
Zookeeper——Watcher原理详解
文章目录
引言
Zookeeper引入了Watcher机制来实现分布式数据的发布/订阅功能,使得多个订阅者可以同时监听某一个主题对象,当主题对象自身状态发生改变时,就会通知所有订阅者。那么Zookeeper是如何实现Watcher的呢?要了解其中的原理,那必然只能通过分析源码才能明白。
正文
在分析源码前,我们首先需要思考几个问题:
- 如何注册绑定监听器?(哪些API可以绑定监听器)
- 哪些操作可以触发事件通知?
- 事件类型有哪些?
- Watcher可以被无限次触发么?为什么要这么设计?
- 客户端和服务端如何实现和管理Watcher?
一、如何注册监听
zookeeper只能通过以下几个API注册监听器:
- 通过构造器注册默认监听事件(在连接成功后会触发):
CountDownLatch countDownLatch = new CountDownLatch(1);
ZooKeeper zooKeeper = new ZooKeeper("192.168.0.106,192.168.0.108,192.168.0.109",
5000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("全局事件");
if (Event.KeeperState.SyncConnected.equals(event.getState())) {
countDownLatch.countDown();
}
}
});
countDownLatch.await();
- 通过exist()/getData()/getChildren()方法绑定事件,这三个方法可以绑定自定义watcher或者传入true绑定默认的监听器
// 传入true则是再次绑定默认的监听器,所有监听器只会被触发一次,除非再次绑定
Stat stat = zooKeeper.exists(NODE, true);
二、如何触发监听事件
Watcher注册好后,我们要如何去触发呢?也分为下述两种情况:
- 构造器绑定的默认监听器会在连接成功后触发,通常利用该方式来保证client端在操作节点时zookeeper已经连接成功,即上述实现
- 通过exists()/getData()/getChildren()绑定的事件,会监听到相应节点的变化事件,即setData()/delete()/create()操作。
三、事件类型有哪些
Zookeeper包含如下事件类型:
| EventType | 触发条件 |
|---|---|
| NodeCreated | Watcher监听的对应节点被创建 |
| NodeDeleted | Watcher监听的对应节点被删除 |
| NodeDataChanged | Watcher监听的对应节点数据内容发生改变 |
| NodeChildrenChanged | Watcher监听的对应节点的子节点发生变更(增、删、改) |
四、Watcher可以被无限次触发么?为什么要这么设计?
通过调用API,我们不难发现,每次注册绑定的Watcher都只会触发一次,而不是一直存在;至于为什么这么设计,也不难理解,如果Watcher一直存在,那么当某些节点更新非常频繁时,服务端就会不停地通知客户端,使得服务端压力非常的大,因此,如此设计是为了缓解服务端的压力。而对于需要一直保持监听的节点我们只需要嵌套注册监听器即可。如下:
zooKeeper.exists(NODE, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event.getType() + "->" + event.getPath());
try {
// 绑定的是自定义事件
zooKeeper.exists(event.getPath(), new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println(event.getType() + "->" + event.getPath());
}
});
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
五、Watcher实现原理
对于最后一个问题,我们就需要深入源码中寻求答案了,那么源码如何去看呢?这里我总结了几个方法:
- 找准入口,这里的入口就是Watcher的注册
- 不要太关注细节,从宏观角度把握整体流程,看源码主要学的是设计思想和优秀的命名规范
- 不要过度依赖debug调试,在不清楚整体的流程架构时,调试只会让我们陷入细节的陷阱中去(在关键步骤debug)
- 进入一个很长的实现方法时,先大体浏览下方法的实现,找到熟悉的步骤
- 判断语句决定流程走向,紧跟我们当前的流程,非当前流程的直接跳过不看,避免晕车
- 大胆猜测。比如当一个流程突然断掉,那极有可能就是一个异步处理或设计模式实现,根据变量名、方法名找到对应处理和接收的地方(优秀的源码命名都是极为规范和有规律的,后面我们就能看到Zookeeper在这方面的体现)。
- 最后一个就是一定熟练运用我的IDE快捷键和功能,可以节省很多时间。笔者使用的是IDEA,在后面的源码分析中会分享几个比较实用的快捷键。
下面就开始源码分析之旅吧!(PS:Zookeeper版本为3.4.8)
1. 客服端发送请求
a. 初始化客户端并绑定Watcher
Zookeeper的构造器是注册的是全局的默认Watcher。
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher,
boolean canBeReadOnly)
throws IOException
{
LOG.info("Initiating client connection, connectString=" + connectString
+ " sessionTimeout=" + sessionTimeout + " watcher=" + watcher);
// 构造器传入的Watcher会注册为全局默认的Watcher
watchManager.defaultWatcher = watcher;
ConnectStringParser connectStringParser = new ConnectStringParser(
connectString);
HostProvider hostProvider = new StaticHostProvider(
connectStringParser.getServerAddresses());
// 初始化ClientCnxn,并start启动SendThread和EventThread两个线程
cnxn = new ClientCnxn(connectStringParser.getChrootPath(),
hostProvider, sessionTimeout, this, watchManager,
getClientCnxnSocket(), canBeReadOnly);
cnxn.start();
}
public void start() {
sendThread.start();
eventThread.start();
}
上面就是构造器注册监听器的过程,需要注意的是getClientCnxnSocket方法,从方法名可以看出应该是获取客户端的通信对象:
private static ClientCnxnSocket getClientCnxnSocket() throws IOException {
// 获取zoo.cfg配置
String clientCnxnSocketName = System
.getProperty(ZOOKEEPER_CLIENT_CNXN_SOCKET);
if (clientCnxnSocketName == null) {
clientCnxnSocketName = ClientCnxnSocketNIO.class.getName();
}
try {
return (ClientCnxnSocket) Class.forName(clientCnxnSocketName)
.newInstance();
} catch (Exception e) {
IOException ioe = new IOException("Couldn't instantiate "
+ clientCnxnSocketName);
ioe.initCause(e);
throw ioe;
}
}
从源码中也可以看出确实是去初始化客户端的通信连接对象,Zookeeper有两个连接对象:ClientCnxnSocketNIO和ClientCnxnSocketNetty,默认是使用ClientCnxnSocketNIO,即默认使用NIO方式通信(PS:后者是3.5.1版本才出现的,但是这段代码在早期版本中已经存在,可以看到优秀代码对于扩展性的考虑和设计)。
b. exists/getData/getChildren绑定Watcher以及发送请求
通过构造器注册的监听在连接成功触发后就移除了(监听器只会触发一次,这里就是监听连接是否成功),因此后面需要监听节点变化只能通过exists/getData/getChildren来绑定(defaultWatcher 这个对象还存在),这三个方法注册监听的流程都一样,因此这里就以exists方法来说明。
// 绑定默认监听
Stat stat = zooKeeper.exists(NODE, true);
// 实现
public Stat exists(String path, boolean watch) throws KeeperException,
InterruptedException
{
// 这里就可以看到如果为true则使用构造器注册的默认监听,否则就不监听节点变化
return exists(path, watch ? watchManager.defaultWatcher : null);
}
public Stat exists(final String path, Watcher watcher)
throws KeeperException, InterruptedException
{
final String clientPath = path;
PathUtils.validatePath(clientPath);
// 这里实例化了一个ExistsWatcherRegistration,记住这个类,后面会用到
WatchRegistration wcb = null;
if (watcher != null) {
wcb = new ExistsWatchRegistration(watcher, clientPath);
}
final String serverPath = prependChroot(clientPath);
RequestHeader h = new RequestHeader();
h.setType(ZooDefs.OpCode.exists);
ExistsRequest request = new ExistsRequest();
request.setPath(serverPath);
request.setWatch(watcher != null);
SetDataResponse response = new SetDataResponse();
// 将实例化后的Header、ExistsRequest、Response以及wcb打包发送,并等待服务端响应
ReplyHeader r = cnxn.submitRequest(h, request, response, wcb);
if (r.getErr() != 0) {
if (r.getErr() == KeeperException.Code.NONODE.intValue()) {
return null;
}
throw KeeperException.create(KeeperException.Code.get(r.getErr()),
clientPath);
}
return response.getStat().getCzxid() == -1 ? null : response.getStat();
}
ClientCnxn.submitRequest
public ReplyHeader submitRequest(RequestHeader h, Record request,
Record response, WatchRegistration watchRegistration)
throws InterruptedException {
ReplyHeader r = new ReplyHeader();
// 打包
Packet packet = queuePacket(h, r, request, response, null, null, null,
null, watchRegistration);
// 等待服务端响应
synchronized (packet) {
while (!packet.finished) {
packet.wait();
}
}
return r;
}
Packet queuePacket(RequestHeader h, ReplyHeader r, Record request,
Record response, AsyncCallback cb, String clientPath,
String serverPath, Object ctx, WatchRegistration watchRegistration)
{
Packet packet = null;
synchronized (outgoingQueue) {
// 封装Packet对象后将其加入到outgoingQueue
packet = new Packet(h, r, request, response, watchRegistration);
packet.cb = cb;
packet.ctx = ctx;
packet.clientPath = clientPath;
packet.serverPath = serverPath;
if (!state.isAlive() || closing) {
conLossPacket(packet);
} else {
if (h.getType() == OpCode.closeSession) {
closing = true;
}
outgoingQueue.add(packet);
}
}
sendThread.getClientCnxnSocket().wakeupCnxn();
return packet;
}
流程到这里就断了,但是我们注意到将要发送的包放入到了一个类型为LinkedList的outgoingQueue发送队列,既然产生了队列,那么说明肯定存在其它线程来异步消费该队列(Zookeeper中大量运用了异步处理,值得我们学习借鉴),还记得构造器中启动的两个线程么(SendThread和EventThread)?
既然是线程,那么我们不用看其它的,直接找到run方法即可(在SendThread类中按CTRL + F12显示所有的方法和字段):
while (state.isAlive()) {
try {
// 传输逻辑主要在这儿,还记得clientCnxnSocket是在什么时候实例化的么?
clientCnxnSocket.doTransport(to, pendingQueue, outgoingQueue, ClientCnxn.this);
}
}
代码很长,这里我只截取了关键代码,其中有很多判断,细看一定会看的很懵逼,因此一定要先浏览整段代码,然后我们会发现clientCnxnSocket.doTransport(to, pendingQueue, outgoingQueue, ClientCnxn.this); 这样一段代码,通过方法名我们就能大致就能猜测到主要的传输逻辑就在这个方法中,这时可以在大致看看前面的判断语句中都做了一些什么事情,主要是看看会不会对传输造成大的影响,这里我们会发现就是判断是否连接成功,对我们的流程没有什么影响,那么按住啊CTRL + 鼠标左键直接进入到doTransport方法中:
abstract void doTransport(int waitTimeOut, List<Packet> pendingQueue,
LinkedList<Packet> outgoingQueue, ClientCnxn cnxn)
throws IOException, InterruptedException;
我们看到是一个抽象的方法,那么可以直接点击如下图中的按钮或者返回调用处按住CTRL + ALT + 鼠标左键进入具体的实现。

因为笔者使用的版本只有ClientCnxnSocketNIO一种实现方式,因此会直接进入到具体实现方法中,否则在高版本中加入了ClientCnxnSocketNetty后会弹出选择框(那我们怎么知道使用的是哪个类呢?还记得构造器中的getClientCnxnSocket方法么,忘了就回去看看!)。
ClientCnxnSocketNIO.doTranport()
void doTransport(int waitTimeOut, List<Packet> pendingQueue, LinkedList<Packet> outgoingQueue,
ClientCnxn cnxn)
throws IOException, InterruptedException {
selector.select(waitTimeOut);
Set<SelectionKey> selected;
synchronized (this) {
selected = selector.selectedKeys();
}
updateNow();
for (SelectionKey k : selected) {
SocketChannel sc = ((SocketChannel) k.channel());
if ((k.readyOps() & SelectionKey.OP_CONNECT) != 0) {
if (sc.finishConnect()) {
updateLastSendAndHeard();
sendThread.primeConnection();
}
} else if ((k.readyOps() & (SelectionKey.OP_READ | SelectionKey.OP_WRITE)) != 0) {
doIO(pendingQueue, outgoingQueue, cnxn);
}
}
if (sendThread.getZkState().isConnected()) {
synchronized(outgoingQueue) {
if (findSendablePacket(outgoingQueue,
cnxn.sendThread.clientTunneledAuthenticationInProgress()) != null) {
enableWrite();
}
}
}
selected.clear();
}
该方法中主要是基于NIO多路复用机制对连接状态的判断,不难发现最主要的逻辑在doIO中:
void doIO(List<Packet> pendingQueue, LinkedList<Packet> outgoingQueue, ClientCnxn cnxn)
throws InterruptedException, IOException {
// 读取服务端的响应
........
// 向服务端传送消息
if (sockKey.isWritable()) {
synchronized(outgoingQueue) {
Packet p = findSendablePacket(outgoingQueue,
cnxn.sendThread.clientTunneledAuthenticationInProgress());
if (p != null) {
updateLastSend();
// If we already started writing p, p.bb will already exist
if (p.bb == null) {
if ((p.requestHeader != null) &&
(p.requestHeader.getType() != OpCode.ping) &&
(p.requestHeader.getType() != OpCode.auth)) {
p.requestHeader.setXid(cnxn.getXid());
}
// 序列化Packet
p.createBB();
}
// 向服务端发送Packet
sock.write(p.bb);
// 发送完成后,从发送队列移除该Packet并将其加入到pendingQueue等待服务器的响应
if (!p.bb.hasRemaining()) {
sentCount++;
outgoingQueue.removeFirstOccurrence(p);
if (p.requestHeader != null
&& p.requestHeader.getType() != OpCode.ping
&& p.requestHeader.getType() != OpCode.auth) {
synchronized (pendingQueue) {
pendingQueue.add(p);
}
}
}
}
}
}
}
该方法中如同方法名就是做IO操作,即发送和接收数据包,那我们现在是向服务端发送数据包,所以只需要看socket.isWritable流程即可。在前面说了这是一个异步消费outgoingQueue的过程,因此需要从发送队列中挨个取出Packet,并序列化后发送给服务端,同样,在发送完成后,我们不可能阻塞等待服务端的响应,因此将Packet放入pendingQueue等待队列,这样大大提高客户端处理请求的能力。
这样,请求就发送完成了,但是我们还需要关注客户端向服务端都发送了哪些数据,点开createBB就知道了:
public void createBB() {
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(baos);
boa.writeInt(-1, "len"); // We'll fill this in later
if (requestHeader != null) {
requestHeader.serialize(boa, "header");
}
if (request instanceof ConnectRequest) {
request.serialize(boa, "connect");
// append "am-I-allowed-to-be-readonly" flag
boa.writeBool(readOnly, "readOnly");
} else if (request != null) {
request.serialize(boa, "request");
}
baos.close();
this.bb = ByteBuffer.wrap(baos.toByteArray());
this.bb.putInt(this.bb.capacity() - 4);
this.bb.rewind();
} catch (IOException e) {
LOG.warn("Ignoring unexpected exception", e);
}
}
可以看到,仅仅只是序列化了Header和Request,这些信息里包含了哪些数据还记得吗?
RequestHeader h = new RequestHeader();
h.setType(ZooDefs.OpCode.exists);
ExistsRequest request = new ExistsRequest();
request.setPath(serverPath);
request.setWatch(watcher != null);
在开始的exists方法中可以看到,header中是当前的操作类型,request中是绑定节点信息和是否设置监听的标识,也就是说这里并没有将Watcher传递给服务端,只是传递了一个flag,告诉服务端“我”要监听该节点的变化,所以,从这里我们就能看到客户端和服务端是分别管理Watcher的,但是客户端会在何时注册监听呢?当然需要等到服务端响应成功后注册了,不难明白,如果客户端都还没有接收到服务端的响应,那怎么能确保服务端一定是操作成功了呢,所以,客户端的监听器一定是在服务端响应后去注册。
2. 服务端处理请求并响应
a. 读取请求报文及反序列化
在看分析服务端源码之前,我们首先需要解决的一个问题,从何入手?客户端的入口很好找,但是我们和服务端是没有直接交互的,那该怎么办呢?这时候就需要我们大胆联想猜测了。在客户端我们是通过ClientCnxnSocketNIO来进行传输的,那么服务端肯定存在对应的一个类来响应请求。代码都是人写的,因此肯定在命名上就会有一定的规范和联系,优秀的代码更是如此。所以,可以通过IDEA快捷键CTRL + N搜索关键字ServerCnxn,然后你就会发现NIOServerCnxn,无需多想,服务端肯定是通过这个类来处理请求的。找到类之后我们还需要猜测处理请求的方法,同样,在客户端是通过doTransport和doIO方法来处理请求,那么服务端应该有对应的方法,或者带有response关键字的方法,打开类的方法结构,果然看到doIO方法:
NIOServerCnxn.doIO()
void doIO(SelectionKey k) throws InterruptedException {
try {
// 读取输入流
if (k.isReadable()) {
int rc = sock.read(incomingBuffer);
if (rc < 0) {
throw new EndOfStreamException(
"Unable to read additional data from client sessionid 0x"
+ Long.toHexString(sessionId)
+ ", likely client has closed socket");
}
if (incomingBuffer.remaining() == 0) {
boolean isPayload;
if (incomingBuffer == lenBuffer) { // start of next request
incomingBuffer.flip();
isPayload = readLength(k);
incomingBuffer.clear();
} else {
// continuation
isPayload = true;
}
if (isPayload) { // not the case for 4letterword
// 读取报文
readPayload();
}
else {
// four letter words take care
// need not do anything else
return;
}
}
}
} catch (CancelledKeyException e) {
LOG.warn("Exception causing close of session 0x"
+ Long.toHexString(sessionId)
+ " due to " + e);
if (LOG.isDebugEnabled()) {
LOG.debug("CancelledKeyException stack trace", e);
}
close();
} catch (CloseRequestException e) {
// expecting close to log session closure
close();
} catch (EndOfStreamException e) {
LOG.warn("caught end of stream exception",e); // tell user why
// expecting close to log session closure
close();
} catch (IOException e) {
LOG.warn("Exception causing close of session 0x"
+ Long.toHexString(sessionId)
+ " due to " + e);
if (LOG.isDebugEnabled()) {
LOG.debug("IOException stack trace", e);
}
close();
}
}
对应客服端,这里同样有read和write两个流程,因为是接收处理请求,所以这里肯定是走read流程,因此会进入到readPayload方法:
private void readPayload() throws IOException, InterruptedException {
if (incomingBuffer.remaining() != 0) { // have we read length bytes?
int rc = sock.read(incomingBuffer); // sock is non-blocking, so ok
if (rc < 0) {
throw new EndOfStreamException(
"Unable to read additional data from client sessionid 0x"
+ Long.toHexString(sessionId)
+ ", likely client has closed socket");
}
}
if (incomingBuffer.remaining() == 0) { // have we read length bytes?
packetReceived();
incomingBuffer.flip();
if (!initialized) {
// 连接请求
readConnectRequest();
} else {
// 其它请求
readRequest();
}
lenBuffer.clear();
incomingBuffer = lenBuffer;
}
}
目前我们是一个ExistsRequest,所以会调用readRequest方法:
private void readRequest() throws IOException {
zkServer.processPacket(this, incomingBuffer);
}
很简单,就是通过server去反序列化Packet并处理。
Zookeeper.processPacket反序列化Header并提交服务端请求
public void processPacket(ServerCnxn cnxn, ByteBuffer incomingBuffer) throws IOException {
// We have the request, now process and setup for next
InputStream bais = new ByteBufferInputStream(incomingBuffer);
BinaryInputArchive bia = BinaryInputArchive.getArchive(bais);
RequestHeader h = new RequestHeader();
// 反序列化header,还记得客户端header中存储的是什么吧
h.deserialize(bia, "header");
incomingBuffer = incomingBuffer.slice();
// 判断当前的请求类型是不是auth
if (h.getType() == OpCode.auth) {
LOG.info("got auth packet " + cnxn.getRemoteSocketAddress());
AuthPacket authPacket = new AuthPacket();
ByteBufferInputStream.byteBuffer2Record(incomingBuffer, authPacket);
String scheme = authPacket.getScheme();
AuthenticationProvider ap = ProviderRegistry.getProvider(scheme);
Code authReturn = KeeperException.Code.AUTHFAILED;
if(ap != null) {
try {
authReturn = ap.handleAuthentication(cnxn, authPacket.getAuth());
} catch(RuntimeException e) {
LOG.warn("Caught runtime exception from AuthenticationProvider: " + scheme + " due to " + e);
authReturn = KeeperException.Code.AUTHFAILED;
}
}
if (authReturn!= KeeperException.Code.OK) {
if (ap == null) {
LOG.warn("No authentication provider for scheme: "
+ scheme + " has "
+ ProviderRegistry.listProviders());
} else {
LOG.warn("Authentication failed for scheme: " + scheme);
}
// send a response...
ReplyHeader rh = new ReplyHeader(h.getXid(), 0,
KeeperException.Code.AUTHFAILED.intValue());
cnxn.sendResponse(rh, null, null);
// ... and close connection
cnxn.sendBuffer(ServerCnxnFactory.closeConn);
cnxn.disableRecv();
} else {
if (LOG.isDebugEnabled()) {
LOG.debug("Authentication succeeded for scheme: "
+ scheme);
}
LOG.info("auth success " + cnxn.getRemoteSocketAddress());
ReplyHeader rh = new ReplyHeader(h.getXid(), 0,
KeeperException.Code.OK.intValue());
cnxn.sendResponse(rh, null, null);
}
return;
} else {
// 判断当前请求类型是不是sasl
if (h.getType() == OpCode.sasl) {
Record rsp = processSasl(incomingBuffer,cnxn);
ReplyHeader rh = new ReplyHeader(h.getXid(), 0, KeeperException.Code.OK.intValue());
cnxn.sendResponse(rh,rsp, "response"); // not sure about 3rd arg..what is it?
}
else {
// 最终会进入到该分支,封装服务端请求对象并提交
Request si = new Request(cnxn, cnxn.getSessionId(), h.getXid(),
h.getType(), incomingBuffer, cnxn.getAuthInfo());
si.setOwner(ServerCnxn.me);
submitRequest(si);
}
}
cnxn.incrOutstandingRequests(h);
}
b. Processor
反序列化完成后会封装request并提交,而在submitRequest方法中我们可以看到关键的一段代码firstProcessor.processRequest(si);,这个firstProcessor是什么东西?通过快捷键跳转到具体实现代码时,提示中会出现很多个Processor实现类,我们该进入哪一个?
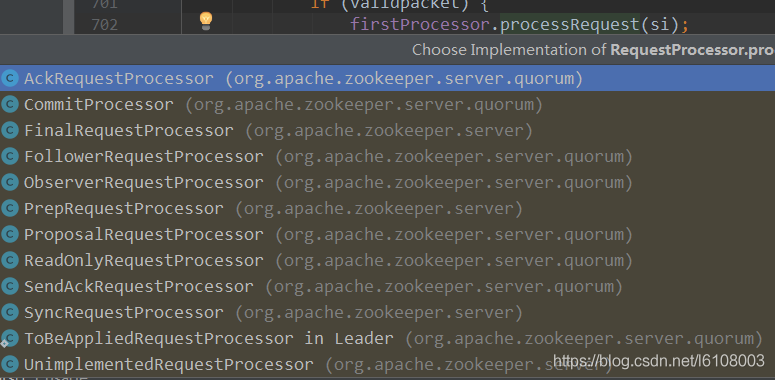
这个时候不要慌,要进入哪一个类肯定要看初始化,通过快捷键Alt + F7显示所有使用了该变量的地方:
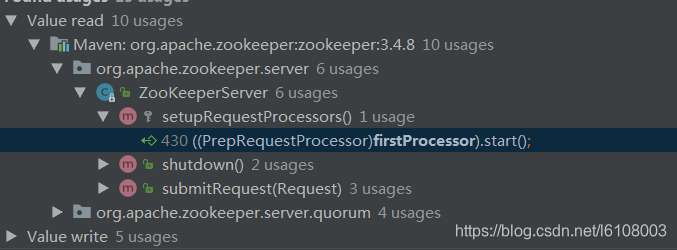
我们可以看到在当前类中有一个setupRequestProcessors方法,毫无疑问,点过去看就是:
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this,
finalProcessor);
((SyncRequestProcessor)syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
// 看到start,我们应该想到这应该又是通过线程来实现异步处理
((PrepRequestProcessor)firstProcessor).start();
}
可以看到这里是通过责任链模式实现了一个链式处理流程,按照顺序Request会分别被PrepRequestProcessor、SyncRequestProcessor、FinalRequestProcessor处理,这个时候别着急去看方法实现做了些什么事,而是应该先去看看这三个类的注释,大概了解一下这三个类的职能和作用。
- PrepRequestProcessor:请求预处理器,继承了线程,所有请求首先通过该处理器,它能识别出事务请求,并对其进行一系列预处理(比如版本校验)。
- SyncRequestProcessor:事务请求同步处理器,继承了线程。它将事务请求和事务日志同步记录到磁盘,并且在同步操作未完成时,不会进入到下一个处理器。同时该处理器在不同的角色中所做的操作不同:
- 当前服务器为leader:同步事务请求到磁盘
- 当前服务器为follower:同步事务请求到磁盘,并将请求转发给leader
- 当前服务器为observer:observer只会接收到来自于leader的同步请求(在之前的文章有说过,observer不会处理客户端的事务请求,只有leader执行事务请求成功后会将数据同步到observer),因此,只需要提交事务请求即可,也不需要返回响应给客户端。
- FinalRequestProcessor:所有处理器链最终都会调用的处理器,该处理器未继承线程,并且是同步处理请求。负责将所有已经提交的事务请求写入到本机,以及对于读请求,将本机数据返回给client。
大概了解了各处理器的职能后,我们再来分析具体的源码,首先是PrepRequestProcessor的processRequest方法:
// LinkedBlockingQueue<Request> submittedRequests = new LinkedBlockingQueue<Request>();
public void processRequest(Request request) {
submittedRequests.add(request);
}
很简单,就是将request加入到队列中,等待线程异步处理,那么我直接找到该类的run方法。run方法中调用了pRequest方法处理request,这个方法很长,浏览整个方法,发现是根据当前的操作类型来处理request,那我们直接找到exists操作的流程:
@Override
public void run() {
pRequest(request);
}
protected void pRequest(Request request) throws RequestProcessorException {
switch (request.type) {
case OpCode.sync:
case OpCode.exists:
case OpCode.getData:
case OpCode.getACL:
case OpCode.getChildren:
case OpCode.getChildren2:
case OpCode.ping:
case OpCode.setWatches:
zks.sessionTracker.checkSession(request.sessionId,
request.getOwner());
break;
}
// 调用下一个processor的方法
nextProcessor.processRequest(request);
}
可以看到这里主要是对request进行校验,详细的校验内容跟我们当前主流程关系不大,不用关心。所以直接翻到方法最后看到是调用了nextProcessor.processRequest方法,nextProcessor是什么,刚刚初始化的时候我们已经看到了,所以直接进入相应类的方法中:
public void processRequest(Request request) {
// request.addRQRec(">sync");
queuedRequests.add(request);
}
同样的也是放入到了一个队列中,所以直接看run方法:
// 将要被写入到磁盘上的request队列
private final LinkedList<Request> toFlush = new LinkedList<Request>();
public void run() {
while (true) {
Request si = null;
if (toFlush.isEmpty()) {
si = queuedRequests.take();
} else {
si = c.poll();
if (si == null) {
// queuedRequests队列中没有request了就提交toFlush队列中的事务,并掉用下一个processor
flush(toFlush);
continue;
}
}
if (si == requestOfDeath) {
break;
}
if (si != null) {
// 记录事务日志成功走这里
if (zks.getZKDatabase().append(si)) {
logCount++;
if (logCount > (snapCount / 2 + randRoll)) {
randRoll = r.nextInt(snapCount/2);
// roll the log
zks.getZKDatabase().rollLog();
// take a snapshot
if (snapInProcess != null && snapInProcess.isAlive()) {
LOG.warn("Too busy to snap, skipping");
} else {
snapInProcess = new ZooKeeperThread("Snapshot Thread") {
public void run() {
try {
zks.takeSnapshot();
} catch(Exception e) {
LOG.warn("Unexpected exception", e);
}
}
};
snapInProcess.start();
}
logCount = 0;
}
} else if (toFlush.isEmpty()) {
// 事务日志记录失败并且toFlush中没有request,那么直接调用下一个processor提高效率
if (nextProcessor != null) {
nextProcessor.processRequest(si);
if (nextProcessor instanceof Flushable) {
((Flushable)nextProcessor).flush();
}
}
continue;
}
// 事务日志记录完成后将request放入到toflush
toFlush.add(si);
if (toFlush.size() > 1000) {
flush(toFlush);
}
}
}
}
记录事务日志的细节我们不用太过关注,主要了解其处理流程以及设计思想,不要被细节搞晕了。这里处理完成后,就到了我们最后一个processor(FinalRequestProcessor)中了,代码很长,直接看关键代码:
Record rsp = null;
ServerCnxn cnxn = request.cnxn;
case OpCode.exists: {
lastOp = "EXIS";
// 反序列化request
ExistsRequest existsRequest = new ExistsRequest();
ByteBufferInputStream.byteBuffer2Record(request.request,
existsRequest);
String path = existsRequest.getPath();
if (path.indexOf('\0') != -1) {
throw new KeeperException.BadArgumentsException();
}
// 这里非常关键,判断客服端是否设置watcher,如有则服务端也对该path节点
// 添加watcher(cnxn本身就是一个watcher子类)
Stat stat = zks.getZKDatabase().statNode(path, existsRequest
.getWatch() ? cnxn : null);
// 封装ExistsResponse响应信息
rsp = new ExistsResponse(stat);
break;
}
// 生成header
long lastZxid = zks.getZKDatabase().getDataTreeLastProcessedZxid();
ReplyHeader hdr =
new ReplyHeader(request.cxid, lastZxid, err.intValue());
// 发送响应信息
cnxn.sendResponse(hdr, rsp, "response");
终于找到关键性的代码,exists操作会去添加监听,下面我们就详细看看服务端注册监听的流程。
c. 服务端注册监听器
点击zks.getZKDatabase().statNode(path, existsRequest.getWatch() ? cnxn : null)方法进入,最终进入DataTree的statNode方法(该对象就是Zookeeper数据结构对象):
// 注意这里的watcher是由ServerCnxn向上转型得到的
public Stat statNode(String path, Watcher watcher)
throws KeeperException.NoNodeException {
Stat stat = new Stat();
DataNode n = nodes.get(path);
if (watcher != null) {
// 调用WatcherManager的方法添加监听
dataWatches.addWatch(path, watcher);
}
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
n.copyStat(stat);
return stat;
}
}
主要逻辑在addWatch中(还记得客户端的WatcherManager么?这里是服务端管理Watcher的类,再次说明客户端服务端是分开管理Watcher的):
private final HashMap<String, HashSet<Watcher>> watchTable =
new HashMap<String, HashSet<Watcher>>();
private final HashMap<Watcher, HashSet<String>> watch2Paths =
new HashMap<Watcher, HashSet<String>>();
public synchronized void addWatch(String path, Watcher watcher) {
// 从节点角度管理watcher,一个节点可能会对应多个watcher
HashSet<Watcher> list = watchTable.get(path);
if (list == null) {
// 第一次给该节点添加监听初始化。这个细节值得学习,内存是昂贵的,
// 从实际角度出发,一般一个节点对应的watcher并不会特别多,因此初始化
// 容量设定4是一个非常好的节省资源和平衡性能的折衷方案
list = new HashSet<Watcher>(4);
watchTable.put(path, list);
}
list.add(watcher);
// 从watcher角度管理path,一个watcher可能会监听多个path
HashSet<String> paths = watch2Paths.get(watcher);
if (paths == null) {
// 第一次添加初始化
paths = new HashSet<String>();
watch2Paths.put(watcher, paths);
}
paths.add(path);
}
至此,服务端监听注册完成,然后就会调用下面的方法发送响应信息给客户端:
cnxn.sendResponse(hdr, rsp, "response");
3. 客户端处理服务器响应信息
a. 客户端读取响应流
ClientCnxnSocketNIO.doIO
一开始在分析客户端发送请求时,我们看到是通过ClientCnxnSocketNIO.doIO方法传输的,应该还记得当时read读取流的部分我们是跳过的,这就是读取服务端的响应信息:
if (sockKey.isReadable()) {
int rc = sock.read(incomingBuffer);
// incomingBuffer已经被读取完
if (!incomingBuffer.hasRemaining()) {
incomingBuffer.flip();
if (incomingBuffer == lenBuffer) {
recvCount++;
readLength();
} else if (!initialized) {
readConnectResult();
enableRead();
if (findSendablePacket(outgoingQueue,
cnxn.sendThread.clientTunneledAuthenticationInProgress()) != null) {
// Since SASL authentication has completed (if client is configured to do so),
// outgoing packets waiting in the outgoingQueue can now be sent.
enableWrite();
}
lenBuffer.clear();
incomingBuffer = lenBuffer;
updateLastHeard();
initialized = true;
} else {
// 主要逻辑在这儿,通过发送线程去读取响应信息
sendThread.readResponse(incomingBuffer);
lenBuffer.clear();
incomingBuffer = lenBuffer;
updateLastHeard();
}
}
}
SendThread.readResponse
void readResponse(ByteBuffer incomingBuffer) throws IOException {
ByteBufferInputStream bbis = new ByteBufferInputStream(
incomingBuffer);
BinaryInputArchive bbia = BinaryInputArchive.getArchive(bbis);
ReplyHeader replyHdr = new ReplyHeader();
replyHdr.deserialize(bbia, "header");
// pendingQueue中取出Packet
Packet packet;
synchronized (pendingQueue) {
if (pendingQueue.size() == 0) {
throw new IOException("Nothing in the queue, but got "
+ replyHdr.getXid());
}
packet = pendingQueue.remove();
}
try {
// 将Header设置到Packet
packet.replyHeader.setXid(replyHdr.getXid());
packet.replyHeader.setErr(replyHdr.getErr());
packet.replyHeader.setZxid(replyHdr.getZxid());
if (replyHdr.getZxid() > 0) {
lastZxid = replyHdr.getZxid();
}
// 反序列化response到Packet
if (packet.response != null && replyHdr.getErr() == 0) {
packet.response.deserialize(bbia, "response");
}
} finally {
// 客户端处理响应信息
finishPacket(packet);
}
}
readResponse中主要做了以下几件事:
- 反序列化ReplyHeader
- 根据header中的xid判断当前服务端的响应类型(-2:Ping类型;-4:权限相关的响应;-1:事件通知。这些类型跟我们目前的流程都不相关,可以先忽略)
- 从pendingQueue中取出客户端之前存放的Packet,并将反序列化后的response以及header设置到Packet
- 调用finishPacket方法完成对数据包的处理(客户端注册监听的逻辑就在该方法中)。
b. 客户端注册监听器
finishPacket
private void finishPacket(Packet p) {
// 注册监听器
if (p.watchRegistration != null) {
// watchRegistration是exists方法实例化的ExistsWatchRegistration对象
p.watchRegistration.register(p.replyHeader.getErr());
}
if (p.cb == null) {
// 未设置回调表示是同步调用接口,不需要异步回调,因此直接唤醒等待响应的Packet线程
synchronized (p) {
p.finished = true;
p.notifyAll();
}
} else {
// 否则放入到EventThread的waitingEvents中
p.finished = true;
eventThread.queuePacket(p);
}
}
这里我们主要看看监听器的注册流程,其它的就是返回客户端结果。
WatchRegistration注册流程
public void register(int rc) {
if (shouldAddWatch(rc)) {
// 模板方法模式获取监听器
Map<String, Set<Watcher>> watches = getWatches(rc);
synchronized(watches) {
// 根据路径获取Watcher集合,如果是第一个监听器则初始化
Set<Watcher> watchers = watches.get(clientPath);
if (watchers == null) {
watchers = new HashSet<Watcher>();
watches.put(clientPath, watchers);
}
// 将watcher添加到集合中即完成Watcher的注册
watchers.add(watcher);
}
}
}
因为一开始我们初始化的是ExistsWatchRegistration对象,所以getWatches是调用的该对象的实例方法并返回存储Watcher的集合:
protected Map<String, Set<Watcher>> getWatches(int rc) {
// 这里不用想,肯定是返回的watchManager.existWatches
return rc == 0 ? watchManager.dataWatches : watchManager.existWatches;
}
下面这个三个集合是ZKWatchManager存储watcher的map集合,分别对应三种注册监听的事件:
// getData
private final Map<String, Set<Watcher>> dataWatches =
new HashMap<String, Set<Watcher>>();
// exists
private final Map<String, Set<Watcher>> existWatches =
new HashMap<String, Set<Watcher>>();
// getChildren
private final Map<String, Set<Watcher>> childWatches =
new HashMap<String, Set<Watcher>>();
至此,客户端注册监听的流程就完成了。总而言之,客户端当通过构造器或者exists/getData/getChildren三个方法注册监听时,首先会通知服务端,得到服务端的成功响应时,客户端再将Watcher注册存储起来等待对应事件的触发。下面我们就来看看事件的触发机制。
4. 事件触发流程
事件的注册是通过非事务型的方法实现,即订阅服务端节点变化,而节点状态只能通过事务型方法去改变,因此事件只能通过create/setData/delete触发(事件绑定时的响应不算),这里通过setData方法来说明。
a. 服务端响应setData类型操作
PrepRequestProcessor.pRequest
客户端和服务端交互的过程和前面讲的都是样的,这里就不再累述了,直接找到PrepRequestProcessor.pRequest方法中的关键位置(在上面的流程中是到这个方法后才会判断操作的类型):
case OpCode.setData:
SetDataRequest setDataRequest = new SetDataRequest();
pRequest2Txn(request.type, zks.getNextZxid(), request, setDataRequest, true);
break;
封装了SetDataRequest对象并掉用pRequest2Txn方法,这个方法中也是根据操作类型来进入对应的流程:
case OpCode.setData:
zks.sessionTracker.checkSession(request.sessionId, request.getOwner());
SetDataRequest setDataRequest = (SetDataRequest)record;
if(deserialize)
ByteBufferInputStream.byteBuffer2Record(request.request, setDataRequest);
path = setDataRequest.getPath();
validatePath(path, request.sessionId);
// 根据path获取node信息,先从outstandingChangesForPath获取,未获取到再从服务器中获取
nodeRecord = getRecordForPath(path);
checkACL(zks, nodeRecord.acl, ZooDefs.Perms.WRITE,
request.authInfo);
version = setDataRequest.getVersion();
int currentVersion = nodeRecord.stat.getVersion();
if (version != -1 && version != currentVersion) {
throw new KeeperException.BadVersionException(path);
}
version = currentVersion + 1;
request.txn = new SetDataTxn(path, setDataRequest.getData(), version);
// 拷贝新的对象
nodeRecord = nodeRecord.duplicate(request.hdr.getZxid());
nodeRecord.stat.setVersion(version);
// 将变化的节点存到outstandingChanges和outstandingChangesForPath中
addChangeRecord(nodeRecord);
break;
FinalRequestProcessor
然后是调用下一个processor处理器,而SyncRequestProcessor中没有流程分支,不必分析,因此直接进入到FinalRequestProcessor的run方法:
case OpCode.setData: {
lastOp = "SETD";
rsp = new SetDataResponse(rc.stat);
err = Code.get(rc.err);
break;
}
同开始exists操作的流程一样,setData操作也会有对应的分支,但在这里面只是封装了响应对象就发送给客户端了,没有其它的逻辑,那说明我们遗漏了什么,就需要返回网上看看了。我们注意到这里使用到了rc.stat,直接点过去,我们看到一个熟悉的东西outstandingChanges,这不是刚刚还在PrepRequestProcessor中添加了变化节点信息进去的么,由于exists操作并没有操作该变量,所以我们一开始就忽略了这一步,那现在不用多想,我们想要的逻辑肯定是在这个步骤里面是实现的:
ProcessTxnResult rc = null;
synchronized (zks.outstandingChanges) {
// 确保request的zxid和最近变化的node的zxid是一致的
while (!zks.outstandingChanges.isEmpty()
&& zks.outstandingChanges.get(0).zxid <= request.zxid) {
ChangeRecord cr = zks.outstandingChanges.remove(0);
if (cr.zxid < request.zxid) {
LOG.warn("Zxid outstanding "
+ cr.zxid
+ " is less than current " + request.zxid);
}
if (zks.outstandingChangesForPath.get(cr.path) == cr) {
zks.outstandingChangesForPath.remove(cr.path);
}
}
if (request.hdr != null) {
TxnHeader hdr = request.hdr;
Record txn = request.txn;
// 实际处理事务请求的方法
rc = zks.processTxn(hdr, txn);
}
// do not add non quorum packets to the queue.
if (Request.isQuorum(request.type)) {
zks.getZKDatabase().addCommittedProposal(request);
}
}
DataTree.processTxn
追踪processTxn方法,最终会进入到DataTree.setData方法中,之前说过,该对象就是服务器的数据结构对象,如果你足够敏感,那么在一开始分析setData方法时,是可以直接定位这里的。
public Stat setData(String path, byte data[], int version, long zxid,
long time) throws KeeperException.NoNodeException {
Stat s = new Stat();
DataNode n = nodes.get(path);
if (n == null) {
throw new KeeperException.NoNodeException();
}
byte lastdata[] = null;
synchronized (n) {
lastdata = n.data;
n.data = data;
n.stat.setMtime(time);
n.stat.setMzxid(zxid);
n.stat.setVersion(version);
n.copyStat(s);
}
// now update if the path is in a quota subtree.
String lastPrefix;
if((lastPrefix = getMaxPrefixWithQuota(path)) != null) {
this.updateBytes(lastPrefix, (data == null ? 0 : data.length)
- (lastdata == null ? 0 : lastdata.length));
}
// 触发监听器,类型为NodeDataChanged
dataWatches.triggerWatch(path, EventType.NodeDataChanged);
return s;
}
b. 服务端监听器的触发
WatcherManager.triggerWatch
服务端节点信息改变会就调用WatcherManager的triggerWatch方法去触发监听器:
public Set<Watcher> triggerWatch(String path, EventType type, Set<Watcher> supress) {
// 根据事件类型、连接状态、节点path创建WatchedEvent
WatchedEvent e = new WatchedEvent(type,
KeeperState.SyncConnected, path);
HashSet<Watcher> watchers;
synchronized (this) {
// 取出并移除path对应的所有watcher
watchers = watchTable.remove(path);
if (watchers == null || watchers.isEmpty()) {
return null;
}
// 移除watcher对应的所有path
for (Watcher w : watchers) {
HashSet<String> paths = watch2Paths.get(w);
if (paths != null) {
paths.remove(path);
}
}
}
for (Watcher w : watchers) {
if (supress != null && supress.contains(w)) {
continue;
}
// 这里才是响应客户端的关键
w.process(e);
}
return watchers;
}
w.process(e)
这是Watcher的一个模板方法,是做什么呢?我们自己实现的监听器就要实现该方法,即事件触发时调用和接收通知的方法,但是这里是服务端,客户端和服务端是分别管理Watcher的,所以这里不可能是直接调用我们实现的方法,那应该是调用哪一个类呢?
想不起来就返回去看看服务端注册Watcher的流程吧,那时是将ServerCnxn对象向上转型存入到Watcher集合中的,而我们这里又是通过子类NIOServerCnxn来传输的,因此,这里就是调用该类的process方法:
synchronized public void process(WatchedEvent event) {
// 构建header,注意这里的xid = -1
ReplyHeader h = new ReplyHeader(-1, -1L, 0);
// 构建WatcherEvent对象
WatcherEvent e = event.getWrapper();
// 将header、event以及tag=notification序列化传送到客户端
sendResponse(h, e, "notification");
}
至此,服务端事件通知就完成了,最后就是客户端如何处理事件通知了。
c. 客户端监听器的触发
SendThread.readResponse
客户端接收响应信息肯定也是同之前一样,所以直接定位到SendThread.readResponse中,在之前的客户端接收服务端响应的流程中我讲过在这个方法中会根据当前header的xid判断进行什么样的操作,刚刚我们看到了服务端设置了header.xid=-1,因此,这就是事件触发要走的流程:
if (replyHdr.getXid() == -1) {
// 反序列化event
WatcherEvent event = new WatcherEvent();
event.deserialize(bbia, "response");
// 构建客户端WatchedEvent 对象并加入到EventThread的waitingEvents中等待触发
WatchedEvent we = new WatchedEvent(event);
eventThread.queueEvent( we );
return;
}
EventThread
public void queueEvent(WatchedEvent event) {
if (event.getType() == EventType.None
&& sessionState == event.getState()) {
return;
}
sessionState = event.getState();
// 构建WatcherSetEventPair对象并加入到队列中
WatcherSetEventPair pair = new WatcherSetEventPair(
watcher.materialize(event.getState(), event.getType(),
event.getPath()),
event);
// queue the pair (watch set & event) for later processing
waitingEvents.add(pair);
}
从这里我们可以看到事件触发对象为WatcherSetEventPair,再看processEvent方法(run方法调用):
private void processEvent(Object event) {
if (event instanceof WatcherSetEventPair) {
WatcherSetEventPair pair = (WatcherSetEventPair) event;
// 这里的Watcher就是刚刚queueEvent方法中初始化WatcherSetEventPair设置的watcher集合,即我们自定义的Watcher
for (Watcher watcher : pair.watchers) {
try {
// 这里就是客户端最终去调用我们自己实现的Watcher的process方法
watcher.process(pair.event);
} catch (Throwable t) {
LOG.error("Error while calling watcher ", t);
}
}
}
}
WatcherSetEventPair中watcher就是我们自定义的Watcher,它们是怎么关联上的呢?返回刚刚queueEvent方法实例化这个对象的地方:
WatcherSetEventPair pair = new WatcherSetEventPair(
watcher.materialize(event.getState(), event.getType(),
event.getPath()),
event);
其中第一个参数就是watcher集合,看看materialize这个方法:
public Set<Watcher> materialize(Watcher.Event.KeeperState state,
Watcher.Event.EventType type,
String clientPath)
{
Set<Watcher> result = new HashSet<Watcher>();
switch (type) {
case NodeDataChanged:
case NodeCreated:
synchronized (dataWatches) {
addTo(dataWatches.remove(clientPath), result);
}
synchronized (existWatches) {
addTo(existWatches.remove(clientPath), result);
}
break;
return result;
}
很简单,就是根据当前的事件类型返回对应的watcher,当前我们是NodeDataChanged事件,因此,返回dataWatches和existWatches中的内容。这两个集合肯定不陌生吧,就是客户端注册监听时存储监听器的集合。
结语
本篇文章到这里终于结束了,个人在这篇文章上也花费了很多的时间和精力。但确实收获颇丰:学到了异步处理的思路,代码架构的设计以及阅读源码的技巧等等。Zookeeper的源码其实是非常易于我们阅读的,它不像Spring那样跳来跳去,但仍需我们反复阅读,多画时序图才能理清楚。
Zookeeper系列文章暂时就到这里结束了,我也是初学,不可能方方面面都讲到,因此也只是针对核心的一些原理和应用进行了总结,想要深入了解的推荐看《从Paxos到Zookeeper 分布式一致性原理与实践 》。
PS:接下来将进入Dubbo系列,而Dubbo的基础使用基本概念官网都讲得非常清楚了,我也不打算耗费时间在这上面,所以主要是分析Dubbo的核心源码。

