Java集合类根接口:Collection 和 Map
前言
在前文中我们了解了几种常见的数据结构,这些数据结构有着各自的应用场景,并且被广泛的应用于编程语言中,其中,Java中的集合类就是基于这些数据结构为基础。
Java的集合类是一些非常实用的工具类,主要用于存储和装载数据 (包括对象),因此,Java的集合类也被成为容器。在Java中,所有的集合类都位于java.util包下,这些集合类主要是基于两个根接口派生而来,它们就是 Collection和 Map。
Collection接口
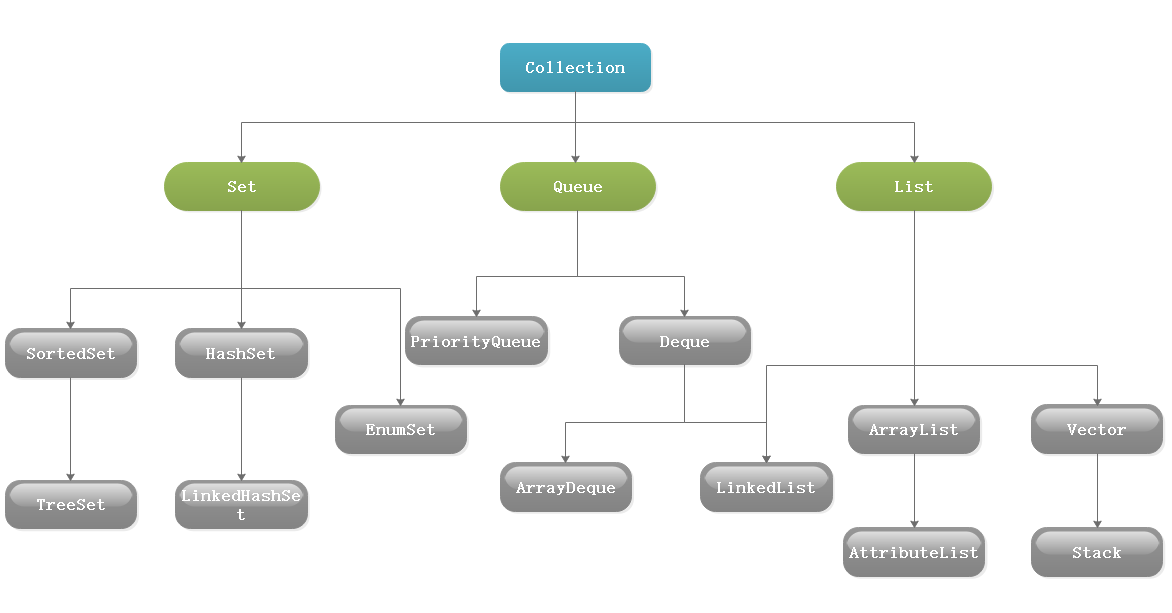
Collection派生出三个子接口,Set代表不可重复的无序集合、List代表可重复的有序集合、Queue是java提供的队列实现,通过它们不断的扩展出很多的集合类,例如HashMap、ArrayList、LinkedList、Deque等,其分布图如下:
作为最基本的两个根接口之一,Collection提供了很多的基础方法,供它的子类调用。下面是Collection接口的源码:
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object var1);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] var1);
boolean add(E var1);
boolean remove(Object var1);
boolean containsAll(Collection<?> var1);
boolean addAll(Collection<? extends E> var1);
boolean removeAll(Collection<?> var1);
default boolean removeIf(Predicate<? super E> var1) {
Objects.requireNonNull(var1);
boolean var2 = false;
Iterator var3 = this.iterator();
while(var3.hasNext()) {
if (var1.test(var3.next())) {
var3.remove();
var2 = true;
}
}
return var2;
}
boolean retainAll(Collection<?> var1);
void clear();
boolean equals(Object var1);
int hashCode();
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(this.spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(this.spliterator(), true);
}
}
从源码可以看出,里面有很多方法是针对集合的基础操作,例如添加,删除,查询。例如:
-
int size()获取元素个数 -
boolean isEmpty()是否个数为 0 -
boolean contains(Object element)是否包含指定元素 -
boolean add(E element)添加元素,成功时返回 true -
boolean remove(Object element)删除元素,成功时返回 true -
Iterator<E> iterator()获取迭代器
还有一些操作整个集合的方法:
boolean containsAll(Collection<?> c)
是否包含指定集合 c 的全部元素
boolean addAll(Collection<? extends E> c)
添加集合 c 中所有的元素到本集合中,如果集合有改变就返回 true
boolean removeAll(Collection<?> c)
删除本集合中和 c 集合中一致的元素,如果集合有改变就返回 true
boolean retainAll(Collection<?> c)
保留本集合中 c 集合中两者共有的,如果集合有改变就返回 true
void clear()
删除所有元素
值得说明的是,在jdk1.8之后,Collection 接口还提供了从集合获取连续的或者并行流的方法:
Stream<E> stream() 在这个集合上返回一个顺序流 ,单线程
Stream<E> parallelStream() 在这个集合上返回一个并行的代码流 ,多线程
Stream相当于高级版本的iterator,可以对集合做比较,分类,甚至是过滤等操作,一般是结合lambda表达式来使用,这样会使代码变得更加简洁 (有人说会更难理解,这个仁者见仁) ,下面举几个简单的例子:
1、使用顺序流来过滤掉集合中为 “aaa” 的元素并做输出:
List<String> list = Arrays.asList("aaa", "bbb", "ccc");
list.stream().filter(e -> !e.contains("aaa"))
.forEach(e -> System.out.println(e));
2、使用并行流来操作集合:
List<String> list = Arrays.asList("aaa", "bbb", "ccc");
list.parallelStream().filter(e -> !e.contains("aaa"))
.forEach(e -> System.out.println(e));
当使用顺序流去遍历时,每个item读完后再读下一个item。
而使用并行流去遍历时,集合会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出,所以理论上,并行流的效率至少是顺序流的两倍以上。
Map接口
Map接口是和Collection同等级的根接口,它表示一个键值对(key-value)的映射,每一个key对应一个value,查找Map中的数据,总是根据key来获取,所以key是不可重复的,它用于标识集合里的每项数据。跟Collection一样,Map接口派生了很多的集合子类,这是Map的体系架构图:

Map接口提供了很多集合的初识方法,其底层结构是封装一个名为entry的接口,源码如下:
public interface Entry<K, V> {
K getKey();
V getValue();
V setValue(V var1);
boolean equals(Object var1);
int hashCode();
static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K, V>> comparingByKey() {
return (Comparator)((Serializable)((var0x, var1x) -> {
return ((Comparable)var0x.getKey()).compareTo(var1x.getKey());
}));
}
static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K, V>> comparingByValue() {
return (Comparator)((Serializable)((var0x, var1x) -> {
return ((Comparable)var0x.getValue()).compareTo(var1x.getValue());
}));
}
static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> var0) {
Objects.requireNonNull(var0);
return (Comparator)((Serializable)((var1x, var2x) -> {
return var0.compare(var1x.getKey(), var2x.getKey());
}));
}
static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> var0) {
Objects.requireNonNull(var0);
return (Comparator)((Serializable)((var1x, var2x) -> {
return var0.compare(var1x.getValue(), var2x.getValue());
}));
}
}
从源码中可以看出,entry中封装了一系列设值和比较器,这也是Map实现类的元素操作的基础接口,一个entry就相当于一个封装了键值对的元素,是Map接口里的架构核心。
除此之外,Map中还提供了两个集合来操作自身,这就是 KeySet 和 Values。
Set<K> keySet();
Collection<V> values();
KeySet 是一个 Map 中 key 的集合,以 Set 的形式保存,不允许重复,因此键存储的对象需要重写 equals() 和 hashCode() 方法。
Values 是一个 Map 中 value 的集合,以 Collection 的形式保存,可以重复。
通过这三种视图,Map可以对自身结构以及内部元素做操作,在集合中非常常用,建议读者们可以多看看源码,作深入的了解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号