
Scrapy爬虫框架快速入门
安装scrapy
pip install scrapy -i https://pypi.douban.com/simple/
安装过程可能遇到的问题
- 版本问题导致一些辅助库没有安装好,需要手动下载并安装一个辅助库Twisted
- 运行时候:ModuleNotFoundError: No module named 'attrs'
pip install attrs --upgrade - 运行时候:Loading "scrapy.core.downloader.handlers.http.HTTPDownload Handler" for scheme "https"
pip install pywin32
创建项目
CMD进入需要创建项目的目录下,输入命令
scrapy startproject ×××

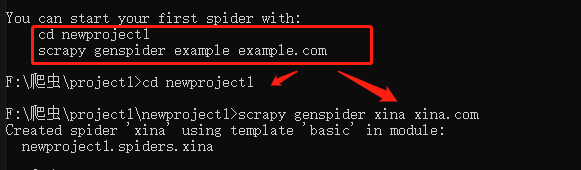
命令基本不需要死记硬背,正如下图所示,会告诉你接下来需要输入的命令
设置实体文件(建立要获取的字段)
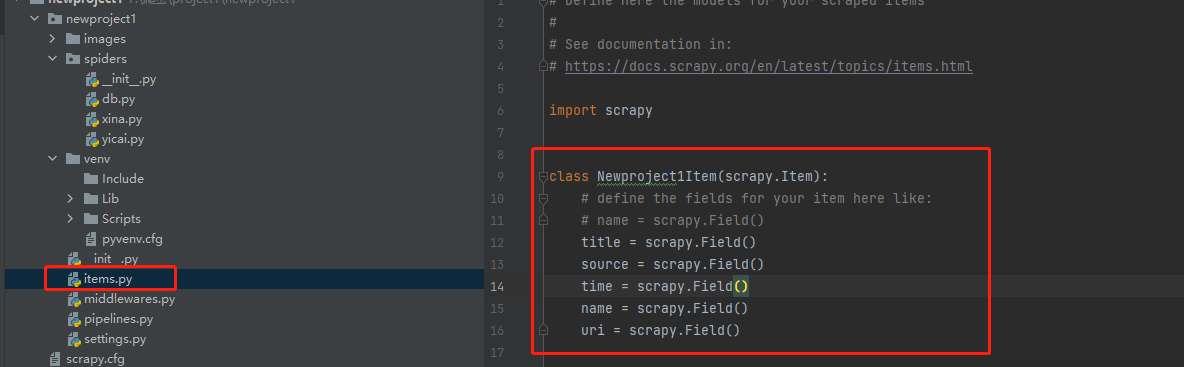
这个文件内会写入后续需要爬取的字段,scrapy.Field()就是变量存储区域,通过“spiders”里的爬虫文件获取的内容都会存储在此处设置的区域里。
然后以实体文件作为中转站,将这些变量传输到其他文件中,例如,传输到管道文件中进行数据存储等处理。设置完实体文件,就可以在实战中应用刚才创建的变量了。
修改设置文件(设置Robots协议和User-Agent,激活管道文件)
运行爬取文件可能会遇到DEBUG:Forbidden by robots txt 说明百度的Robots协议禁止Scrapy框架直接爬取。
解决这个问题可以通过设置文件20行左右的位置把OBEY置为False

设置User-Agent同样在设置文件40行左右位置,添加一行User-Agent

要进行数据的爬后处理,即将数据写入数据库或文件等后续操作。所以先要激活管道
后面的数字只是排序的顺序,越小越靠前
如果管道文件有新增类名,就需要在这里添加

在文件夹“spiders”中编写爬虫逻辑(核心爬虫代码)
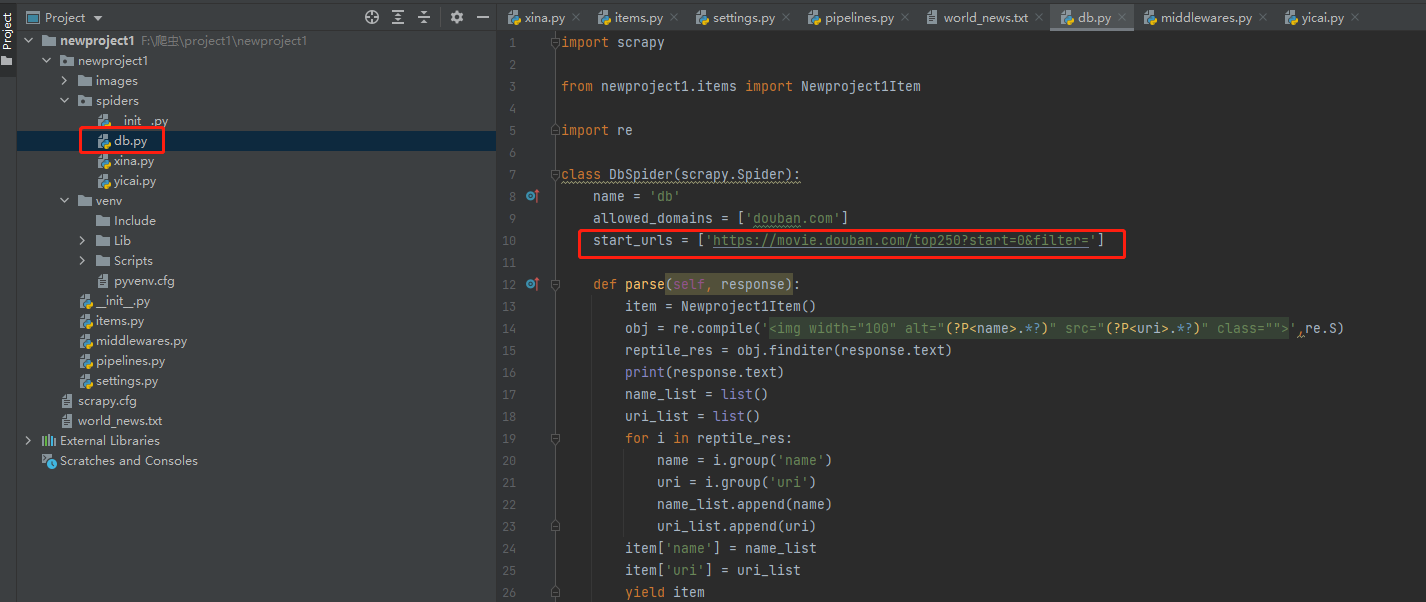
第10 行start_urls是一个列表存放需要爬取的url,如果需要爬取多个地址(例如存在ajex动态页面爬取),可以往这个start_urls列表中append多个地址
爬虫代码基本都在parse中
第13行实例化items,就是实例化需要提取的字段
后面几行都是基本的爬虫代码这里就解释了,需要说一下的是response.text才是网页源代码
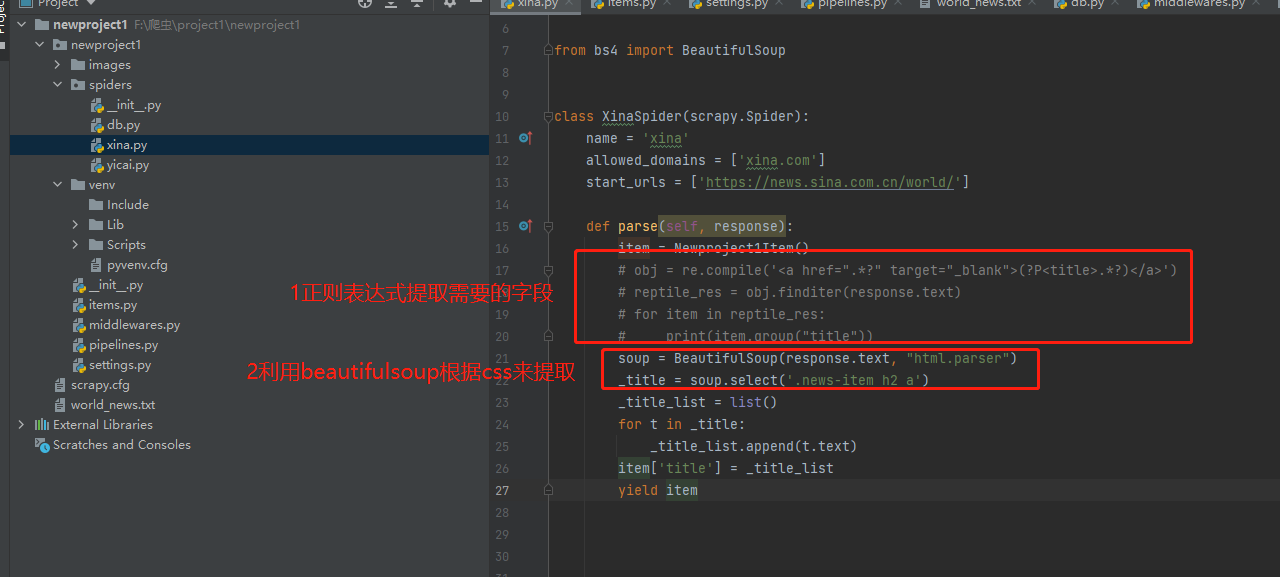
注:除了常见的用正则表达式提取,还有一个库比较常见就是Beautifulsoup
设置管道文件(爬后处理)
爬取后需要存入文件或者下载文件
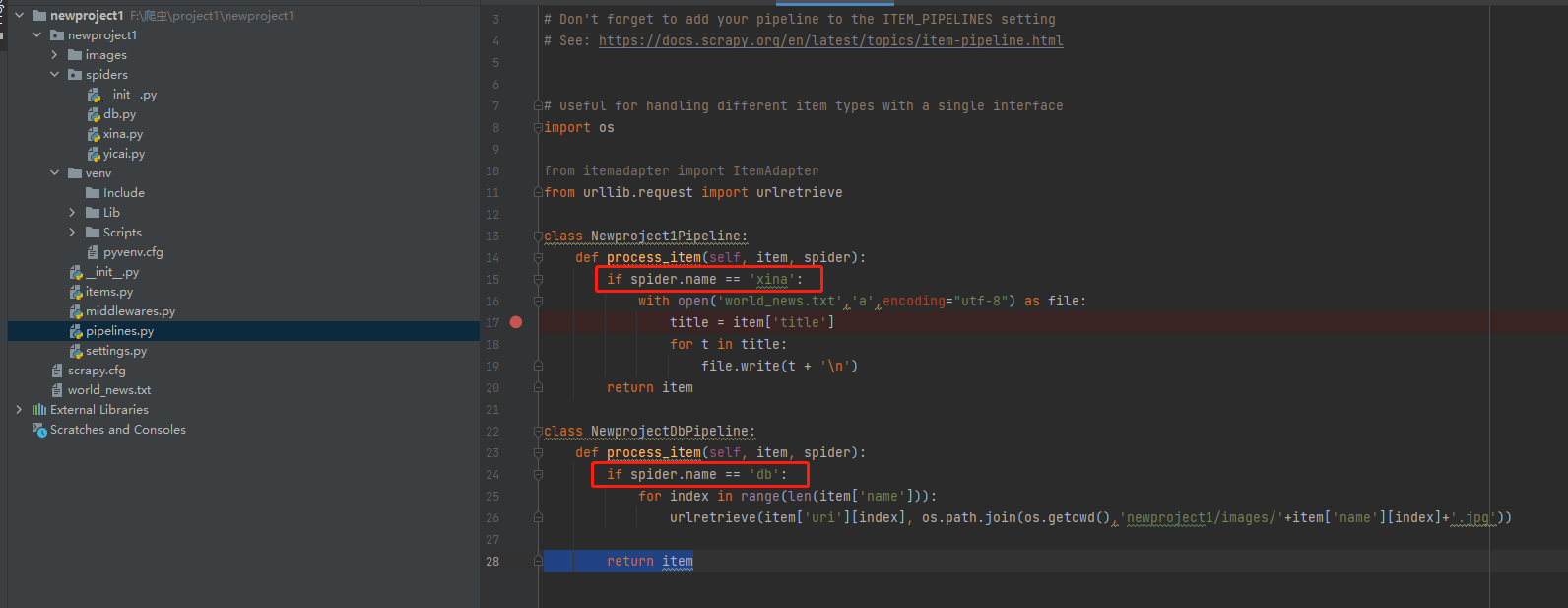
这里需要说一下,第15行和第24行去判断spider.name是为了在运行的时候进行区分。
当然写管道的时候,可以把所有处理方式写在一个类中,通过spider.name去进行区分,也可以像下图一样用不同的类去写。但如果是不同的类就需要到设置文件中把新增类添加到设置中去。
第26行urlretrieve()函数是用来下载图片
最后运行
最后在命令行输入
scrapy crawl ****
作者: yetangjian
出处: https://www.cnblogs.com/yetangjian/p/17057552.html
关于作者: yetangjian
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出, 原文链接 如有问题, 可邮件(yetangjian@outlook.com)咨询.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律