

结对项目
结对项目:自动生成小学四则运算题目的命令行程序
| 这个作业属于哪个课程 | 计科22级12班 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 二人合作实现一个自动生成小学四则运算题目的命令行程序 |
| 姓名 | 学号 | GitHub链接 |
|---|---|---|
| 余李烨 | 3222004854 | https://github.com/yeyezi112/3222004854/tree/partner-work/patner_work |
| 江玲 | 3222004466 |
PSP表格
| PSP | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 30 | 30 |
| 估计这个任务需要多少时间 | 930 | 1170 |
| 开发 | 840 | 1080 |
| 需求分析 | 120 | 120 |
| 生成设计文档 | 30 | 30 |
| 设计复审 | 30 | 30 |
| 代码规范 | 30 | 30 |
| 具体设计 | 180 | 210 |
| 具体编码 | 300 | 480 |
| 代码复审 | 30 | 60 |
| 测试 | 120 | 120 |
| 报告 | 90 | 90 |
| 测试报告 | 30 | 30 |
| 计算工作量 | 30 | 30 |
| 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 960 | 1200 |
效能分析
使用profile功能进行效能分析
· 生成一万题的效能分析
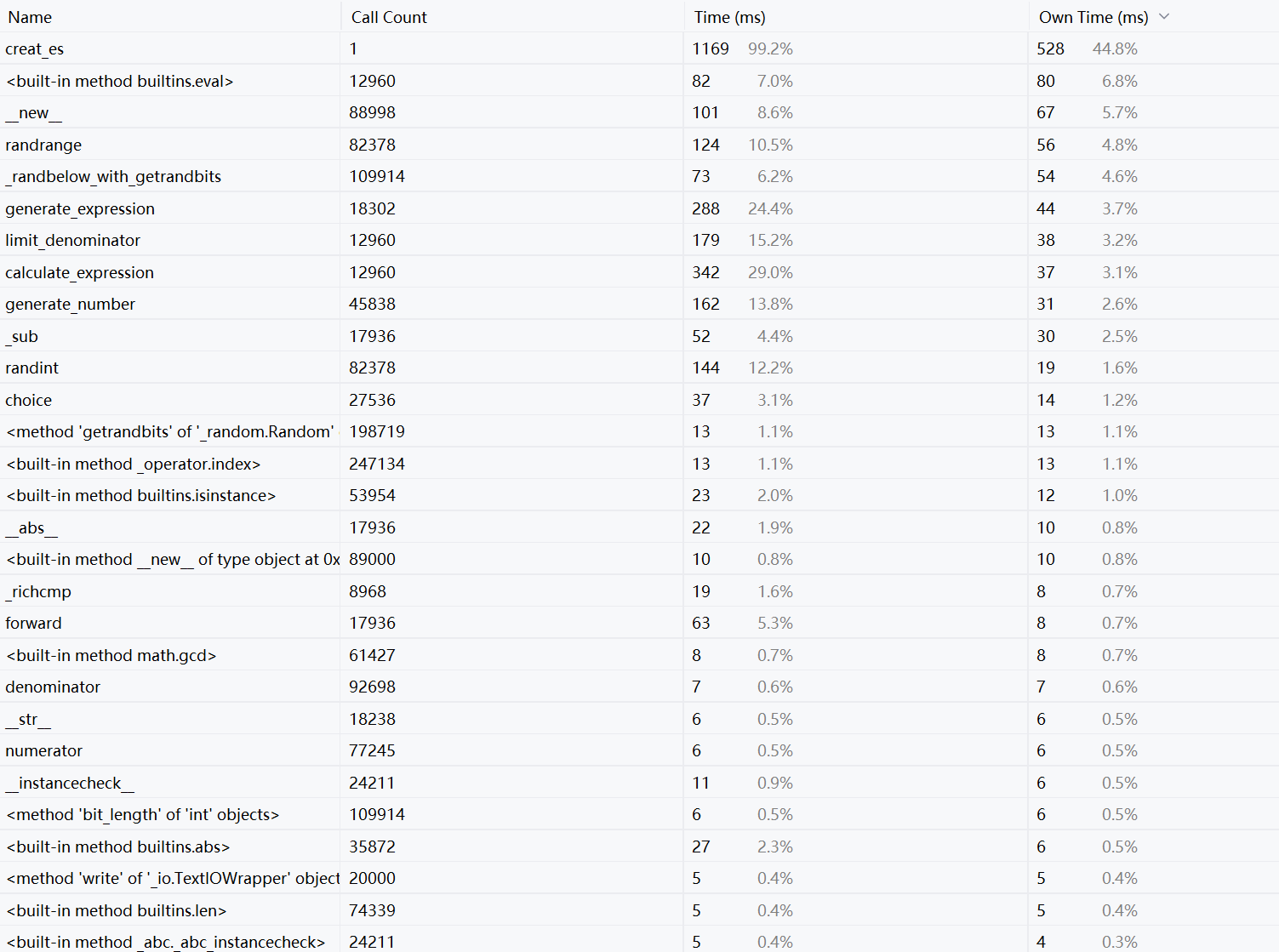
· 程序生成一万题花费时间最多的函数是creat_es,即创建表达式的函数。即代表消耗大的generate_expression和calculate_expression。在最开始进行设计时,曾出现无法生成大量题目的情形,如:生成200题耗时很长,不得不使用control+C中断运行,这反映出程序的不良设计,因此对生成表达式的函数进行了修改。
· 优化心得:优化对'*'和'/'号转化思路,在生成表达式选择符号时就使用'×'和'÷',计算时在替换为计算机能识别的运算符,这样可以减少判断除法运算符和分数除号步骤增加的时间(因为原本的设计还需要判断符号类型,加之使用正则表达式进行替换),优化后也能成功生成一万道题目,同时时间也比较满意,耗时最长的函数也只耗时了1169ms。
· 评分一万题的效能分析
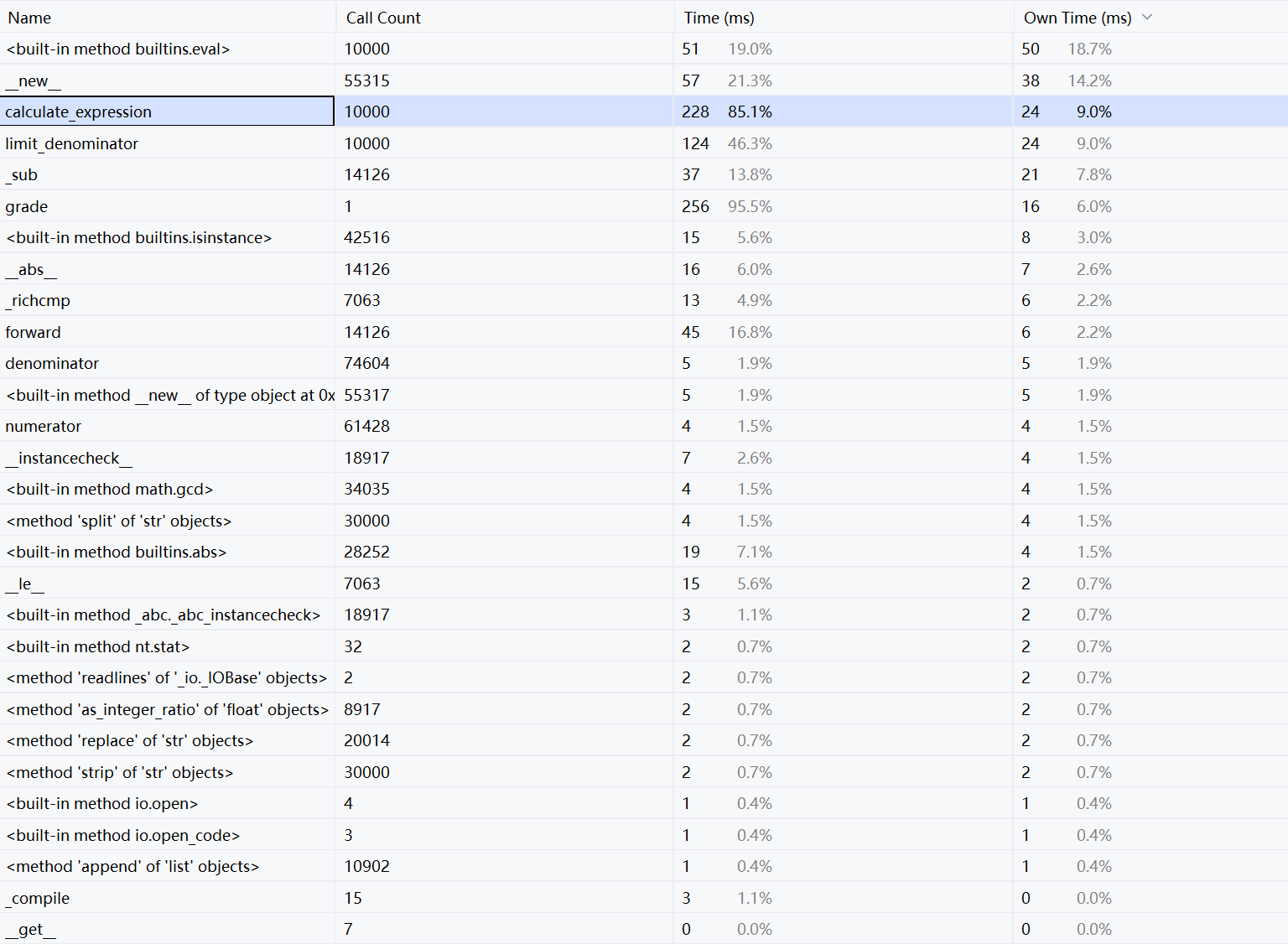
· 评分一万题花费最多时间的函数是计算表达式的函数calculate_expression
设计实现过程
设计包括六个函数,分别为generate_number、generate_expression、calculate_expression、creat_es、grade和main。generate_number用于生成随机数;generate_expression用于生成四则运算表达式;calculate_expression用于计算表达式的值;creat_es用于生成表达式文件和答案文件;main作为程序的入口,调用各个函数。

代码说明
生成四则运算表达式
# 生成四则运算表达式
def generate_expression(max_value, max_operators):
# 定义一个列表,包含四则运算符。
operators = ['+', '-', '×', '÷']
# 初始化一个空字符串,用于构建算术表达式。
expression = ""
# 随机选择一个运算符的数量,这个数量不会超过max_operators。
num_operators = random.randint(2, max_operators)
# 循环num_operators次,每次循环都向表达式中添加一个运算符和一个数值(整数或分数)。
for i in range(num_operators):
# 如果不是第一个运算符,在运算符前添加一个空格。
if i > 0:
expression += " " + random.choice(operators) + " "
expression += str(generate_number(max_value))
# 返回构建好的算术表达式。
return expression
计算表达式的值
# 计算表达式的值
def calculate_expression(expression):
try:
# 使用eval函数计算表达式的值
result = eval(expression.replace('÷', '/').replace('×', '*'))
# 将结果转换为分数
fraction_result = fractions.Fraction(result).limit_denominator()
# 将分数转换为字符串
if fraction_result.denominator == 1:
# 如果分母为1,则结果为整数
return str(fraction_result.numerator)
else:
# 如果分子大于分母,则转换为带分数形式
if fraction_result.numerator >= fraction_result.denominator:
whole_number = fraction_result.numerator // fraction_result.denominator
remainder = fraction_result.numerator % fraction_result.denominator
if remainder == 0:
# 如果没有余数,则只返回整数部分
return str(whole_number)
else:
# 如果有余数,则返回带分数形式
return f"{whole_number}'{remainder}/{fraction_result.denominator}"
else:
# 如果是真分数,则直接返回分数形式
return f"{fraction_result.numerator}/{fraction_result.denominator}"
# 如果在计算过程中出现除以零的错误(ZeroDivisionError)
# 捕获这个异常,并返回字符串"Error"
except ZeroDivisionError:
return "Error"
评分
# 评分
def grade(args):
# 打开题目文件和答案文件进行读取
with open(args.e, 'r') as ef, open(args.a, 'r') as af:
# 读取题目和答案文件中的所有行
exercises = ef.readlines()
answers = af.readlines()
# 初始化两个列表,分别用于存储正确和错误的题目编号
correct = []
wrong = []
# 遍历题目和答案的每一对,并使用enumerate来跟踪编号
for i, (exercise, answer) in enumerate(zip(exercises, answers), 1):
# 去除题目和答案的编号
exercise = exercise.split(".", 1)
exercise = exercise[1].strip()
# 去除题目的‘=’号
exercise = exercise.split('=')[0].strip()
answer = answer.split(".", 1)
answer = answer[1].strip()
# 如果计算出的题目结果等于答案文件中的答案,则标记为正确
if calculate_expression(exercise) == answer:
correct.append(i)
else:
# 否则标记为错误
wrong.append(i)
# 打开Grade.txt文件进行写入
with open('Grade.txt', 'w') as gf:
# 写入正确题目的数量和编号
gf.write(f"Correct: {len(correct)} ({', '.join(map(str, correct))})\n")
# 写入错误题目的数量和编号
gf.write(f"Wrong: {len(wrong)} ({', '.join(map(str, wrong))})")
测试运行
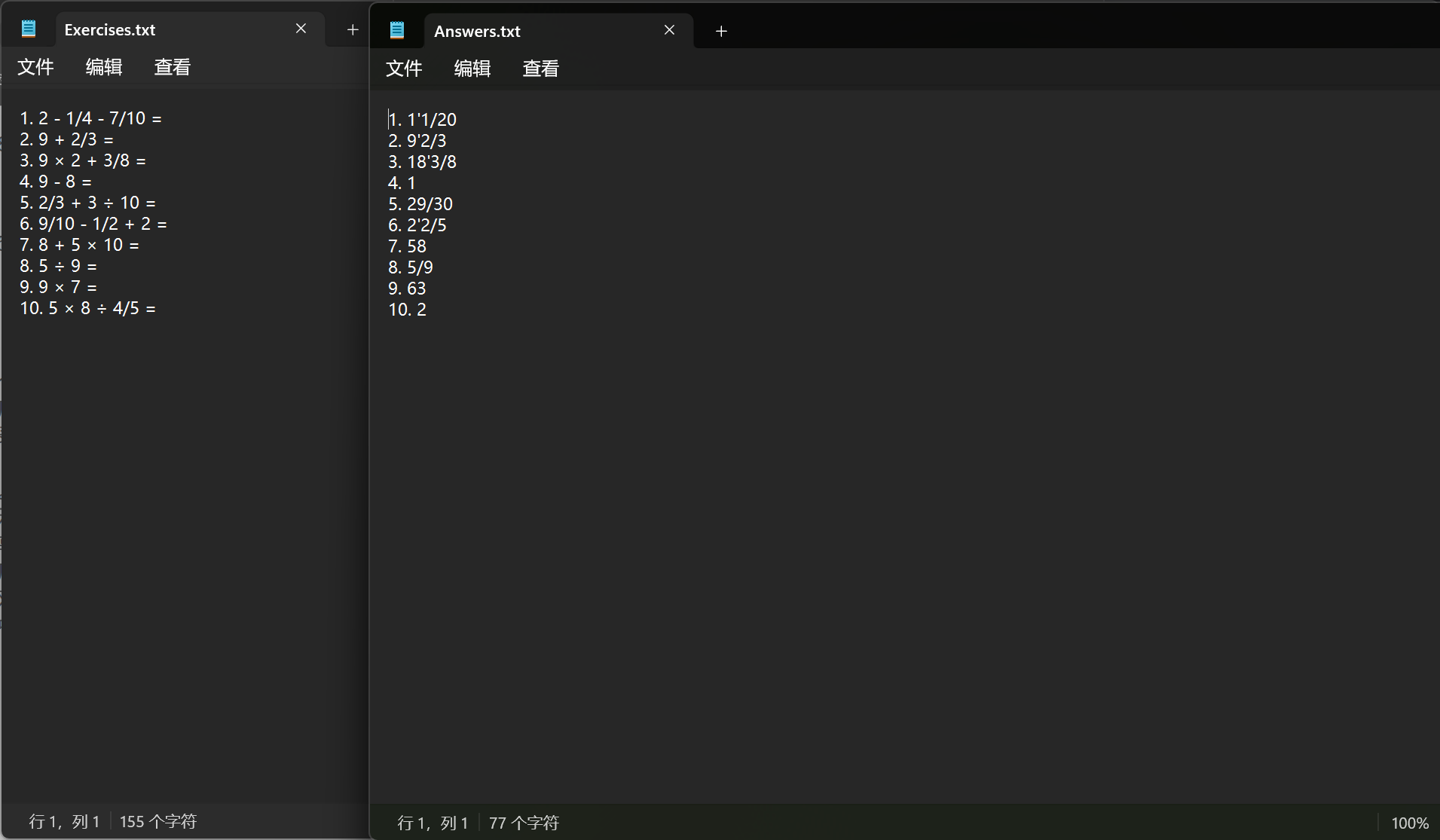
· 生成表达式功能
在命令行输入python Myapp.py -n 10 -r 10 命令,得到Exercises.txt和Answers.txt两个文件
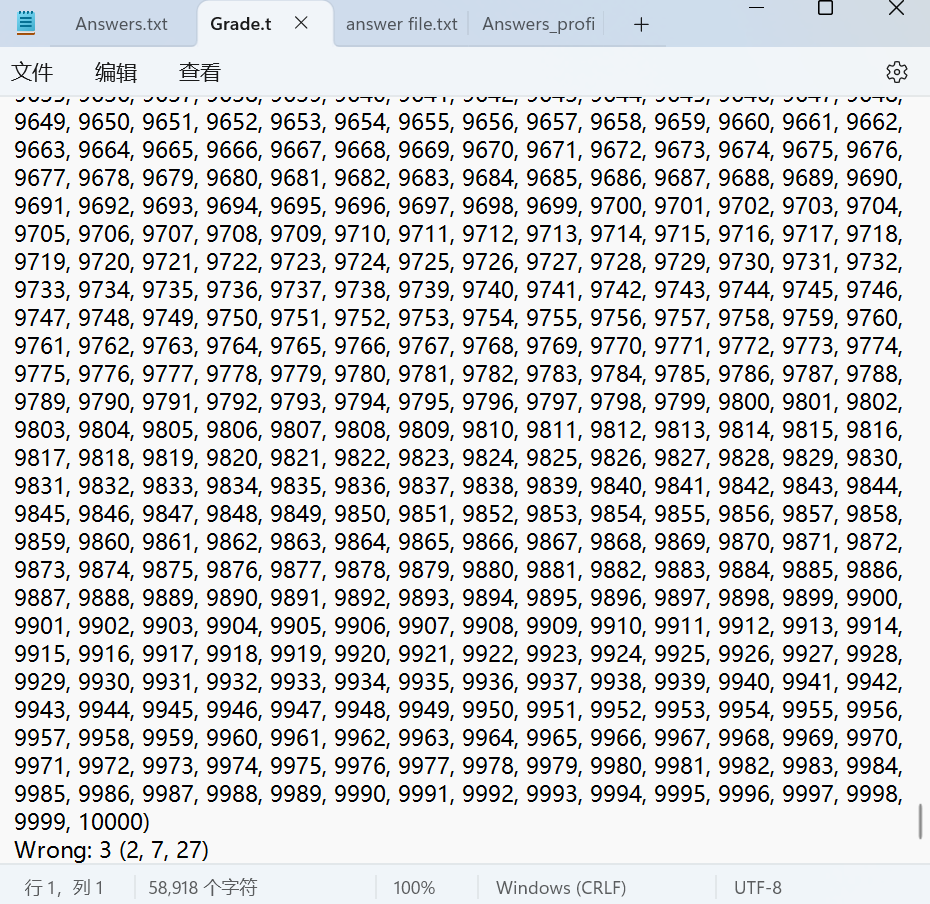
· 生成一万题功能测试

· 批改一万题测试
对2、7、27共3题进行错误作答,得到批改效果正确
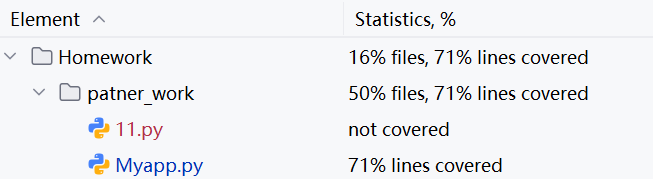
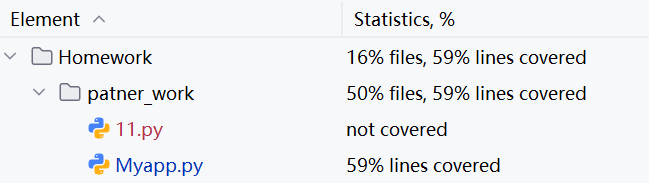
· 测试覆盖率
生成一万题
批改一万题
项目小结
在合作开发算术练习生成器项目中,我们成功实现了代码的模块化设计,提高了代码的可读性和可维护性。过程中也遇到了很多困难,但通过明确分工,积极学习,我们确保了项目的高效推进。最终,我们按时完成了所有功能,并进行了测试,最大程度保证了确保程序的稳定性和准确性。结对也让我们体会到了协作的魅力,通过明确的分工和工作过程中及时的沟通和交流,我们顺利完成了项目。
