

FLume相关面试题
1.为什么要用Flume?
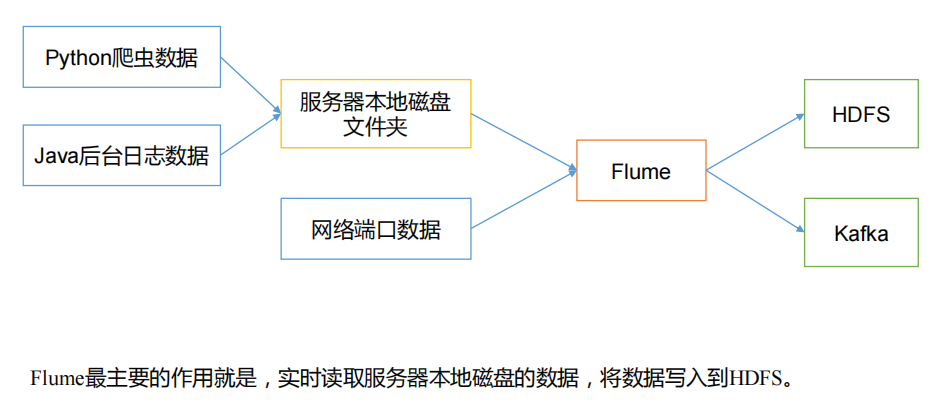
(1).高效的数据收集与聚合:
Flume能从多种来源(如Web服务器、消息队列、文件系统等)高效地收集数据,并将其发送到指定的目标位置。
它还能将来自不同源的数据进行聚合,便于后续的分析和处理。
(2).灵活的数据转换与传输:
Flume支持对收集到的数据进行转换和过滤,以满足特定的业务需求。
它能将处理后的数据传输到多种目标位置,如HDFS、HBase、Elasticsearch等,为数据的进一步利用提供了便利。
(3).减轻Hadoop集群压力:
Flume作为数据推送的中间层,能有效隔离生产应用程序与Hadoop集群,减轻集群的写入压力和网络负担。
通过Flume的分布式设计,可以平衡数据流量,避免高峰时段的数据拥堵和延迟。
(4).保证数据可靠性:
Flume提供了持久的Channel,确保数据在传输过程中不会丢失。
其灵活的配置和高度可定制性,使得Flume能够适应各种复杂的数据处理场景,保证数据的可靠性和完整性。
(5).支持实时数据处理:
Flume能够实时处理数据,与Kafka或Storm等流式处理引擎集成,实现实时数据分析,满足企业对数据时效性的需求。
2.Flume架构(Flume 有哪些组件,Flume 的 source、channel、sink 具体是做什么的?)

数据可能有各种来源,收集的方式不同,这是source 的主要工作,可以设置不同的收集方式:
1).采集某个文件的数据
2).指定接收某个端口的数据
3).采集文件的增加数据
常见的source如下:
1)Netcat tcp source:用来监听端口数据 (将流经端口的每一个文本行数据作为event输入)
2)Exec source: 监听单个追加文件 (用于从外部执行命令或脚本并收集输出的数据源组件,这个source在启动时运行给定的Unix命令,并期望该进程在标准输出上连续生成数据)
3)Spooling Directory Source:监听目录下新增文件 (监控指定目录内的新文件,但不适合实时监听追加内容的文件)
4)Taildir Source:监听目录下新增文件以及追加文件 (监控指定目录下新增文件和追加文件,支持断点续传)
5)Kafka source: 从Kafka的Topic中读取消息,并将其发送到Flume的Channel中
由于source收集和sink发送速度不均衡,容易造成拥堵,所以需要一个中转站暂时存放数据,就是channel。
File Channel:数据存储于磁盘,宕机数据可以保存,安全可靠。传输速率慢,适合对数据传输可靠性要求高的场景,例如:金融行业。
Memory Channel:数据存储于内存,速度快,宕机数据容易丢失。传输效率快,适合对数据传输可靠性要求不高的场景,例如:日志数据。
Kafka Channel:数据存储于 Kafka,传输速度最快,省去sink阶段,如果果下一级是 Kafka,优先选择。
数据可能要发送给不同的对象,发送的方式不同,这是sink的主要工作,可以设置不同的发送方式:
1).打印到控制台
2).指定服务器:端口进行发送
3).发送到hdfs集群
4).发送到kafka
3.Flume参数调优思路
(1) .source :
1)、增加Source个数。启动多个source 进行采集,可以增大Source读取数据的能力。例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个文件目录,同时配置好多个 Source以保证Source有足够的能力获取到新产生的数据。
2)、适当调大batchSize。因为batchSize决定了source 一次批量运输events到channel 的条数,可以提高Source搬运Event到Channel时的性能。
(2).channel:
1)、缓存方式type选择memory时Channel的性能最好,但是如果Flume进程意外挂掉可能会丢失数据。
2)、缓存方式type选择file时Channel的可靠性更好,但是性能上会比memory Channel差。使用file Channel时 dataDirs酊置多个不同盘下的目录(注意不是同一个盘不同目录哦)可以提高性能。
3)、capacity参数决定Channel可容纳最大的Event条数。参数transactionCapacity决定了每次source往channel写/sink从channel读的最大enents条数。注意:transactionCapacity要大于source和sink的batchsize。
(3).sink:
1)、增加Sink的个数可以增加Sink消费Event的能力。不过Sink也不是越多越好,过多的Sink会占用系统资源,造成系统资源不必要的浪费。
2)、适当调大batchSize,可以提高Sink从Channel搬出Event的性能。参数batchsize决定了sink一次批量从channel 读取的events条数。
4.Flume的数据会丢失吗?
根据Flume的事务机制,Flume的数据一般不会丢失,除非使用的时候memory channel 。
Source 到 Channel 是事务性的,Channel 到 Sink 是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是 Channel 采用 memoryChannel,agent 宕机导致数据丢失,或者 Channel 存储数据已满,导致 Source 不再写入,未写入的数据丢失。
Flume 不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由 Sink 发出,但是没有接收到响应,Sink 会再次发送数据,此时可能会导致数据的重复。
5.零点漂移问题,在Flume中如何解决?
(1).什么是零点漂移?
零点漂移指的是在Flume数据传输过程中,由于时间戳处理不当,导致数据被错误地归类到错误的时间段(如跨天)中,进而影响到数据分析和处理的准确性。具体来说,如果采集的数据是在某一天的23:59:59产生的,但由于传输延迟或其他原因,数据在零点之后才被抽取到服务器上,那么这些数据就可能会被错误地归类到第二天,从而产生零点漂移现象。
(2).原因分析
零点漂移的原因主要有以下几点:
1).时间戳处理不一致:
- 数据落地到磁盘文件时,会记录一个时间戳,这个时间戳通常是业务实际发生的时间。
- Flume从数据源(如Kafka)消费数据时,也会记录一个时间戳,这个时间戳是Flume消费数据的时间,可能与业务实际时间存在偏差。
2).Flume Event时间和业务时间不同步:
- Flume HDFS Sink默认基于Flume Event中的timestamp时间戳落盘。
- 如果Flume Event时间和业务时间跨天,就会产生数据漂移。
3).系统时间不同步:
- 如果Flume集群中的各个节点系统时间不同步,也会导致时间戳处理不一致,进而产生零点漂移。
(3).解决方法
为了解决Flume零点漂移问题,可以采取以下措施:
1). 使用自定义拦截器:
- 编写一个自定义的Flume拦截器(Interceptor),用于解析Event中的时间戳,并将其转换为业务实际时间。
- 在Flume配置文件中,将该拦截器添加到相应的source中。
以下是一个自定义拦截器的Java代码示例:
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public class TimestampInterceptor implements Interceptor {
@Override
public void initialize() {
// 初始化逻辑(可选)
}
@Override
public Event intercept(Event event) {
// 获取Event的body和header
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
Map<String, String> headers = event.getHeaders();
// 解析body中的时间戳字段(假设字段名为"ts")
JSONObject jsonObject = JSONObject.parseObject(log);
String ts = jsonObject.getString("ts");
// 将时间戳放入header的"timestamp"字段中
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
Iterator<Event> iterator = events.iterator();
while (iterator.hasNext()) {
Event event = iterator.next();
intercept(event);
}
return events;
}
@Override
public void close() {
// 关闭逻辑(可选)
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimestampInterceptor();
}
}
}
在Flume配置文件中,添加该拦截器的配置:
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.yourpackage.flume.interceptor.TimestampInterceptor$Builder
注意:上述代码中的com.yourpackage.flume.interceptor.TimestampInterceptor$Builder应替换为实际拦截器类的全限定名。
2). 确保系统时间同步:
- 使用NTP(Network Time Protocol)等时间同步服务,确保Flume集群中的各个节点系统时间保持同步。
3). 配置Flume Sink时使用事件时间:
- 在配置Flume Sink时,将
useLocalTimeStamp设置为false,确保数据写入时使用的是Event中的时间戳,而不是系统时间。
a1.sinks.k1.hdfs.useLocalTimeStamp = false
通过以上措施,可以有效解决Flume零点漂移问题,确保数据按照生成时间而非传输延迟进行分类,提高数据分析和处理的准确性。
6.Flume的事务机制(Flume的Put事务,Take事务?)
Flume使用两个独立事务put事务和take事务,分别负责从source —>channel 、channel —>sink,记录事件状态,保证两个过程的数据不会丢失。一旦事务中所有的事件全部传递到 Channel 且提交成功,那么 Soucrce 就将该文件标记为完成。
Source—>Channel是Put事务;
Channel—>Sink是Take事务;
从 Channel 到 Sink 的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。需要注意的是,Take事务可能导致数据重复。
如果发送过程中出现异常,回滚,将takeList中的全部event归还给Channel。这个操作可能导致数据重复,如果已经写入一半的event到了HDFS,但是回滚时会向channel归还整个takeList中的event,后续再次开启事务向HDFS写入这批event时候,就出现了数据重复。
(1).Channel使用被动存储机制,依靠Source完成数据写入(推送)、依Sink完成数据读取(拉取)。
Channel是Event队列,先进先出:Source->EventN,...,Event2,Event1 -> Sink
Sink是完全事务性的。
在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。
批量Event一旦成功写出到存储系统或下一个Agent,Sink就利用Channel提交事务。
事务一旦被提交,该Channel从自己的内部缓冲区删除Event。
(2).Flume 推送事务流程
doPut:将批数据先写入临时缓冲区putList,不是来一条Event就处理,是来一批Event才处理;
doCommit:检查Channel内存队列空间是否充足,充足则直接写入Channel内存队列;
doRollback:Channel内存队列空间不足则doRollback回滚数据到putList,等待重新传递,回滚数据指的是putList的Event索引回退到之前。
(3).Flume拉取事务流程
doTake:先将数据取到临时缓冲区takeList;
doCommit:如果数据全部发送成功,则清除临时缓冲区takeList;
doRolback:数据发送过程中如果出现异常,将临时缓冲区takeList中的数据doRolback归还给Channel内存队列,等待重新传递。
7.Flume 和 Kafka 采集日志区别,采集日志时中间停了,怎么记录之前的日志?
(1).Flume 采集日志是通过流的方式直接将日志收集到存储层,而 kafka 是将缓存在 kafka集群,待后期可以采集到存储层。
(2).Flume 采集中间停了,可以采用文件的方式记录之前的日志,而 kafka 是采用 offset 的方式记录之前的日志。
8.数据怎么采集到 Kafka,实现方式?
使用官方提供的 Flume Kafka 插件,插件的实现方式是自定义了 Flume 的 sink,将数据从channel 中取出,通过 kafka 的producer 写入到 kafka 中,可以自定义分区等。
9.如何实现Flume数据传输的实时监控(监控器)
使用第三方框架Ganglia实时监控Flume。
(1).采用Ganglia监控器,监控到Flume尝试提交的次数远远大于最终成功的次数,说明Flume运行比较差。主要是内存不够导致的。
(2).解决办法?
1)自身:Flume默认内存2000m。考虑增加Flume内存,在flume-env.sh配置文件中修改Flume内存为4-6g
-Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
2)找朋友:增加服务器台数
搞活动 618 —> 增加服务器 —> 用完在退出
日志服务器配置:8-16g内存、磁盘8T
10.Channel selectors是什么?(选择器)
events或者说数据要可以通过不同的channel 发送到不同的sink中去,那么events要发送到哪个channel 就是由于channel selectors决定的。
channel selectors包括:
(1).Replicating channel selectors 复制选择器(default)
(2).Multiplexing channel selectors 多路选择器
默认的是复制选择器,即每个channel的数据都是一样的,多路选择权就需要按照制定的规则去判断了。
11.Flume拦截器(拦截器)
(1).拦截器注意事项
1)ETL拦截器:主要是用来判断json是否完整。没有做复杂的清洗操作主要是防止过多的降低传输速率。
2)时间戳拦截器:主要是解决零点漂移问题
(2).自定义拦截器步骤
1)实现 Interceptor
2)重写四个方法
- initialize 初始化
- public Event intercept(Event event) 处理单个Event
- public List<Event> intercept(List<Event> events) 处理多个Event,在这个方法中调用Event intercept(Event event)
- close方法
3)静态内部类,实现Interceptor.Builder
(3).拦截器可以不用吗?
ETL拦截器可以不用;需要在下一级Hive的dwd层和SparkSteaming里面处理。
时间戳拦截器建议使用。 如果不用需要采用延迟15-20分钟处理数据的方式,比较麻烦。
12.Flume的source中Exec、Spooldir、Taildir的区别
(1).Exec:(读一个不断在追加新内容的文件,不能断点续传) 表示执行linux命令来读取文件 和 tail -F命令搭配可以检测文件, exec source 适合监控一个实时追加的文件,不能实现断点续传。如果agent挂了会把所有文件内容重新读一遍。
(2).Spooldir source:(就是读目录下的新文件)适合同步新文件 但不适合对实时追加日志的文件监听同步,读取新文件后会标记completed,但是这个文件无论是否有变化 都不会再读取了。
(3).Taildir source:(就是读目录下的文件,这些文件是不断在追加新内容的文件,可以断点续传) 适合用于监听多个实时追加的文件。 Taildir source 维护了一个json格式的position File ,会定期往position File更新每个文件读取到的最新的位置,因此能够进行断点续读。也就是读到的位置可以记录下来,agent重启后可以断点续读。
13.Flume的source、channel、sink的对应关系
在一个Flume进程中,source、channel、sink的关系是:1个source可以绑定多个channel,一个channel只能绑定1个sink。
(1). source和channel是一对多的关系,这意味着一个source可以同时向多个channel发送数据,增加了数据的冗余和可靠性。
(2). sink和channel是一对一的关系,这确保了数据从source到sink的单一流向,避免了数据混乱。
本文来自博客园,作者:业余砖家,转载请注明原文链接:https://www.cnblogs.com/yeyuzhuanjia/p/18586955

