
把大象装进冰箱:HTTP传输大文件的方法
一、数据压缩
上一篇博文有说到,如果文件过大,通常浏览器在发送请求时都会带着“Accept-Encoding”头字段,里面是浏览器支持的压缩格式列表,例如 gzip、deflate、br 等,这样服务器就可以从中选择一种压缩算法,放进“Content-Encoding”响应头里,再把原数据压缩后发给浏览器。但是这一办法只对文本文档有效果,对于图片、视频等就不那么友好了,视频或者音频这些文件压缩后其实和原文件大小差不多,甚至压缩后内存会变成更大。。所以我们需要其他办法对大文件进行传输。
二、分块传输
既然大文件直接压缩不可行,那么我们可以考虑服务器端响应传输文件的时候将文件进行拆分,分块传给浏览器,浏览器接收后又将每一块都拼接起来,组合成大文件。这种“化整为零”的思路在 HTTP 协议里就是“chunked”分块传输编码,在响应报文里用头字段“Transfer-Encoding: chunked”来表示,意思是报文里的 body 部分不是一次性发过来的,而是分成了许多的块chunk)逐个发送。
“Transfer-Encoding: chunked”和“Content-Length”这两个字段是互斥的,也就是说响应报文里这两个字段不能同时出现,一个响应报文的传输要么是长度已知,要么是长度未知(chunked)。
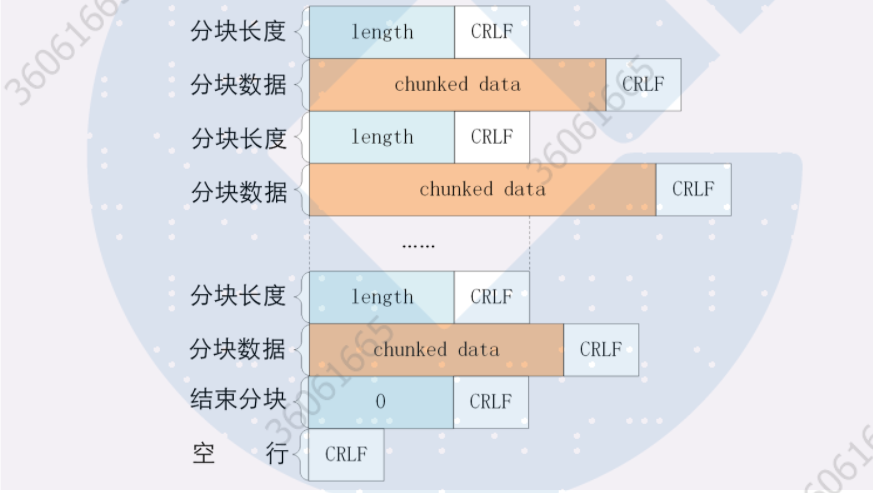
下面我们来看一下分块传输的编码规则,其实也很简单,同样采用了明文的方式,很类似响应头。每个分块包含两个部分,长度头和数据块;
长度头是以 CRLF(回车换行,即\r\n)结尾的一行明文,用 16 进制数字表示长度;
数据块紧跟在长度头后,最后也用 CRLF 结尾,但数据不包含 CRLF;
最后用一个长度为 0 的块表示结束,即“0\r\n\r\n”。
如下图所示:
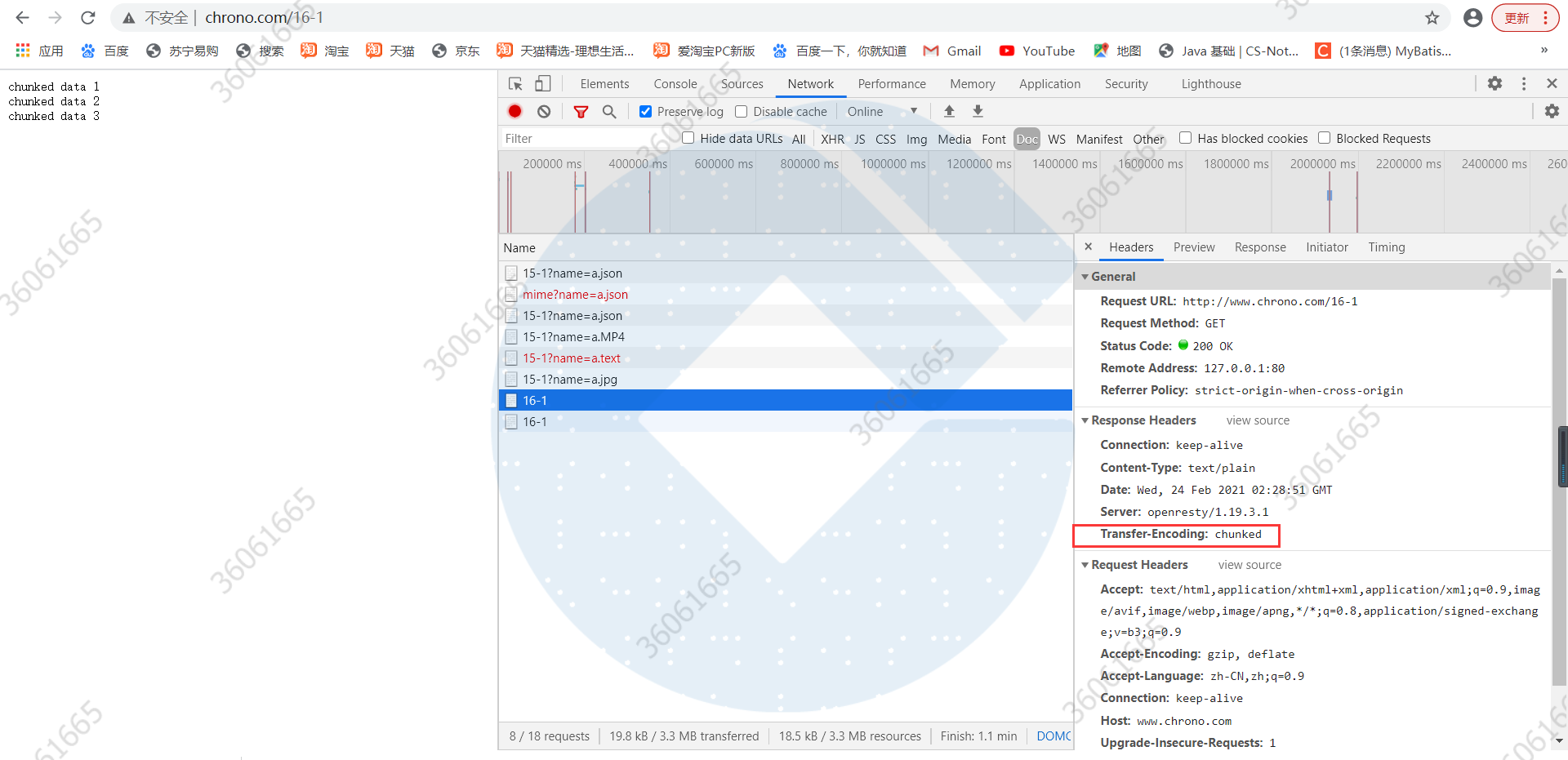
实验环境里的 URI“/16-1”简单地模拟了分块传输,可以用 Chrome 访问这个地址看一下效果:
不过浏览器在收到分块传输的数据后会自动按照规则去掉分块编码,重新组装出内容,所以想要看到服务器发出的原始报文形态就得用 Telnet 手工发送请求(或者用 Wireshark 抓包):
GET /16-1 HTTP/1.1 Host: www.chrono.com
执行指令后响应如下:
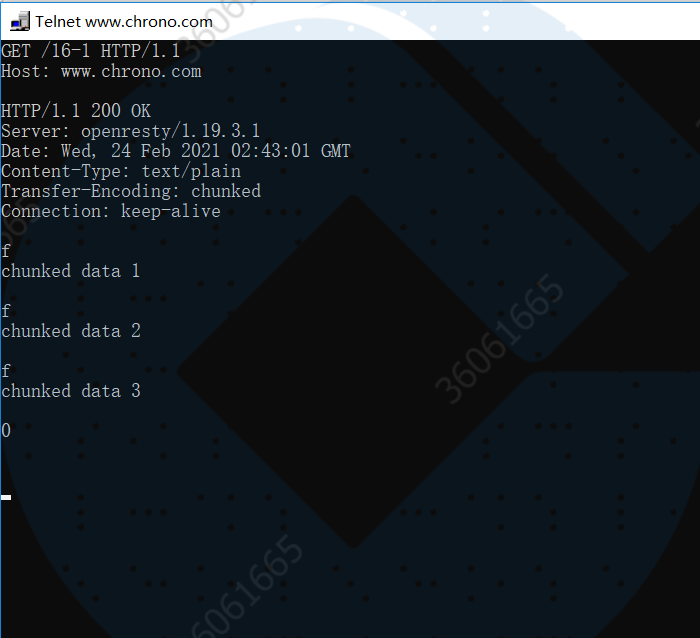
这便是原始形态。
因为 Telnet 只是收到响应报文就完事了,不会解析分块数据,所以可以很清楚地看到响应报文里的 chunked 数据格式:先是一行 16 进制长度,然后是数据,然后再是 16 进制长度和数据,如此重复,最后是 0 长度分块结束。
三、范围请求
有时候我们在看视频的时候,就想要跳到一个视频片段,单独看那个片段,这时候有需要如何实现呢?我们知道,分块传输是不具备范围请求这个功能的,这时,HTTP 协议为了满足这样的需求,提出了“范围请求”(range requests)的概念,允许客户端在请求头里使用专用字段来表示只获取文件的一部分,相当于是客户端的“化整为零”。范围请求不是 Web 服务器必备的功能,可以实现也可以不实现,所以服务器必须在响应头里使用字段“Accept-Ranges: bytes”明确告知客户端:“我是支持范围请求的”。但是如果响应头没有此字段时候就默认不支持范围请求,请求头只能接受整个报文字段。
请求头Range是 HTTP 范围请求的专用字段,格式是“bytes=x-y”,其中的 x 和 y 是以字节为单位的数据范围。
要注意 x、y 表示的是“偏移量”,范围必须从 0 计数,例如前 10 个字节表示为“0-9”,第二个 10 字节表示为“10-19”,而“0-10”实际上是前 11 个字节。
Range 的格式也很灵活,起点 x 和终点 y 可以省略,能够很方便地表示正数或者倒数的范围。假设文件是 100 个字节,那么:
“0-”表示从文档起点到文档终点,相当于“0-99”,即整个文件;
“10-”是从第 10 个字节开始到文档末尾,相当于“10-99”;
“-1”是文档的最后一个字节,相当于“99-99”;
“-10”是从文档末尾倒数 10 个字节,相当于“90-99”。
服务器收到 Range 字段后,需要做四件事。
第一,它必须检查范围是否合法,比如文件只有 100 个字节,但请求“200-300”,这就是范围越界了。服务器就会返回状态码416,意思是“你的范围请求有误,我无法处理,请再检查一下”。
第二,如果范围正确,服务器就可以根据 Range 头计算偏移量,读取文件的片段了,返回状态码“206 Partial Content”,和 200 的意思差不多,但表示 body 只是原数据的一部分。
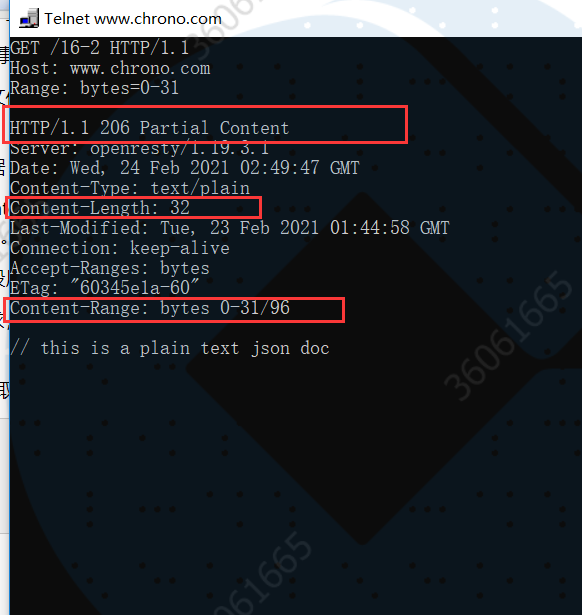
第三,服务器要添加一个响应头字段Content-Range,告诉片段的实际偏移量和资源的总大小,格式是“bytes x-y/length”,与 Range 头区别在没有“=”,范围后多了总长度。例如,对于“0-10”的范围请求,值就是“bytes 0-10/100”。
最后剩下的就是发送数据了,直接把片段用 TCP 发给客户端,一个范围请求就算是处理完了。
用实验环境的 URI“/16-2”来测试范围请求,它处理的对象是“/mime/a.txt”。不过我们不能用 Chrome 浏览器,因为它没有编辑 HTTP 请求头的功能(这点上不如 Firefox 方便),所以还是要用 Telnet。
例如下面的这个请求使用 Range 字段获取了文件的前 32 个字节:
GET /16-2 HTTP/1.1 Host: www.chrono.com Range: bytes=0-31
得到响应结果:
有了范围请求之后,HTTP 处理大文件就更加轻松了,看视频时可以根据时间点计算出文件的 Range,不用下载整个文件,直接精确获取片段所在的数据内容。
四、多段数据
刚才说的范围请求一次只获取一个片段,其实它还支持在 Range 头里使用多个“x-y”,一次性获取多个片段数据。
这种情况需要使用一种特殊的 MIME 类型:“multipart/byteranges”,表示报文的 body 是由多段字节序列组成的,并且还要用一个参数“boundary=xxx”给出段之间的分隔标记。多段数据的格式与分块传输也比较类似,但它需要用分隔标记 boundary 来区分不同的片段。
每一个分段必须以“- -boundary”开始(前面加两个“-”),之后要用“Content-Type”和“Content-Range”标记这段数据的类型和所在范围,然后就像普通的响应头一样以回车换行结束,再加上分段数据,最后用一个“- -boundary- -”(前后各有两个“-”)表示所有的分段结束。
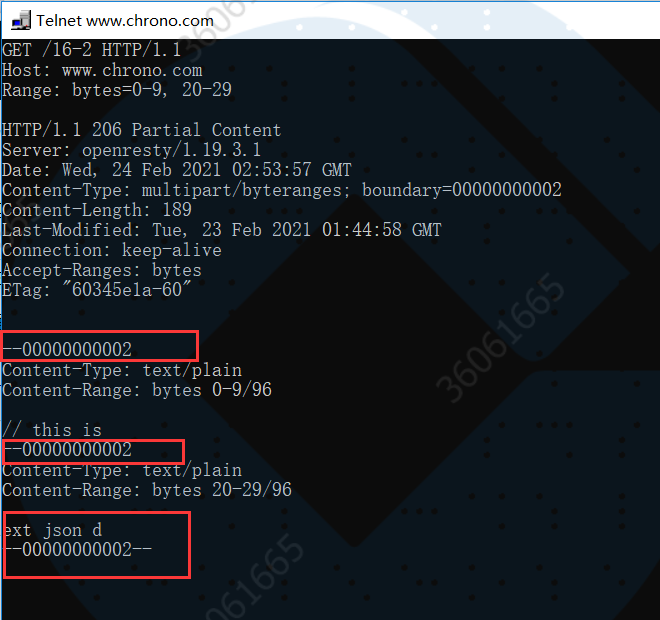
例如,我们在实验环境里用 Telnet 发出有两个范围的请求:
GET /16-2 HTTP/1.1 Host: www.chrono.com Range: bytes=0-9, 20-29
响应结果如下:
五、课后作业:
1. 分块传输数据的时候,如果数据里含有回车换行(\r\n)是否会影响分块的处理呢?
答:分块传输中数据里含有回车换行(\r\n)不影响分块处理,因为分块前有数据长度说明
2. 如果对一个被 gzip 的文件执行范围请求,比如“Range: bytes=10-19”,那么这个范围是应用于原文件还是压缩后的文件呢?
答:需要分情况,看原文件是什么形式。如果原来的文件是gzip的,那就正确。如果原文件是文本,而是在传输过程中被压缩,那么就应用于压缩前的数据。总之,range是针对原文件的。
至此,结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号