《深入理解JVM》第12章 Java内存模型与线程
第12章 Java内存模型与线程
12.3 Java内存模型
Java内存模型(JMM Java Memory Model):屏蔽掉各种硬件和操作系统的内存访问差异,以实现Java程序在各个平台下都能达到一致的内存访问效果。
(在此之前,C/C++直接使用物理硬件和操作系统的内存模型,会由于不同平台上内存模型的差异,导致程序在以套平台上并发完全正常,到另一平台上并发访问经常出错。)
经过长时间验证和修补,JDK1.5(实现了JSR-133)发布后,Java内存模型成熟和完善起来。
JSR-133:Java Memory Model and Thread Specification Revision Java内存模型和线程规范修订。
https://download.oracle.com/otndocs/jcp/memory_model-1.0-pfd-spec-oth-JSpec/
主内存和工作内存
Java内存模型规定了所有的变量都存储在主内存里。
每条线程有自己的工作内存,线程的工作内存保存了被该线程使用到的变量的主内存副本的拷贝。
线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量。
不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存完成。
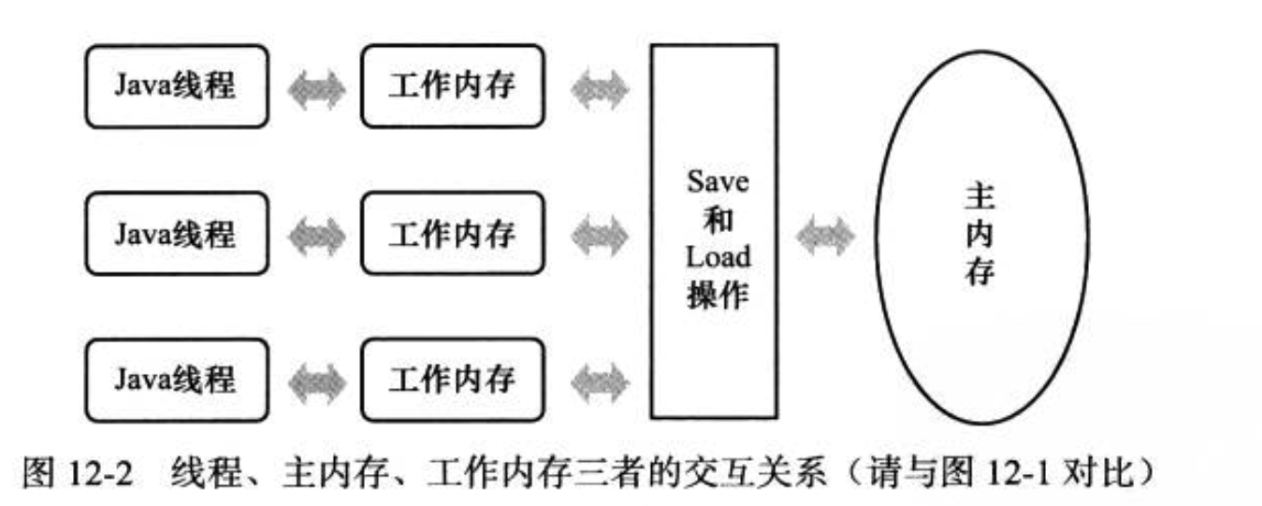
主内存和工作内存之间的交互协议
交互协议:一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存
Java内存模型定义了以下8种操作,虚拟机实现时需要保证每个操作都是原子的、不可再分的。
-
lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占的状态。
-
unclock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
-
read(读取):作用于主内存的变量,把一个变量的值从主内存传输到线程的工作内存,以便随后的load动作使用。
-
load(载入):作用于工作内存的变量,把read操作从主内存中得到的变量值放入工作内存的变量副本中。
-
use(使用):作用于工作内存的变量,把工作内存中一个变量的值传递给执行引擎。
-
assign(赋值):作用于工作内存的变量,把执行引擎接收到的值赋给工作内存的变量。
-
store(存储):作用于工作内存的变量,把工作内存中一个变量的值传送给主内存中,以便随后的write操作使用。
-
write(写入):作用于主内存的变量,把store操作从工作内存中得到的变量的值放入主内存的变量中。
操作的规定
-
不允许read和load、store和write操作之一单独出现,即不允许一个变量从主内存中读取了但工作内存不接受,或者工作内存发起了回写但主内存不接受的情况出现。
-
不允许一个线程丢弃它的最近的assign操作,即变量在工作内存中改变了之后必须把该变化同步到主内存。
-
不允许一个线程无原因地(没有发生任何assign操作)把数据从线程的工作内存同步到主内存。
-
一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量,换句话说,就是对一个变量use、store操作之前,必须先执行过了assign和load操作。
-
一个变量在同一时刻只允许一个线程对其进行lock操作,但lock操作可以被同一条线程重复执行多次,多次执行lock后,只有执行相同次数的unclock操作,变量才会被解锁。
-
如果对一个变量执行lock操作,那么会清空工作内存次变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值。
-
如果对一个变量执行lock操作,那么会清空工作内存次变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值。
-
对一个变量执行unclock之前,必须先把此变量同步回主内存中(执行store、write操作)
这8中内存操作及上述规定,加上对volatile的特殊规定,完全确定了Java程序中哪些内存操作在并发下是安全的。
(最新的JSR-133文档,已经放弃采用这8种操作去定义Java内存模型访问协议了。
后面会介绍等效判断原则——先行发生原则,来确定一个访问在并发环境下是否安全。
)
1)对于volatile型变量的特殊规则
volatile的内存语义
1)保证可见性
对于volatile变量,当一个线程修改了这个变量的值,其他线程可以立刻得知新值
2)禁止指令重排序优化
Map configOptions; //此变量必须定义为volatile volatile boolean initialized = false;
下面代码在线程A中执行,解析配置信息,解析配置后,将initialized设为true,通知其他线程
configOptions = processConfigOptions(); initialized = true;
下面代码在线程B中执行,等待nitialized设为true,对配置信息进行操作。
while (!initialized) { sleep(); } doSomethingWithConfig();
如果nitialized变量不用volatile进行修饰,可能会由于重排序优化,导致线程A中initialized=true被提前执行,导致程序错误。
(重排序优化是机器级的优化,在此提前执行值对应的汇编代码被提前执行)
线程A initialized=true 线程B while (!initialized) { sleep(); } doSomethingWithConfig(); 线程A configOptions = processConfigOptions();
如何禁止执行重排序的?会插入一些内存屏障汇编机器指令,使重排序时无法将指令重排序到内存屏障之前或之后的位置。
volatile变量的注意点
volatile只能保证可见性,在以下场景中,需要使用锁(synchronized 或 juc包中的原子类)来保证原子性。
1)运算结果依赖变量的当前值
2)变量需要与其他的状态变量来共同构成不变性约束
运行20个线程,每个线程对race变量进行10000次自增操作。
如果正确并发的话,结果应该为200,000。
但是运行可以发现,每次输出结果都是一个小于200,000的值。
public class VolatileTest { public static volatile int race = 0; public static void increase() { race++; } private static final int THREAD_COUNT = 20; public static void main(String[] args) { Thread[] threads = new Thread[THREAD_COUNT]; for (int i = 0; i < THREAD_COUNT; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 10000; i++) { increase(); } } }); threads[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); } System.out.println(race); } }
volatile的正确使用场景
用于结束线程
volatile boolean stop; public void shutdown() { stop = true; } public void doWork() { while (!stop) { // do stuff } }
2)对于long和double型变量的特殊规则
Java内存模型允许没有被volatile修饰的64位数据(long和double)划分为两次32位操作。
目前,商用虚拟机都选择把64位数据的读写作为原子操作看待,因此,写代码时,不需要专门将long和double声明为volatile。
原子性、可见性、有序性
Java内存模型是围绕并发过程中如何处理原子性、可见性和有序性这3个特征来建立的。
哪些操作实现了这3个特征那?
原子性:
1)对于基本数据类型的访问读写是具备原子性的。
2)synchronized块之间操作是原子性的(通过monitorenter和monitorexit两条指令)。
可见性:
可见性指当一个线程修改了共享变量的值,其他线程能够立即得知到。
Java内存模型是通过在变量修改后将新值同步回主内存,在变量读取前从主内存刷新变量值来实现可见性的。
1)volatile保证可见性:保证新值能够立即同步到主内存,每次使用前从主内存刷新。
2)synchronized同步块保证可见性:对一个变量unlock之前,必须先把此变量同步回主内存
3)final保证可见性:被final修饰的字段在构造器中一但初始化完成,并且构造器没有把”this“引用传递出去,那其他线程就能够看到final字段的值。
有序性:
如果在本线程内观察,所有的操作都是有序的
(线程内表现为串行的语义:方法执行过程中所有依赖赋值结果的地方都能获取到正确的结果,但不保证变量赋值操作的顺序与程序代码中的顺序一致)
如果在一个线程观察另一个线程,所有的操作都是无序的
("指令重排序"现象 和 ”工作内存与主内存同步延迟“现象)。
1)volatile关键字通过禁止指令重排序的语义保证线程之间操作的有序性
2)synchronized通过”一个变量在同一个时刻只运行一个线程对其进行lock操作“这条规则,保证持有同一个锁的两个同步块只能串行进入
先行发生原则(happens-before)
先行发生原则指的是什么?
如果操作A先行发生于B,那么在发生操作B之前,操作A产生的影响能够被B观察到,影响包括修改了内存中共享变量的值、调用了方法等。
举例
//线程A中执行 i = 1; //线程B中执行 j = i;
假设线程A中的操作i=1先行发生于线程B中的j=i。
可以断定线程B操作执行后,变量j一定等于1。
//线程A中执行 i = 1; //线程B中执行 j = i; //线程C中执行 i = 2;
加入线程C后,线程C操作在线程A和B操作之间,但线程C与B没有先行发生关系。
变量j的值将不确定,可能为1也可能为2。因为线程C对变量i的影响可能被线程观察到,也可能不会。这导致了线程安全问题。
先行发生原则可以用来做什么那?
可以用于判断数据是否存在竞争、线程是否安全。
Java内存模型下有以下天然的先行发生关系,无须任何同步协助就已经存在。
如果两个操作之间的关系不在此列,且无法根据下列规则推到出来,它们就没有顺序性保障,虚拟机可对他们随意重排序。
-
程序次序规则:在一个线程内,按照程序代码顺序,书写在前面的操作先行发生于书写在后面的操作。
-
管程锁定规则:对于同一个锁的unlock操作先行发生于后面的lock操作。”后面“指时间上的先后顺序。
-
volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个变量的读操作。”后面“指时间上的先后顺序
-
线程启动规则:Thread对象的start()方法先行发生于此线程的每一个动作。
-
线程终止规则:线程中的所有操作都先行发生于对此线程的终止检测。可通过Thread.join()方法结束、Thread.isAlive()的返回值等手段判断线程已经终止运行。
-
线程中断规则:对线程的interrupt()方法的调用先行发生于检测到中断事件的发生。可以通过Thread.interrupted()方法检测是否有中断发生
-
对象终结规则:一个对象的处理化完成(构造函数执行结束)先行发生于它的finalize()方法的开始
-
传递性:操作A先行发生于B,操作B先行发生于C,则操作A先行发生于操作C。
用先行发生原则判断是否线程安全的一个例子。
private int value = 0; //线程A先执行setValue(10) (时间上的先后) public void setValue(int value) { this.value = value; } //线程B后执行getValue() public int getValue() { return value; }
线程B收到的返回值是什么?
上述所有先行发生原则都不适用。
因此,尽管线程A在操作上先于线程B,但无法确定线程B中getValue()的返回结果。
(一个操作”时间上先行发生“不代表这个操作是”先行发生”)
如何修复?
方法1:get/set方法用synchronized修饰 管程锁定规则
方法2:声明为volatile类型 volatile变量规则
(一个操作“先行发生”也不代表这个操作“时间上先行发生”)
//在同一个线程中执行 int i = 1; int j = 2;
两个语句在同一个线程中执行,依据程序次序规则,int i = 1先行发生于int j = 2,但是由于执行重排序,int j = 2可能先被处理器执行。
总结:时间先后顺序与先行发生顺序之间没必然关系。判定线程并发安全问题时应不受时间顺序的干扰,以先行发生原则为准。
12.4 Java与线程
12.4.1 线程的实现
实现线程的3种方式
1.使用内核线程实现
内核线程(Kernel-Level Thread,KLT):直接由操作系统内核支持,由内核进行线程调度,并映射到各个处理器上。
程序中一般不直接使用内核线程,而是使用内核线程的高级接口——轻量级进程(Light Weight Process, LWP),即我们通常讲的线程。
轻量级进程与内核线程之间为1:1的关系称为【1对1的线程模型】。
局限性
1)基于内核线程实现,各种线程操作(如创建、销毁)都需要进行系统调用,在用户态和内核态之间切换,代价较高。
2)每个轻量级线程需要一个内核线程支持,需要消耗一定的内核资源(如内核线程的栈空间),因此系统支持的轻量级进程的数量有限
2. 使用用户线程实现
用户线程:完全建立在用户空间的线程库上,系统内核感知不到线程的存在,线程的创建、销毁、同步等完全在用户态完成。
进程与用户线程之间1:N的关系称为【1对多的线程模型】。
优势
1)线程创建、销毁等操作不需要切换到内核态,快且低消耗
2)支持更多的线程数量
劣势
所有的线程操作(创建、销毁)等都需要用户程序自己处理(用户程序依赖线程库,因此主要是线程库的实现需要处理这些问题)
而诸如”阻塞如何处理“”多处理器中如何将线程映射到其他处理器上“等问题解决起来较困难,甚至不可能完成。
目前,使用用户线程的程序越来越少了。
3.使用用户线程加轻量级进程混合实现
用户线程完全建立在用户空间中,因此线程的创建、销毁等操作依赖廉价,并可支持较大规模的线程数量。
轻量级进程作为用户线程和内核线程之间的桥梁,从而可以使用内核使用的线程调度和处理器映射功能。
用户线程和轻量级进程之间的数据量比是不定的,即N:M的关系,称为【多对多的线程模型】。
许多UNIX系列操作系统,都提供N:M线程模型实现。
12.4.2Java线程的实现
线程模型基于操作系统原生的线程模型实现,操作系统支持怎样的线程模型,很大程度上决定了Java虚拟机的线程模型。
这点在不同平台上没办法达成一致,虚拟机规范也未线程使用哪种线程模型来实现。
在Windows 、 Linux上都是一对一的线程模型,一条线程就映射到一条轻量级线程。
在Solaris平台,操作系统支持一对一及多对多线程模型,因此可通过指定虚拟机参数来指定要用哪种线程模型。
12.4.2Java线程调度
线程调度指系统为线程分配处理器使用权的过程。
线程调度方式有两种,分别是协同式调度、抢占式调度。
|
调度方式 |
说明 |
特点 |
|---|---|---|
|
协同式调度 |
线程的执行时间有线程本身控制,工作执行完后,主动通知系统切换到另一个线程上 |
好处:实现简单 坏处:线程执行时间不可控制。如果代码有问题,一直不告知系统进行线程切换,会导致进程阻塞 |
|
抢占式调度 |
线程的执行时间由系统来分配,线程切换由系统控制 |
好处:不会出现一个线程导致整个进程阻塞的情况 |
Java线程调度方式为抢占式调度。
关于线程优先级
虽然可通过将线程优先级调高使cpu分配更多的时间片,但是线程优先级不太靠谱。
Java线程映射到系统原生的线程上,线程调度最终那还是取决于操作系统。
12.4.3 Java线程状态转换
-
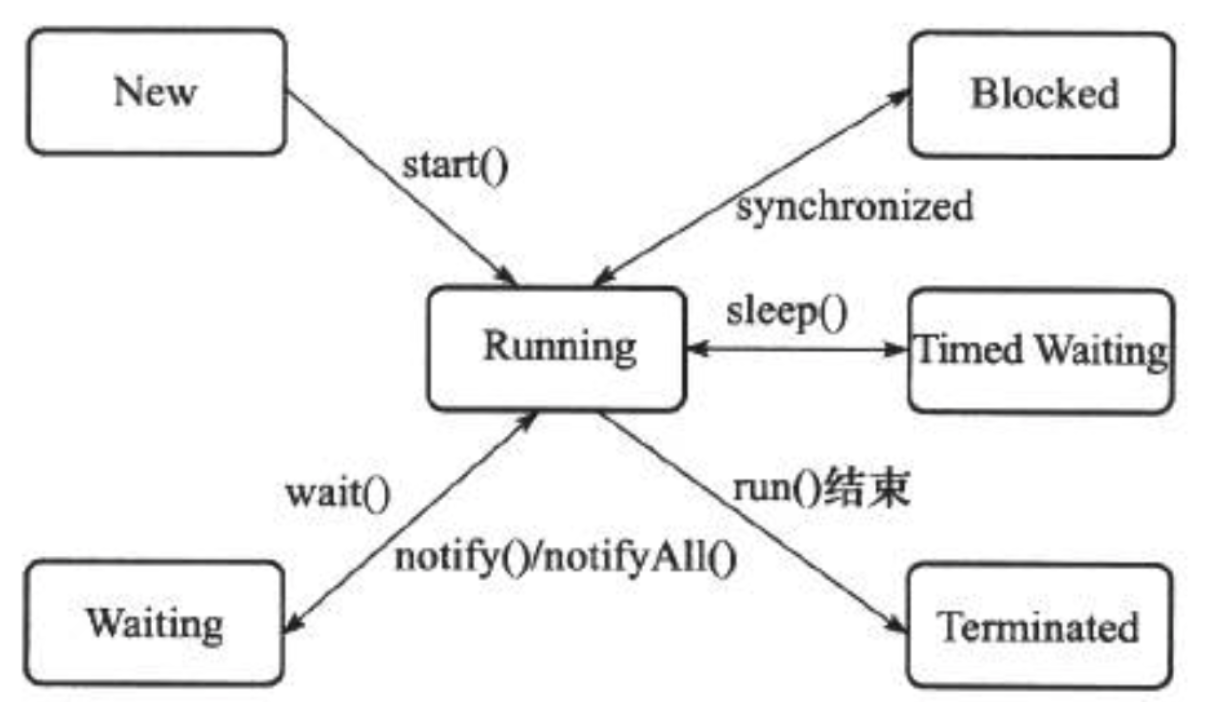
新建(New):创建后但尚未启动的线程处于这种状态。
-
运行(Runnable):包含了操作系统线程状态中的Running和Ready。线程有可能正在执行,也可能正在等待cpu为它分配时间片。
-
无限期等待(Waiting):不会被cpu分配时间片,等待被其他线程唤醒。以下方法会让线程进行无限期等待状态
1)没有设置Timeout参数的Object.wait()方法
2)没有设置Timeout参数的Thread.join()方法
3)LockSupport.park()方法
-
限期等待(Timed Waiting):不会被cpu分配时间片,在一段时间后由系统自动唤醒。
1)Thread.sleep()
2)设置了Timeout参数的Object.wait()方法
3)设置了Timeout参数额Thread.join()方法
4)LockSupport.parkNanos()
5) LockSupport.pardUntil()
-
阻塞(Blocked):线程被阻塞了,在线程等待进行临界区时,线程进入阻塞状态
阻塞状态与等待状态的区别
阻塞状态:等待获取一个排它锁
等待状态:等待一段时间 或者是 等待被唤醒
-
结束(Terminated):已终止的线程的状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号