
个人项目
| 这个作业属于哪个课程 | 计算2114 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 1.在github上实现代码的运行 2.对于文本相似度算法的理解 3.遍历代码并对其做出优化 |
需求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
Github仓库链接
PSP表格
| *PSP2.1* | *Personal Software Process Stages* | *预估耗时(分钟)* | *实际耗时(分钟)* |
|---|---|---|---|
| Planning | 计划 | 100 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 500 | 450 |
| Development | 开发 | 120 | 150 |
| · Analysis | · 需求分析 (包括学习新技术) | 200 | 150 |
| · Design Spec | · 生成设计文档 | 60 | 80 |
| · Design Review | · 设计复审 | 20 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 90 | 100 |
| · Coding | · 具体编码 | 90 | 150 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 10 | 30 |
| Reporting | 报告 | 90 | 90 |
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 10 |
| · 合计 | 1370 | 1420 |
运行环境
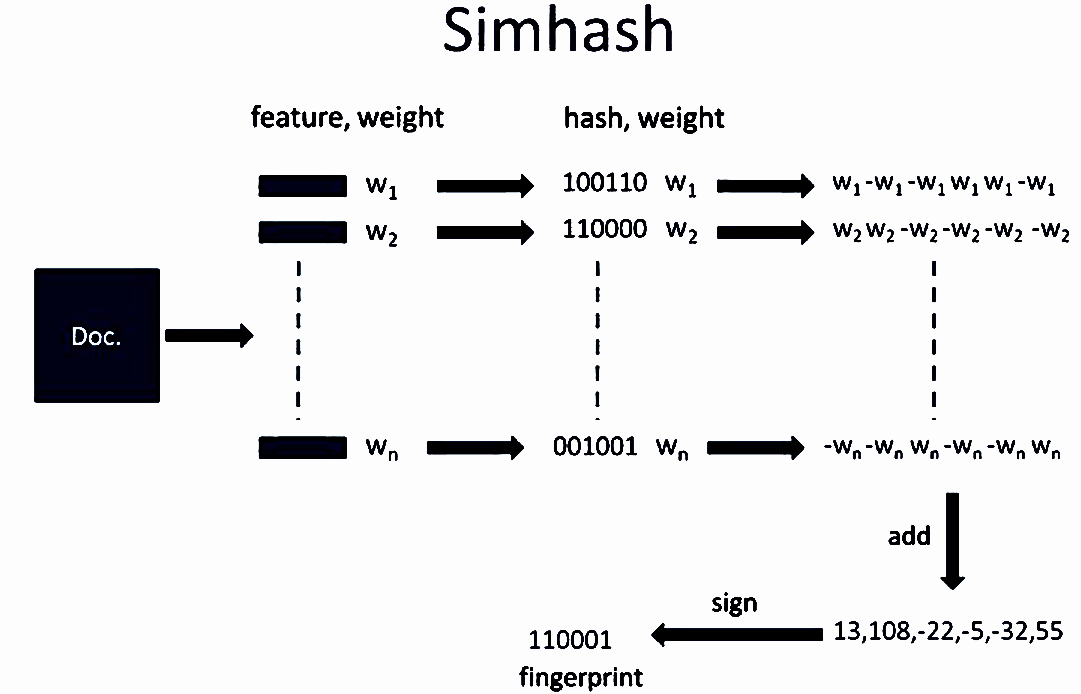
SimHash计算原理
1.分词:对给定的一段文本进行分词,产生n个特征词,并赋予每个特征词一个权重。
2.Hash:通过hash函数对每一个词向量进行映射,产生一个n位二进制串。
3.加权:经过前面的计算已经得到了每个词向量的Hash串和该词向量对应的权重,第三步计算权重向量W=hash*weight。
4.合并:对于一个文本,计算出了文本分词之后每一个特征词的权重向量,在合并这个阶段,把文本所有词向量的权重向量相累加,得到一个新的权重向量。
5.降维:对于前面合并后得到的文本的权重向量,大于0的位置1,小于等于0的位置0,就可以得到该文本的SimHash值。
SimHash算法步骤如下:
1.将一个 f 维的向量 V 初始化为 0 ;f 位的二进制数 S 初始化为 0;
2.对每一个特征用传统的 Hash 算法对该特征产生一个 f 位的签名 b。对 i=1 到 f :如果b 的第 i 位为 1 ,则 V 的第 i 个元素加上该特征的权重;否则,V 的第 i 个元素减去该特征的权重;
3.如果 V 的第 i 个元素大于 0 ,则 S 的第 i 位为 1,否则为 0 ;
4.输出 S 作为签名;
SimHash算法原理图如下:
文本相似度的计算
JAVA通过SimHash计算
一.新增依赖包
package com.b2c.aiyou.bbs.common.utils.hanlp;
import com.hankcs.hanlp.seg.common.Term;
import com.hankcs.hanlp.tokenizer.StandardTokenizer;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.safety.Whitelist;
import java.math.BigInteger;
import java.util.*;
二.过滤特殊字符
/**
* Description:[过滤特殊字符]
*
*/
private String clearSpecialCharacters(String topicName) {
// 将内容转换为小写
topicName = StringUtils.lowerCase(topicName);
// 过来HTML标签
topicName = Jsoup.clean(topicName, Whitelist.none());
// 过滤特殊字符
String[] strings = {" ", "\n", "\r", "\t", "\\r", "\\n", "\\t", " ", "&", "<", ">", """, "&qpos;"};
for (String string : strings) {
topicName = topicName.replaceAll(string, "");
}
return topicName;
}
三.计算单个分词的Hash值
/**
* Description:[计算单个分词的hash值]
*
*/
private BigInteger getWordHash(String word) {
if (StringUtils.isEmpty(word)) {
// 如果分词为null,则默认hash为0
return new BigInteger("0");
} else {
// 分词补位,如果过短会导致Hash算法失败
while (word.length() < SimHashUtil.WORD_MIN_LENGTH) {
word = word + word.charAt(0);
}
// 分词位运算
char[] wordArray = word.toCharArray();
BigInteger x = BigInteger.valueOf(wordArray[0] << 7);
BigInteger m = new BigInteger("1000003");
// 初始桶pow运算
BigInteger mask = new BigInteger("2").pow(this.hashCount).subtract(new BigInteger("1"));
for (char item : wordArray) {
BigInteger temp = BigInteger.valueOf(item);
x = x.multiply(m).xor(temp).and(mask);
}
x = x.xor(new BigInteger(String.valueOf(word.length())));
if (x.equals(ILLEGAL_X)) {
x = new BigInteger("-2");
}
return x;
}
}
四.分词计算向量
/**
* Description:[分词计算向量]
*
*/
private BigInteger simHash() {
// 清除特殊字符
this.topicName = this.clearSpecialCharacters(this.topicName);
int[] hashArray = new int[this.hashCount];
// 对内容进行分词处理
List<Term> terms = StandardTokenizer.segment(this.topicName);
// 配置词性权重
Map<String, Integer> weightMap = new HashMap<>(16, 0.75F);
weightMap.put("n", 1);
// 设置停用词
Map<String, String> stopMap = new HashMap<>(16, 0.75F);
stopMap.put("w", "");
// 设置超频词上线
Integer overCount = 5;
// 设置分词统计量
Map<String, Integer> wordMap = new HashMap<>(16, 0.75F);
for (Term term : terms) {
// 获取分词字符串
String word = term.word;
// 获取分词词性
String nature = term.nature.toString();
// 过滤超频词
if (wordMap.containsKey(word)) {
Integer count = wordMap.get(word);
if (count > overCount) {
continue;
} else {
wordMap.put(word, count + 1);
}
} else {
wordMap.put(word, 1);
}
// 过滤停用词
if (stopMap.containsKey(nature)) {
continue;
}
// 计算单个分词的Hash值
BigInteger wordHash = this.getWordHash(word);
for (int i = 0; i < this.hashCount; i++) {
// 向量位移
BigInteger bitMask = new BigInteger("1").shiftLeft(i);
// 对每个分词hash后的列进行判断,例如:1000...1,则数组的第一位和末尾一位加1,中间的62位减一,也就是,逢1加1,逢0减1,一直到把所有的分词hash列全部判断完
// 设置初始权重
Integer weight = 1;
if (weightMap.containsKey(nature)) {
weight = weightMap.get(nature);
}
// 计算所有分词的向量
if (wordHash.and(bitMask).signum() != 0) {
hashArray[i] += weight;
} else {
hashArray[i] -= weight;
}
}
}
// 生成指纹
BigInteger fingerPrint = new BigInteger("0");
for (int i = 0; i < this.hashCount; i++) {
if (hashArray[i] >= 0) {
fingerPrint = fingerPrint.add(new BigInteger("1").shiftLeft(i));
}
}
return fingerPrint;
}
五.获取文本内容的海明距离
/**
* Description:[获取文本内容的海明距离]
*
*/
private int getHammingDistance(SimHashUtil simHashUtil) {
// 求差集
BigInteger subtract = new BigInteger("1").shiftLeft(this.hashCount).subtract(new BigInteger("1"));
// 求异或
BigInteger xor = this.bigSimHash.xor(simHashUtil.bigSimHash).and(subtract);
int total = 0;
while (xor.signum() != 0) {
total += 1;
xor = xor.and(xor.subtract(new BigInteger("1")));
}
return total;
}
六.获取文本内容的相似度
/**
* Description:[获取文件内容的相似度]
*
*/
public Double getSimilar(SimHashUtil simHashUtil) {
// 获取海明距离
Double hammingDistance = (double) this.getHammingDistance(simHashUtil);
// 求得海明距离百分比
Double scale = (1 - hammingDistance / this.hashCount) * 100;
Double formatScale = Double.parseDouble(String.format("%.2f", scale));
return formatScale;
}
异常处理
try {
// 读取原文文件和抄袭版论文文件的内容
String originalTitle = readTitleContent(originalTitlePath);
String copyingTitle = readTitleContent(copyingTitlePath);
// 计算重复率
double similarity = calculateSimilarity(originalTitle,copyingTitle);
// 将结果写入输出结果文件
writeResult(outputTitlePath, similarity);
// 输出重复率
System.out.println("检测完成,重复率为: " + String.format("%.2f", similarity));
} catch (IOException e) {
System.out.println("发生错误:" + e.getMessage());
e.printStackTrace();
}
测试
public static void main(String[] args) {
// 准备测试文件内容数据
List<String> titleList = new ArrayList<>();
titleList.add("今天是星期天,天气晴,今天晚上我要去看电影。");
titleList.add("今天是周天,天气晴朗,我晚上要去看电影。");
// 原始文件内容数据
String originalTitle = "今天是星期天,天气晴,今天晚上我要去看电影。";
Map<String, Double> simHashMap = new HashMap<>(16, 0.75F);
System.out.println("======================================");
long startTime = System.currentTimeMillis();
System.out.println("原始文件:" + originalTitle);
// 计算相似度
titleList.forEach(title -> {
SimHashUtil mySimHash_1 = new SimHashUtil(title, 64);
SimHashUtil mySimHash_2 = new SimHashUtil(originalTitle, 64);
Double similar = mySimHash_1.getSimilar(mySimHash_2);
simHashMap.put(title, similar);
});
// 打印测试结果到控制台
/* simHashMap.forEach((title, similarity) -> {
System.out.println("文件:"+title+"-----------相似度:"+similarity);
});*/
// 按相文本内容排序输出控制台
Set<String> titleSet = simHashMap.keySet();
Object[] titleArrays = titleSet.toArray();
Arrays.sort(titleArrays, Collections.reverseOrder());
System.out.println("-------------------------------------");
for (Object title : titleArrays) {
System.out.println("文本:" + title + "-----------相似度:" + simHashMap.get(title));
}
// 求得运算时长(单位:毫秒)
long endTime = System.currentTimeMillis();
long totalTime = endTime - startTime;
System.out.println("\n本次运算总耗时" + totalTime + "毫秒");
System.out.println("======================================");
}
接口设计与类名
| 类名 | 实现方法 |
|---|---|
| main | main方法 |
| SimHash类 | getWordHash,BigInteger simHash,BigInteger simHash,getSimilar |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号