
键入网址再按下回车,后面究竟发生了什么?
现在我们来探索一次HTTP请求以及应答整个过程
使用IP地址访问web服务器,然后利用wireshark捕捉这一过程
一、准备工作
1. 首先运行 www 目录下的“start”批处理程序,启动本机的 OpenResty 服务器,启动后可以用“list”批处理确认服务是否正常运行。
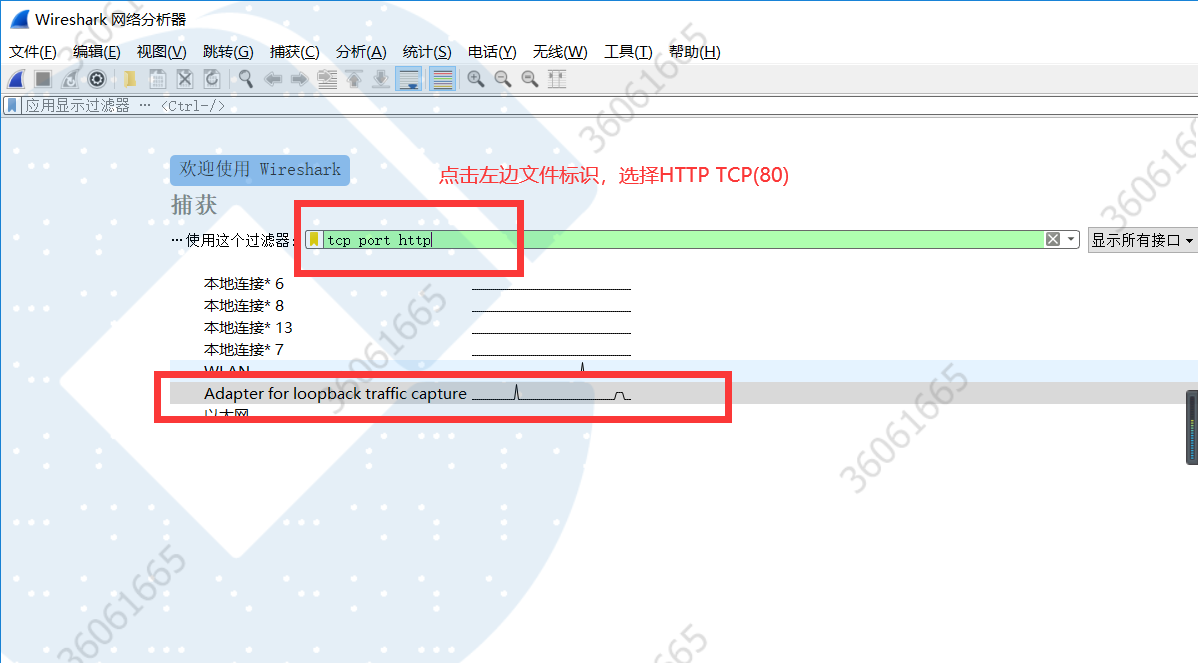
2. 然后打开wireshark,过滤器选择“HTTP TCP(80)” , 然后双击Adapter for loopback traffic capture,开始捕捉。
打开后界面是空白的,静待浏览器端发起请求。
二、正式工作——通过IP地址访问Web服务器
1. 浏览器端发起了请求:http://localhost/ 或者http://127.0.0.1,enter键访问后出现欢迎页面:

2. 然后回到wireshark,发现捕捉到了访问瞬间,如下所示: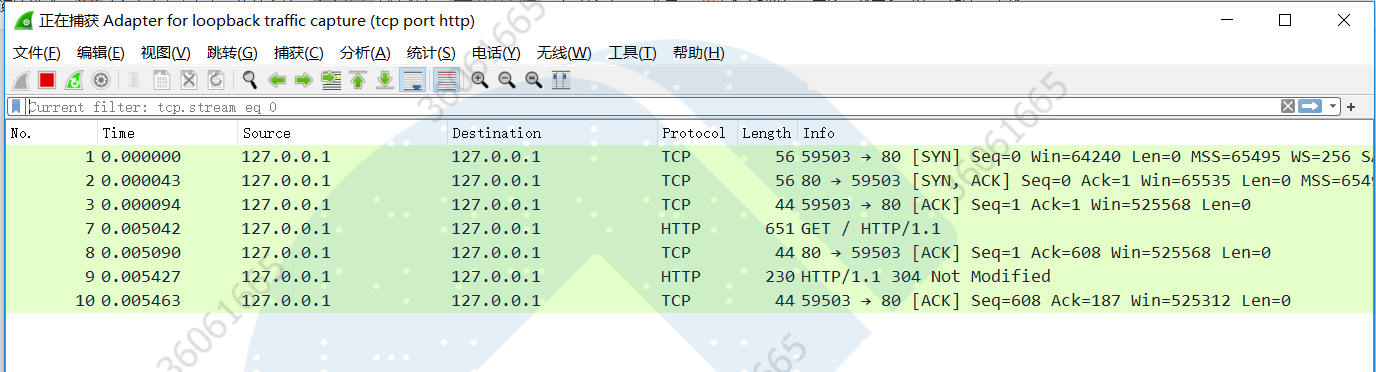
这里其实是实现了HTTP协议的三次握手过程,首先我们要知道,浏览器这里访问端口是59503,服务器响应端口是80,接下来说一下这一整个流程。
(1)我们知道,HTTP协议是建立在TCP/IP基础上的,所以在利用HTTP传输数据之前,会先进行TCP/IP搭建,这里就对应到前三个包,通过SYN、SYN,ACK,ACK顺利搭建好了TCP/IP;
(2)紧接着,这时候浏览器按照 HTTP 协议规定的格式,通过 TCP 发送了一个“GET / HTTP/1.1”请求报文,也就是 Wireshark 里的第四个包。
(3)接着,服务器返给浏览器一个报文,说:'好的好的,我收到你的请求啦",对应第五个包
(4)然后,服务器对浏览器发过来的报文进行处理,并将结果和处理结果返给浏览器,对应第6个包,这里304指的是该请求和之前的请求一样,因此从缓存中获取到了内容,直接返回给了浏览器。
(5)最后,浏览器收到查询结果后给服务器进行了回应,“好啦好啦我收到来自你的回复啦!”,对应最后一个包,整个三次握手过程结束。
再简要叙述一下这次最简单的浏览器 HTTP 请求过程:
浏览器从地址栏的输入中获得服务器的 IP 地址和端口号;
浏览器用 TCP 的三次握手与服务器建立连接;
浏览器向服务器发送拼好的报文;
服务器收到报文后处理请求,同样拼好报文再发给浏览器;
浏览器解析报文,渲染输出页面。
三、正式工作——域名访问web浏览器
1. 浏览器端发起了请求:http://www.chrono.com/,enter键访问后出现欢迎页面:
这说明这里的http://www.chrono.com/效果和127.0.0.1,这是为啥呢,这里就又涉及到域名解析的用法了。
我们之前对hosts文件进行了修改,在hosts文件中添加了三行代码,

所以我们在进行域名网址访问的时候会进行域名解析,首先在浏览器缓存中进行查询是否有记录,接着是操作系统缓存,然后是hosts文件缓存,这时发现原来http://www.chrono.com/域名地址解析后就是127.0.0.1,这就成功解释了两者为什么会产生相同的查询结果。
四、课后习题
1. 你能试着解释一下在浏览器里点击页面链接后发生了哪些事情吗?
答:浏览器判断这个链接是要在当前页面打开还是新开标签页,然后走一遍本文中的访问过程:拿到ip地址和端口号,建立tcp/ip链接,发送请求报文,接收服务器返回并渲染。
2. 这一节课里讲的都是正常的请求处理流程,如果是一个不存在的域名,那么浏览器的工作流程会是怎么样的呢?
答:我们在上面已经大致介绍了一下,点击页面连接后,浏览器判断是不是ip地址,不是就进行域名解析,首先进入浏览器缓存查找是否有过查询记录,没有进入操作系统缓存,没有再进入hosts缓存,如果还没有就进入局域网域名服务器,接着是广域网域名服务器,再就是顶级域名服务器,最后是根域名服务器,如果都没有,那就返回错误页面。
至此,结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号