

Hadoop相关面试题
1.1、介绍Hadoop
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
(1)、HDFS(分布式文件系统):解决海量数据存储;
(2)、YARN(作业调度和集群资源管理的框架):解决资源任务调度;
(3)、MAPREDUCE(分布式运算编程框架):解决海量数据计算;
1.2、Hadoop特性优点
(1)、扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,集群可以方便的扩展到数以千计的节点中。
(2)、成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
(3)、高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
(4)、可靠性(Rellable):能自动维护数据的多份副本,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
1.3、hadoop集群都需要启动哪些进程,作用分别是什么?
(1)、namenode =>HDFS的守护进程,负责维护整个文件系统,存储着整个文件系统的元数据信息,fsimage + edit log。
(2)、datanode =>是具体文件系统的工作节点,当我们需要某个数据,NameNode告诉我们去哪里找,就直接和那个DataNode对应的服务器的后台进程进行通信,由DataNode进行数据的检索,然后进行具体的读/写操作。
(3)、secondarynamenode =>一个守护进程,相当于一个NameNode的元数据的备份机制,定期的更新,和NameNode进行通信,将NameNode上的fsimage和edit log进行合并,可以作为NameNode的备份使用。
(4)、resourcemanager =>是yarn平台的守护进程,负责所有资源的分配与调度,client的请求由此负责,监控nodemanager。
(5)、nodemanager => 是单个节点的资源管理,执行来自resourcemanager的具体任务和命令。
(6)、ZKFailoverController => 高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为Active NN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。
(7)、JournalNode => 高可用情况下存放NameNode的edit log文件。 它的主要作用是保证 NameNode 的高可用性,当某个节点出现故障时,其他节点可以从它的 JournalNode 中获取数据,继续提供服务,从而避免了系统单点故障的情况。
1.4、Hadoop主要的配置文件
(1)、hadoop-env.sh
文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
(2)、core-site.xml
设置Hadoop的文件系统地址
<property> <name>fs.defaultFS</name> <value>hdfs://node-1:9000</value> </property>
(3)、hdfs-site.xml
1) 指定HDFS副本的数量
2) secondary namenode 所在主机的ip和端口

<property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node-2:50090</value> </property>
(4)、mapred-site.xml
指定mr运行时框架,这里指定在yarn上,默认是local
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
(5)、yarn-site.xml
指定YARN的主角色(ResourceManager)的地址
<property> <name>yarn.resourcemanager.hostname</name> <value>node-1</value> </property>
1.5、Hadoop集群重要命令
(1)、初始化
hadoop namenode -format
(2)、启动dfs
start-dfs.sh
(3)、启动yarn
start-yarn.sh
4)、启动任务历史服务器
mr-jobhistory-daemon.sh start historyserver
(5)、一键启动
start-all.sh
(6)、启动成功后:
NameNode http://nn_host:port/ 默认50070.
ResourceManagerhttp://rm_host:port/ 默认 8088
|
选项名称 |
使用格式 |
含义 |
|
-ls |
-ls <路径> |
查看指定路径的当前目录结构 |
|
-lsr |
-lsr <路径> |
递归查看指定路径的目录结构 |
|
-du |
-du <路径> |
统计目录下个文件大小 |
|
-dus |
-dus <路径> |
汇总统计目录下文件(夹)大小 |
|
-count |
-count [-q] <路径> |
统计文件(夹)数量 |
|
-mv |
-mv <源路径> <目的路径> |
移动 |
|
-cp |
-cp <源路径> <目的路径> |
复制 |
|
-rm |
-rm [-skipTrash] <路径> |
删除文件/空白文件夹 |
|
-rmr |
-rmr [-skipTrash] <路径> |
递归删除 |
|
-put |
-put <多个linux上的文件> <hdfs路径> |
上传文件 |
|
-copyFromLocal |
-copyFromLocal <多个linux上的文件> <hdfs路径> |
从本地复制 |
|
-moveFromLocal |
-moveFromLocal <多个linux上的文件> <hdfs路径> |
从本地移动 |
|
-getmerge |
-getmerge <源路径> <linux路径> |
合并到本地 |
|
-cat |
-cat <hdfs路径> |
查看文件内容 |
|
-text |
-text <hdfs路径> |
查看文件内容 |
|
-copyToLocal |
-copyToLocal [-ignoreCrc] [-crc] [hdfs源路径] [linux目的路径] |
从本地复制 |
|
-moveToLocal |
-moveToLocal [-crc] <hdfs源路径> <linux目的路径> |
从本地移动 |
|
-mkdir |
-mkdir <hdfs路径> |
创建空白文件夹 |
|
-setrep |
-setrep [-R] [-w] <副本数> <路径> |
修改副本数量 |
|
-touchz |
-touchz <文件路径> |
创建空白文件 |
|
-stat |
-stat [format] <路径> |
显示文件统计信息 |
|
-tail |
-tail [-f] <文件> |
查看文件尾部信息 |
|
-chmod |
-chmod [-R] <权限模式> [路径] |
修改权限 |
|
-chown |
-chown [-R] [属主][:[属组]] 路径 |
修改属主 |
|
-chgrp |
-chgrp [-R] 属组名称 路径 |
修改属组 |
|
-help |
-help [命令选项] |
帮助 |
1.6、HDFS的垃圾桶机制
修改core-site.xml
<property> <name>fs.trash.interval</name> <value>1440</value> </property>
这个时间以分钟为单位,例如1440=24h=1天。HDFS的垃圾回收的默认配置属性为 0,也就是说,如果你不小心误删除了某样东西,那么这个操作是不可恢复的。
1.7、HDFS写数据流程
HDFS dfs -put a.txt /
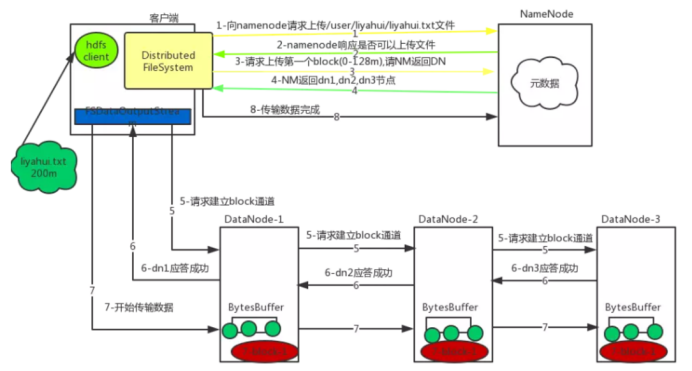
详细步骤:
1)客户端通过Distributed FileSystem模块向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1、dn2、dn3逐级应答客户端。
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(大小为64k),dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。
1.8、Hadoop读数据流程
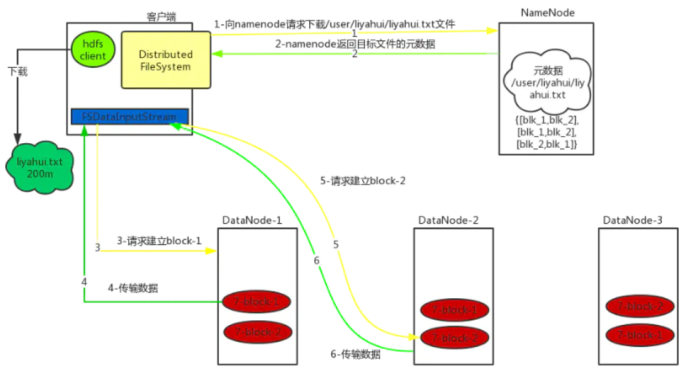
详细步骤:
1)客户端通过Distributed FileSystem向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验,大小为64k)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
checkpoint流程
在hdfs-site.xml文件指定secondarynamenode部署在哪个机器上
<property> <name>dfs.namenode.secondary.http-address</name> <value>hdp02:50090</value> </property>
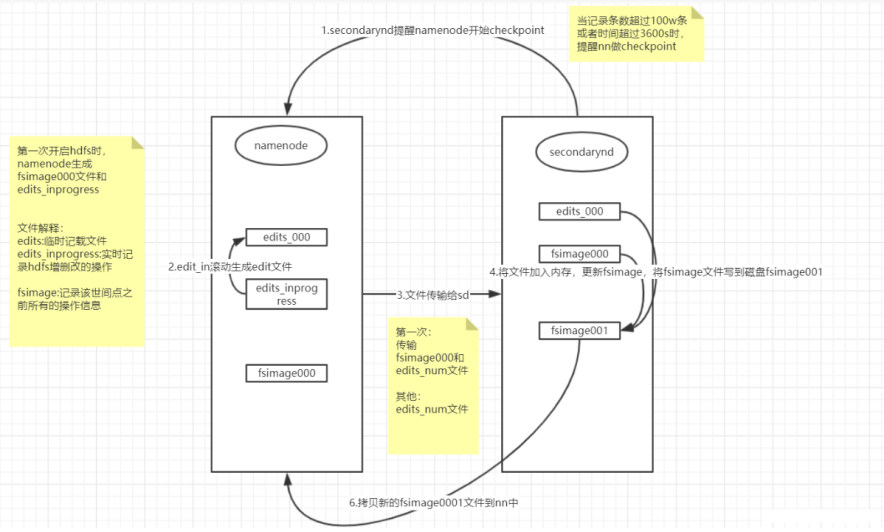
1.sn提醒nn做checkpoint
2.nn上的edit_inprogress文件滚动生成edit_sum文件
3.将edit_sum文件传给sn
4.sn更新fsimage文件
5.sn将文件写入磁盘
6.将文件传给nn
作用讲解:
edit:NameNode在本地操作hdfs系统的文件都会保存在Edits日志文件中。也就是说当文件系统中的任何元数据产生操作时,都会记录在Edits日志文件中(增删改查)
fsimage:存放的是一份最完整的元数据信息,内容比较大
edit一直记录元数据操作记录的话,也会慢慢膨胀的比较大,也会造成操作起来比较困难
为了控制edits不会膨胀太大,引入secondaryNameNode机制。
ss主要作用合并edits和fsimage文件,清空edit
元数据
元数据的分类
按形式分类:内存元数据和元数据文件;它们的存在的位置分别为:内存和磁盘上。其中内存元数据主要是hdfs文件目录的管理;元数据文件则用于持久化存储。
按类型分,元数据主要包括:
1、文件、目录自身的属性信息,例如文件名,目录名,修改信息等。
2、文件记录的信息的存储相关的信息,例如存储块信息,分块情况,副本个数等。
3、记录HDFS的Datanode的信息,用于DataNode的管理。
1.9、SecondaryNameNode的作用
NameNode职责是管理元数据信息,DataNode的职责是负责数据具体存储,那么SecondaryNameNode的作用是什么?
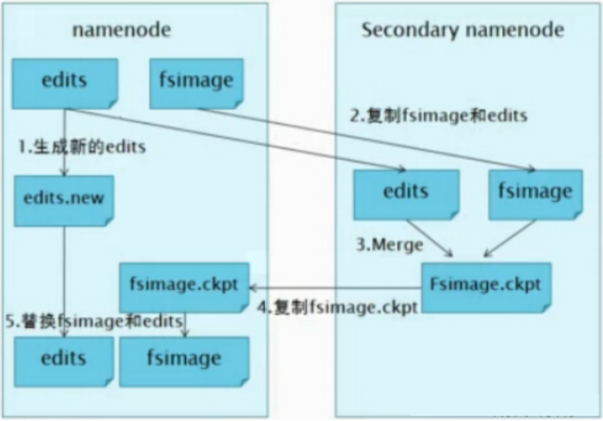
答:它的职责是合并NameNode的edit logs到fsimage文件。
每达到触发条件 [达到一个小时,或者事物数达到100万],会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint),如下图所示:
1.10、HDFS的扩容、缩容(面试)
(1)、动态扩容
随着公司业务的增长,数据量越来越大,原有的datanode节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。也就是俗称的动态扩容。
有时候旧的服务器需要进行退役更换,暂停服务,可能就需要在当下的集群中停止某些机器上hadoop的服务,俗称动态缩容。
1)、基础准备
在基础准备部分,主要是设置hadoop运行的系统环境
修改新机器系统hostname(通过/etc/sysconfig/network进行修改)
修改hosts文件,将集群所有节点hosts配置进去(集群所有节点保持hosts文件统一)
设置NameNode到DataNode的免密码登录(ssh-copy-id命令实现)
修改主节点slaves文件,添加新增节点的ip信息(集群重启时配合一键启动脚本使用)
在新的机器上上传解压一个新的hadoop安装包,从主节点机器上将hadoop的所有配置文件,scp到新的节点上。
2)、添加datanode
在namenode所在的机器的
/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop目录下创建dfs.hosts文件
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim dfs.hosts
添加如下主机名称(包含新服役的节点)
node-1
node-2
node-3
node-4
在namenode机器的hdfs-site.xml配置文件中增加dfs.hosts属性
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
<property> <name>dfs.hosts</name> <value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts</value> </property>
dfs.hosts属性的意义:命名一个文件,其中包含允许连接到namenode的主机列表。必须指定文件的完整路径名。如果该值为空,则允许所有主机。相当于一个白名单,也可以不配置。
在新的机器上单独启动datanode: hadoop-daemon.sh start datanode
刷新页面就可以看到新的节点加入进来了
3)、datanode负载均衡服务
新加入的节点,没有数据块的存储,使得集群整体来看负载还不均衡。因此最后还需要对hdfs负载设置均衡,因为默认的数据传输带宽比较低,可以设置为64M,即hdfs dfsadmin -setBalancerBandwidth 67108864即可。
默认balancer的threshold为10%,即各个节点与集群总的存储使用率相差不超过10%,我们可将其设置为5%。然后启动Balancer,
sbin/start-balancer.sh -threshold 5,等待集群自均衡完成即可。
4)、添加nodemanager
在新的机器上单独启动nodemanager:
yarn-daemon.sh start nodemanager
在ResourceManager,通过yarn node -list查看集群情况
(2)、动态缩容
1)、添加退役节点
在namenode所在服务器的hadoop配置目录etc/hadoop下创建dfs.hosts.exclude文件,并添加需要退役的主机名称。
注意:该文件当中一定要写真正的主机名或者ip地址都行,不能写node-4
node04.hadoop.com
在namenode机器的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
<property> <name>dfs.hosts.exclude</name> <value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts.exclude</value> </property>
dfs.hosts.exclude属性的意义:命名一个文件,其中包含不允许连接到namenode的主机列表。必须指定文件的完整路径名。如果值为空,则不排除任何主机。
2)、刷新集群
在namenode所在的机器执行以下命令,刷新namenode,刷新resourceManager。
hdfs dfsadmin -refreshNodes
yarn rmadmin –refreshNodes
等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。
node-4执行以下命令,停止该节点进程
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemon.sh stop datanode
sbin/yarn-daemon.sh stop nodemanager
namenode所在节点执行以下命令刷新namenode和resourceManager
hdfs dfsadmin –refreshNodes
yarn rmadmin –refreshNodes
namenode所在节点执行以下命令进行均衡负载
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-balancer.sh
1.11、HDFS安全模式
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求,是一种保护机制,用于保证集群中的数据块的安全性。
在NameNode主节点启动时,HDFS首先进入安全模式,集群会开始检查数据块的完整性。DataNode在启动的时候会向namenode汇报可用的block信息,当整个系统达到安全标准时,HDFS自动离开安全模式。
手动进入安全模式
hdfs dfsadmin -safemode enter
手动离开安全模式
hdfs dfsadmin -safemode leave
1.12、机架感知
hadoop自身是没有机架感知能力的,必须通过人为的设定来达到这个目的。一种是通过配置一个脚本来进行映射;另一种是通过实现DNSToSwitchMapping接口的resolve()方法来完成网络位置的映射。
1、写一个脚本,然后放到hadoop的core-site.xml配置文件中,用namenode和jobtracker进行调用。
#!/usr/bin/python #-*-coding:UTF-8 -*- import sys rack = {"hadoop-node-31":"rack1", "hadoop-node-32":"rack1", "hadoop-node-33":"rack1", "hadoop-node-34":"rack1", "hadoop-node-49":"rack2", "hadoop-node-50":"rack2", "hadoop-node-51":"rack2", "hadoop-node-52":"rack2", "hadoop-node-53":"rack2", "hadoop-node-54":"rack2", "192.168.1.31":"rack1", "192.168.1.32":"rack1", "192.168.1.33":"rack1", "192.168.1.34":"rack1", "192.168.1.49":"rack2", "192.168.1.50":"rack2", "192.168.1.51":"rack2", "192.168.1.52":"rack2", "192.168.1.53":"rack2", "192.168.1.54":"rack2" } if __name__=="__main__": print "/" + rack.get(sys.argv[1],"rack0")
2、将脚本赋予可执行权限chmod +x RackAware.py,并放到bin/目录下。
3、然后打开conf/core-site.html
<property> <name>topology.script.file.name</name> <value>/opt/modules/hadoop/hadoop-1.0.3/bin/RackAware.py</value> <!--机架感知脚本路径--> </property> <property> <name>topology.script.number.args</name> <value>20</value> <!--机架服务器数量,由于我写了20个,所以这里写20--> </property>
4、重启Hadoop集群
namenode日志
2012-06-08 14:42:19,174 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.49:50010 storage DS-1155827498-192.168.1.49-50010-1338289368956
2012-06-08 14:42:19,204 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack2/192.168.1.49:50010
2012-06-08 14:42:19,205 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.53:50010 storage DS-1773813988-192.168.1.53-50010-1338289405131
2012-06-08 14:42:19,226 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack2/192.168.1.53:50010
2012-06-08 14:42:19,226 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.34:50010 storage DS-2024494948-127.0.0.1-50010-1338289438983
2012-06-08 14:42:19,242 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack1/192.168.1.34:50010
2012-06-08 14:42:19,242 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 192.168.1.54:50010 storage DS-767528606-192.168.1.54-50010-1338289412267
2012-06-08 14:42:49,492 INFO org.apache.hadoop.hdfs.StateChange: STATE* Network topology has 2 racks and 10 datanodes
2012-06-08 14:42:49,492 INFO org.apache.hadoop.hdfs.StateChange: STATE* UnderReplicatedBlocks has 0 blocks
2012-06-08 14:42:49,642 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: ReplicateQueue QueueProcessingStatistics: First cycle completed 0 blocks in 0 msec
2012-06-08 14:42:49,642 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: ReplicateQueue QueueProcessingStatistics: Queue flush completed 0 blocks in 0 msec processing time, 0 msec clock time, 1 cycles
1.13、其他
1.13.1、数据存储在hdfs格式,使用的什么压缩方式,压缩比多少
目前在Hadoop中用得比较多的有lzo ,gzip ,snappy , bzip2这4种压缩格式,笔者根据实践经验介绍一 下这4种压缩格式的优缺点和应用场景,以便大家在实践中根据实际情况选择不同的压缩格式。
(1)、gzip压缩
优点:
压缩率比较高,而且压缩/解压速度也比较快;
hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样; 有hadoop native库;
大部分linux系统都自带gzip命令,使用方便。
缺点:不支持split。
应用场景:
当每个文件压缩之后在130M以内的(1个块大小内),都可以考虑用gzip压缩格式。譬如说 一天或者一个小时的日志压缩成一个gzip文件,运行mapreduce程序的时候通过多个gzip文 件达到并发。
hive程序, streaming程序,和java写的mapreduce程序完全和文本处理一样,压缩之后原来 的程序不需要做任何修改。
(2)、lzo压缩
优点:
压缩/解压速度也比较快,合理的压缩率;
支持split,是hadoop中最流行的压缩格式;
支持hadoop native库;
可以在linux系统下安装lzop命令,使用方便。
缺点:
压缩率比gzip要低一些;
hadoop本身不支持,需要安装;
在应用中对lzo格式的文件需要做一些特殊处理(为了支持split需要建索引,还需要指定
inputformat为lzo格式)。
应用场景:
一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大, lzo优点越 明显。
(3)、snappy压缩
优点:
高速压缩速度和合理的压缩率;
支持hadoop native库。
缺点:
不支持split;
压缩率比gzip要低;
hadoop本身不支持,需要安装;
linux系统下没有对应的命令。
应用场景:
当mapreduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格 式;或者作为一个mapreduce作业的输出和另外一个mapreduce作业的输入。
(4)、bzip2压缩
优点:
支持split;
具有很高的压缩率,比gzip压缩率都高;
hadoop本身支持,但不支持native;
在linux系统下自带bzip2命令,使用方便。
缺点:
压缩/解压速度慢;
不支持native。
应用场景:
适合对速度要求不高,但需要较高的压缩率的时候,可以作为mapreduce作业的输出格式; 或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比 较少的情况;
或者对单个很大的文本文件想压缩减少存储空间,同时又需要支持split,而且兼容之前的应用 程序(即应用程序不需要修改)的情况。
1.13.2、高可用的集群中namenode宕机了,怎么恢复的
首先进入安全模式:
hdfs dfsadmin -safemode enter
然后刷一下active节点的log到image
hdfs dfsadmin -saveNamespace
然后将active节点的image文件全部拷贝到故障节点的相应目录下
然后重启故障namenode
最后hdfs namenode -bootstrapStandby
到此,故障解决。
后来还解决过一次hdfs的block丢失的问题,也是将原先的image全部拷贝回来搞定的。 所以说,即便有HA,定期备份image文件还是很重要的。
1.13.3、hdfs的瓶颈
(1)、fsimage加载阶段,主要耗时的操作:
1) FSDirectory.addToParent(),功能是根据路径path生成节点INode,并加入目录树中,占加载时间的73%;
2) FSImage.readString和PermissionStatus.read操作是从fsimage的文件流中读取数据(分别 是读取String和short)的操作,分别占加载时间的15%和8%;
优化方案:对fsimage的持久化操作采用多线程技术,为目录列表中的每个目录存储开辟一个线 程,用来存储fsimage文件。主线程等待所有存储的子线程完毕后完成对fsimage加载。这样,存 储时间将取决于存储最慢的那个线程,达到了提高fsimage加载速度的目的,从而在一定程度上提 升了NameNode启动速度。
(2)、blockReport阶段, DataNode在启动时通过RPC调用NameNode.blockReport()方法, 主要耗时操作:
1) FSNamesystem.addStoredBlock调用,对每一个汇报上来的block,将其于汇报上来的 datanode的对应关系初始化到namenode内存中的BlocksMap表中,占用时间比为77%;此方法中主要耗时的两个阶段分别是FSNamesystem.countNode和DatanodeDescriptor.addBlock,后 者是java中的插表操作,而FSNamesystem.countNode调用的目的是为了统计在BlocksMap中, 每一个block对应的各副本中,有几个是live状态,几个是decommission状态,几个是Corrupt状态。
2) DatanodeDescriptor.reportDiff,主要是为了将该datanode汇报上来的blocks跟 namenode内存中的BlocksMap中进行对比,以决定那个哪些是需要添加到BlocksMap中的 block,哪些是需要添加到toRemove队列中的block,以及哪些是添加到toValidate队列中的 block,占用时间比为20%;
(3)、锁的竞争成为性能瓶颈
优化方案:其中锁内耗时的操作有FSEditLog.logXXX方法,可以考虑将FSEditLog的logXXX操作放 到写锁外记录,但会引起记录的顺序不一致,可以通过在写锁内生成SerialNumber,在锁外按顺 序输出来解决;
(4)、UTF8/Unicode转码优化成为性能瓶颈
优化方案:用SIMD指令的JVM Intrinsic转码实现, 32bytes比目前Hadoop内pure Java实现快4 倍,64bytes快十几倍。
(5)、RPC框架中, N个Reader将封装的Call对象放入一个BlockingQueue , N个Handler从一个 BlockingQueue中提取Call对象,使得此BlockingQueue成为性能瓶颈
优化方案:采用多队列,一个Handler一个BlockingQueue,按callid分配队列。
(6)、sendHeartbeat阶段,在DataNode调用namenode.sendHeartbeat()方法时会DF和DU两个类, 它们通过Shell类的runComamnd方法来执行系统命令,以获取当前目录的 df, du 值,在 runComamnd方法中实质是通过java.lang. ProcessBuilder类来执行系统命令的。该类由JVM通过 Linux 内核来fork 子进程,子进程当然会完全继承父进程的所有内存句柄, jstack看到JVM此时线 程状态大部分处于WAITING , 这个过程会影响DFSClient写入超时,或关闭流出错。
1.13.4、hdfs存放文件量过大怎么优化
(1)、可以通过调用 HDFS 的 sync() 方法(和 append 方法结合使用),每隔一定时间生成一个大文件。或者可以通过写一个 MapReduce 程序来来合并这些小文件。
(2)、HAR File
Hadoop Archives ( HAR files)是在 0.18.0 版本中引入到 HDFS 中的,它的出现就是为了缓解大量小文件消耗 NameNode 内存的问题。 HAR 文件是通过在 HDFS 上构建一个分层文件系统来工 作。 HAR 文件通过 hadoop archive 命令来创建,而这个命令实际上是运行 MapReduce 作业来将 小文件打包成少量的 HDFS 文件(译者注:将小文件进行合并成几个大文件)。对于客户端来说, 使用 HAR 文件系统没有任何的变化:所有原始文件都可见以及可以访问(只是使用 har://URL,而 不是 hdfs://URL),但是在 HDFS 中中文件个数却减少了。
读取 HAR 文件不如读取 HDFS 文件更有效,并且实际上可能更慢,因为每个 HAR 文件访问需要读 取两个索引文件以及还要读取数据文件本。
尽管 HAR 文件可以用作 MapReduce 的输入,但是 Map 没有办法直接对共同驻留在 HDFS 块上的 HAR 所有文件操作。可以考虑通过创建一种 input format,充分利用 HAR 文件的局部性优势,但 是目前还没有这种input format。需要注意的是: MultiFileInputSplit,即使在 HADOOP-4565 进 行了改进,选择节点本地分割中的文件,但始终还是需要每个小文件的搜索。在目前看来, HAR 可能最好仅用于存储文档。
(3)、SequenceFile
通常解决”小文件问题”的回应是:使用 SequenceFile。这种方法的思路是,使用文件名作为 key, 文件内容作为 value
在实践中这种方式非常有效。我们回到10,000个100KB大小的小文件问题上,你可以编写一个程序 将合并为一个 SequenceFile,然后你可以以流式方式处理(直接处理或使用 MapReduce) SequenceFile。这样会带来两个优势:
SequenceFiles 是可拆分的,因此 MapReduce 可以将它们分成块,分别对每个块进行操作;
与 HAR 不同,它们支持压缩。在大多数情况下,块压缩是最好的选择,因为它直接对几个记录组 成的块进行压缩,而不是对每一个记录进行压缩。
将现有数据转换为 SequenceFile 可能会很慢。但是,完全可以并行创建一个一个的 SequenceFile 文件。 Stuart Sierra 写了一篇关于将 tar 文件转换为 SequenceFile 的文章,像这样的工具是非常 有用的,我们应该多看看。向前看,最好设计好数据管道,如果可能的话,将源数据直接写入 SequenceFile ,而不是作为中间步骤写入小文件。
与 HAR 文件不同,没有办法列出 SequenceFile 中的所有键,所以不能读取整个文件。 Map File, 类似于对键进行排序的 SequenceFile,维护部分索引,所以他们也不能列出所有的键
1.13.5、HDFS小文件问题及解决方案
小文件是指文件size小于HDFS上block大小的文件,这样的文件会给hadoop的扩展性和性能带来严重问题。
首先,在HDFS中,任何block、文件或者目录在内存中均以对象的形式存储,每个对象约占150byte,如果有1000 0000个小文件,每个文件占用一个block,则namenode大约需要2G空间。如果存储1亿个文件,则namenode需要20G空间。这样namenode内存容量严重制约了集群的扩展。
其次,访问大量小文件速度远远小于访问几个大文件。HDFS最初是为流式访问大文件开发的,如果访问大量小文件,需要不断的从一个datanode跳到另一个datanode,严重影响性能。
最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个task,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
对于小文件问题,Hadoop本身也提供了几个解决方案,分别为:Hadoop Archive,Sequence file和CombineFileInputFormat。
1)、Hadoop Archive: Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。
HAR是在Hadoop file system之上的一个文件系统,因此所有fs shell命令对HAR文件均可用,只不过是文件路径格式不一样
使用HAR时需要两点,第一,对小文件进行存档后,原文件并不会自动被删除,需要用户自己删除;第二,创建HAR文件的过程实际上是在运行一个mapreduce作业,因而需要有一个hadoop集群运行此命令。
此外,HAR还有一些缺陷:第一,一旦创建,Archives便不可改变。要增加或移除里面的文件,必须重新创建归档文件。第二,要归档的文件名中不能有空格,否则会抛出异常,可以将空格用其他符号替换
2)、 sequence file :sequence file由一系列的二进制key/value组成,如果为key小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。
3)、CombineFileInputFormat:CombineFileInputFormat是一种新的inputformat,用于将多个文件合并成一个单独的split
1.13.6、HDFS高可用(HA)
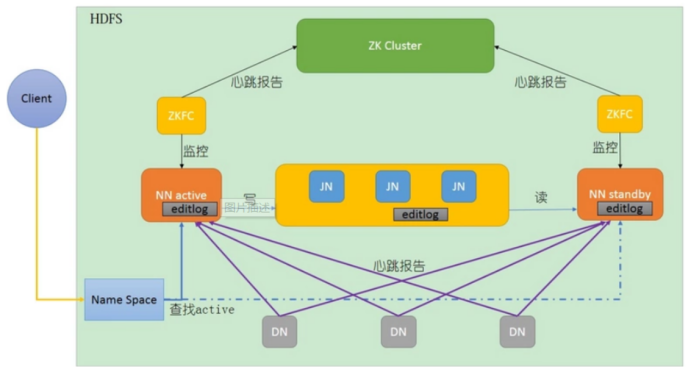
高可用原理
所谓HA,即高可用(7*24小时不中断服务),实现高可用最关键的是消除单点故障。
HDFS 的 HA 就是通过双namenode 来防止单点问题,一旦主NameNode出现故障,可以迅速切换至备用的 NameNode。两个namenode有不同的状态,状态分别是Active和Standby。(备用) Namenode作为热备份,在机器发生故障时能够快速进行故障转移,同时在日常维护的时候进行Namenode切换。
HDFS HA的几大重点
1)保证两个namenode里面的内存中存储的文件的元数据同步
->namenode启动时,会读镜像文件
2)变化的记录信息同步
3)日志文件的安全性
->分布式的存储日志文件(cloudera公司提出来的)
->2n+1个,使用副本数保证安全性
->使用zookeeper监控
->监控两个namenode,当一个出现了问题,可以达到自动故障转移。
->如果出现了问题,不会影响整个集群
->zookeeper对时间同步要求比较高。
4)客户端如何知道访问哪一个namenode
->使用proxy代理
->隔离机制
->使用的是sshfence
->两个namenode之间无密码登录
5)namenode是哪一个是active
->zookeeper通过选举选出zookeeper。
->然后zookeeper开始监控,如果出现文件,自动故障转移。
HDFS HA的实现流程
主Namenode处理所有的操作请求,而Standby只是作为slave,主要进行同步主Namenode的状态,保证发生故障时能够快速切换,并且数据一致。为了两个 Namenode数据保持同步,两个Namenode都与一组Journal Node进行通信。当主Namenode进行任务的namespace操作时,都会同步修改日志到Journal Node节点中。Standby Namenode持续监控这些edit,当监测到变化时,将这些修改同步到自己的namespace。当进行故障转移时,Standby在成为Active Namenode之前,会确保自己已经读取了Journal Node中的所有edit日志,从而保持数据状态与故障发生前一致。
为了确保故障转移能够快速完成,Standby Namenode需要维护最新的Block位置信息,即每个Block副本存放在集群中的哪些节点上。为了达到这一点,Datanode同时配置主备两个Namenode,并同时发送Block报告和心跳到两台Namenode。
任何时刻集群中只有一个Namenode处于Active状态,否则可能出现数据丢失或者数据损坏。当两台Namenode都认为自己的Active Namenode时,会同时尝试写入数据。为了防止这种脑裂现象,Journal Nodes只允许一个Namenode写入数据,内部通过维护epoch数来控制,从而安全地进行故障转移。
1.13.7、Hadoop切片机制
一个超大文件在HDFS上存储时,是以多个Block存储在不同的节点上,比如一个512M的文件,HDFS默认一个Block为128M,那么512M的文件分成4个Block存储在集群中4个节点上。
Hadoop在map阶段处理上述512M的大文件时分成几个MapTask进行处理呢?Hadoop的MapTask并行度与数据切片有有关系,数据切片是对输入的文件在逻辑上进行分片,对文件切成多少份,Hadoop就会分配多少个MapTask任务进行并行执行该文件,原理如下图所示。
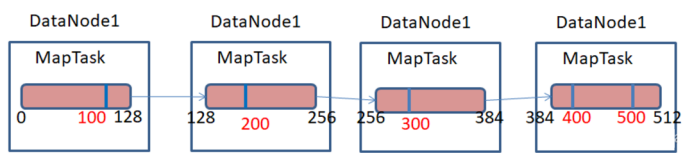
Block与Splite区别:Block是HDFS物理上把数据分成一块一块;数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。如下图所示,一个512M的文件在HDFS上存储时,默认一个block为128M,那么该文件需要4个block进行物理存储;若对该文件进行切片,假设以100M大小进行切片,该文件在逻辑上需要切成6片,则需要6个MapTask任务进行处理。
(1)、TextInputFormat切片机制
切片方式:TextInputFormat是默认的切片机制,按文件规划进行切分。比如切片默认为128M,如果一个文件为200M,则会形成两个切片,一个是128M,一个是72M,启动两个MapTask任务进行处理任务。但是如果一个文件只有1M,也会单独启动一个MapTask执行此任务,如果是10个这样的小文件,就会启动10个MapTask处理小文件任务。
读取方式:TextInputFormat是按行读取文件的每条记录,key代表读取的文件行在该文件中的起始字节偏移量,key为LongWritable类型;value为读取的行内容,不包括任何行终止符(换行符/回车符), value为Text类型,相当于java中的String类型。
(2)、CombineTextInputFormat切片机制
如果要处理的任务中含有很多小文件,采用默认的TextInputFormat切片机制会启动多个MapTask任务处理文件,浪费资源。CombineTextInputFormat用于处理小文件过多的场景,它可以将多个小文件从逻辑上切分到一个切片中。CombineTextInputFormat在形成切片过程中分为虚拟存储过程和切片过程两个过程。
1)虚拟存储过程
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
2)切片过程
判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片;
如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
本文来自博客园,作者:业余砖家,转载请注明原文链接:https://www.cnblogs.com/yeyuzhuanjia/p/18570730

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步