者 null。
示例 1:

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
示例 4:
输入:head = []
输出:[]
解释:给定的链表为空(空指针),因此返回 null。
提示:
-10000 <= Node.val <= 10000Node.random为空(null)或指向链表中的结点。- 结点数目不超过 1000 。
题目解析
题目解析内容来自于题解中 腐烂的橘子🍊
题目的意思是要复制一个链表并返回,这里的复制指的是深拷贝(Deep Copy), 区别于浅拷贝。
浅拷贝只是复制某个对象的指针,在python中只是复制这个对象的引用,而不是对象本身,新旧对象用的是同一块内存;深拷贝是从新获取一块内存,从头到尾的复制对象。新对象与原对象不共用内存。修改新对象不会影响到原对象。
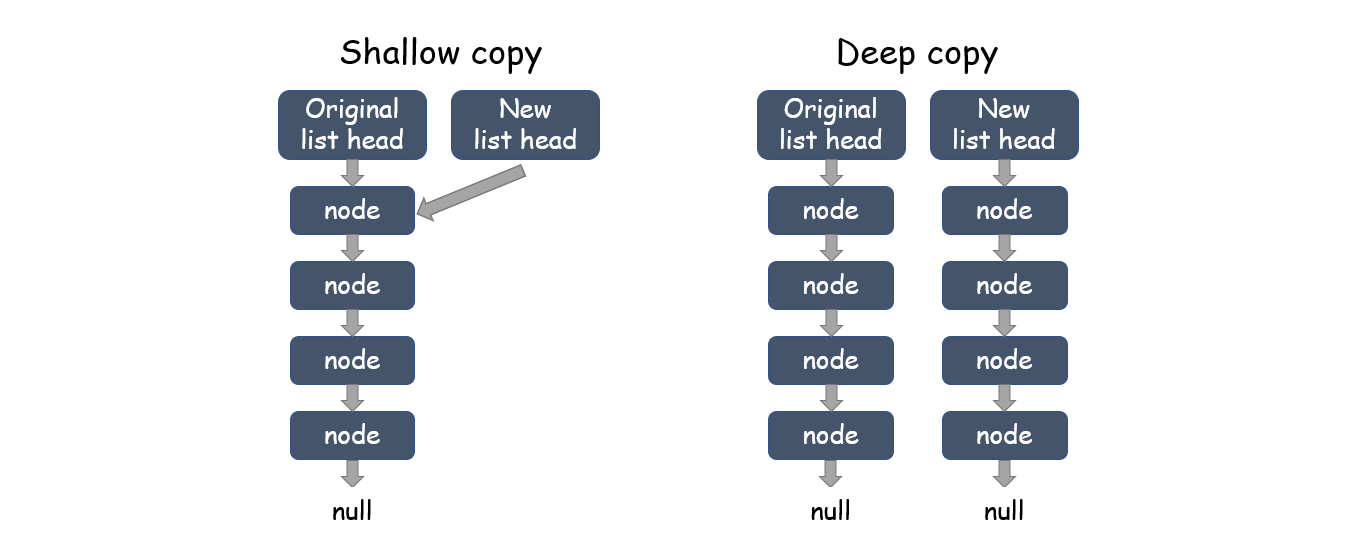
方法一:一行python(面试不要写这个)
根据解析,可直接调用 python 自带的相关函数
class Solution:
def copyRandomList(self, head: 'Node') -> 'Node':
return copy.deepcopy(head) # 需要 import copy
方法二:DFS & BFS
图的基本单元是顶点,顶点之间的关联关系称之为边,我们可以将此链表看成一个图:
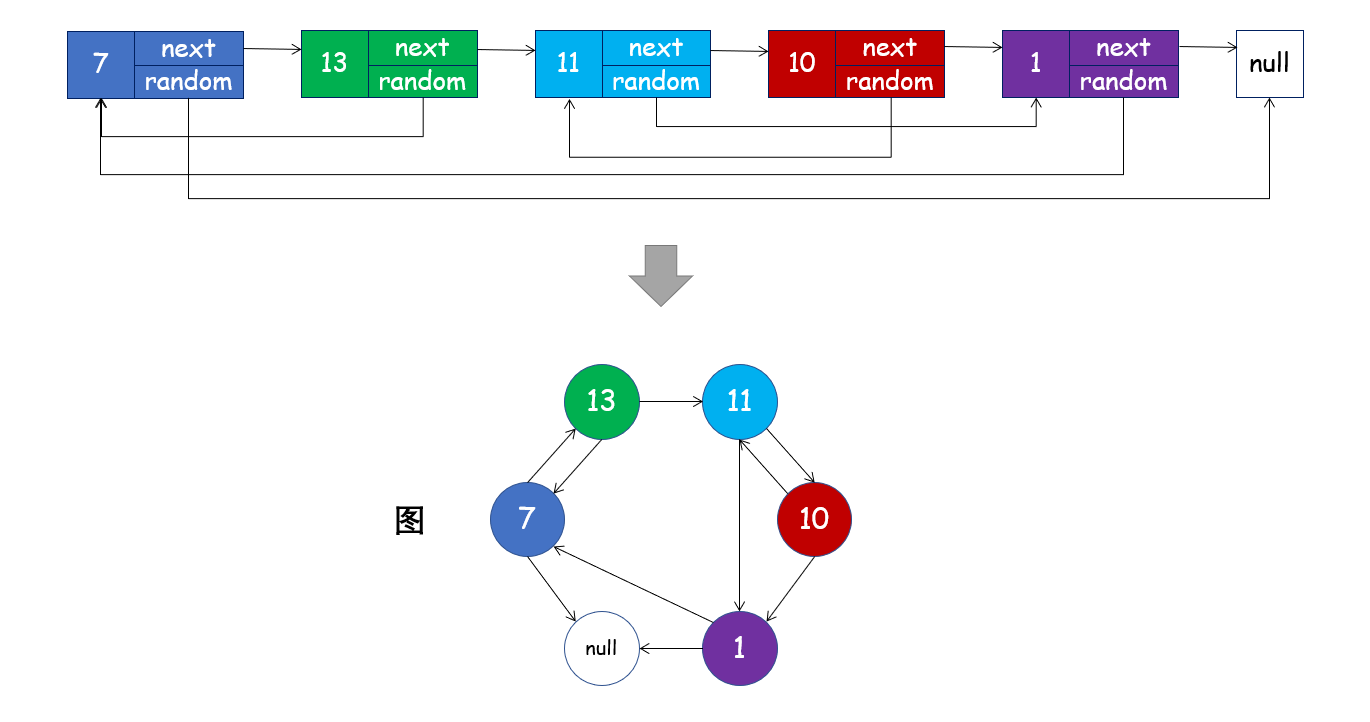
由于图的遍历方式有深度优先搜索和广度优先搜索,同样地,对于此链表也可以使用深度优先搜索和广度优先搜索两种方法进行遍历。
算法:深度优先搜索
-
从头结点
head开始拷贝; -
由于一个结点可能被多个指针指到,因此如果该结点已被拷贝,则不需要重复拷贝;
-
如果还没拷贝该结点,则创建一个新的结点进行拷贝,并将拷贝过的结点保存在哈希表中;
-
使用递归拷贝所有的
next结点,再递归拷贝所有的random结点。
代码
class Solution:
def copyRandomList(self, head: 'Node') -> 'Node':
def dfs(head):
if not head:
return None
if head in visited:
return visited[head]
# 创建一个新的结点
new = Node(head.val, None, None)
visited[head] = new
new.next = dfs(head.next)
new.random = dfs(head.random)
return new
visited = {}
return dfs(head)
复杂度分析
- 时间复杂度:O(N)
- 空间复杂度:O(N)
算法:广度优先搜索
-
创建哈希表保存已拷贝结点,格式
{原结点:拷贝结点} -
创建队列,并将头结点入队
-
当队列不为空时,弹出一个结点,如果该结点的
next结点未被拷贝过,则拷贝next结点并加入队列;同理,如果该结点的random结点未被拷贝过,则拷贝random结点并加入队列;
class Solution:
def copyRandomList(self, head: 'Node') -> 'Node':
visited = {}
def bfs(head):
if not head:
return head
new = Node(head.val, None, None) # 创建新结点
queue = collections.deque()
queue.append(head)
visited[head] = clone
while queue:
tmp = queue.pop()
if tmp.next and tmp.next not in visited:
visited[tmp.next] = Node(tmp.next.val, [], [])
queue.append(tmp.next)
if tmp.random and tmp.random not in visited:
visited[tmp.random] = Node(tmp.random.val, [], [])
queue.append(tmp.random)
visited[tmp].next = visited.get(tmp.next)
visited[tmp].random = visited.get(tmp.random)
return new
return bfs(head)
复杂度分析
- 时间复杂度:O(N)
- 空间复杂度:O(N)
方法三:迭代
对于一个结点,分别拷贝此结点、next指针指向的结点、random 指针指向的结点, 然后进行下一个结点...如果遇到已经出现的结点,那么我们不用拷贝该结点,只需将 next 或random 指针指向该结点即可。
代码
class Solution:
def copyRandomList(self, head: 'Node') -> 'Node':
visited = {}
def getClonedNode(node):
if node:
if node in visited:
return visited[node]
else:
visited[node] = Node(node.val,None,None)
return visited[node]
return None
if not head: return head
old_node = head
new_node = Node(old_node.val,None,None)
visited[old_node] = new_node
while old_node:
new_node.random = getClonedNode(old_node.random)
new_node.next = getClonedNode(old_node.next)
old_node = old_node.next
new_node = new_node.next
return visited[head]
复杂度分析
- 时间复杂度:O(N)
- 空间复杂度:O(N)
方法四:优化的迭代
我们也可以不使用哈希表的额外空间来保存已经拷贝过的结点,而是将链表进行拓展,在每个链表结点的旁边拷贝,比如 A->B->C 变成 A->A'->B->B'->C->C',然后将拷贝的结点分离出来变成 A->B->C和A'->B'->C',最后返回 A'->B'->C'。
class Solution:
def copyRandomList(self, head: 'Node') -> 'Node':
if not head: return head
cur = head
while cur:
new_node = Node(cur.val,None,None) # 克隆新结点
new_node.next = cur.next
cur.next = new_node # 克隆新结点在cur 后面
cur = new_node.next # 移动到下一个要克隆的点
cur = head
while cur: # 链接random
cur.next.random = cur.random.next if cur.random else None
cur = cur.next.next
cur_old_list = head # 将两个链表分开
cur_new_list = head.next
new_head = head.next
while cur_old_list:
cur_old_list.next = cur_old_list.next.next
cur_new_list.next = cur_new_list.next.next if cur_new_list.next else None
cur_old_list = cur_old_list.next
cur_new_list = cur_new_list.next
return new_head
复杂度分析
- 时间复杂度:O(N)
- 空间复杂度:O(N)
总结
在对链表进行操作的时候,经常要记得把一个结点的指针域用另一个指针保存起来,这样返回的时候不容易出错。

