前端大量复杂数据存储探索
引入
最近有需求做一个在B端的长期数据储存方案,主要是需要将大量数据结构化储存,避免每一次启动都去服务端重复拉取数据
第一个想到的前端持久化数据存储方案理所当然想到localstorage,但是它有一个最大5M的空间限制,这大小远远不够,因此我们将视线转移到前端数据库,半年前我接的有看到过sqlite.js这样的东西,于是我们很快找到了它
sql.js
从官网示例关键代码来看
const initSqlJs = require('sql.js');
// or if you are in a browser:
// const initSqlJs = window.initSqlJs;
const SQL = await initSqlJs({
// Required to load the wasm binary asynchronously. Of course, you can host it wherever you want
// You can omit locateFile completely when running in node
locateFile: file => `https://sql.js.org/dist/${file}`
});
// Create a database
const db = new SQL.Database();
// NOTE: You can also use new SQL.Database(data) where
// data is an Uint8Array representing an SQLite database file
似乎第12行非常重要,它也表明了 data is an Unit8Array,那么意味着它并不能完成数据长期化储存,它的任务是当一个引擎,在内存中操作SQL,那么我们再去思考,有没有什么东西可以储存这个data呢?
顺水摸鱼就摸到了IndexedDB,这好像也是一个前两年很火的东西,一样的我们去MDN看看
IndexedDB - Web API 接口参考 | MDN (mozilla.org) https://developer.mozilla.org/zh-CN/docs/Web/API/IndexedDB_API
看官网介绍:IndexedDB 是一种底层 API,用于在客户端存储大量的结构化数据(也包括文件/二进制大型对象(blobs))。该 API 使用索引实现对数据的高性能搜索。虽然 Web Storage 在存储较少量的数据很有用,但对于存储更大量的结构化数据来说力不从心。而 IndexedDB 提供了这种场景的解决方案。本页面 MDN IndexedDB 的主要引导页 - 这里,我们提供了完整的 API 参考和使用指南,浏览器支持细节,以及关键概念的一些解释的链接。
好家伙,似乎IndexedDB直接就从底层支持了索引,可以处理复杂结构化数据,那么我们仔细看看接口
IndexDB
先看概念
概念
IndexedDB 是一个事务型数据库系统,类似于基于 SQL 的 RDBMS。然而,不像 RDBMS 使用固定列表,IndexedDB 是一个基于 JavaScript 的面向对象数据库。IndexedDB 允许你存储和检索用键索引的对象;可以存储结构化克隆算法支持的任何对象。你只需要指定数据库模式,打开与数据库的连接,然后检索和更新一系列事务。
说人话:类似于MongoDB那样的文档类型数据库,但是支持事务
同步
IndexedBD是完全异步的,同步的API已经被移除,但是如果开发者有需求并且需求够多(💰没到位)可以考虑重新引入同步接口
使用
我们可以直接尝试看demo,看看它到底是如何工作的,但是在这之前,先了解几个基础概念(几个通用接口)
连接数据库
IDBFactory(连接数据库用的)
提供数据库访问。这是全局对象 indexedDB 实现的接口,因此是 API 的入口。
IDBOpenDBRequest (en-US)(类似于HTTP里的一次请求)
表示一个打开数据库的请求。
IDBDatabase(连接成功了以后才能获取到的数据库实例)
表示一个数据库连接。这是在数据库中获取事务的唯一方式。
接收和修改数据
IDBTransaction(IDBDatabase中开启一个事务)
表示一个事务。在数据库上创建一个事务,指定作用域(例如要访问的存储对象),并确定所需的访问类型(只读或读写)。
IDBRequest(IDBTranscation中一次数据访问请求)
处理数据库请求并提供对结果访问的通用接口。
IDBObjectStore(键值对)
表示允许访问通过主键查找的 IndexedDB 数据库中的一组数据的对象存储区。
IDBIndex(带索引的键值对)
也是为了允许访问 IndexedDB 数据库中的数据子集,但使用索引来检索记录而不是主键。这有时比使用 IDBObjectStore 更快。
IDBCursor(结果迭代
迭代对象存储和索引。
IDBCursorWithValue (en-US)
迭代对象存储和索引并返回游标的当前值。
IDBKeyRange
定义可用于从特定范围内的数据库检索数据的键范围。
Demo
来看看demo吧
HelloWorld
const request = indexedDB.open("library");
let db;
request.onupgradeneeded = function() {
// The database did not previously exist, so create object stores and indexes.
const db = request.result;
const store = db.createObjectStore("books", {keyPath: "isbn"});
const titleIndex = store.createIndex("by_title", "title", {unique: true});
const authorIndex = store.createIndex("by_author", "author");
// Populate with initial data.
store.put({title: "Quarry Memories", author: "Fred", isbn: 123456});
store.put({title: "Water Buffaloes", author: "Fred", isbn: 234567});
store.put({title: "Bedrock Nights", author: "Barney", isbn: 345678});
};
request.onsuccess = function() {
db = request.result;
};
同意注意官网的示例

upgradeneeded是indexedDB检测到数据库需要进行迁移时的回调,可以用于初始化数据库
在这个回调中,我们创建了books这个store(可以理解为一张表),并且指定主键为ibsn(可以理解为书的出版号,唯一),后又添加了两个索引,title和author,同时title为唯一索引
完成了这些事情以后,往数据库里添加了三行数据,好家伙,可以发现这和MongoDB那是基本上一模一样的
事务
下面我们来看,如何通过事务来完成数据插入
const tx = db.transaction("books", "readwrite");
const store = tx.objectStore("books");
store.put({title: "Quarry Memories", author: "Fred", isbn: 123456});
store.put({title: "Water Buffaloes", author: "Fred", isbn: 234567});
store.put({title: "Bedrock Nights", author: "Barney", isbn: 345678});
tx.oncomplete = function() {
// All requests have succeeded and the transaction has committed.
};
差不太多,但是这次获取store是通过事务获取,操作具有原子性(说人话,不会出现插入了两条到了第三天直接寄掉然后只插入了两条的情况,要么一条都没有插入要么全进去了)
在传统数据库里,我们可能还需要进行一次 tx.Rollback,那么这里如何?看看官网解释

说人话,压根不会对数据库造成影响,一次事务只要失败了那就是失败了,啥事情没有,再粗暴一点理解,就是自动rollback
索引
好的,那么下面我们来看看索引怎么用,有两个例子
const tx = db.transaction("books", "readonly");
const store = tx.objectStore("books");
const index = store.index("by_title");
const request = index.get("Bedrock Nights");
request.onsuccess = function() {
const matching = request.result;
if (matching !== undefined) {
// A match was found.
report(matching.isbn, matching.title, matching.author);
} else {
// No match was found.
report(null);
}
};
const tx = db.transaction("books", "readonly");
const store = tx.objectStore("books");
const index = store.index("by_author");
const request = index.openCursor(IDBKeyRange.only("Fred"));
request.onsuccess = function() {
const cursor = request.result;
if (cursor) {
// Called for each matching record.
report(cursor.value.isbn, cursor.value.title, cursor.value.author);
cursor.continue();
} else {
// No more matching records.
report(null);
}
};
一是通过唯一索引去get一行(在传统数据库里叫 1 row,这里可以叫一个文档),可以看到这里全都是异步的,当然我们肯定是希望把它封装成async/await的形式的,但这个工作应该已经有大牛去做了,我们之后搜一搜就好
二是通过openCursor去获取多行数据,并且加入了IDBKeyRange字段,这个按照我的理解,就是数据库中改的WhereClause,参考这里 IDBKeyRange - Web API 接口参考 | MDN (mozilla.org),而所谓cursor,可以简单理解为用迭代器的形式去避免同时大量数据读写
插入
除了像刚刚那样指定主键外,还可以使用递增主键,甚至这个建。。可以是数组可以是字符串,那么按照我的猜测,主键使用的应该是类似于hash之类的索引
store = db.createObjectStore("store1", { autoIncrement: true });
store.put("a"); // Will get key 1
store.put("b", 3); // Will use key 3
store.put("c"); // Will get key 4
store.put("d", -10); // Will use key -10
store.put("e"); // Will get key 5
store.put("f", 6.00001); // Will use key 6.0001
store.put("g"); // Will get key 7
store.put("f", 8.9999); // Will use key 8.9999
store.put("g"); // Will get key 9
store.put("h", "foo"); // Will use key "foo"
store.put("i"); // Will get key 10
store.put("j", [1000]); // Will use key [1000]
store.put("k"); // Will get key 11
// All of these would behave the same if the objectStore used a
// keyPath and the explicit key was passed inline in the object
最后,主键可以是插入时不存在的,它会自动创建,就像这样
const store = db.createObjectStore("store", { keyPath: "foo.bar.baz",
autoIncrement: true });
store.put({ zip: {} }).onsuccess = function(e) {
const key = e.target.result;
console.assert(key === 1);
store.get(key).onsuccess = function(e) {
const value = e.target.result;
// value will be: { zip: {}, foo: { bar: { baz: 1 } } }
console.assert(value.foo.bar.baz === 1);
};
};
你看,foo.bar.baz是不存在的,但是被创建了
不过当然,如果你使用原始数据类型如number/string之类的,并且指定了keyPath,那么储存会失败,因为IndexedDB不知道怎么在 "hello" 这个字符串上面添加key,例子如下
const store = db.createObjectStore("store", { keyPath: "foo", autoIncrement: true });
// The key generation will attempt to create and store the key path
// property on this primitive.
store.put(4); // will throw DataError
// The key generation will attempt to create and store the key path
// property on this array.
store.put([10]); // will throw DataError
以上,就是差不多官网的所有示例了,但是这些肯定不够用,还需要详细翻看API文档,递地址在这
Indexed Database API 3.0 (w3c.github.io) https://w3c.github.io/IndexedDB/#object-store-interface
我们可以从最简单的IDObjectStore看看
[Exposed=(Window,Worker)]
interface IDBObjectStore {
attribute DOMString name;
readonly attribute any keyPath;
readonly attribute DOMStringList indexNames;
[SameObject] readonly attribute IDBTransaction transaction;
readonly attribute boolean autoIncrement;
[NewObject] IDBRequest put(any value, optional any key);
[NewObject] IDBRequest add(any value, optional any key);
[NewObject] IDBRequest delete(any query);
[NewObject] IDBRequest clear();
[NewObject] IDBRequest get(any query);
[NewObject] IDBRequest getKey(any query);
[NewObject] IDBRequest getAll(optional any query,
optional [EnforceRange] unsigned long count);
[NewObject] IDBRequest getAllKeys(optional any query,
optional [EnforceRange] unsigned long count);
[NewObject] IDBRequest count(optional any query);
[NewObject] IDBRequest openCursor(optional any query,
optional IDBCursorDirection direction = "next");
[NewObject] IDBRequest openKeyCursor(optional any query,
optional IDBCursorDirection direction = "next");
IDBIndex index(DOMString name);
[NewObject] IDBIndex createIndex(DOMString name,
(DOMString or sequence<DOMString>) keyPath,
optional IDBIndexParameters options = {});
undefined deleteIndex(DOMString name);
};
dictionary IDBIndexParameters {
boolean unique = false;
boolean multiEntry = false;
};
该有的都有,那么其他的我们也可以不用深究了,总之这玩意就是一个面向对象的数据库了
开源市场
大概看了一下,比较大的有这么几个基于indexedDB开发的库
- localForage/localForage: 💾 Offline storage, improved. Wraps IndexedDB, WebSQL, or localStorage using a simple but powerful API. (github.com)
- dexie/Dexie.js: A Minimalistic Wrapper for IndexedDB (github.com)
- jakearchibald/idb: IndexedDB, but with promises (github.com)
- pouchdb/pouchdb: 🐨 - PouchDB is a pocket-sized database. (github.com)
- LocalForage
其中 localForage 是一个类似于localStorage的库,提供的接口基本上一模一样,不符合我们复杂查询的要求,因此忽略
Dexie.js
在官网上我看到了一个很酷的东西
<template>
<h2>Friends</h2>
<ul>
<li v-for="friend in friends" :key="friend.id">
{{ friend.name }}, {{ friend.age }}
</li>
</ul>
</template>
<script>import { liveQuery } from "dexie";
import { db } from "../db";
import { useObservable } from "@vueuse/rxjs";
export default {
name: "FriendList",
setup() {
return {
friends: useObservable(
liveQuery(async () => {
//
// Query the DB using our promise based API.
// The end result will magically become
// observable.
//
return await db.friends
.where("age")
.between(18, 65)
.toArray();
})
)
};
}
};
</script>
它支持动态的数据!甚至可以不需要我们去手动更新!这可以省掉很多很多功夫了!即使它使用了@vueuse/rxjs这个第三方库,那也仍然是很省心的
事务用起来也更有“事务”的感觉,API和MongoDB也高度相似
db.transaction('rw', db.friends, async() => {
// Make sure we have something in DB:
if ((await db.friends.where({name: 'Josephine'}).count()) === 0) {
const id = await db.friends.add({name: "Josephine", age: 21});
alert (`Addded friend with id ${id}`);
}
// Query:
const youngFriends = await db.friends.where("age").below(25).toArray();
// Show result:
alert ("My young friends: " + JSON.stringify(youngFriends));
}).catch(e => {
alert(e.stack || e);
});
并且这个库这个月内还在维护,因此我将其加入了最主要的待选方案
IDB
不是说这个库不好,主要的问题在于它已经一年多没有维护了,上一个commit还是在22年11月,还有一个问题就是它的API更接近IndexedDB,而不是我们其他熟悉的数据库,就像这样
const tx = db.transaction('keyval', 'readwrite');
const store = tx.objectStore('keyval');
const val = (await store.get('counter')) || 0;
await store.put(val + 1, 'counter');
await tx.done;
你看,它的封装就没有那么和谐,更像是在原本的API上套了一层Promise
PouchDB
这是维护的最勤奋的一个,并且示例看起来真就和MongoDB的原生查询一模一样。。
db.find({
selector: {name: 'Mario'},
fields: ['_id', 'name'],
sort: ['name']
}).then(function (result) {
// handle result
}).catch(function (err) {
console.log(err);
});
支持的查询如下

你会发现它很强大,强大到基本上你要的都支持,但是代价是你得自己去写这个selector,而不是使用已经封装好的API,像下面这样
db.find({
selector: {
debut: {'$gte': null}
},
sort: [{debut: 'desc'}]
}).then(function (result) {
// handle result
}).catch(function (err) {
console.log(err);
});
使用它的话维护成本会很高,毕竟只要换一个库,这些selector都要重写,因此我会选择将它看做是备选方案,可以用来处理更加复杂的情况,而非我们现在的需求
异步存取
最后,我们再讨论一下前端数据异步存取的一点小碎碎念
IndexedDB设计是全部异步的,这意味着JS主线程在进行的操作不会被IndexedDB阻塞,那么,我们还需要那么复杂的索引吗?事实上我觉得其实并没有必要了,复杂的索引会使得数据库越发庞大,而且,IndexedDB这种前端数据库并不支持复合索引,如果要完成类似的效果需求我们进行二层封装,比如手动手动加上索引,Dexie就是这么做的,这是它的实现方式
Compound Index (dexie.org)https://dexie.org/docs/Compound-Index
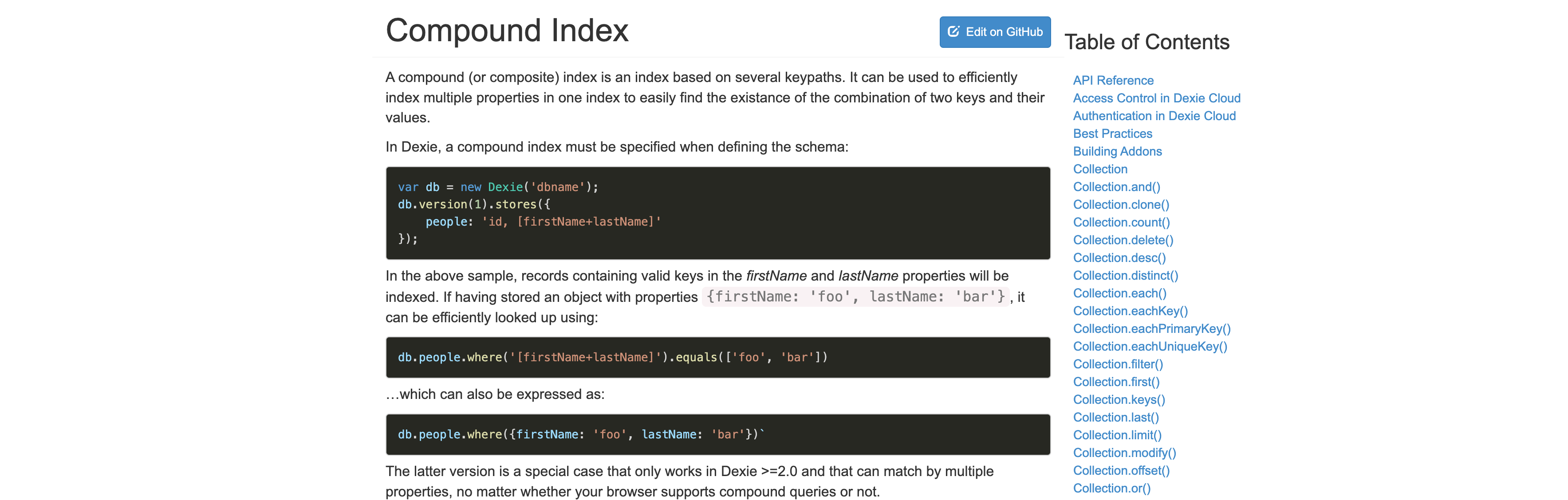
它通过再加上[field1+field2]这样的方式上索引,在indexedDB里大概是这样的
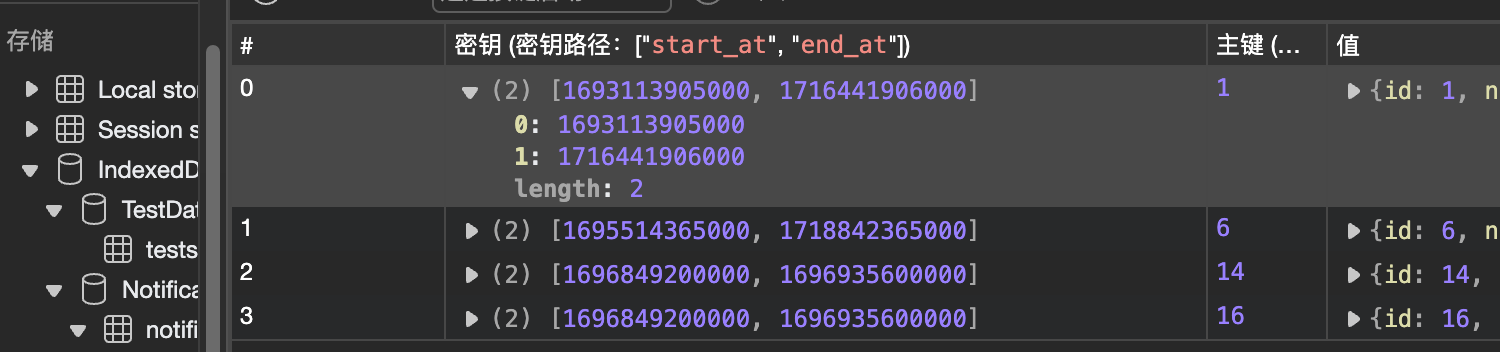
那如果我们有4个需要索引的数据,就意味着我们需要 SUM_1^4{C(4, i)} 个索引,这明显是不好的,但是我们真的需要这么多吗?
注意,前端与后端在数据查询这一块最大的区别应该是一个只用对自己负责,一个要对数以万计的前端负责,因此数据库查询的时候我们会想尽办法做各种各样的索引,为的只是避免数据库爆炸,但是前端呢?
对于用户来说,只要不卡住,数据不要一直不来,那么对用户来说都是可以接受的,这是不是有点像Python中yield想要解决的问题?
在前端,这根本不需要yield,indexedDB天生支持异步,只要其IDBCursor的迭代是异步的就行,我们可以一行一行地处理数据,就算是10w行数据,也只需要不到5s,而这5s不会卡住用户,并且还可以让页面有所响应
比如说我们有一个复杂的查询条件,我们迭代10w行,其中有50行是用户想要的,那么平均每1/10s就会有一条符合条件的数据,并且这个数据可以实时反馈到html中,比如说拿到一行我们就append一行,这不是正好好可以完成一些类似动画的效果?
实验
带着这个思路,我使用dexie进行了一点小小的实现,因为dexie迭代数据的时候使用的是cursor,因此不用担心它会先把所有数据加载进内存再去迭代这种窒息的做法
代码如下
import Dexie, { Table } from 'dexie'
type TestUser = {
id: number,
name: string,
}
class TestDatabase extends Dexie {
public tests!: Table<TestUser, number>
public constructor() {
super("TestDatabase")
this.version(1).stores({
tests: "id"
})
}
}
export const testDatabase = new TestDatabase()
export const testCursor = async () => {
const count = await testDatabase.tests.count()
for(let i = count; i < 50000; i ++) {
await testDatabase.tests.put({
id: i,
name: `测试用户${i}`
})
}
testDatabase.tests.where('id').above(20000).each(obj => {
console.log(obj)
})
}
生成5w行数据,并且测试id大于20000的所有数据(简单测一下索引好不好使而已)
事实就是,迭代这30000行大概3s,并且前端完全不会被阻塞,还是很丝滑
当然,一点索引不用还是不行的,我的做法还是先对一个最常用的字段做索引,在这个索引的前提下做迭代,可以快很多,并且如果就这么迭代可能会导致性能不行,比如说耗电高发热等,那么我们可以选择每迭代个几千次就等个几毫秒再继续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号