

第一次个人编程作业
| 这个作业属于哪个课程 | 计科22级12班 |
|---|---|
| 这个作业要求在哪 | 作业要求 |
| 这个作业的目标 | 完成一次个人开发流程,学会开发、测试和在Github上管理 |
一、项目需求
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
要求输入输出采用文件输入输出,规范如下:
·从命令行参数给出:论文原文的文件的绝对路径
·从命令行参数给出:抄袭版论文的文件的绝对路
·从命令行参数给出:输出的答案文件的绝对路径
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 10 |
| Estimate | 估计这个任务需要多少时间 | 5 | 10 |
| Development | 开发 | 170 | 310 |
| Analysis | 需求分析 | 30 | 15 |
| Design Spec | 生成设计文档 | 20 | 10 |
| Design Review | 设计复审 | 10 | 30 |
| Coding Standard | 代码规范 | 10 | 15 |
| Design | 具体设计 | 20 | 60 |
| Coding | 具体编码 | 40 | 70 |
| Code Review | 代码复审 | 20 | 60 |
| Test | 测试 | 20 | 60 |
| Reporting | 报告 | 35 | 50 |
| Test report | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 5 | 10 |
| Postmortem & Progress Improvement Plan | 事后总结,并提出过程改进意见 | 10 | 10 |
| 合计 | 210 | 370 |
远远不止,很多时候没有计时。。。
三、算法设计
· 代码环境
Python 3.11
jieba==0.42.1
transformers==4.44.2
由requirements.txt给出
-
设计思路
· 读取文件:使用read_file函数读取原文文件和抄袭版论文文件的内容。
· 文本预处理:在calculate_similarity函数中,首先对读取的文本进行清洗,移除标点符号和换行符,以便于后续处理。
· 中文分词:使用jieba库对清洗后的文本进行中文分词。jieba是一个广泛使用的中文分词工具,能够将中文句子切分成词语列表。
· 计算相似度:提取两个文本的交集:找出原文和抄袭版论文中共同的词语。使用了difflib.SequenceMatcher来计算两个文本字符串之间的相似度,并且通过ratio()方法获取了相似度比例。然后使用round()函数将结果四舍五入到小数点后两位。
· 输出结果:将计算出的相似度转换为百分比形式,并使用write_result函数将结果写入到指定的输出文件中。 -
组织关系
主函数(main):负责程序流程的控制。
· 检查命令行参数的个数是否正确。
· 检查提供的文件路径是否存在。
· 调用read_file函数读取文件内容。
· 调用calculate_similarity函数计算相似度。
· 调用write_result函数将结果写入文件。 -
设计关键点
· 文本清洗:通过移除标点符号和换行符,减少了文本噪声,使得分词结果更加准确。
· 分词:中文文本需要分词处理,因为中文词语之间没有空格分隔。
· 相似度计算:通过difflib.SequenceMatcher来估计文本的相似度,这是一个简单有效的方法。 -
可供改进之处
这个设计思路是一个基础的实现,可能无法处理复杂的文本相似度问题。在实际应用中,可能需要考虑更多的因素,如文本的结构、语义、上下文等,必要时可能需要引入人工智能模型或者优化相似度算法
四、性能分析
· 性能分析图--使用Pycharm Profile
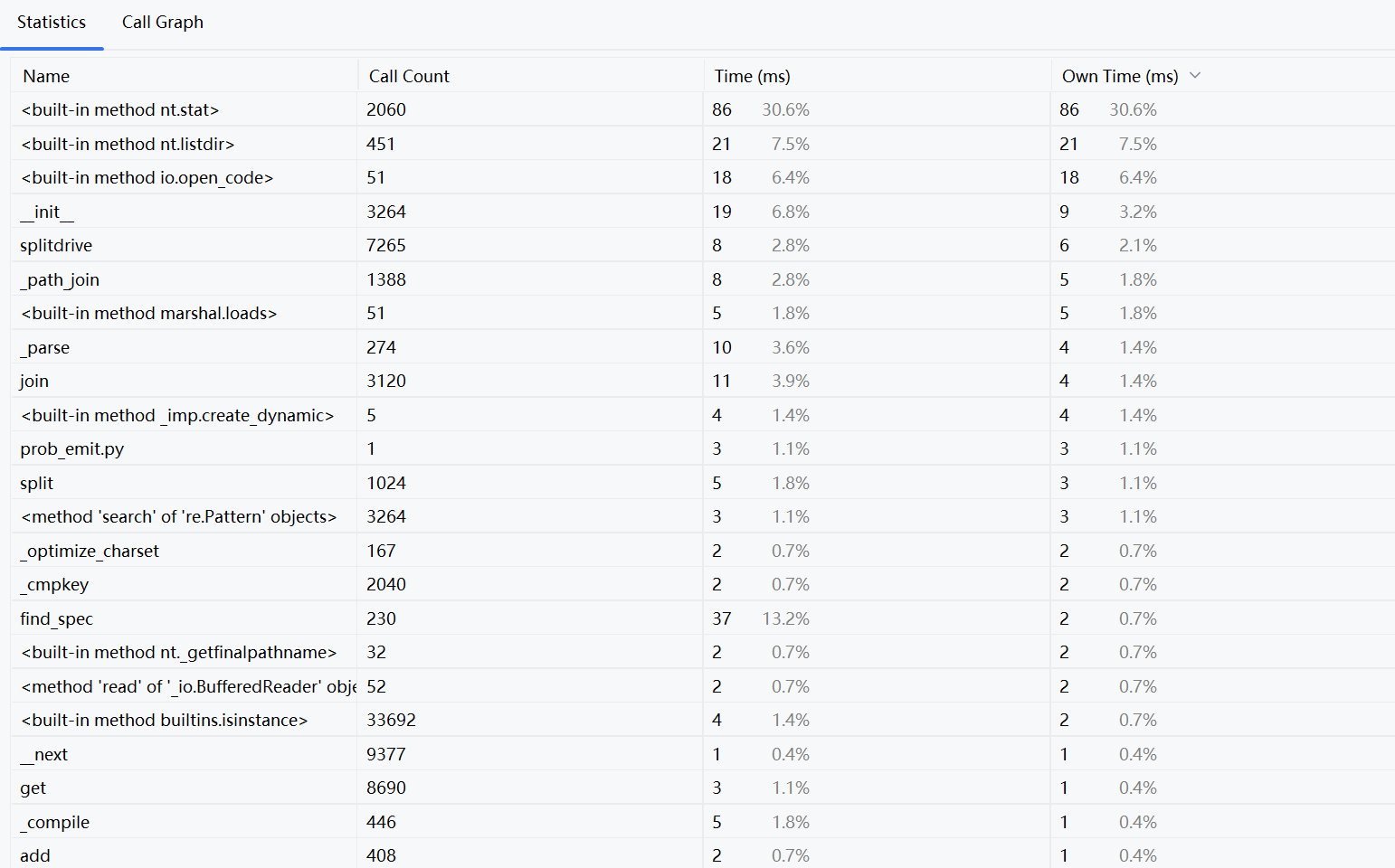
· 性能分析图列出了不同函数或方法在程序中的调用次数、所花费的总时间(Time)以及它们自身的执行时间(Own Time)。
· built-in method nt.stat是最耗时的操作,占据了超过 30% 的总运行时间,且其自身执行也占用了相同比例的时间。
它是Python内置的函数,用于获取文件或目录的详细信息。它通常用于检查文件或目录的属性,如创建时间、修改时间、大小等。
五、单元测试
- 命令行运行功能
· 在控制台输入命令,测试程序是否正常运行。

· 运行结果

- 单元测试
· 单元测试是软件开发中的重要组成部分,它有助于验证代码的正确性、稳定性和可维护性。Python提供了内置的unittest模块,用于编写和执行单元测试。
· 单元测试代码展示
import subprocess
import unittest
from main import calculate_similarity
class MyTestCase(unittest.TestCase):
#普通情况
def test_common(self):
self.assertGreater(calculate_similarity('他是一个聪明的人,总能迅速解决问题。',
'她是一个聪明的人,总能迅速解决问题。'), 0.9)
· 测试情况
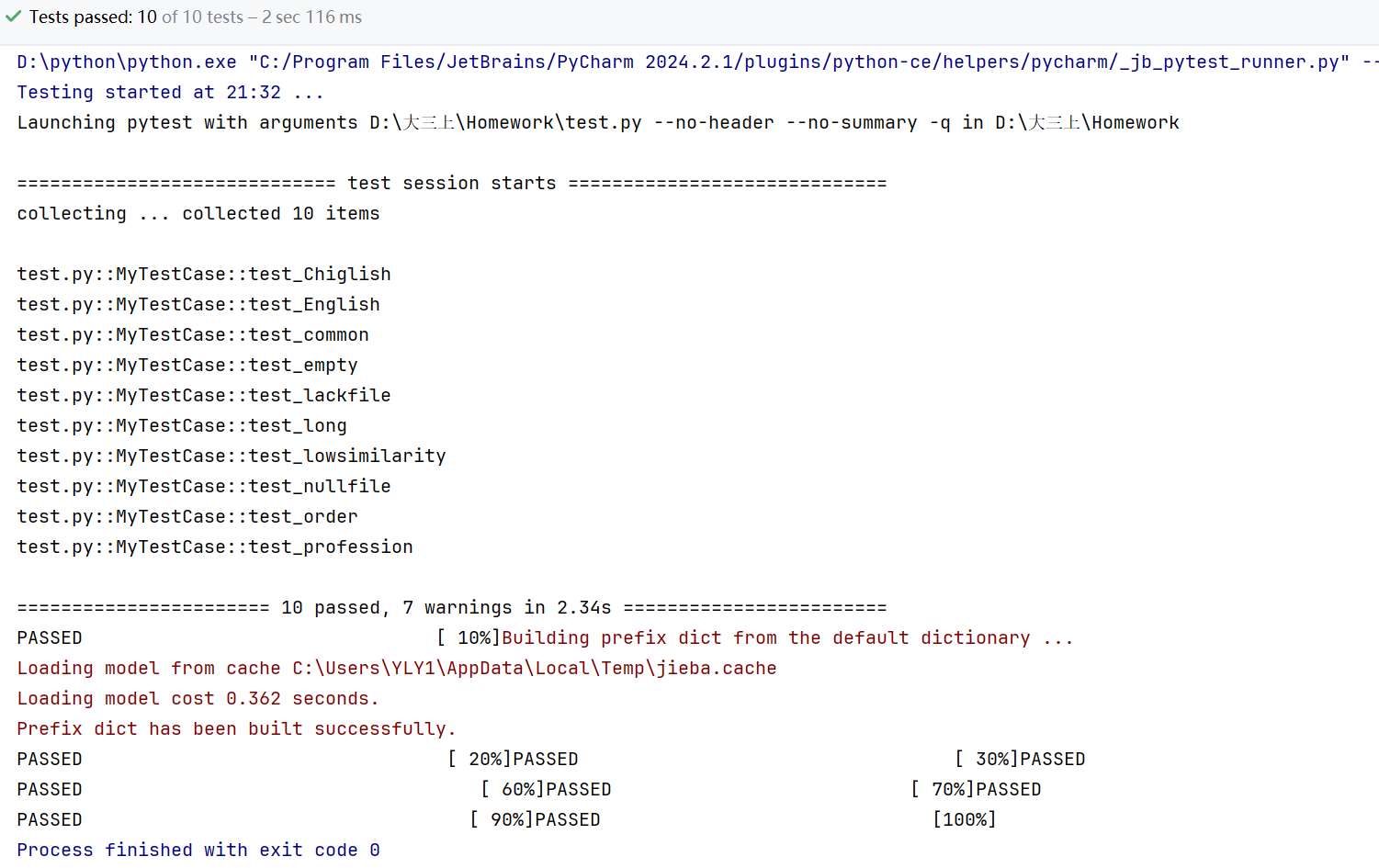
· 测试函数选择和测试数据
self.assertGreater:测试相似度是否大于给定数值:针对给定文本的测试数据,如:普通文本、专业术语、低相似度文本、长文本、英语文本、中英结合文本等。
self.assertEqual:测试相似度是否等于给定数值:针对具有明确的相似度的文本,如:其中一个文本为空白、文本仅调整有语序不同
#空白输入
def test_empty(self):
self.assertEqual(calculate_similarity('我很好。', ''), 0)
· 针对异常的单元测试
针对异常的测试分布在测试输入的文件路径错误、输入命令时缺少参数,将在六、异常处理中详细解释。
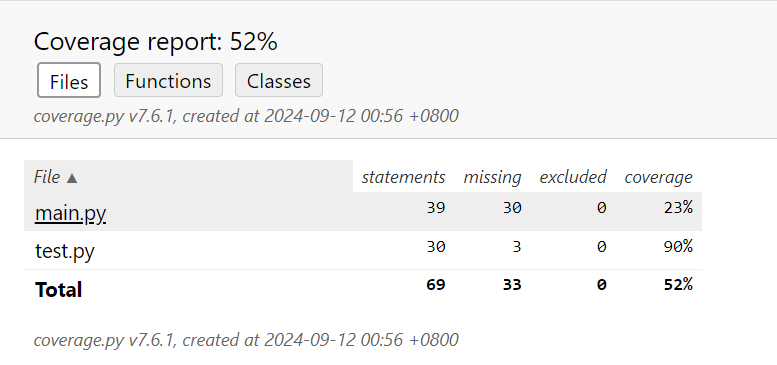
- 测试覆盖率
使用coverage查看测试覆盖率,可以看到test.py测试文件的测试覆盖率达到90%
六、异常处理
- 缺少命令行参数
· 测试
#缺少文件路径
def test_lackfile(self):
result = subprocess.run(
['python', 'D:\大三上\Homework\main.py', '--param1', 'D:\大三上\\ruangong_test\original.txt',
'--param2',
'--param3', 'D:\大三上\\ruangong_test\similarity.txt'
], stdout=subprocess.PIPE)
stdout = result.stdout.decode
print(stdout)
· 程序处理
#读取文件
if len(sys.argv) != 4:
for arg in sys.argv:
print(arg)
print("Usage: python script.py <path_to_original> <path_to_original_add> <path_to_result>")
sys.exit(1)
- 读取的文件不存在
· 测试
#文件路径错误
def test_nullfile(self):
result = subprocess.run(
['python', 'D:\大三上\Homework\main.py', '--param1', 'D:\大三上\\ruangong_test\original.txt',
'--param2','D:\大三上\\ruangong_test\original_add1.txt',
'--param3', 'D:\大三上\\ruangong_test\similarity.txt'
], stdout=subprocess.PIPE)
stdout = result.stdout.decode
print(stdout)
· 程序处理
original_path = sys.argv[1]
original_add_path = sys.argv[2]
result_path = sys.argv[3]
if not os.path.isfile(original_path) or not os.path.isfile(original_add_path) or not os.path.isfile(result_path):
print("Error: One of the provided file paths does not exist.")
sys.exit(1)
