

自制操作系统教程(持续更新)
由于本文过长,以至于把后台编辑和前台渲染都干碎了,目前已经迁移至 我的博客(备用地址),当然这里的文章也不会删除,只是去那两个地址会有更好的体验
-1.写在开始之前
虽然网上此类教程云集,虽然此类书籍很多,但是!
这些书籍有很多地方讲得不够细致(主要是代码有缺漏),有些对代码的更改甚至在书中了无痕迹。
而这才是我开启这篇教程的原因。
这篇教程之中,只要照着所有的操作做了一遍,以您 OIer 的水平,应当能够写出完整的操作系统!
本教程默认各位读者是会汇编的,或者说,至少应该能看懂汇编。
与其说这篇文章是个教程,倒不如说是一个学习笔记和我自身编程经验的记录。
0.开发环境配置
如果您使用的是 Linux,我们只需要输入下面一行命令即可完成开发环境的配置:
sudo apt-get install nasm build-essential qemu-system-x86
如果您使用的 Linux 中不含有 apt 系列包管理器,请使用您系统中的包管理器。
如果您使用的是 Linux,但您的系统内没有包管理器,那么您可以去 nasm 官网、 gcc 官网和 qemu 官网下载源码,然后 configure -> make -> sudo make install。
如果您使用的是 Windows,请去以下地方获取所需要的工具:
交叉编译的gcc(请下载i686-elf-tools-windows.zip)
bochs(其实我们只需要其中的 bximage.exe )(如果是 32 位电脑请下载 2.5 以前的版本)
edimg(这个就是《30天自制操作系统》的写盘工具)
如果您使用的是 macOS,那么请注意,系统内置的 gcc 会把文件编译成 Mach-O 格式,请通过 Homebrew 下载交叉编译器:
brew install i386-elf-binutils
brew install i386-elf-gcc
然后我们还需要去往 nasm 官网获取可执行文件,并执行:
brew install qemu
以获取 qemu。
在安装完之后,如果您使用的是 Windows,请确保它们的路径位于 PATH 下!
除此之外便没什么重点了,不过,对于下文给出的工具名称默认以 Windows 为准,若您使用 Linux,请去掉工具前缀,若您使用 macOS,请将工具前缀中的 i686 改为 i386!!!
对了,如果您使用的是 Linux 或 macOS,请确保您在 dd 命令的后面加入 conv=notrunc !!!
那么,开发环境配置正式结束,征程开始!
1.第一个引导扇区
所谓引导扇区,其实就是一段可执行的代码而已,不过加入了一个小限制:编译后的总字节数不能超过 512,同时扇区(一个 512 字节的连续区域,一般在磁盘里)最后两个字节必须是 0x55 0xAA 。
虽然现在看来这个限制并不怎样,但一到后面再回过头来,您将会发现这是一个非常恶心的限制。不过没关系,对于现在的我们来说,这个限制并不大。
那么我们的目标就是用一些功能往屏幕上输出信息。现在这个阶段,除了我们之外,还活着的也就一个 BIOS 了。万幸的是,BIOS 提供了显示字符串的方法,具体用法如下:
向下列寄存器中依次存入:
AH=13h:输出信息
BH=页码(一般可以置0)
BL=属性(当al=0或1时才有用)
CX=字符串长度
(DH, DL):行和列
ES:BP:字符串地址
AL=输出方式
AL=0:仅含显示字符,字符属性(颜色等)位于 BL 中。显示后,光标位置不变。
AL=1:同 AL=0,但显示后光标位置改变。
AL=2:字符串中含有显示字符和显示属性。显示后,光标位置不变。
AL=3:同 AL=2,但显示后光标位置改变。
然后执行
int 10h。
寄存器可以近似理解为变量,这里面的 AH、BH、BL、DH、DL 这些都是寄存器。怎么操作它们呢?且看待会的代码。
这里面有个东西叫 ES,它与其他寄存器不同,它是段寄存器。至于段寄存器是什么, ES:BP 又是什么意思,且看下文说明。
那么此次我们要使用的就是 AH=13h AL=01h 的显示方法,即显示字符串后光标移动。
知道怎么显示字符串,主体部分的代码除了汇编的语法以外就没有理解障碍了。鉴于是第一段代码,我们还是来做一个阅读理解吧:
代码 1-1 最简单的引导扇区(boot.asm)
org 07c00h ; 告诉编译器程序将装载至0x7c00处
mov ax, cs
mov ds, ax
mov es, ax ; 将ds es设置为cs的值(因为此时字符串存在代码段内)
call DispStr ; 显示字符函数
jmp $ ; 死循环
DispStr:
mov ax, BootMessage
mov bp, ax ; es前面设置过了,所以此处的bp就是串地址
mov cx, 16 ; 字符串长度
mov ax, 01301h ; 显示模式
mov bx, 000ch ; 显示属性
mov dl, 0 ; 显示坐标(这里只设置列因为行固定是0)
int 10h ; 显示
ret
BootMessage: db "Hello, OS world!"
times 510 - ($ - $$) db 0
db 0x55, 0xaa ; 确保最后两个字节是0x55AA
汇编语言大小写不敏感,因此我们把所有的指令和寄存器都搞成了小写。汇编语言也不存在 main 函数,会从第一行开始顺次往下执行(当然如果遇到跳转会跳走,这个流程类似 Python),因此我们也一行一行的看。
第一行,org 07c00h,意义已经写在注释里,但是为什么要这么做?这是因为,按照硬件规程(这个词汇后面还会出现多次),BIOS 在执行完自检等一系列操作以后,将执行位于 0x7c00 处的代码。07c00h,与 0x7c00 同义;同理,0(管你是啥)h 和 0x(管你是啥) 也同义。这样,下面的代码才有被执行到的机会。由于它实际上不会产生任何机器码,因此它也被叫做伪指令。
下面的 mov ax, cs,可以近似理解为 ax = cs,这里的 ax 也是寄存器,cs 也是寄存器,但这两者并不尽相同:ax 被称为通用寄存器,顾名思义可以随便用;而 cs 则是段寄存器,段与内存有莫大的关系,如果乱动将导致内存操作不合预期,这个 cs 更是和 code 有关,乱动会导致执行出故障,因此除了某些必然更改的方法以外,它一般都是只读的。
接下来的两个 mov 本身,我想读者可以自己引申理解。这其中,ds 和 es 也是段寄存器。段与内存有什么关系呢?在刚刚进入引导扇区的实模式下,我们认为一个段管理 64KB 内存。如果某个段寄存器的数值是 x,那么从 x * 16 开始的 64KB 就归它管,x 本身则代表一个段。这样的寻址方法,用 段寄存器:寻址寄存器 来表示。或许有人就要问了:
唉,这不对啊,那两个段难道不会重合么?
好问题,两个段还真会重合。那么重合部分的内存归谁管呢?段寄存器里是哪个段,这个内存就归谁管。
至于这个寻址寄存器又是什么东西,由于我们不会在实模式待太久(我是不是听到了“还有其他模式?”),所以就先不解释了。
这里之所以要把 ds 和 es 用 cs 赋值,则又是因为这两者在 BIOS 执行期间可能还存着 BIOS 时期的段,如果不进行覆写,后面的 int 10h 会觉得我要从 BIOS 的某处取字符串,实际则应该从执行代码的某处读字符串,而后者是由 cs 进行表示的。
然后 call DispStr,这个可以近似理解为 DispStr();。至于具体发生了什么,由于本节教程(甚至可能一直到很后面的教程)都没有用到,所以先不解释,用到了再说。
最后这个 jmp $,相当于 while (1);。但是需要注意,jmp 并不是循环,它是一个跳转语句,和 goto 反而更为接近。$ 则表示这条指令的起始地址。这么一来,这条指令就相当于跳转到这条指令开始的位置,从而继续执行跳转,于是就起到了无限循环的作用。
然后是 DispStr:,它既可以表示 void DispStr(),也可以干脆作为 goto 的标签名,从后面的介绍还可以知道,它还能表示更多的意思,就先不说了。
下面 mov ax, BootMessage,相当于 ax = BootMessage。这个 BootMessage 又是从什么地方来的?仔细观察发现,原来就在下面,BootMessage: db "Hello, OS world!"。这个 db 也是个伪指令,作用是把后面的东西原样写进内存,不管它是一个数,一串数,或是一个字符串,只要它或它的每一个最小单元都在一个字节的范围内,就从头开始到最后,依次把这个数原样写在生成的文件里。大概相当于这样:
db 0x55, 0xaa -> char sth[] = {0x55, 0xaa};
db "Hello, OS World! -> char sth[] = "Hello, OS World!"
db 0x55 -> char sth[] = {0x55}
这个 db 其实也是一系列伪指令里的一个,还有 dw 和 dd,分别是把那个数组的类型改成了 short 和 int。再往上还有更大尺度的,但是我们用不到。
把一个 BootMessage: 加在 db 前面,就相当于把这一串数组的名字给搞成了 BootMessage。也就是说,
BootMessage: db "Hello, OS world!" 等价于 char BootMessage[] = "Hello, OS world!"
因此这个 mov 代表的意思,就相当于是把 BootMessage 对应的内存地址赋值给了 ax。
接下来 mov bp, ax,就是 bp = ax。或许有人要问:
那么为什么不直接
bp = BootMessage呢,转写成汇编就是mov bp, BootMessage?这样难道不是效率更高、指令更少吗?
这是因为,有的寄存器不能直接使用内存地址和数字(我们统称这俩为立即数,意思是可以立即知道数值的数)赋值,比如段寄存器。虽然 bp 不在此列,但为了保险的需要,还是使用 ax 进行中转。
接下来就是按照要求,依次对这些寄存器进行写入了。先是 mov cx, 16(cx = 16),这是手动计算的下面字符串的长度;然后 mov ax, 01301h(ax = 0x1301)、mov bx, 000ch(bx = 0x000c),再之后是 mov dl, 0 设置在第 0 列显示。由注释可知,这是因为我们默认此时的 dh 是 0 的缘故。神奇的事情发生了,我们好像并没有对 ah、al、bh、bl 赋值!这又是为什么呢?
如果您的观察比较敏锐,那么就会发现,ah 本该获得的 0x13,被放在了 ax 的高 8 位;al 本该获得的 0x01,被放在了 ax 的低 8 位。难道说……?
没错!ah 和 al,其实就代表了 ax 的高8位和低8位(这也是它们 h 和 l 的来源)。同理,bh、bl 对应 bx,ch、cl 对应 cx,dh、dl 对应 dx。其余的通用寄存器:di、si、sp 和 bp,没有对应的 h 和 l。
接下来的 int 10h,相当于在调用库函数,上面的 ah 什么的都是参数。如果硬要类比,可能类似于这样:
sort(v.begin(), v.end(), cmp);,int 10h 就类似 sort(只是角色,功能很不同),v.begin()、v.end()、cmp 作为参数则和那些寄存器类似(当然后面知道其实也很不同)。
最后的 ret,相当于 return ax;。这个返回值怎么处置,最终是由调用方说了算。
下面的 BootMessage 那一行已解释过,再往下比较有意思,times 510 - ($ - $$) db 0,这是在干什么,发刀乐么?
先说 times。times xxx aaa,相当于做 xxx 次 aaa。times 本身也就是个伪指令。一般 times 都与 db 系列的伪指令配合使用,和其他的联合使用的,我是没见过例子。
下面的 $ 已经解释过,表示现在这个指令的起始内存地址,以此类推,其实伪指令的起始地址也可以用 $ 表示;$$ 则比较复杂,不过在这个语境下,可以默认它是 0。也就是说,写成 times 510 - $ db 0 也是没有问题的。
最后 db 0x55, 0xAA,是为了顺应硬件规程的需要,“扇区最后两个字节必须是 55 AA”。一个扇区一共 512 个字节,所以先把最后这一句一直到 510 字节填充成 0,然后写 55 AA,就能够保证这个二进制是一个符合硬件规程的扇区,从而能够被执行。
程序读完了,想必在这之前大家也写 抄 好了,我们该怎么运行呢?首先编译一下:
nasm boot.asm -o boot.bin
对于 Linux 和 macOS 用户而言,只需要下面两行命令就可以完成软盘映像的创建与写入:
dd if=/dev/zero of=a.img bs=512 count=2880
dd if=boot.bin of=a.img bs=512 count=1 conv=notrunc
如果您使用的是 Windows,那么需要执行 bximage。下面是使用 bximage 创建软盘映像的实例:
> bximage
========================================================================
bximage
Disk Image Creation Tool for Bochs
$Id: bximage.c,v 1.34 2009/04/14 09:45:22 sshwarts Exp $
========================================================================
Do you want to create a floppy disk image or a hard disk image?
Please type hd or fd. [hd] fd
Choose the size of floppy disk image to create, in megabytes.
Please type 0.16, 0.18, 0.32, 0.36, 0.72, 1.2, 1.44, 1.68, 1.72, or 2.88. [1.44]
I will create a floppy image with
heads=2
sectors per track=18
total sectors=2880
total bytes=1474560
What should I name the image? [a.img]
Writing: [] Done.
I wrote 1474560 bytes to a.img.
The following line should appear in your bochsrc:
floppya: image="a.img", status=inserted
(The line is stored in your windows clipborad, use CTRL-V to paste)
Press any key to continue
>
硬盘镜像制作完成之后,我们再执行一条写入命令:
dd if=boot.bin of=a.img bs=512 count=1
注意,Windows 下的 dd 不支持 conv 选项。
另外,如果您的 boot.bin 被报毒 KillMBR,请不要惊慌,因为它就是一个 MBR,因此被判为覆盖 MBR 的病毒非常正常,默认不做操作即可。
无论是上述哪种情况,在制作完成之后,直接执行一行命令来执行:
qemu-system-i386 -fda a.img
如果您的执行结果如下图,那么恭喜您,您的引导扇区成功执行了!
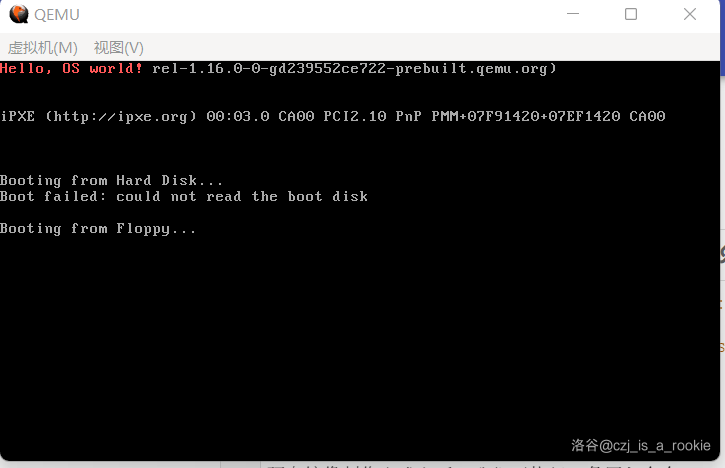
(图 1-1 运行结果)
无论您使用的是哪种虚拟机,只要左上角出现 Hello, OS world! 就算是成功。
2.FAT12 文件系统
前面我们花了极大的篇幅来写一个极简引导扇区的实现,但是本节相比之下就要短很多了,我们要在我们的软盘中创建 FAT12 文件系统,这样后续我们写入 Loader 和 Kernel 就要方便很多了。
一个磁盘中有没有文件系统,是依靠什么来进行标识的呢?一般而言,每一个文件系统都有特定的一个结构用来描述自己,无论是 ext2 的 metadata 块,还是 FAT12/16/32 在引导扇区中加入的 BPB,都是一种对文件系统的标识。
BPB 的具体结构如下图所示(实在懒得打列表了,干脆搬了一张网图):
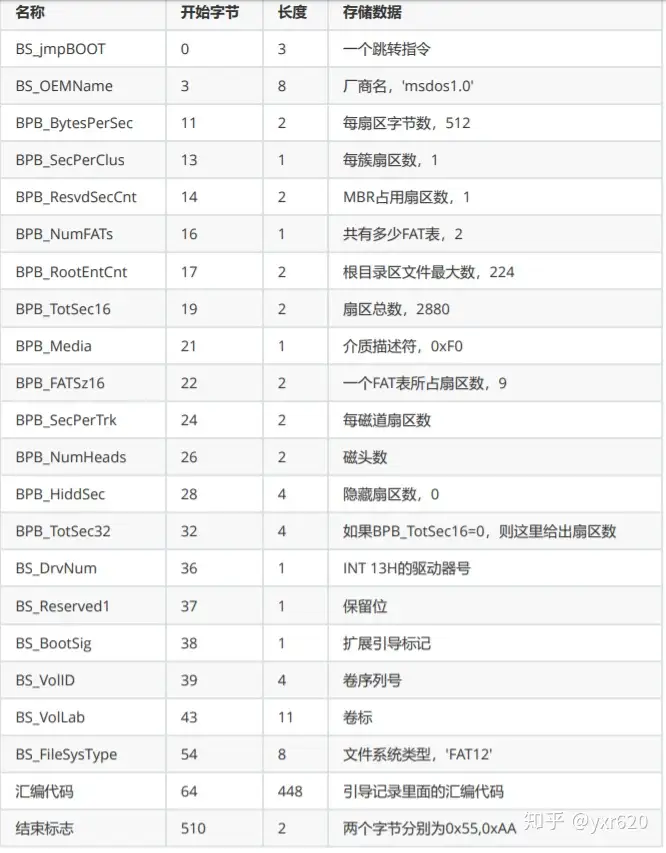
(图 2-1 BPB 的结构)
如诸位所见,FAT12 文件系统头占用了汇编程序开头的 64 个字节。这下可用的空间又少了 64 字节(泪目)
不过它也带给我们一个好处,一般的 FAT 实现都认为只要有 BPB 就是有 FAT 文件系统(有的实现甚至不会管 BPB),这样就可以用一些工具来方便地操作磁盘了。
那么我们就依照此结构写入一下这些结构吧:
代码 2-1 FAT12 文件系统头(boot.asm)
org 07c00h ; 告诉编译器程序将装载至0x7c00处
jmp short LABEL_START
nop ; BS_JMPBoot 由于要三个字节而jmp到LABEL_START只有两个字节 所以加一个nop
BS_OEMName db 'tutorial' ; 8个字节,内容随意
BPB_BytsPerSec dw 512 ; 每扇区固定512个字节
BPB_SecPerClus db 1 ; 每簇固定1个扇区
BPB_RsvdSecCnt dw 1 ; MBR固定占用1个扇区
BPB_NumFATs db 2 ; FAT12 文件系统固定2个 FAT 表
BPB_RootEntCnt dw 224 ; FAT12 文件系统中根目录最大224个文件
BPB_TotSec16 dw 2880 ; 1.44MB磁盘固定2880个扇区
BPB_Media db 0xF0 ; 介质描述符,固定为0xF0
BPB_FATSz16 dw 9 ; 一个FAT表所占的扇区数,FAT12 文件系统固定为9个扇区
BPB_SecPerTrk dw 18 ; 每磁道扇区数,固定为18
BPB_NumHeads dw 2 ; 磁头数,bximage 的输出告诉我们是2个
BPB_HiddSec dd 0 ; 隐藏扇区数,没有
BPB_TotSec32 dd 0 ; 若之前的 BPB_TotSec16 处没有记录扇区数,则由此地址记录,如果记录了,这里直接置0即可
BS_DrvNum db 0 ; int 13h 调用时所读取的驱动器号,由于只有一个软盘所以是0
BS_Reserved1 db 0 ; 未使用,预留
BS_BootSig db 29h ; 扩展引导标记,固定为 0x29
BS_VolID dd 0 ; 卷序列号,由于只挂载一个软盘所以为0
BS_VolLab db 'OS-tutorial' ; 卷标,11个字节,内容随意
BS_FileSysType db 'FAT12 ' ; 由于是 FAT12 文件系统,所以写入 FAT12 后补齐8个字节
LABEL_START: ; 后面就是正常的引导代码
mov ax, cs
mov ds, ax
mov es, ax ; 将ds es设置为cs的值(因为此时字符串存在代码段内)
call DispStr ; 显示字符函数
jmp $ ; 死循环
DispStr:
mov ax, BootMessage
mov bp, ax ; es前面设置过了,所以此处的bp就是串地址
mov cx, 16 ; 字符串长度
mov ax, 01301h ; 显示模式
mov bx, 000ch ; 显示属性
mov dl, 0 ; 显示坐标(这里只设置列因为行固定是0)
int 10h ; 显示
ret
BootMessage: db "Hello, OS world!"
times 510 - ($ - $$) db 0
db 0x55, 0xaa ; 确保最后两个字节是0x55AA
按上文的方法编译运行,结果仍应如图 1-1 所示。虽然显示结果没有变化,但此时的软盘已经拥有了 FAT12 文件系统。
3.查找 Loader
总是困在小小的引导扇区之中,也不是长久之计,毕竟只有 446 个字节能给我们自由支配,而保护模式的栈动不动就 512 字节,一个引导扇区完全盛不下。所以我们有必要进入一个跳板模块,并在其中进行初始化工作,再进入内核。
这时候又该有人问了:
啊所以为什么不直接进内核呢?
emmm,事实上也有这种系统(比如 haribote),但这样的一个缺点就是你的内核文件结构必须很简单甚至根本没有结构才行。
所以我们还是老老实实地跳入 Loader 再进内核吧,不过话说回来,我们现在连一个正经八百的 Loader 都还没有,不着急,我们马上创建一个:
代码 3-1 极简 Loader(loader.asm)
org 0100h
mov ax, 0B800h
mov gs, ax ; 将gs设置为0xB800,即文本模式下的显存地址
mov ah, 0Fh ; 显示属性,此处指白色
mov al, 'L' ; 待显示的字符
mov [gs:((80 * 0 + 39) * 2)], ax ; 直接写入显存
jmp $ ; 卡死在此处
这个 Loader 的作用很简单,只是在屏幕第一行的正中央显示一个白色的 “L”。不过,它还是需要一些解释的。
首先第一行想必不用解释,不管它加载到了什么段,都把它加载到 0x100 的偏移处。接下来两行让 gs = 0xB800,由第一节的知识可知,这个 gs 管的是从 0xB8000 开始的 64KB,而这个位置恰好(虽然没那么大)是文本模式下的显存,这里但凡有风吹草动,都会被立即显示在屏幕上。
0Fh 代表白色,'L' 代表字符。把它们分别放在 ah 和 al,组成的 ax 就是一个可以被显示的字符了。对于任意一个字符而言,都需要用高 8 位放颜色,低 8 位放字符本身,然后再进行显示。
最后一行出现了我们没见过的 [],它是什么意思?我们先把这个 [] 去掉看看。gs:((80 * 0 + 39) * 2),这像是一个坐标。确实如此,文本模式的显存横向为 80 字符,纵向为 25 字符。前面的 80 * 0,代表第 0 行,同样,80 * k 就代表第 + 39,自然就表示第
那么为什么这个坐标要乘
最后加上前面的 gs:,我们就得到了这个字符将要被显示的内存地址。而加上这个中括号,就意味着往这个地址对应的内存里写入东西,这里是 ax。至此,只要它被执行到,就可以在屏幕上显示一个白色 L。
想要执行 Loader,自然需要先把它读取到内存,然后跳转过去;而想要读取 Loader,自然需要先找到它。
于是现在最主要的问题就变成了:我们应该怎样寻找 Loader 呢?
这个很简单,在根目录区中是一个一个一个 32 字节的文件结构,其中就包含文件名,我们在根目录区中查找即可。
依照 FAT12 文件系统的结构规定,根目录区排在 FAT 表和引导扇区后面,因此它的起始扇区是 BPB_RsvdSecCnt + BPB_NumFATs * BPB_FATSz16 = 19 号扇区;它的结束位置则是 19 + BPB_RootEntCnt * 32 / BPB_BytsPerSec = 33 号扇区。在第一节也曾提到,扇区是一个长度为 512 字节的结构,大多数时候位于磁盘中。不过它还有一个地位,那就是磁盘读写的最小单位。当我们说第某某扇区或者是某某号扇区时,默认它从 0 开始,也就是说引导扇区是第 0 个而非第 1 个扇区。
于是我们的思路便有了:从第 19 号扇区开始,依次读取每一个扇区,并在读到的扇区中查找 LOADER BIN(loader.bin写入之后的文件名)。如果已经读到第 34 扇区而仍然没有找到 LOADER BIN,那么就默认该磁盘内不存在 loader 。至于怎么找 LOADER BIN,现在没有实现那么多高级算法的条件,只有一个小窍门:根目录区是从某某扇区开始的,而某某扇区的开始位置,一定是 512 的倍数,从而一定是 32 的倍数。那么,我们就只需要遍历开头 11 字节,若不等于 LOADER BIN,则先指回开头,然后加 32,就来到了下一个文件结构。由于某某扇区的开始位置是 32 的倍数,所有文件信息的开始位置也都是 32 的倍数,从而指回开头可以通过位运算实现:32=0b100000,所以只需要与上
那么我们该怎么读取磁盘呢?事实上,BIOS 也给我们提供了这个功能:
向下列寄存器中依次存入:
AH=02h,表示读取磁盘
AL:待读取扇区数
CH:起始扇区所在的柱面
DH:起始扇区所在的磁头
CL:起始扇区在柱面内的编号
DL:驱动器号
ES:BX:读入缓冲区的地址
然后执行
int 13h。返回值:
FLAGS.CF=0:操作成功,AH=0,AL=成功读入的扇区总数
FLAGS.CF=1:操作失败,AH 存放错误编码
这里又出现了一堆新名词,柱面、磁头,这又是什么?这是在物理上磁盘的存储结构,具体的结构不需要知道,你只需要知道,每一个磁盘有两面,分别对应上下两个磁头,编号为
由于这种寻址方法太过具体,要给的参数太多,现在已经普遍弃用这种指定扇区的方法;由于用到柱面 Cylinder、磁头 Head 和磁头内的扇区编号 Sector,这种方法被称为 CHS 方式。现在一般采用直接指定总的扇区编号的方法,这个扇区编号又有一个名字叫做逻辑区块地址(Logical Block Address),所以这种方法又被称为 LBA 方式。之所以现在突然提到这个,是为了给后面一个方便,以后就可以叫 CHS、LBA 了,更何况 LBA 这个概念我们后面还要用到。从上面的描述也可以大致猜出,为什么 CHS 里 C 排在 H 前面,实话说不查资料谁能想到啊。
还有一个更坑的点,CHS 方式下的第一个扇区是
总之,我们现在最大的需求,又变成了把 LBA 方式下的扇区转换成 CHS 的形式。我们先从扇区找到柱面,然后从柱面找到磁头,这一流程大概是这样的:
首先,用 LBA 方式的扇区去除每磁道扇区数,这个东西写在了 BPB 里。前面定义 BPB 用的都是 db、dw、dd,也就是存了一堆数组。其中,BPB_SecPerTrk 表示每个磁道(其实就是柱面)有多少个扇区,它大概长这样:short BPB_SecPerTrk[] = {18};。所以,读取的时候也要读内存地址,也就是类似 *BPB_SecPerTrk 的东西。如果您有一定 C 语言储备,就知道它相当于 BPB_SecPerTrk[0]。这样,商就对应柱面,余数就是这个扇区在柱面内的位置,CHS 的 S 就已经到手了。由于 CHS 方式与 LBA 方式起始扇区的不同,这里需要给余数加 1。
再然后,从柱面找磁头,由上面的描述可以推知,给柱面除以 2,余数就是磁头,商就是对应的那个柱面。举个例子看看,第 36 扇区除以 18,可以知道是第 2 个柱面(这个玩意也是从 0 开始),而它对应的磁头则在正面,隶属 0 磁头;第 35 扇区除以 18,是第 1 个柱面,而它则在背面,隶属 1 磁头。这是因为沿着扇区号走下去时,磁头整体上呈一个 0、1、0、1 交替的态势(具体地说,是一段 0、一段 1 这么交替下去的)。
这样,就可以从 LBA 中一个单独的扇区号,完整地推出 CHS 三个分量的值。那么,我们也就只需要一个 LBA 扇区号就行了,上面的 BIOS 调用中,CH、DH、CL 可以归一。而驱动器号,则明明白白地写在 BS_DrvNum 这个数组里(它也是由 db 定义的),到时候从这个数组取值就行了,DL 也可以不要。这样,就只剩下三个必要的参数:缓冲区 ES:BX、读取扇区数 AL 以及起始扇区号。由于起始扇区号可能很大,我们把它分配给 AX,原先读取扇区数的位置就随便挑个东西给了,就 CL 吧。
返回值中,错误编码我们并不需要,只需要保证 FLAGS.CF 的值为 0 就可以了。对此,我们可以执行一个 jc 跳转命令,它的作用是当 FLAGS.CF 为 1 时跳转。在这个案例里,我们让它多试几遍,不要因失败而放弃,每次让它在出错的时候跳转回读取循环的开头重新读入。
思路有了,读盘功能也有了,我们就开始写程序吧。首先在 DispStr 函数的后面加入一个读取扇区的函数 ReadSector,它的作用上面已经讲过,从第 ax 号扇区开始,连续读取 cl 个扇区到 es:bx。
代码 3-2 读取软盘的函数(boot.asm)
ReadSector:
push bp
mov bp, sp
sub esp, 2 ; 空出两个字节存放待读扇区数(因为cl在调用BIOS时要用)
mov byte [bp-2], cl
push bx ; 这里临时用一下bx
mov bl, [BPB_SecPerTrk]
div bl ; 执行完后,ax将被除以bl(每磁道扇区数),运算结束后商位于al,余数位于ah,那么al代表的就是总磁道个数(下取整),ah代表的是剩余没除开的扇区数
inc ah ; +1表示起始扇区(这个才和BIOS中的起始扇区一个意思,是读入开始的第一个扇区)
mov cl, ah ; 按照BIOS标准置入cl
mov dh, al ; 用dh暂存位于哪个磁道
shr al, 1 ; 每个磁道两个磁头,除以2可得真正的柱面编号
mov ch, al ; 按照BIOS标准置入ch
and dh, 1 ; 对磁道模2取余,可得位于哪个磁头,结果已经置入dh
pop bx ; 将bx还原
mov dl, [BS_DrvNum] ; 将驱动器号存入dl
.GoOnReading: ; 万事俱备,只欠读取!
mov ah, 2 ; 读盘
mov al, byte [bp-2] ; 将之前存入的待读扇区数取出来
int 13h ; 执行读盘操作
jc .GoOnReading ; 如发生错误就继续读,否则进入下面的流程
add esp, 2
pop bp ; 恢复堆栈
ret
这里出现了很多没有见过的东西,鉴于实在是有点多,所以我这里把它转写为类似 C 的程序:
代码 3-2 的转写(主体部分)
void ReadSector(short ax, short cl, short *es:bx)
{
save(cl); // 在栈里保存cl,但这个和存 bx 有很大不同,待会再说
push_to_stack(bx); // 暂存bx
bl = BPB_SecPerTrk[0]; // 18
short quot = ax / bl, remain = ax % bl; // quot -> 商,是从0开始位于第几个柱面;remain -> 余数,是柱面内第几个扇区
ah = remain, al = quot; // div bl的效果就是这样
ah++; // inc ah
cl = ah; // cl:起始扇区在柱面内编号,已获得
dh = al; // dh:从0开始的柱面号
al >>= 1; // shr al, 1,此时的al为柱面号
ch = al; // ch:柱面号,已获得
dh &= 1; // dh:磁头号,已获得
// 至此 LBA 格式的 ax 已经成功转换为 CHS 格式的 cl、ch 和 dh
pop_from_stack(bx); // 还原bx
dl = BS_DrvNum[0]; // 获取驱动器号
do {
ah = 2; // ah = 0x02,读盘
al = load(); // 读取先前保存的cl
INT(0x13, ah, al, ch, dh, cl, dl, es:bx);
} while (flags.cf);
}
什么 inc 啦,shr 啦,and 啦,到底什么意思都已经讲明白了。下面那个 jc,我们也把它表示成了 do-while 的形式。
那么现在,需要解释清楚的就是几点:1、开头结尾的 push bp、mov bp, sp 和结尾的 pop bp 是在干什么;2、这个 cl 到底存哪去了;3、这个 .GoOnReading 带 . 是在干什么 (虽然我觉得有这个问题的不会多)。
我们从易到难吧。先说最后一点,这实际上是 nasm 的私货,这种东西不能单独存在,必须长成类似这样:
xxx:
.xxx:
aaa:
才行。只要现在的代码还在最上面那个 xxx: 之下,访问下面那个 .xxx 就可以直接用 .xxx 的形式,比如 mov、jmp、call 都行;但一旦到了下面那个 aaa: 的下面,就不能再这么做了,如果还想访问上面那个 .xxx,必须通过 xxx.xxx 的方式。或许有人会有疑问:
如果我在
aaa下面再定义一个.xxx呢?
那自然是毫无问题,aaa 下面的代码访问 .xxx,访问的就是 aaa 下面定义的那个,而非 xxx 下面定义的那个。这个东西就类似在别的什么高级编程语言里的私有属性,因此有个名字叫本地标签。不过目前知道就行了,具体用处没有体现。
接下来来解决 1 和 2,这俩其实是同一个问题。push bp 和 mov bp, sp 是 C 语言函数默认带有的两条指令,表示函数开始,所谓的栈帧也就是这个东西。而最后的 pop bp,自然是反过来的操作,表示函数结束,退出栈帧。
接下来的 mov byte [bp - 2], cl,bp - 2 处此时是个什么地方呢?注意在存完栈帧以后,立刻执行了 sub esp, 2(esp -= 2)的操作,而 bp 则相当于还没减时候的 sp,bp - 2 自然就是现在的 sp。
说白了,这一番操作其实就相当于:push cl,而已。只不过为了对称,一般有 push 必有 pop,除非返回,而这个位置后面还要用到多次,不能 pop,因此最开头为了对称起见(笑)也就没有用 push。这样一来,cl 和 bx 其实类似,都是被暂存在栈上了,只是 bx 只被用到一次,很快就 pop 掉了,但 cl 被用到多次,一直到最后的 add esp, 2 才相当于把它 pop 了出去。
好了,ReadSector 就解释完了,不知道大家明白没有(笑),我们继续吧。
下一步,我们定义几个常量,它们的作用是增加可读性,毕竟满篇写死的根目录大小14之类的,很难让人看懂。
代码 3-3 放在开头的常量定义(boot.asm)
BaseOfStack equ 07c00h ; 栈的基址
BaseOfLoader equ 09000h ; Loader的基址
OffsetOfLoader equ 0100h ; Loader的偏移
RootDirSectors equ 14 ; 根目录大小
SectorNoOfRootDirectory equ 19 ; 根目录起始扇区
常量过后还有变量,我们在这个程序中将要用到的变量也不少,它们将被放置在 DispStr 函数的前面。
代码 3-4 放在中间的变量定义(boot.asm)
wRootDirSizeForLoop dw RootDirSectors ; 查找loader的循环中将会用到
wSectorNo dw 0 ; 用于保存当前扇区数
bOdd db 0 ; 这个其实是下一节的东西,不过先放在这也不是不行
LoaderFileName db "LOADER BIN", 0 ; loader的文件名
MessageLength equ 9 ; 下面是三条小消息,此变量用于保存其长度,事实上在内存中它们的排序类似于二维数组
BootMessage: db "Booting " ; 此处定义之后就可以删除原先定义的BootMessage字符串了
Message1 db "Ready. " ; 显示已准备好
Message2 db "No LOADER" ; 显示没有Loader
BootMessage 改过之后,DispStr 也做了微调,现在可以用 dh 传递消息编号来打印了:
代码 3-5 改进后的 DispStr(boot.asm)
DispStr:
mov ax, MessageLength
mul dh ; 将ax乘以dh后,结果仍置入ax(事实上远比此复杂,此处先解释到这里)
add ax, BootMessage ; 找到给定的消息
mov bp, ax ; 先给定偏移
mov ax, ds
mov es, ax ; 以防万一,重新设置es
mov cx, MessageLength ; 字符串长度
mov ax, 01301h ; ah=13h, 显示字符的同时光标移位
mov bx, 0007h ; 黑底灰字
mov dl, 0 ; 第0行,前面指定的dh不变,所以给定第几条消息就打印到第几行
int 10h ; 显示字符
ret
或许有人看不懂这个 DispStr 最开头的三行代码在干什么,把它和那一堆变量转写成 C 会更好理解一点:
代码 3-5 的转写
#define MessageLength 9
char BootMessage[MessageLength][3] = {
"Booting ",
"Ready. ",
"No LOADER"
};
void DispStr()
{
bp = BootMessage[dh];
// ...下略
}
也就是说,上面的三个 Message 在内存中的排布实际上就是一个二维数组,而 mov ax, MessageLength 和 mul dh 的操作相当于在找它的第 dh 行。
为什么用 dh 当参数呢?重新翻阅第一节可以知道,这样还顺便指定了行数,确实是一条妙计。
一切准备工作均已办妥,下面我们开始主循环吧……且慢,我们还有一点点预备知识要补充,下面是 int 13h 的另一种用途。
向下列寄存器中依次存入:
AH=00h:复位磁盘驱动器
DL=驱动器号
然后执行
int 13h。返回值:
FLAGS.CF=0:操作成功
FLAGS.CF=1:操作失败,AH=错误代码
这里我们直接假定 FLAGS.CF 为0,不做任何判断了。下面便是主体代码:
代码 3-6 查找 Loader 的代码主体(boot.asm)
LABEL_START:
mov ax, cs
mov ds, ax
mov es, ax ; 将ds es设置为cs的值(因为此时字符串和变量等存在代码段内)
mov ss, ax ; 将堆栈段也初始化至cs
mov sp, BaseOfStack ; 设置栈顶
xor ah, ah ; 复位
xor dl, dl
int 13h ; 执行软驱复位
mov word [wSectorNo], SectorNoOfRootDirectory ; 开始查找,将当前读到的扇区数记为根目录区的开始扇区(19)
LABEL_SEARCH_IN_ROOT_DIR_BEGIN:
cmp word [wRootDirSizeForLoop], 0 ; 将剩余的根目录区扇区数与0比较
jz LABEL_NO_LOADERBIN ; 相等,不存在Loader,进行善后
dec word [wRootDirSizeForLoop] ; 减去一个扇区
mov ax, BaseOfLoader
mov es, ax
mov bx, OffsetOfLoader ; 将es:bx设置为BaseOfLoader:OffsetOfLoader,暂且使用Loader所占的内存空间存放根目录区
mov ax, [wSectorNo] ; 起始扇区:当前读到的扇区数(废话)
mov cl, 1 ; 读取一个扇区
call ReadSector ; 读入
mov si, LoaderFileName ; 为比对做准备,此处是将ds:si设为Loader文件名
mov di, OffsetOfLoader ; 为比对做准备,此处是将es:di设为Loader偏移量(即根目录区中的首个文件块)
cld ; FLAGS.DF=0,即执行lodsb/lodsw/lodsd后,si自动增加
mov dx, 10h ; 共16个文件块(代表一个扇区,因为一个文件块32字节,16个文件块正好一个扇区)
LABEL_SEARCH_FOR_LOADERBIN:
cmp dx, 0 ; 将dx与0比较
jz LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR ; 继续前进一个扇区
dec dx ; 否则将dx减1
mov cx, 11 ; 文件名共11字节
LABEL_CMP_FILENAME: ; 比对文件名
cmp cx, 0 ; 将cx与0比较
jz LABEL_FILENAME_FOUND ; 若相等,说明文件名完全一致,表示找到,进行找到后的处理
dec cx ; cx减1,表示读取1个字符
lodsb ; 将ds:si的内容置入al,si加1
cmp al, byte [es:di] ; 此字符与LOADER BIN中的当前字符相等吗?
jz LABEL_GO_ON ; 下一个文件名字符
jmp LABEL_DIFFERENT ; 下一个文件块
LABEL_GO_ON:
inc di ; di加1,即下一个字符
jmp LABEL_CMP_FILENAME ; 继续比较
LABEL_DIFFERENT:
and di, 0FFE0h ; 指向该文件块开头
add di, 20h ; 跳过32字节,即指向下一个文件块开头
mov si, LoaderFileName ; 重置ds:si
jmp LABEL_SEARCH_FOR_LOADERBIN ; 由于要重新设置一些东西,所以回到查找Loader循环的开头
LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR:
add word [wSectorNo], 1 ; 下一个扇区
jmp LABEL_SEARCH_IN_ROOT_DIR_BEGIN ; 重新执行主循环
LABEL_NO_LOADERBIN: ; 若找不到loader.bin则到这里
mov dh, 2
call DispStr; 显示No LOADER
jmp $
LABEL_FILENAME_FOUND: ; 找到了则到这里
jmp $ ; 什么都不做,直接死循环
这一段代码实在是太长了,所以在注释里做了解读。其中还有相当多我们还没有提到的东西,比如 lodsb,比如 dec(这个其实就是 --),以及 jz。鉴于实在太长,也就不提供转写了,感兴趣的读者可以自行当作习题来做(?)
后面的代码讲的就不会再像第一节和这一节这么详细了,大部分的解读都在注释,所以一定要善用哦。
如果直接按照上文的方法,先 nasm 后 dd,一顿操作猛如虎的话,那么运行结果应该是这样的:
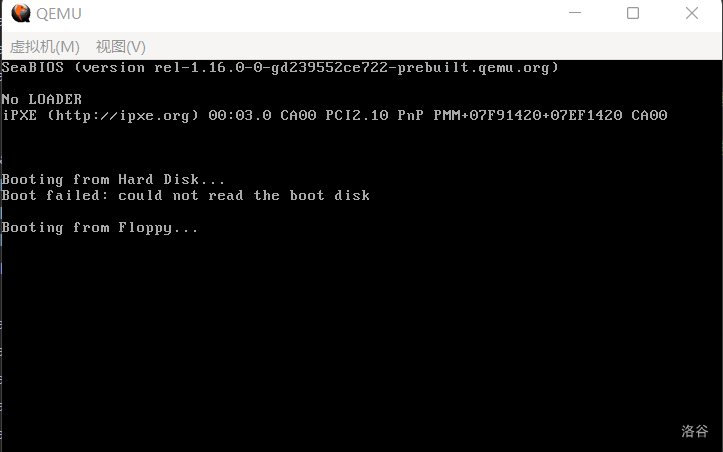
(图 3-1 直接运行的效果)
第三行将会出现一个 No LOADER 的标识,虽然不符合预期(应该没有任何输出才对),但这也正好说明了我们的主循环在工作。
那么下面我们的工作就是把 Loader 写入磁盘了,不过您可能会发现,我们甚至都没有编译 Loader,没事,马上编译一下:
nasm loader.asm -o loader.bin
虽然得到了 loader.bin,但我们的写入工作在此处就有两个分支了。如果您使用的是 Linux 或 macOS,请使用下列命令将 loader.bin 写入磁盘:
mkdir floppy
sudo mount -o loop a.img ./floppy/
cp loader.bin ./floppy/ -v
sudo umount ./floppy/
rmdir floppy
在 Windows 下我们则需要这样:
edimg imgin:a.img copy from:loader.bin to:@: imgout:a.img
无论用什么方式,只要您成功把 Loader 写入了磁盘,便无大碍。总之,写入之后的运行结果是这样的:
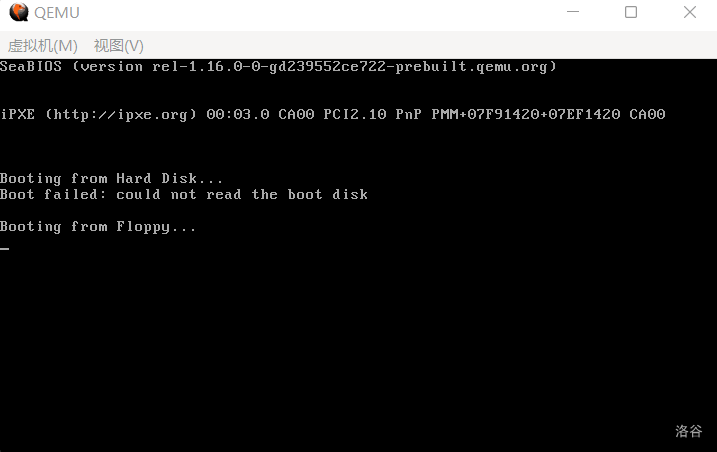
(图 3-2 写入后再运行,第 3 行已经没有了 No LOADER)
如果您的运行结果与之相符,那么您就可以进入下一节的学习,我们将要加载我们的 Loader,并跳入其中,这样,我们的可支配空间就从 0.5KB 扩张到了 63KB,足有 126 倍的提升。64KB 是一个段的大小,我们的 Loader 就活在一个段里;至于还有 1KB 则是被 org 0100h 给吃了。
4.加载并跳入 Loader
在执行流到达 LABEL_FILENAME_FOUND 时,此时的 di 应当正好位于 Loader 所在的文件块中。因此,我们可以通过这个方法获得 Loader 的起始扇区。
至于怎么获得,这就与那个 32 字节文件块的结构有关。
typedef struct FILEINFO {
uint8_t name[8], ext[3];
uint8_t type, reserved[10];
uint16_t time, date, clustno;
uint32_t size;
} __attribute__((packed)) fileinfo_t;
这个结构体就是对文件块的描述,后面我们还会见到它的。其中的 clustno 是它起始的簇,一个簇对应一个扇区。
从簇号转化到扇区号要怎么办呢?这就不得不提到 FAT12 文件系统的结构了。以下叙述默认下标从 0 开始。
FAT12 文件系统在磁盘中是这样的:第 0 个扇区,是引导扇区,接下来是两块大小为 9 扇区的 FAT 表,再往下是 14 个扇区的根目录区,剩下的部分都是数据区。
数据区的每一个扇区,都叫做一个簇。数据区的第 0 个扇区,是第 2 个簇。这个时候或许有人要问了:
那么第 0 个簇和第 1 个簇去哪里了?
它们被 FAT 表给暴力强占了。
FAT 表和数据区不是彼此独立的吗,怎么会发生这种事情?
是这样的,我来解释一下。FAT 表的每一项,都和数据区的簇息息相关,具体而言,FAT 表每一项的索引,都代表着它的索引对应的簇的下一个簇是第几个;如果这个数字
然而,不知道因为什么,前两个本该对应 0 号簇和 1 号簇的项,分别存储的是坏簇标记 FF0 和结束标记 FFF。因此,可以使用的第一个簇也就变成了第 2 个。这两个簇不能使用,又不能真空出两个扇区来啥也不干,所以干脆把数据区的第 0 个扇区(也就是第 33 扇区)当成第 2 号簇。
既然这堆簇排成了一个链表,自然需要知道第一个簇在什么地方,而这个值就保存在文件信息块 fileinfo_t 的 clustno 成员中,偏移量为
获得第一个簇以后之后我们便可以做几件事:读取第一个扇区,查找 FAT,读入下一个扇区,直至所有扇区都被读完。
不难发现我们需要多次查找 FAT,所以我们干脆把查找 FAT 的过程也包装一下,我们将使用 ax 存储待查询的簇号,查询结果也放入 ax 中。
请把下面的代码放到 ReadSector 之后:
代码 4-1 读取 FAT 项的函数(boot.asm)
GetFATEntry:
push es
push bx
push ax ; 都会用到,push一下
mov ax, BaseOfLoader ; 获取Loader的基址
sub ax, 0100h ; 留出4KB空间
mov es, ax ; 此处就是缓冲区的基址
pop ax ; ax我们就用不到了
mov byte [bOdd], 0 ; 设置bOdd的初值
mov bx, 3
mul bx ; dx:ax=ax * 3(mul的第二重用法:如有进位,高位将放入dx)
mov bx, 2
div bx ; dx:ax / 2 -> dx:余数 ax:商
; 此处* 1.5的原因是,每个FAT项实际占用的是1.5扇区,所以要把表项 * 1.5
cmp dx, 0 ; 没有余数
jz LABEL_EVEN
mov byte [bOdd], 1 ; 那就是奇数了
LABEL_EVEN:
; 此时ax中应当已经存储了待查找FAT相对于FAT表的偏移,下面我们借此来查找它的扇区号
xor dx, dx ; dx置0
mov bx, [BPB_BytsPerSec]
div bx ; dx:ax / 512 -> ax:商(扇区号)dx:余数(扇区内偏移)
push dx ; 暂存dx,后面要用
mov bx, 0 ; es:bx:(BaseOfLoader - 4KB):0
add ax, SectorNoOfFAT1 ; 实际扇区号
mov cl, 2
call ReadSector ; 直接读2个扇区,避免出现跨扇区FAT项出现bug
pop dx ; 由于ReadSector未保存dx的值所以这里保存一下
add bx, dx ; 现在扇区内容在内存中,bx+=dx,即是真正的FAT项
mov ax, [es:bx] ; 读取之
cmp byte [bOdd], 1
jnz LABEL_EVEN_2 ; 是偶数,则进入LABEL_EVEN_2
shr ax, 4 ; 高12位为真正的FAT项
LABEL_EVEN_2:
and ax, 0FFFh ; 只保留低4位
LABEL_GET_FAT_ENRY_OK: ; 胜利执行
pop bx
pop es ; 恢复堆栈
ret
这一段代码恐怕也需要解释一下。FAT12 文件系统的
??于是缺德微软就脑子短路没有选择跳过 FAT12 直接发明 FAT16??
于是微软就搞出了一套“压缩”方法(说是压缩,每一个 FAT 项还是占一个字节半,其实没有任何优化),把两个 FAT 项硬挤在三个字节里,具体而言是长这样的:
| FAT 项 | 磁盘中的表示 |
|---|---|
FF0 FFF |
F0 FF FF |
abc def |
bc fa de |
这样就搞得很恶心,FAT12 要考虑的细节有一半都来自这个破算法。比如,由于每两个 FAT 项占三个字节,所以极端情况下会出现某个 FAT 项的低八位在扇区
不过,上面的代码中,使用了非常巧妙的方法辗转腾挪,最终只用了五行代码就完成了转换,我们到时候再说。
说的有点远,我们从第一行开始看。开局存了三个寄存器 es、bx 和 ax,这是因为读取磁盘要用 es 和 bx,而设置新缓冲区要用 ax,所以都得存一下。
接下来这几行,把 Loader 前面 4KB(0x100 * 16 = 4096 = 4KB)的位置当做缓冲区,然后还原 ax。其实选什么地方当缓冲区并没有什么特别的规定,基本上是想放哪放哪,这里使用 Loader 的开头作为基准只是为了方便。
还原 ax 以后,由于每两个 FAT 项占三个字节,所以先给它乘 3 找到对应的两个 FAT 项。由于 ax 可能过大,再乘一个 bx 有爆掉 16 位的危险(其实算一算就知道根本不可能),因此 CPU 会把乘积的低 16 位放在 ax,高 16 位放在 dx。注释里使用 dx:ax,算是一种惯用法,表示高 16 位和低 16 位是这两个寄存器,与 es:bx 这种寻址意义不同,需要注意一下。
那么问题来了,你现在找到了两个一共占三字节的 FAT 项,它们可是缠在一起的,你怎么知道你要找的那个项被塞在了哪两个字节里呢?
这与 intel 对数据的存储策略密切相关。事实上,那种压缩看似很恶心,也和这种数据存储策略有千丝万缕的联系。这是怎么回事呢?
我们能直接使用的变量,都是以字节(char)为最小单位。想要访问它的第几位,就需要用位运算来处理。同理,内存处理的最小单位也是字节,低于一个字节的都要用位运算来提取。由此就引发了一个问题:高于一个字节的东西怎么在内存里储存呢?比如这有个两字节的东西:0xAA55,它放在内存里长什么样呢?
对此,不同的 CPU 有不同的方法,其中最流行的,是小端(intel 采用这种模式)和大端。还有一些更为复杂的,什么网络序之类的,在此不提。把数按从高字节到低字节的顺序排列,一般的十六进制数都是天然按这种方法排列的,比如:0x12345678,它的高字节就是 0x12,低字节就是 0x78;如果按字节从高到低的顺序顺次写入内存,就叫大端,反之就是小端。
比如我要把 0x12345678 存储到 0x100 开头的四个字节。先把数按照从高到低字节顺序排列:0x12、0x34、0x56、0x78。大端按字节从高到低顺序写入内存,也就是 0x100 处存 0x12,0x101 处存 0x34,0x102 处存 0x56,0x103 处存 0x78。小端则反过来,0x100 处存 0x78,0x101 处存 0x56,以此类推。
这两种排列方式孰优孰劣,我们还真不好判断。不过,用这种视角重新回看上面提到的 FAT 的“压缩”,或许你瞬间就能发现其不对劲之处:按照小端来解释,bc fa de 不仅不抽象,反而刚好是 defabc 的表示!也就是说,微软的这种编码反而很自然,FAT 表变成了一个项正好 1.5 字节的数组。
这样一来,我要找第 cmp dx, 0 的判断(总算说回到代码了)。顺便一提,div 指令如果发现你在试图除以一个 16 位数,将会把 dx:ax 当作被除数,商仍放在 ax,余数放在 dx。
这一下可扯得太太太太太远了,我们说回来。在判断奇偶的时候,使用了一个 bOdd 变量,它是在上一节被定义的。最终,执行流都会进入 LABEL_EVEN。
LABEL_EVEN 一上来把 dx 清零,这是为了避免已经没有用的余数影响接下来的除法。然后,把此时的 ax 再除以 512,和刚才一样,商放在 ax 中表示距离 FAT 开头多少个扇区,余数放在 dx 中表示距离扇区开头的偏移。接下来要读取磁盘,由于 dx 被改变,需要暂存一下。接下来把 ax 加上第一个 FAT 起始位置的扇区号,得到它在磁盘中的真正位置,把 cl 设成 2 表示要读两个扇区。从上面的说明中可以知道这是为什么,如果这么快就忘了罚你从头再看一遍。
读完两个扇区以后把 dx 弹出来,然后加到 bx 上,此时的 bx 和原本一样,应该是 0,所以此时 add bx, dx 就相当于 mov bx, dx。至于为什么要挪到 bx 上,是因为 bx 可以用来访问内存而 dx 不可以。接着,从 es:bx,也就是读到的数据里拿到两个字节的 FAT 项,我们只需要其中的 1.5 字节,所以需要进行一些小小的处理。
接下来的五行,堪称是这一整段程序最巧妙的五行,充分利用了 intel 是小端的特性。
我们来手动模拟一下。我想要取第 abc 放在低位,是第 def 放在高位,是第 abc 变成了 fabc,def 变成了 defc。那么,对于奇数项而言,首先要右移四位;之后是奇偶项统一的操作,取低 12 位,这样就搞到了我们想要的 FAT 项。
代码里的五行,也正是这个逻辑。先判断是不是奇数,是奇数就右移四位,随后统一取低 12 位。
最后返回的时候,按照 C 调用约定默认 ax 是返回值,这里虽然写的是汇编无所谓,但是 ax 是参数,考虑到频繁调用,把 ax 当返回值自有其方便之处在。
这样一来,总算就把上面那个鬼函数讲完了。
从代码中也能看到,我们的常量喜加一,把下面的代码放到 SectorNoOfRootDirectory 后面:
代码 4-2 新常量的定义(boot.asm)
SectorNoOfFAT1 equ 1 ; 第一个FAT表的开始扇区
DeltaSectorNo equ 17 ; 由于前两个簇不用,所以SectorNoOfRootDirectory要-2再加上根目录区大小和簇号才能得到真正的扇区号,故把SectorNoOfRootDirectory-2封装成一个常量(17)
可以看到,除了上文已经出现的常量以外,还定义了一个 DeltaSectorNo,其作用已经在注释中阐明。
现在是时候加载并跳入 Loader 了:
代码 4-3 加载并跳入 Loader(boot.asm)
LABEL_FILENAME_FOUND:
mov ax, RootDirSectors ; 将ax置为根目录首扇区(19)
and di, 0FFE0h ; 将di设置到此文件块开头
add di, 01Ah ; 此时的di指向Loader的FAT号
mov cx, word [es:di] ; 获得该扇区的FAT号
push cx ; 将FAT号暂存
add cx, ax ; +根目录首扇区
add cx, DeltaSectorNo ; 获得真正的地址
mov ax, BaseOfLoader
mov es, ax
mov bx, OffsetOfLoader ; es:bx:读取扇区的缓冲区地址
mov ax, cx ; ax:起始扇区号
LABEL_GOON_LOADING_FILE: ; 加载文件
push ax
push bx
mov ah, 0Eh ; AH=0Eh:显示单个字符
mov al, '.' ; AL:字符内容
mov bl, 0Fh ; BL:显示属性
; 还有BH:页码,此处不管
int 10h ; 显示此字符
pop bx
pop ax ; 上面几行的整体作用:在屏幕上打印一个点
mov cl, 1
call ReadSector ; 读取Loader第一个扇区
pop ax ; 加载FAT号
call GetFATEntry ; 加载FAT项
cmp ax, 0FFFh
jz LABEL_FILE_LOADED ; 若此项=0FFF,代表文件结束,直接跳入Loader
push ax ; 重新存储FAT号,但此时的FAT号已经是下一个FAT了
mov dx, RootDirSectors
add ax, dx ; +根目录首扇区
add ax, DeltaSectorNo ; 获取真实地址
add bx, [BPB_BytsPerSec] ; 将bx指向下一个扇区开头
jmp LABEL_GOON_LOADING_FILE ; 加载下一个扇区
LABEL_FILE_LOADED:
jmp BaseOfLoader:OffsetOfLoader ; 跳入Loader!
这里的逻辑就比较简单了。首先让 di 指向首簇号,然后让 cx 读取之。然后给 cx 加上一个 DeltaSectorNo,再加 SectorNoOfRootDirectory,把簇号转换成扇区号,再然后就是设置 es 和 bx,并按照 ReadSector 的要求,把扇区号倒腾到 ax。每加载一个扇区就输出一个 .,可以看作一种提示和装饰,由于改变了 ax 和 bx 所以用栈暂存。
接下来先读取扇区,然后从栈里弹出之前存的首簇号,用它来查找 FAT 项。如果是 0xfff,则说明文件结束,进入 LABEL_FILE_LOADED 文件加载成功的分支;否则,存储现在的 FAT 项(待会接着查),这个 FAT 项同时也是当前簇,所以把它也转换成扇区号,准备进行下一轮读取;bx 也向后移动一个扇区,然后开始读取下一个扇区的内容。
加载成功以后,自然是直接 jmp 进去。这里用的 jmp xxx:xxx,同时修改代码段和下一条要执行的指令,就相当于进入了 Loader 里去了。前一个 xxx 是代码段的值,后一个 xxx 是下一条要执行的指令,它实际上也是一个寄存器,叫做 EIP,平时只通过 jmp、ret、call 之类的语句修改。
下面就是编译运行了,如果成功的话,就会执行 Loader 的指令,在屏幕第一行正中央显示一个白色的 L。运行结果如下:
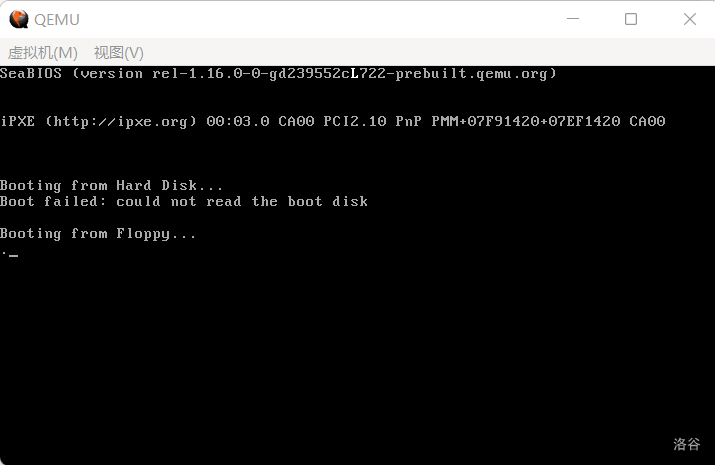
(图 4-1 成功进入 Loader)
屏幕第一行正中间出现了一个白色的 L,我们成功了!这意味着我们摆脱了引导扇区的束缚,进入了 Loader 的广阔天地!
在进入保护模式之前,我们最后休整一下。首先用下列代码清屏,它位于 mov sp, BaseOfStack 和 xor ah, ah 之间:
代码 4-4 清屏(boot.asm)
mov ax, 0600h ; AH=06h:向上滚屏,AL=00h:清空窗口
mov bx, 0700h ; 空白区域缺省属性
mov cx, 0 ; 左上:(0, 0)
mov dx, 0184fh ; 右下:(80, 25)
int 10h ; 执行
mov dh, 0
call DispStr ; Booting
下面的代码用于在加载 Loader 之前打印 Ready.
代码 4-5 打印 Ready.(boot.asm)
LABEL_FILE_LOADED:
mov dh, 1 ; 打印第 1 条消息(Ready.)
call DispStr
jmp BaseOfLoader:OffsetOfLoader ; 跳入Loader!
下图是运行结果:
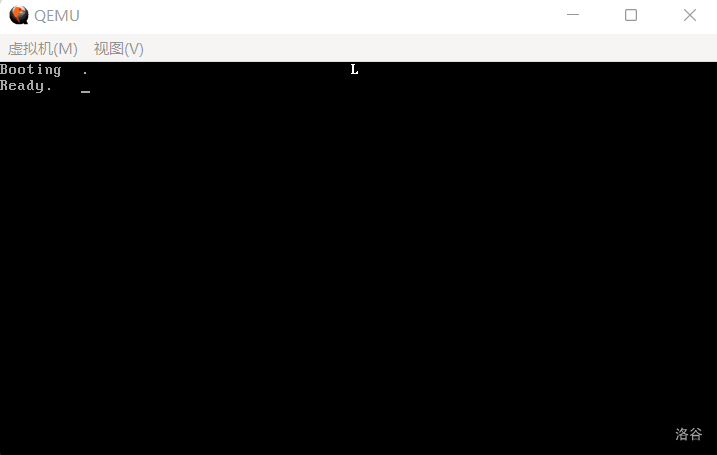
(图 4-2 整理屏幕)
那么最后我们贴一下现在引导扇区的完整代码:
代码 4-6 完整的引导扇区(boot.asm)
org 07c00h ; 告诉编译器程序将装载至0x7c00处
BaseOfStack equ 07c00h ; 栈的基址
BaseOfLoader equ 09000h ; Loader的基址
OffsetOfLoader equ 0100h ; Loader的偏移
RootDirSectors equ 14 ; 根目录大小
SectorNoOfRootDirectory equ 19 ; 根目录起始扇区
SectorNoOfFAT1 equ 1 ; 第一个FAT表的开始扇区
DeltaSectorNo equ 17 ; 由于第一个簇不用,所以RootDirSectors要-2再加上根目录区首扇区和偏移才能得到真正的地址,故把RootDirSectors-2封装成一个常量(17)
jmp short LABEL_START
nop ; BS_JMPBoot 由于要三个字节而jmp到LABEL_START只有两个字节 所以加一个nop
BS_OEMName db 'tutorial' ; 固定的8个字节
BPB_BytsPerSec dw 512 ; 每扇区固定512个字节
BPB_SecPerClus db 1 ; 每簇固定1个扇区
BPB_RsvdSecCnt dw 1 ; MBR固定占用1个扇区
BPB_NumFATs db 2 ; FAT12 文件系统固定2个 FAT 表
BPB_RootEntCnt dw 224 ; FAT12 文件系统中根目录最大224个文件
BPB_TotSec16 dw 2880 ; 1.44MB磁盘固定2880个扇区
BPB_Media db 0xF0 ; 介质描述符,固定为0xF0
BPB_FATSz16 dw 9 ; 一个FAT表所占的扇区数,FAT12 文件系统固定为9个扇区
BPB_SecPerTrk dw 18 ; 每磁道扇区数,固定为18
BPB_NumHeads dw 2 ; 磁头数,bximage 的输出告诉我们是2个
BPB_HiddSec dd 0 ; 隐藏扇区数,没有
BPB_TotSec32 dd 0 ; 若之前的 BPB_TotSec16 处没有记录扇区数,则由此记录,如果记录了,这里直接置0即可
BS_DrvNum db 0 ; int 13h 调用时所读取的驱动器号,由于只挂在一个软盘所以是0
BS_Reserved1 db 0 ; 未使用,预留
BS_BootSig db 29h ; 扩展引导标记
BS_VolID dd 0 ; 卷序列号,由于只挂载一个软盘所以为0
BS_VolLab db 'OS-tutorial' ; 卷标,11个字节
BS_FileSysType db 'FAT12 ' ; 由于是 FAT12 文件系统,所以写入 FAT12 后补齐8个字节
LABEL_START:
mov ax, cs
mov ds, ax
mov es, ax ; 将ds es设置为cs的值(因为此时字符串和变量等存在代码段内)
mov ss, ax ; 将堆栈段也初始化至cs
mov sp, BaseOfStack ; 设置栈顶
mov ax, 0600h ; AH=06h:向上滚屏,AL=00h:清空窗口
mov bx, 0700h ; 空白区域缺省属性
mov cx, 0 ; 左上:(0, 0)
mov dx, 0184fh ; 右下:(80, 25)
int 10h ; 执行
mov dh, 0
call DispStr ; Booting
xor ah, ah ; 复位
xor dl, dl
int 13h ; 执行软驱复位
mov word [wSectorNo], SectorNoOfRootDirectory ; 开始查找,将当前读到的扇区数记为根目录区的开始扇区(19)
LABEL_SEARCH_IN_ROOT_DIR_BEGIN:
cmp word [wRootDirSizeForLoop], 0 ; 将剩余的根目录区扇区数与0比较
jz LABEL_NO_LOADERBIN ; 相等,不存在Loader,进行善后
dec word [wRootDirSizeForLoop] ; 减去一个扇区
mov ax, BaseOfLoader
mov es, ax
mov bx, OffsetOfLoader ; 将es:bx设置为BaseOfLoader:OffsetOfLoader,暂且使用Loader所占的内存空间存放根目录区
mov ax, [wSectorNo] ; 起始扇区:当前读到的扇区数(废话)
mov cl, 1 ; 读取一个扇区
call ReadSector ; 读入
mov si, LoaderFileName ; 为比对做准备,此处是将ds:si设为Loader文件名
mov di, OffsetOfLoader ; 为比对做准备,此处是将es:di设为Loader偏移量(即根目录区中的首个文件块)
cld ; FLAGS.DF=0,即执行lodsb/lodsw/lodsd后,si自动增加
mov dx, 10h ; 共16个文件块(代表一个扇区,因为一个文件块32字节,16个文件块正好一个扇区)
LABEL_SEARCH_FOR_LOADERBIN:
cmp dx, 0 ; 将dx与0比较
jz LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR ; 继续前进一个扇区
dec dx ; 否则将dx减1
mov cx, 11 ; 文件名共11字节
LABEL_CMP_FILENAME: ; 比对文件名
cmp cx, 0 ; 将cx与0比较
jz LABEL_FILENAME_FOUND ; 若相等,说明文件名完全一致,表示找到,进行找到后的处理
dec cx ; cx减1,表示读取1个字符
lodsb ; 将ds:si的内容置入al,si加1
cmp al, byte [es:di] ; 此字符与LOADER BIN中的当前字符相等吗?
jz LABEL_GO_ON ; 下一个文件名字符
jmp LABEL_DIFFERENT ; 下一个文件块
LABEL_GO_ON:
inc di ; di加1,即下一个字符
jmp LABEL_CMP_FILENAME ; 继续比较
LABEL_DIFFERENT:
and di, 0FFE0h ; 指向该文件块开头
add di, 20h ; 跳过32字节,即指向下一个文件块开头
mov si, LoaderFileName ; 重置ds:si
jmp LABEL_SEARCH_FOR_LOADERBIN ; 由于要重新设置一些东西,所以回到查找Loader循环的开头
LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR:
add word [wSectorNo], 1 ; 下一个扇区
jmp LABEL_SEARCH_IN_ROOT_DIR_BEGIN ; 重新执行主循环
LABEL_NO_LOADERBIN: ; 若找不到loader.bin则到这里
mov dh, 2
call DispStr; 显示No LOADER
jmp $
LABEL_FILENAME_FOUND:
mov ax, RootDirSectors ; 将ax置为根目录首扇区(19)
and di, 0FFE0h ; 将di设置到此文件块开头
add di, 01Ah ; 此时的di指向Loader的FAT号
mov cx, word [es:di] ; 获得该扇区的FAT号
push cx ; 将FAT号暂存
add cx, ax ; +根目录首扇区
add cx, DeltaSectorNo ; 获得真正的地址
mov ax, BaseOfLoader
mov es, ax
mov bx, OffsetOfLoader ; es:bx:读取扇区的缓冲区地址
mov ax, cx ; ax:起始扇区号
LABEL_GOON_LOADING_FILE: ; 加载文件
push ax
push bx
mov ah, 0Eh ; AH=0Eh:显示单个字符
mov al, '.' ; AL:字符内容
mov bl, 0Fh ; BL:显示属性
; 还有BH:页码,此处不管
int 10h ; 显示此字符
pop bx
pop ax ; 上面几行的整体作用:在屏幕上打印一个点
mov cl, 1
call ReadSector ; 读取Loader第一个扇区
pop ax ; 加载FAT号
call GetFATEntry ; 加载FAT项
cmp ax, 0FFFh
jz LABEL_FILE_LOADED ; 若此项=0FFF,代表文件结束,直接跳入Loader
push ax ; 重新存储FAT号,但此时的FAT号已经是下一个FAT了
mov dx, RootDirSectors
add ax, dx ; +根目录首扇区
add ax, DeltaSectorNo ; 获取真实地址
add bx, [BPB_BytsPerSec] ; 将bx指向下一个扇区开头
jmp LABEL_GOON_LOADING_FILE ; 加载下一个扇区
LABEL_FILE_LOADED:
mov dh, 1 ; 打印第 1 条消息(Ready.)
call DispStr
jmp BaseOfLoader:OffsetOfLoader ; 跳入Loader!
wRootDirSizeForLoop dw RootDirSectors ; 查找loader的循环中将会用到
wSectorNo dw 0 ; 用于保存当前扇区数
bOdd db 0 ; 这个其实是下一节的东西,不过先放在这也不是不行
LoaderFileName db "LOADER BIN", 0 ; loader的文件名
MessageLength equ 9 ; 下面是三条小消息,此变量用于保存其长度,事实上在内存中它们的排序类似于二维数组
BootMessage: db "Booting " ; 此处定义之后就可以删除原先定义的BootMessage字符串了
Message1 db "Ready. " ; 显示已准备好
Message2 db "No LOADER" ; 显示没有Loader
DispStr:
mov ax, MessageLength
mul dh ; 将ax乘以dh后,结果仍置入ax(事实上远比此复杂,此处先解释到这里)
add ax, BootMessage ; 找到给定的消息
mov bp, ax ; 先给定偏移
mov ax, ds
mov es, ax ; 以防万一,重新设置es
mov cx, MessageLength ; 字符串长度
mov ax, 01301h ; ah=13h, 显示字符的同时光标移位
mov bx, 0007h ; 黑底白字
mov dl, 0 ; 第0行,前面指定的dh不变,所以给定第几条消息就打印到第几行
int 10h ; 显示字符
ret
ReadSector:
push bp
mov bp, sp
sub esp, 2 ; 空出两个字节存放待读扇区数(因为cl在调用BIOS时要用)
mov byte [bp-2], cl
push bx ; 这里临时用一下bx
mov bl, [BPB_SecPerTrk]
div bl ; 执行完后,ax将被除以bl(每磁道扇区数),运算结束后商位于al,余数位于ah,那么al代表的就是总磁道个数(下取整),ah代表的是剩余没除开的扇区数
inc ah ; +1表示起始扇区(这个才和BIOS中的起始扇区一个意思,是读入开始的第一个扇区)
mov cl, ah ; 按照BIOS标准置入cl
mov dh, al ; 用dh暂存位于哪个磁道
shr al, 1 ; 每个磁道两个磁头,除以2可得真正的柱面编号
mov ch, al ; 按照BIOS标准置入ch
and dh, 1 ; 对磁道模2取余,可得位于哪个磁头,结果已经置入dh
pop bx ; 将bx弹出
mov dl, [BS_DrvNum] ; 将驱动器号存入dl
.GoOnReading: ; 万事俱备,只欠读取!
mov ah, 2 ; 读盘
mov al, byte [bp-2] ; 将之前存入的待读扇区数取出来
int 13h ; 执行读盘操作
jc .GoOnReading ; 如发生错误就继续读,否则进入下面的流程
add esp, 2
pop bp ; 恢复堆栈
ret
GetFATEntry:
push es
push bx
push ax ; 都会用到,push一下
mov ax, BaseOfLoader ; 获取Loader的基址
sub ax, 0100h ; 留出4KB空间
mov es, ax ; 此处就是缓冲区的基址
pop ax ; ax我们就用不到了
mov byte [bOdd], 0 ; 设置bOdd的初值
mov bx, 3
mul bx ; dx:ax=ax * 3(mul的第二重用法:如有进位,高位将放入dx)
mov bx, 2
div bx ; dx:ax / 2 -> dx:余数 ax:商
; 此处* 1.5的原因是,每个FAT项实际占用的是1.5扇区,所以要把表项 * 1.5
cmp dx, 0 ; 没有余数
jz LABEL_EVEN
mov byte [bOdd], 1 ; 那就是奇数了
LABEL_EVEN:
; 此时ax中应当已经存储了待查找FAT相对于FAT表的偏移,下面我们借此来查找它的扇区号
xor dx, dx ; dx置0
mov bx, [BPB_BytsPerSec]
div bx ; dx:ax / 512 -> ax:商(扇区号)dx:余数(扇区内偏移)
push dx ; 暂存dx,后面要用
mov bx, 0 ; es:bx:(BaseOfLoader - 4KB):0
add ax, SectorNoOfFAT1 ; 实际扇区号
mov cl, 2
call ReadSector ; 直接读2个扇区,避免出现跨扇区FAT项出现bug
pop dx ; 由于ReadSector未保存dx的值所以这里保存一下
add bx, dx ; 现在扇区内容在内存中,bx+=dx,即是真正的FAT项
mov ax, [es:bx] ; 读取之
cmp byte [bOdd], 1
jnz LABEL_EVEN_2 ; 是偶数,则进入LABEL_EVEN_2
shr ax, 4 ; 高4位为真正的FAT项
LABEL_EVEN_2:
and ax, 0FFFh ; 只保留低4位
LABEL_GET_FAT_ENRY_OK: ; 胜利执行
pop bx
pop es ; 恢复堆栈
ret
times 510 - ($ - $$) db 0
db 0x55, 0xaa ; 确保最后两个字节是0x55AA
5.读入内核并进入保护模式
事实上,读入内核的方法与读入 Loader 完全一致,因此为了可读性着想,我们只需要更改几个变量名,再改几条字符串,便可告成。事实上我们完全可以把这个过程写成函数,但鉴于引导扇区 446 字节的限制过于恶心和做成函数后的堆栈操作占据的空间,我们还是直接复制粘贴吧。
在此之前,我们先把 FAT12 相关的东西放到一起:
代码 5-1 FAT12 文件系统相关(fat12hdr.inc)
BS_OEMName db 'tutorial' ; 固定的8个字节
BPB_BytsPerSec dw 512 ; 每扇区固定512个字节
BPB_SecPerClus db 1 ; 每簇固定1个扇区
BPB_RsvdSecCnt dw 1 ; MBR固定占用1个扇区
BPB_NumFATs db 2 ; FAT12 文件系统固定2个 FAT 表
BPB_RootEntCnt dw 224 ; FAT12 文件系统中根目录最大224个文件
BPB_TotSec16 dw 2880 ; 1.44MB磁盘固定2880个扇区
BPB_Media db 0xF0 ; 介质描述符,固定为0xF0
BPB_FATSz16 dw 9 ; 一个FAT表所占的扇区数,FAT12 文件系统固定为9个扇区
BPB_SecPerTrk dw 18 ; 每磁道扇区数,固定为18
BPB_NumHeads dw 2 ; 磁头数,bximage 的输出告诉我们是2个
BPB_HiddSec dd 0 ; 隐藏扇区数,没有
BPB_TotSec32 dd 0 ; 若之前的 BPB_TotSec16 处没有记录扇区数,则由此记录,如果记录了,这里直接置0即可
BS_DrvNum db 0 ; int 13h 调用时所读取的驱动器号,由于只挂在一个软盘所以是0
BS_Reserved1 db 0 ; 未使用,预留
BS_BootSig db 29h ; 扩展引导标记
BS_VolID dd 0 ; 卷序列号,由于只挂载一个软盘所以为0
BS_VolLab db 'OS-tutorial' ; 卷标,11个字节
BS_FileSysType db 'FAT12 ' ; 由于是 FAT12 文件系统,所以写入 FAT12 后补齐8个字节
FATSz equ 9 ; BPB_FATSz16
RootDirSectors equ 14 ; 根目录大小
SectorNoOfRootDirectory equ 19 ; 根目录起始扇区
SectorNoOfFAT1 equ 1 ; 第一个FAT表的开始扇区
DeltaSectorNo equ 17 ; 由于第一个簇不用,所以RootDirSectors要-2再加上根目录区首扇区和偏移才能得到真正的地址,故把RootDirSectors-2封装成一个常量(17)
下面是我们更改过后的 Loader 代码:
代码 5-2 新版 Loader (loader.asm)
org 0100h ; 告诉编译器程序将装载至0x100处
BaseOfStack equ 0100h ; 栈的基址
BaseOfKernelFile equ 08000h ; Kernel的基址
OffsetOfKernelFile equ 0h ; Kernel的偏移
jmp LABEL_START
%include "fat12hdr.inc"
LABEL_START:
mov ax, cs
mov ds, ax
mov es, ax ; 将ds es设置为cs的值(因为此时字符串和变量等存在代码段内)
mov ss, ax ; 将堆栈段也初始化至cs
mov sp, BaseOfStack ; 设置栈顶
mov dh, 0
call DispStr ; Loading
mov word [wSectorNo], SectorNoOfRootDirectory ; 开始查找,将当前读到的扇区数记为根目录区的开始扇区(19)
xor ah, ah ; 复位
xor dl, dl
int 13h ; 执行软驱复位
LABEL_SEARCH_IN_ROOT_DIR_BEGIN:
cmp word [wRootDirSizeForLoop], 0 ; 将剩余的根目录区扇区数与0比较
jz LABEL_NO_KERNELBIN ; 相等,不存在Kernel,进行善后
dec word [wRootDirSizeForLoop] ; 减去一个扇区
mov ax, BaseOfKernelFile
mov es, ax
mov bx, OffsetOfKernelFile ; 将es:bx设置为BaseOfKernel:OffsetOfKernel,暂且使用Kernel所占的内存空间存放根目录区
mov ax, [wSectorNo] ; 起始扇区:当前读到的扇区数(废话)
mov cl, 1 ; 读取一个扇区
call ReadSector ; 读入
mov si, KernelFileName ; 为比对做准备,此处是将ds:si设为Kernel文件名
mov di, OffsetOfKernelFile ; 为比对做准备,此处是将es:di设为Kernel偏移量(即根目录区中的首个文件块)
cld ; FLAGS.DF=0,即执行lodsb/lodsw/lodsd后,si自动增加
mov dx, 10h ; 共16个文件块(代表一个扇区,因为一个文件块32字节,16个文件块正好一个扇区)
LABEL_SEARCH_FOR_KERNELBIN:
cmp dx, 0 ; 将dx与0比较
jz LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR ; 继续前进一个扇区
dec dx ; 否则将dx减1
mov cx, 11 ; 文件名共11字节
LABEL_CMP_FILENAME: ; 比对文件名
cmp cx, 0 ; 将cx与0比较
jz LABEL_FILENAME_FOUND ; 若相等,说明文件名完全一致,表示找到,进行找到后的处理
dec cx ; cx减1,表示读取1个字符
lodsb ; 将ds:si的内容置入al,si加1
cmp al, byte [es:di] ; 此字符与LOADER BIN中的当前字符相等吗?
jz LABEL_GO_ON ; 下一个文件名字符
jmp LABEL_DIFFERENT ; 下一个文件块
LABEL_GO_ON:
inc di ; di加1,即下一个字符
jmp LABEL_CMP_FILENAME ; 继续比较
LABEL_DIFFERENT:
and di, 0FFE0h ; 指向该文件块开头
add di, 20h ; 跳过32字节,即指向下一个文件块开头
mov si, KernelFileName ; 重置ds:si
jmp LABEL_SEARCH_FOR_KERNELBIN ; 由于要重新设置一些东西,所以回到查找Kernel循环的开头
LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR:
add word [wSectorNo], 1 ; 下一个扇区
jmp LABEL_SEARCH_IN_ROOT_DIR_BEGIN ; 重新执行主循环
LABEL_NO_KERNELBIN: ; 若找不到kernel.bin则到这里
mov dh, 2
call DispStr ; 显示No KERNEL
jmp $
LABEL_FILENAME_FOUND:
mov ax, RootDirSectors ; 将ax置为根目录首扇区(19)
and di, 0FFF0h ; 将di设置到此文件块开头
push eax
mov eax, [es:di + 01Ch]
mov dword [dwKernelSize], eax
pop eax
add di, 01Ah ; 此时的di指向Kernel的FAT号
mov cx, word [es:di] ; 获得该扇区的FAT号
push cx ; 将FAT号暂存
add cx, ax ; +根目录首扇区
add cx, DeltaSectorNo ; 获得真正的地址
mov ax, BaseOfKernelFile
mov es, ax
mov bx, OffsetOfKernelFile ; es:bx:读取扇区的缓冲区地址
mov ax, cx ; ax:起始扇区号
LABEL_GOON_LOADING_FILE: ; 加载文件
push ax
push bx
mov ah, 0Eh ; AH=0Eh:显示单个字符
mov al, '.' ; AL:字符内容
mov bl, 0Fh ; BL:显示属性
; 还有BH:页码,此处不管
int 10h ; 显示此字符
pop bx
pop ax ; 上面几行的整体作用:在屏幕上打印一个点
mov cl, 1
call ReadSector ; 读取Kernel第一个扇区
pop ax ; 加载FAT号
call GetFATEntry ; 加载FAT项
cmp ax, 0FFFh
jz LABEL_FILE_LOADED ; 若此项=0FFF,代表文件结束,直接跳入Kernel
push ax ; 重新存储FAT号,但此时的FAT号已经是下一个FAT了
mov dx, RootDirSectors
add ax, dx ; +根目录首扇区
add ax, DeltaSectorNo ; 获取真实地址
add bx, [BPB_BytsPerSec] ; 将bx指向下一个扇区开头
jmp LABEL_GOON_LOADING_FILE ; 加载下一个扇区
LABEL_FILE_LOADED:
call KillMotor ; 关闭软驱马达
mov dh, 1 ; "Ready."
call DispStr
jmp $ ; 暂时停在此处
dwKernelSize dd 0 ; Kernel大小
wRootDirSizeForLoop dw RootDirSectors ; 查找Kernel的循环中将会用到
wSectorNo dw 0 ; 用于保存当前扇区数
bOdd db 0 ; 这个其实是下一节的东西,不过先放在这也不是不行
KernelFileName db "KERNEL BIN", 0 ; Kernel的文件名
MessageLength equ 9 ; 下面是三条小消息,此变量用于保存其长度,事实上在内存中它们的排序类似于二维数组
BootMessage: db "Loading " ; 此处定义之后就可以删除原先定义的BootMessage字符串了
Message1 db "Ready. " ; 显示已准备好
Message2 db "No KERNEL" ; 显示没有Kernel
DispStr:
mov ax, MessageLength
mul dh ; 将ax乘以dh后,结果仍置入ax(事实上远比此复杂,此处先解释到这里)
add ax, BootMessage ; 找到给定的消息
mov bp, ax ; 先给定偏移
mov ax, ds
mov es, ax ; 以防万一,重新设置es
mov cx, MessageLength ; 字符串长度
mov ax, 01301h ; ah=13h, 显示字符的同时光标移位
mov bx, 0007h ; 黑底白字
mov dl, 0 ; 第0行,前面指定的dh不变,所以给定第几条消息就打印到第几行
add dh, 3
int 10h ; 显示字符
ret
ReadSector:
push bp
mov bp, sp
sub esp, 2 ; 空出两个字节存放待读扇区数(因为cl在调用BIOS时要用)
mov byte [bp-2], cl
push bx ; 这里临时用一下bx
mov bl, [BPB_SecPerTrk]
div bl ; 执行完后,ax将被除以bl(每磁道扇区数),运算结束后商位于al,余数位于ah,那么al代表的就是总磁道个数(下取整),ah代表的是剩余没除开的扇区数
inc ah ; +1表示起始扇区(这个才和BIOS中的起始扇区一个意思,是读入开始的第一个扇区)
mov cl, ah ; 按照BIOS标准置入cl
mov dh, al ; 用dh暂存位于哪个磁道
shr al, 1 ; 每个磁道两个磁头,除以2可得真正的柱面编号
mov ch, al ; 按照BIOS标准置入ch
and dh, 1 ; 对磁道模2取余,可得位于哪个磁头,结果已经置入dh
pop bx ; 将bx弹出
mov dl, [BS_DrvNum] ; 将驱动器号存入dl
.GoOnReading: ; 万事俱备,只欠读取!
mov ah, 2 ; 读盘
mov al, byte [bp-2] ; 将之前存入的待读扇区数取出来
int 13h ; 执行读盘操作
jc .GoOnReading ; 如发生错误就继续读,否则进入下面的流程
add esp, 2
pop bp ; 恢复堆栈
ret
GetFATEntry:
push es
push bx
push ax ; 都会用到,push一下
mov ax, BaseOfKernelFile ; 获取Kernel的基址
sub ax, 0100h ; 留出4KB空间
mov es, ax ; 此处就是缓冲区的基址
pop ax ; ax我们就用不到了
mov byte [bOdd], 0 ; 设置bOdd的初值
mov bx, 3
mul bx ; dx:ax=ax * 3(mul的第二重用法:如有进位,高位将放入dx)
mov bx, 2
div bx ; dx:ax / 2 -> dx:余数 ax:商
; 此处* 1.5的原因是,每个FAT项实际占用的是1.5扇区,所以要把表项 * 1.5
cmp dx, 0 ; 没有余数
jz LABEL_EVEN
mov byte [bOdd], 1 ; 那就是奇数了
LABEL_EVEN:
; 此时ax中应当已经存储了待查找FAT相对于FAT表的偏移,下面我们借此来查找它的扇区号
xor dx, dx ; dx置0
mov bx, [BPB_BytsPerSec]
div bx ; dx:ax / 512 -> ax:商(扇区号)dx:余数(扇区内偏移)
push dx ; 暂存dx,后面要用
mov bx, 0 ; es:bx:(BaseOfKernelFile - 4KB):0
add ax, SectorNoOfFAT1 ; 实际扇区号
mov cl, 2
call ReadSector ; 直接读2个扇区,避免出现跨扇区FAT项出现bug
pop dx ; 由于ReadSector未保存dx的值所以这里保存一下
add bx, dx ; 现在扇区内容在内存中,bx+=dx,即是真正的FAT项
mov ax, [es:bx] ; 读取之
cmp byte [bOdd], 1
jnz LABEL_EVEN_2 ; 是偶数,则进入LABEL_EVEN_2
shr ax, 4 ; 高4位为真正的FAT项
LABEL_EVEN_2:
and ax, 0FFFh ; 只保留低4位
LABEL_GET_FAT_ENRY_OK: ; 胜利执行
pop bx
pop es ; 恢复堆栈
ret
KillMotor: ; 关闭软驱马达
push dx
mov dx, 03F2h ; 软驱端口
mov al, 0 ; 软盘驱动器:0,复位软盘驱动器,禁止DMA中断,关闭软驱马达
out dx, al ; 执行
pop dx
ret
之所以在此处关闭软驱马达是因为后面我们用不到软盘了。
引导扇区开头的部分也做了一点修改,因为 FAT12 的部分已经抽离出来了:
代码 5-3 引导扇区开头部分(boot.asm)
jmp short LABEL_START
nop ; BS_JMPBoot 由于要三个字节而jmp到LABEL_START只有两个字节 所以加一个nop
%include "fat12hdr.inc"
LABEL_START:
运行结果如下:

(图 5-1 不存在Kernel时的运行情况)
屏幕中出现了一行 No KERNEL,这是理所应当的,因为我们甚至连一个最简单的内核都没有写,马上来写一个:
代码 5-4 极简内核程序(kernel.asm)
[section .text]
global _start
_start: ; 此处假设gs仍指向显存
mov ah, 0Fh
mov al, 'K'
mov [gs:((80 * 1 + 39) * 2)], ax ; 第1行正中央,白色K
jmp $ ; 死循环
这里好像出现了很多我们之前的极简 Loader 没有的东西,这个 global 是什么,section .text 又是什么东西,为什么一上来还要定义一个 _start?
说实话,其实这些都和现在无关,完全是为了以后的考虑。前四节(包括这一节)我们一直在使用汇编,但更多的时候,我们为了方便理解甚至会使用 C 语言转写。如果未来能使用 C 语言,会不会方便得多?只是可惜,如果为了方便,继续使用纯二进制的话,写 C 恐怕会十分复杂,而且不一定能够成功(说多了都是泪.jpg)。
因此,我们为内核引入了一种可执行文件格式(当然不是我自己写的,我还没那个本事),叫做 ELF,全称不想写,目前广泛应用于 Linux 以及自制操作系统中(题外话:现在的自制操作系统可执行文件基本都是 ELF,少数使用 PE,也就是微软家 exe 文件的格式,自创格式的几乎没有)。
既然有 Linux 撑腰,想要用它自然十分容易,在一开头就下载了 i686-elf-tools-windows.zip(或者 i386-elf-gcc for mac,Linux 自己的 gcc 编译出来就是 ELF),用它包办编译和链接即可。使用下面的命令,即可轻松编译出一个 ELF 来(mac 用户把 i686 改成 i386,linux 用户去掉 i686-elf,链接选项加上 -m elf_i386)。
nasm -f elf -o kernel.o kernel.asm
i686-elf-ld -s -o kernel.bin kernel.o
写入的命令也要改一下:
edimg imgin:a.img copy from:loader.bin to:@: copy from:kernel.bin to:@: imgout:a.img
这样就把 kernel.bin 也给写入到磁盘里来了。
唉唉唉,别想避重就轻,你还没解释那堆东西到底是什么玩意呢。
uhh,好吧。global _start 和 _start: 是给链接器看的,以这种方式告诉链接器,ELF 程序从这里开始执行(ELF 程序的默认入口点都是 _start,这是一个约定。或许有人会问:“那 main 是什么?难道不重要吗?”其实还真的不重要,看看第 23 节没准就能获得解答)。section .text 是给 ld 看的,这样 ld 就会知道“哦,下面的部分都是代码而不是数据”,从而正确设置 ELF。至于为什么能把 section 放进中括号这种取址用的东西里,据说是一部分伪指令的特性,带与不带中括号有一些奇妙的不同;不过在这篇教程的语境下,可以认为它们是一样的。
再次运行,结果应如下图所示:

(图 5-2 写入内核之后)
屏幕第四行出现了 Ready.,意味着我们的内核已经被成功读入了,下面我们进入保护模式吧。在保护模式中我们只做两件事:重新放置内核并进入内核,也就是下一节的内容。
首先来说一下,什么是保护模式?一般而言,我们认为只要有 GDT、 cs 是 GDT 选择子、cr0 寄存器的 PE 位是 1 的时候,当前 CPU 就处于保护模式。至于 GDT 和 cr0 是什么,将在接下来阐明。保护模式分为 16 位和 32 位两种,不过 16 位保护模式非常少见(也不是不可以,只要设置 16 位代码段和数据段就可以了,一个 flag 的事),后文除非特别指明,默认保护模式是 32 位的。
进入保护模式总共分为 6 步:
1.准备
GDT
2.加载
GDT(lgdt)
3.关中断
4.打开
A20地址线
5.将
cr0的第0位置1(PE位)
6.通过一个
jmp指令进入32位代码段
这其中又出现了很多生词, A20 是啥,中断又是什么?再加上上面挖的坑,接下来我们一块填了。
首先是 A20,它是一个什么东西呢?在曾经的 CPU 里,一共有 20 条地址线,编号为 A0~A19,这样就可以访问到共计 2^20=1MB 的内存。但是,后来内存大了,20 根地址线不够用了,到了 80286 时期,又涨到 24 根,这就衍生出了兼容性的问题(你看,又是兼容):早期的 CPU 对于超过 1MB 的内存会重新指回 0x00,比如访问 FFFF:FFFF 并不会访问到预想中的 0x10FFEF,而是会指回 0xFFEF 去。这又来了五根地址线,不就麻烦了么?
intel 遂采取一种笨办法,既然多出来这一点会带来问题,那我找个地方,把新来的 A20 一关,不就行了么?你设置的地址是 0x100000,但 A20 一关,实际上相当于不管你第 20 位是多少,通通把它当成 0,于是 1MB 又变回了 0x000000,这就暴力地兼容了以往把内存指回去的方案。80286 还是 16 位,最大还是 0x10FFEF 的内存,所以关一个 A20 就够了;但 80386 以后加了 32 位,从而可以访问 4GB 内存,A21~A31 根本没人管,但 A20 却还是默认关着,只有第 20 位受伤的世界打成了。如果直接进入 32 位模式而不去打开 A20,那就相当于 12MB、34MB、5~6MB 等内存空间完全无法访问,因为这一位 CPU 不管,所以为了访问到全部内存,必须把 A20 打开。
唯一的问题就是把 A20 放在哪呢?请欣赏:兼容性问题的终极解决方案,键盘控制器——这里可谓人杰地灵,既要管理键盘,又要管理鼠标,甚至可以用键盘重启电脑,总之不差你一个 A20。于是,intel 就随便扒了一个键盘的空余引脚,用来控制 A20。这么搞唯一的问题就是它实在太慢了,于是又衍生出更多打开 A20 的方案,包括但不限于使用 int 15h 的扩展,以及访问其他端口等。我们使用的是 0x92 端口法,这个端口内的数值,第二位是 1,则表示开启 A20。
然后是 GDT(全局描述符表),它与 32 位保护模式下的内存寻址密切相关。32 位保护模式最大有 32 位的变量,因此可以指向 4GB 的内存空间,相比原先的 1MB 已有了很大提升。而原先段:偏移的寻址方案仍然适用,但此时的段寄存器值已经不再是地址的一部分,而是一种名叫选择子的鬼东西,后面再谈。
GDT 的表项就没有这么简单了,它被称为描述符。下图是一个描述符结构的简图(节选自《Orange'S:一个操作系统的实现》):

(图 5-3 GDT 描述符结构)
粗看一眼就知道,第 5、6 字节的这些属性也好,段基址和段界限的存放位置也罢,都是需要单独存放的。下面是它们的声明:
代码 5-5 保护模式下段属性之类的声明(pm.inc)
DA_32 EQU 4000h
DA_LIMIT_4K EQU 8000h
DA_DPL0 EQU 00h
DA_DPL1 EQU 20h
DA_DPL2 EQU 40h
DA_DPL3 EQU 60h
DA_DR EQU 90h
DA_DRW EQU 92h
DA_DRWA EQU 93h
DA_C EQU 98h
DA_CR EQU 9Ah
DA_CCO EQU 9Ch
DA_CCOR EQU 9Eh
DA_LDT EQU 82h
DA_TaskGate EQU 85h
DA_386TSS EQU 89h
DA_386CGate EQU 8Ch
DA_386IGate EQU 8Eh
DA_386TGate EQU 8Fh
SA_RPL0 EQU 0
SA_RPL1 EQU 1
SA_RPL2 EQU 2
SA_RPL3 EQU 3
SA_TIG EQU 0
SA_TIL EQU 4
PG_P EQU 1
PG_RWR EQU 0
PG_RWW EQU 2
PG_USS EQU 0
PG_USU EQU 4
%macro Descriptor 3
dw %2 & 0FFFFh
dw %1 & 0FFFFh
db (%1 >> 16) & 0FFh
dw ((%2 >> 8) & 0F00h) | (%3 & 0F0FFh)
db (%1 >> 24) & 0FFh
%endmacro
%macro Gate 4
dw (%2 & 0FFFFh)
dw %1
dw (%3 & 1Fh) | ((%4 << 8) & 0FF00h)
dw ((%2 >> 16) & 0FFFFh)
%endmacro
上面用了一堆 equ 的语法的部分都是硬件规程。equ 本质上相当于 C++ 里的 #define,即:#define DA_32 0x4000 之类的。(nasm 里也有 %define,但是用得好像很少,都被 equ 和 %macro 给包了)除此之外,唯一需要解释的可能就是 Descriptor 这一块了(Gate 宏根本没有用到,所以也就不管它)。
从下面的代码可知,Descriptor 的用法是:Descriptor xxx, xxx, xxx。再由前文可以知道,文本模式显存基址是 0xb8000,与显存段一对比,显然第一个参数是段基址。第三个参数全是各种 DA_ 混合在一块,显然是段属性,也就是 GDT 描述符结构那个图里,BYTE6 和 BYTE5 去掉段界限的那一部分。而剩下的第二个参数,也就只能是段界限了。用这个宏最大的好处,无疑是简化了描述符的定义,看看其他的教程和书里是怎么定义描述符的就知道了,他们还在硬凹数位的时候,我们已经用上如此方便的宏了……(笑)不过这个宏也不是笔者的劳动成果,如此自夸怕是不太好。 (前六节内容均基于《Orange'S:一个操作系统的实现》,有能力支持原作喵。至少就前六节而言,相当于这本书的二创了。)
这个宏怎么就能定义出一个描述符呢?先得解释这个奇怪的语法。这个东西是汇编里的宏,和 C 语言中的 #define 非常相似。第一行的 %macro 表示宏开始,Descriptor 为宏名,4 为接收参数数量,接收的参数从 %1 开始逐渐递增表示。
接下来这一部分,一直到 %endmacro 为止,就是宏的本体了,里面是纯粹的位运算。最后是一个 %endmacro,表示宏结束。这里的宏就是纯粹的文本替换,也就是说,Descriptor 0, 0, 0 会被替换为:
dw 0 & 0FFFFh
dw 0 & 0FFFFh
db (0 >> 16) & 0FFh
dw ((0 >> 8) & 0F00h) | (0 & 0F0FFh)
db (0 >> 24) & 0FFh
什么,汇编居然有这么方便的位运算?那第四节
shr、and半天在干什么呢?
事实上,只有在编译期间可以被计算的量,才能够用上这么方便的东西,具体而言,有且只有常数和标签对应的地址是可以在编译期立即知道的。你要是想对一个寄存器做这些,没门,用 x86 指令去;对内存,更没门,这块地方都不知道是不是归内存管(有的外设会在内存里开辟一段空间来,驱动程序通过读写这段内存与外设交互),哪能随便让你算了。
好了,话说回来,我们来看看这五行都在干什么。
首先写入两个字节的段界限低 16 位(%2 是第二个参数表段界限),然后是两个字节的段基址低 16 位(%1 是第一个参数表段基址),再往下是一个字节的段基址第 16-23 位。与上面的图对照,正好是 BYTE0~BYTE4 的内容。
接下来的 BYTE5 到 BYTE6,用了一个 dw 来写入。首先把段界限右移 8 位,把原来第 16~19 位的位置变成第 8~11 位,也就是在 BYTE5~BYTE6 中它实际在的位置,然后用与运算把除了这四位以外的部分都设置成 0。后面则是把第三个参数里,把段界限占领的部分变成 0,最后把两个部分或在一起,拼成一个完整的 BYTE5~BYTE6。最后是段基址的高 8 位,写在 BYTE7。于是,这些位运算就这样把原来的三个参数拼成了内存里 8 字节的描述符。
下一步就是具体解释一下这个段寄存器里的值与 GDT 描述符之间的关系。事实上,这个段值也被称为选择子,下面是选择子的结构简图(同样节选自《Orange'S》):

(图 5-4 选择子结构)
当 TI 和 RPL 均为0时,不难发现,此时的整个选择子就是它对应的描述符的偏移(一个 GDT 占 8 字节。事实上也正是因为一个 GDT 占 8 字节,intel 才敢在低三位塞点私货)。这两个小部分的作用后面还会提及,到第 22 节我们再揭晓。
那么下一个部分自然就是 lgdt 了,我们需要把下面的结构写入 gdtr 寄存器:

(图 5-5 gdtr 结构)
这个也不难理解,我们只需要按照上图中的结构写入就可以了。唯一需要注意的是这一段内存会在保护模式下被访问,所以写汇编时有 16 位意义下段的相对地址,要被转化为原来的段基址乘以 16 再加上相对地址的绝对地址。
下一步就是关中断了。中断的具体内容我们放到后面第 9、10 节解释,此处我们只需要知道对于这个东西的处理保护模式另有安排,因此为了以后的重新设置,此处暂时关闭。
最后便是 cr0,它属于控制寄存器(Control Register),共有四个(cr0+cr2~4)。下面是 cr0 的结构:

(图 5-6 cr0 结构)
可以看到,cr0 的最低位就是 PE 位,它的含义是:当它为 1 时,进入保护模式,当它为 0 时,为实模式。
最后一步,是一个跳转,跳转完后进入 32 位代码段,真正进入保护模式。这一段听起来很简单,但是实现上它却必须放在 16 位的代码段内,必然需要有一种方法来声明它要跳入 32 位代码段。我们的 nasm 编译器提供了 jmp dword 的方案,其作用正是如此。
那么以上部分我们就阐述清楚了,如果您不明白的话,看下面的代码大致就能明白了,它们在实际开发中位于 LABEL_START 之前:
代码 5-6 GDT 表结构(loader.asm)
LABEL_GDT: Descriptor 0, 0, 0 ; 占位用描述符
LABEL_DESC_FLAT_C: Descriptor 0, 0fffffh, DA_C | DA_32 | DA_LIMIT_4K ; 32位代码段,平坦内存
LABEL_DESC_FLAT_RW: Descriptor 0, 0fffffh, DA_DRW | DA_32 | DA_LIMIT_4K ; 32位数据段,平坦内存
LABEL_DESC_VIDEO: Descriptor 0B8000h, 0ffffh, DA_DRW | DA_DPL3 ; 文本模式显存,后面用不到了
GdtLen equ $ - LABEL_GDT ; GDT的长度
GdtPtr dw GdtLen - 1 ; gdtr寄存器,先放置长度
dd BaseOfLoaderPhyAddr + LABEL_GDT ; 保护模式使用线性地址,因此需要加上程序装载位置的物理地址(BaseOfLoaderPhyAddr)
SelectorFlatC equ LABEL_DESC_FLAT_C - LABEL_GDT ; 代码段选择子
SelectorFlatRW equ LABEL_DESC_FLAT_RW - LABEL_GDT ; 数据段选择子
SelectorVideo equ LABEL_DESC_VIDEO - LABEL_GDT + SA_RPL3 ; 文本模式显存选择子
上述代码定义了 gdt 的同时,也定义了 gdtr 和选择子。不过需要注意的是,这其中我们用到了 BaseOfLoaderPhyAddr,它的定义如下:
代码 5-7 新常量(load.inc)
BaseOfLoader equ 09000h ; Loader的基址
OffsetOfLoader equ 0100h ; Loader的偏移
BaseOfLoaderPhyAddr equ BaseOfLoader * 10h ; Loader被装载到的物理地址
BaseOfKernelFile equ 08000h ; Kernel的基址
OffsetOfKernelFile equ 0h ; Kernel的偏移
由于把 BaseOfLoader 和 OffsetOfLoader 也给搬进来了,boot.asm 中的这一部分就可以删除了。因此,引导扇区和 loader 的前面几行也应当相应做出更改:
代码 5-8 引导扇区头部(boot.asm)
org 07c00h ; 告诉编译器程序将装载至0x7c00处
BaseOfStack equ 07c00h ; 栈的基址
jmp short LABEL_START
nop ; BS_JMPBoot 由于要三个字节而jmp到LABEL_START只有两个字节 所以加一个nop
%include "fat12hdr.inc"
%include "load.inc"
代码 5-9 Loader头部(loader.asm)
org 0100h ; 告诉编译器程序将装载至0x100处
BaseOfStack equ 0100h ; 栈的基址
jmp LABEL_START
%include "fat12hdr.inc"
%include "load.inc"
%include "pm.inc"
经过一番整理,虽然简化了一点代码,但别忘了我们最原始的目标仍没达成。下面我们首先创建 32 位代码段,它位于 KillMotor 之后。
代码 5-10 32 位代码段(loader.asm)
[section .s32]
align 32
[bits 32]
LABEL_PM_START:
mov ax, SelectorVideo ; 按照保护模式的规矩来
mov gs, ax ; 把选择子装入gs
mov ah, 0Fh
mov al, 'P'
mov [gs:((80 * 0 + 39) * 2)], ax ; 这一部分写入显存是通用的
jmp $
开头又是之前没有解释,糊弄过去的 section。除了 .text、.data 这种有特殊意义的名字以外,剩下的名字都只是一种分割的表示,并没有实际的意义。下面的 align 32 和 bits 32,则是先设置内存按 32 位模式对齐,然后告知 nasm “已进入 32 位模式,以下指令请按照 32 位进行解读”。接下来在第 0 行正中央显示一个 P,并没有什么太大的改变,只是 gs 由实模式的 0B800h 变成了保护模式的 SelectorVideo。时刻记住,这样 CPU 会去查找 GDT 的段,并使用 GDT 的段基址来进行相对地址的访问。
下列代码用于进入保护模式。
代码 5-11 进入保护模式(loader.asm)
LABEL_FILE_LOADED:
call KillMotor ; 关闭软驱马达
mov dh, 1 ; "Ready."
call DispStr
lgdt [GdtPtr] ; 下面开始进入保护模式
cli ; 关中断
in al, 92h ; 使用A20快速门开启A20
or al, 00000010b
out 92h, al
mov eax, cr0
or eax, 1 ; 置位PE位
mov cr0, eax
jmp dword SelectorFlatC:(BaseOfLoaderPhyAddr + LABEL_PM_START) ; 真正进入保护模式
无非是按照上文的流程完整地做了一遍。重复一下,若一段内存在保护模式下被访问,则原来 16 位意义下段的相对地址,要被转化为原来的段基址乘以 16 再加上相对地址的绝对地址。 所以,这里要给 LABEL_PM_START 加上 BaseOfLoaderPhyAddr,后者是 BaseOfLoader 乘 16 的封装。
编译运行后,如果一切正常的话,运行结果应如下图:

(图 5-7 运行结果)
我们看到了白色的字母 P,这说明我们已经进入了保护模式。如果您还是不放心,可以把 jmp $ 换成 int 0,如果您的 QEMU 窗口中的文字开始无限变换,那么就说明我们成功进入了保护模式。
6.重新放置内核并进入内核
进入保护模式之后我们的目标只有一个,那就是随之跳入内核。不过,既然我们的内核是有格式的(ELF),我们需要先分析一下 ELF 格式到底长什么样子,如下图所示:

(图 6-1 ELF 文件结构)
与程序执行直接相关的只有 Program Header,利用它们头中给定的地址把分割成几个部分的程序依次排列在内存中,ELF 解析工作就完成了,接下来从 ELF 头给定的入口点开始执行即可。
下面就是对 Program Header 和 ELF 头的描述:
代码 6-1 Program Header
typedef struct {
Elf32_Word p_type; // 当前header描述的段类型
Elf32_Off p_offset; // 段的第一个字节在文件中的偏移
Elf32_Addr p_vaddr; // 段在内存中的虚拟地址
Elf32_Addr p_paddr; // 段在内存中的物理地址,为兼容不进入保护模式的OS
Elf32_Word p_filesz; // 段在文件中的长度
Elf32_Word p_memsz; // 段在内存中的长度
Elf32_Word p_flags; // 与段相关的标志
Elf32_Word p_align; // 确定段在文件和内存中如何对齐
} Elf32_Phdr;
代码 6-2 ELF 头
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT]; // ELF特征标
Elf32_Half e_type; // 文件类型
Elf32_Half e_machine; // 运行至少需要的体系结构
Elf32_Word e_version; // 文件版本
Elf32_Addr e_entry; // 程序的入口点
Elf32_Off e_phoff; // Program Header 表的偏移
Elf32_Off e_shoff; // Section Header 表的偏移
Elf32_Word e_flags; // 对于32位系统为0
Elf32_Half e_ehsize; // ELF Header 的大小,单位字节
Elf32_Half e_phentsize; // Program Header 的大小
Elf32_Half e_phnum; // Program Header 的数量
Elf32_Half e_shentsize; // Section Header 的大小
Elf32_Half e_shnum; // Section Header 的数量
Elf32_Half e_shstrndx; // 包含 Section 名称的字符串表位于哪一项
} Elf32_Ehdr;
其中的所有数据类型(Elf32_Word、Elf32_Off 和 Elf32_Addr) 均为大小为 4、对齐也为 4 的无符号类型,而 Word 为大整数,Off 为偏移,Addr 为地址。至于 Elf32_Half(unsigned char 大家肯定很熟悉就不算了),它代表一个无符号中等大小整数,大小和对齐均为 2 字节。
由上图可知,给 ELF 头的地址加上 e_phoff 的偏移,后面就是 Program Header 的数组,直接分段复制即可。
对于 ELF 的研究就到此为止,后续的细节我们在代码当中说明……但此时还有一个小问题,下图是目前的 kernel.bin 的样子。

(图 6-2 目前的 kernel.bin)
我用蓝色标出来的位置,根据计算不难发现是 e_entry,它已经位于0x8000000(128MB)以外(具体的数值为 0x8048060,读者不妨自行验证),但根据我们的默认设置,我们的内存大小只有128MB。另一方面来讲我们可以通过分页来调低这个位置,但它的具体位置也是不可控的。
那么我们就只剩下一条路了:手动更改 e_entry 的值。事实上,这个过程只需要修改一下编译命令:
nasm -f elf -o kernel.o kernel.asm
i686-elf-ld -s -Ttext 0x100000 -o kernel.bin kernel.o
我们把它的入口点定在了 0x100000,因为这里刚好是1MB,可以避开前面错综复杂的势力。
说了这么半天,我们到底如何重新放置内核?根据前面的分析,我们只需要重复执行与下列 C 语句相同的指令即可:
代码 6-3 我们的目标
memcpy(p_vaddr, BaseOfKernelFilePhyAddr + p_offset, p_filesz);
这时候我们忽然惊奇地发现,我们还没有内存拷贝用的函数,而且连保护模式下的堆栈都没有,甚至对各种段寄存器的处理都欠佳。不要紧,马上修改:
代码 6-4 修整保护模式(loader.asm)
[section .s32]
align 32
[bits 32]
LABEL_PM_START:
mov ax, SelectorVideo ; 按照保护模式的规矩来
mov gs, ax ; 把选择子装入gs
mov ax, SelectorFlatRW ; 数据段
mov ds, ax
mov es, ax
mov fs, ax
mov ss, ax
mov esp, TopOfStack
; cs的设定已在之前的远跳转中完成
jmp $
MemCpy: ; ds:参数2 ==> es:参数1,大小:参数3
push ebp
mov ebp, esp ; 保存ebp和esp的值
push esi
push edi
push ecx ; 暂存这三个,要用
mov edi, [ebp + 8] ; [esp + 4] ==> 第一个参数,目标内存区
mov esi, [ebp + 12] ; [esp + 8] ==> 第二个参数,源内存区
mov ecx, [ebp + 16] ; [esp + 12] ==> 第三个参数,拷贝的字节大小
.1:
cmp ecx, 0 ; if (ecx == 0)
jz .2 ; goto .2;
mov al, [ds:esi] ; 从源内存区中获取一个值
inc esi ; 源内存区地址+1
mov byte [es:edi], al ; 将该值写入目标内存
inc edi ; 目标内存区地址+1
dec ecx ; 拷贝字节数大小-1
jmp .1 ; 重复执行
.2:
mov eax, [ebp + 8] ; 目标内存区作为返回值
pop ecx ; 以下代码恢复堆栈
pop edi
pop esi
mov esp, ebp
pop ebp
ret
[section .data1]
StackSpace: times 1024 db 0 ; 栈暂且先给1KB
TopOfStack equ $ - StackSpace ; 栈顶
下面便是本节最后的工作了。首先我们重新放置内核:
代码 6-5 重新放置内核(loader.asm)
[section .s32]
align 32
[bits 32]
LABEL_PM_START:
mov ax, SelectorVideo ; 按照保护模式的规矩来
mov gs, ax ; 把选择子装入gs
mov ax, SelectorFlatRW ; 数据段
mov ds, ax
mov es, ax
mov fs, ax
mov ss, ax
mov esp, TopOfStack
; cs的设定已在之前的远跳转中完成
call InitKernel ; 重新放置内核
jmp $
...略去MemCpy...
InitKernel:
xor esi, esi ; esi = 0;
mov cx, word [BaseOfKernelFilePhyAddr + 2Ch] ; 这个内存地址存放的是ELF头中的e_phnum,即Program Header的个数
movzx ecx, cx ; ecx高16位置0,低16位置入cx
mov esi, [BaseOfKernelFilePhyAddr + 1Ch] ; 这个内存地址中存放的是ELF头中的e_phoff,即Program Header表的偏移
add esi, BaseOfKernelFilePhyAddr ; Program Header表的具体位置
.Begin:
mov eax, [esi] ; 首先看一下段类型
cmp eax, 0 ; 段类型:PT_NULL或此处不存在Program Header
jz .NoAction ; 本轮循环不执行任何操作
; 否则的话:
push dword [esi + 010h] ; p_filesz
mov eax, [esi + 04h] ; p_offset
add eax, BaseOfKernelFilePhyAddr ; BaseOfKernelFilePhyAddr + p_offset
push eax
push dword [esi + 08h] ; p_vaddr
call MemCpy ; 执行一次拷贝
add esp, 12 ; 清理堆栈
.NoAction: ; 本轮循环的清理工作
add esi, 020h ; 下一个Program Header
dec ecx
jnz .Begin ; jz过来的话就直接ret了
ret
基本上就是一个复制 Program Header 的过程,具体的细节注释里都写了。一些比较迷惑的指令(比如 movzx)的含义也已经写在注释里了。
其中又有很多新的常量:
代码 6-6 新常量(load.inc)
BaseOfLoader equ 09000h ; Loader的基址
OffsetOfLoader equ 0100h ; Loader的偏移
BaseOfLoaderPhyAddr equ BaseOfLoader * 10h ; Loader被装载到的物理地址
BaseOfKernelFile equ 08000h ; Kernel的基址
OffsetOfKernelFile equ 0h ; Kernel的偏移
BaseOfKernelFilePhyAddr equ BaseOfKernelFile * 10h ; Kernel被装载到的物理地址
KernelEntryPointPhyAddr equ 0x100000 ; Kernel入口点,一定要与编译命令一致!!!
可能有聪明的读者就要问了:
所以为啥不Init完直接进呢???
有点仪式感(bushi),你看之前进 Loader,一点仪式感没有,平平淡淡地就进了(
好那么我们最后重视一下这仪式感吧,下面是进入内核的远跳转,请用它代替 jmp $:
代码 6-7 跳入内核(loader.asm)
jmp SelectorFlatC:KernelEntryPointPhyAddr
运行结果如图:

(图 6-3 运行结果)
运行地非常成功,这不仅代表着我们可以让汇编仅起辅助作用,更是我们的操作系统的一个重要成果。
但是我既没有说后面不用汇编,也没有说 Loader 的工作到此结束,事实上后面我们可能还要再对 Loader 进行一次大改。
那么我们就暂时维持着 Kernel 现在的样子,进入下一节的内容。
7.实现我们自己的打印函数
经过了六节不长不短的征程,我们总算是来到了内核之中。
首先,我们要让 kernel 获取很多东西的控制权,比如 gdt,比如 esp。这一部分肯定是要用到汇编的,但主体已经是 C。
因此,我们要把 kernel 更改一下:
代码 7-1 内核改版(kernel.asm)
[section .bss]
; 这里,为栈准备空间
StackSpace resb 2 * 1024 ; 2KB的栈,大概够用?
StackTop: ; 栈顶位置
[section .text]
extern kernel_main ; kernel_main是C部分的主函数
global _start ; 真正的入口点
_start:
mov esp, StackTop ; 先把栈移动过来
cli ; 以防万一,再关闭一次中断(前面进保护模式已经关闭过一次)
call kernel_main ; 进入kernel_main
jmp $ ; 从kernel_main回来了(一般不会发生),悬停
然后呢?然后告诉大家一个好消息,我们可以开始用C啦!(鼓掌)但是坏消息是,这里的C不能用标准库(因为某些原因),所以我们只能自力更生了。
所以,我们应当先把基础设施搭建起来,在这里我指的是基本的整数类型。虽然整数类型可以直接用,但 unsigned int 之流毕竟还是太长了。
所以,新建 common.h,我们要开始定义了。
代码 7-2 基础设施(common.h)
#ifndef COMMON_H
#define COMMON_H
typedef unsigned int uint32_t;
typedef int int32_t;
typedef unsigned short uint16_t;
typedef short int16_t;
typedef unsigned char uint8_t;
typedef char int8_t;
typedef int8_t bool;
#define true 1
#define false 0
void outb(uint16_t port, uint8_t value);
void outw(uint16_t port, uint16_t value);
uint8_t inb(uint16_t port);
uint16_t inw(uint16_t port);
#define NULL ((void *) 0)
#endif
这里除了定义了整数类型、布尔类型和 NULL 外,还有四个 I/O 端口操作函数。正如我们在平常写app时一样,新建 common.c,我们来添加实现:
代码 7-3 端口操作(common.c)
#include "common.h"
void outb(uint16_t port, uint8_t value)
{
asm volatile("outb %1, %0" : : "dN"(port), "a"(value)); // 相当于 out value, port
}
void outw(uint16_t port, uint16_t value)
{
asm volatile("outw %1, %0" : : "dN"(port), "a"(value)); // 相当于 out value, port
}
uint8_t inb(uint16_t port)
{
uint8_t ret;
asm volatile("inb %1, %0" : "=a"(ret) : "dN"(port)); // 相当于 in val, port; return val;
return ret;
}
uint16_t inw(uint16_t port)
{
uint16_t ret;
asm volatile("inw %1, %0" : "=a"(ret) : "dN"(port)); // 相当于 in val, port; return val;
return ret;
}
怎么样,看上去很不好懂是不是?这玩意叫做内联汇编,这么复杂的用法只此一次,后面哪怕用也不会这么复杂了。至于它具体的用法,可自行百度,在此略过不提。
(说白了其实就是我也看不懂这坨史,只好把它们抄下来)
虽然它们定义起来很麻烦,但用还是很好用的,我们很快就会看到。
接下来,看看本节的标题,我们继续向着实现打印函数的目标前进。
代码 7-4 打印函数头文件(monitor.h)
#ifndef _MONITOR_H_
#define _MONITOR_H_
#include "common.h"
void monitor_put(char c); // 打印字符
void monitor_clear(); // 清屏
void monitor_write(char *s); // 打印字符串
void monitor_write_hex(uint32_t hex); // 打印十六进制数
void monitor_write_dec(uint32_t dec); // 打印十进制数
#endif
从名字和注释上看,应该还是挺好懂的吧。这里同时提供十六进制打印和十进制打印,十六进制对于地址等情况十分便利,而对于我们这些用惯了十进制的人而言,打印十进制会更有亲和力。
接下来,我们将实施“四步走”战略,逐步完成打印函数的实现。
第一步:移动光标
我们之前操作光标,用的都是 int 10h。现在进入了保护模式,int 10h 不能用了,怎么办?
换一个角度来想,光标是在显示器上跳动的,所以显示器必然有调整光标的方法。猜对啦,我们正是要操纵显卡来移动光标。
新建 monitor.c,加入如下定义:
代码 7-5 基本定义与光标移动(monitor.c)
#include "monitor.h"
static uint16_t cursor_x = 0, cursor_y = 0; // 光标位置
static uint16_t *video_memory = (uint16_t *) 0xB8000; // 一个字符占两个字节(字符本体+字符属性,即颜色等),因此用uint16_t
static void move_cursor() // 根据当前光标位置(cursor_x,cursor_y)移动光标
{
uint16_t cursorLocation = cursor_y * 80 + cursor_x; // 当前光标位置
outb(0x3D4, 14); // 光标高8位
outb(0x3D5, cursorLocation >> 8); // 写入
outb(0x3D4, 15); // 光标低8位
outb(0x3D5, cursorLocation); // 写入,由于value声明的是uint8_t,因此会自动截断
}
这样,只要调用 move_cursor,显示器就会自动把光标移到 (cursor_x, cursor_y) 处。
第二步:滚屏操作
在平常用shell的时候,当光标到了最后一行,我们还要按enter,那么shell内部的文字将自动滚动。这个过程我们称为滚屏。
显然,如果我们自己的OS在打印时也能自动滚屏就好了。其实,实现滚屏并不太难:
代码 7-6 滚屏(monitor.c)
// 文本控制台共80列,25行(纵列竖行),因此当y坐标不低于25时就要滚屏了
static void scroll() // 滚屏
{
uint8_t attributeByte = (0 << 4) | (15 & 0x0F); // 黑底白字
uint16_t blank = 0x20 | (attributeByte << 8); // 0x20 -> 空格这个字,attributeByte << 8 -> 属性位
if (cursor_y >= 25) // 控制台共25行,超过即滚屏
{
int i;
for (i = 0 * 80; i < 24 * 80; i++) video_memory[i] = video_memory[i + 80]; // 前24行用下一行覆盖
for (i = 24 * 80; i < 25 * 80; i++) video_memory[i] = blank; // 第25行用空格覆盖
cursor_y = 24; // 光标设置回24行
}
}
这样,只要调用 scroll,显示器就会自动判断是否需要滚屏;如果需要滚屏,则立即执行滚屏,但这一过程并不会重新设置光标位置。
第三步:打印单个字符、打印字符串、清屏
打印字符串无非是不断重复打印单个字符的过程,因此这一步的重点还是在打印字符上。
打印字符本身并不难,难的是随之而来的各种判断,比如对各种转义字符的处理,对不可见字符(也就是在ASCII里,但我们根本看不见的字,比如换行其实是一个单独的字符,但我们看不见,只能看见渲染时候分行了)的处理,等等。
总之,下面就是打印单个字符的函数。
代码 7-7 打印单个字符(monitor.c)
void monitor_put(char c) // 打印字符
{
uint8_t backColor = 0, foreColor = 15; // 背景:黑,前景:白
uint8_t attributeByte = (backColor << 4) | (foreColor & 0x0f); // 黑底白字
uint16_t attribute = attributeByte << 8; // 高8位为字符属性位
uint16_t *location; // 写入位置
// 接下来对字符种类做各种各样的判断
if (c == 0x08 && cursor_x) // 退格,且光标不在某行开始处
{
cursor_x--; // 直接把光标向后移一格
}
else if (c == 0x09) // 制表符
{
cursor_x = (cursor_x + 8) & ~(8 - 1); // 把光标后移至8的倍数为止
// 这一段代码实际上的意思是:先把cursor_x + 8,然后把这一个数值变为小于它的最大的8的倍数(位运算的魅力,具体的可以在纸上推推)
}
else if (c == '\r') // CR
{
cursor_x = 0; // 光标回首
}
else if (c == '\n') // LF
{
cursor_x = 0; // 光标回首
cursor_y++; // 下一行
}
else if (c >= ' ' && c <= '~') // 可打印字符
{
location = video_memory + (cursor_y * 80 + cursor_x); // 当前光标处就是写入字符位置
*location = c | attribute; // 低8位:字符本体,高8位:属性,黑底白字
cursor_x++; // 光标后移
}
if (cursor_x >= 80) // 总共80列,到行尾必须换行
{
cursor_x = 0;
cursor_y++;
}
scroll(); // 滚屏,如果需要的话
move_cursor(); // 移动光标
}
这一段代码中,就是各式各样的判断占了巨大的篇幅。真正负责写入的其实只有这短短的两行:
location = video_memory + (cursor_y * 80 + cursor_x); // 当前光标处就是写入字符位置
*location = c | attribute; // 低8位:字符本体,高8位:属性,黑底白字
接下来便是打印字符串,它不过是对打印字符的简单重复:
代码 7-8 打印字符串(monitor.c)
void monitor_write(char *s)
{
for (; *s; s++) monitor_put(*s); // 遍历字符串直到结尾,输出每一个字符
}
这一步还剩下最后一个任务,实现清屏。说白了,清屏不过就是把全屏都打印上空格,然后把光标放到左上角而已。
代码 7-9 清屏(monitor.c)
void monitor_clear()
{
uint8_t attributeByte = (0 << 4) | (15 & 0x0F); // 黑底白字
uint16_t blank = 0x20 | (attributeByte << 8); // 0x20 -> 空格这个字,attributeByte << 8 -> 属性位
for (int i = 0; i < 80 * 25; i++) video_memory[i] = blank; // 全部打印为空格
cursor_x = 0;
cursor_y = 0;
move_cursor(); // 光标置于左上角
}
至此,最基本的打印函数已经成型。其实这里已经可以测试了,但还有两个函数,我们总不能放着不管。
第四步:输出整数
这一步我们要更进一步,在基础打印函数的基础上实现十六进制和十进制数的输出。我们从易到难,从十进制数开始。
OIer 基本都知道,在OI中,有一套东西,叫做快读快写。而现在,没有 cout,没有 printf,还想输出十进制数,快写正好可以胜任。
在这里,我们使用最简单的一版快写——递归版,它的代码并不长,仅有三行:
代码 7-10 十进制数打印(monitor.c)
void monitor_write_dec(uint32_t dec)
{
int upper = dec / 10, rest = dec % 10;
if (upper) monitor_write_dec(upper);
monitor_put(rest + '0');
}
还是挺好懂的吧,先输出高位,再把最后一位输出出来。
十六进制相比十进制要难上一点,因为我们希望在输出十六进制的时候有一个 0x 前缀,这样就不能直接用递归了(不过硬要用递归也可以,写起来肯定比循环短)。
代码 7-11 十六进制打印(monitor.c)
void monitor_write_hex(uint32_t hex)
{
char buf[20]; // 32位最多0xffffffff,20个都多了
char *p = buf; // 用于写入的指针
char ch; // 当前十六进制字符
int i, flag = 0; // i -> 循环变量,flag -> 前导0是否结束
*p++ = '0';
*p++ = 'x'; // 先存一个0x
if (hex == 0) *p++ = '0'; // 如果是0,直接0x0结束
else {
for (i = 28; i >= 0; i -= 4) { // 每次4位,0xF = 0b1111
ch = (hex >> i) & 0xF; // 0~9, A~F
// 28的原因是多留一点后路(
if (flag || ch > 0) { // 跳过前导0
flag = 1; // 没有前导0就把flag设为1,这样后面再有0也不会忽略
ch += '0'; // 0~9 => '0'~'9'
if (ch > '9') {
ch += 7; // 'A' - '9' = 7
}
*p++ = ch; // 写入
}
}
}
*p = '\0'; // 结束符
monitor_write(buf);
}
具体如上,配合注释还是比较好懂的。至此,我们的“四步走”战略胜利完成。
最后的最后,自然是功能测试。新建 main.c,如此这般:
#include "monitor.h"
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear(); // 先清屏
monitor_write("Hello, kernel world!\n");
// 验证write_hex和write_dec,由于没有printf,这一步十分烦人
monitor_write_hex(0x114514);
monitor_write(" = ");
monitor_write_dec(0x114514);
monitor_write("\n");
// 悬停
while (1);
}
虽然前面我们一直在写C,但是忽略了一个问题,那就是怎么编译的问题。如果操作正确,在第0节您应该下载了i686-elf-tools(或者linux的gcc),如此这般编译:
i686-elf-gcc -c -O0 -fno-builtin -fno-stack-protector -o monitor.o monitor.c
这是编译 monitor.c 的示例。现在总的编译命令太长了,总共有这么多:
nasm boot.asm -o boot.bin
nasm loader.asm -o loader.bin
i686-elf-gcc -c -O0 -fno-builtin -fno-stack-protector -o monitor.o monitor.c
i686-elf-gcc -c -O0 -fno-builtin -fno-stack-protector -o common.o common.c
i686-elf-gcc -c -O0 -fno-builtin -fno-stack-protector -o main.o main.c
nasm -f elf -o kernel.o kernel.asm
i686-elf-ld -s -Ttext 0x100000 -o kernel.bin kernel.o common.o monitor.o main.o
edimg imgin:a.img copy from:loader.bin to:@: copy from:kernel.bin to:@: imgout:a.img
qemu-system-i386 -fda a.img
足足9条,随着文件越来越多它还会水涨船高,下一节我们来解决一下这个问题。
不过在此之前,我们还是要看看我们成果如何。把上面的那坨命令粘贴到命令行,QEMU 窗口应如下图:

(图 7-1 运行结果)
好,成功运行!
8.整理文件
本来想继续写代码的,但上一节的 9 条编译命令还是有些让人发怵:以后文件还会越来越多,难道就任由它这么发展下去?
况且,现在我们的根目录长这样:

(图 8-1 根目录的惨状)
各个部分堆在一起,杂乱无章,我们还是应该先整理一下根目录再说。
按照不同功能和部分的划分,我们把它这样分割:

(图 8-2 分割以后)
这样一分就很舒服了,但是编译命令也由此变成了彻底的地狱。下面就让我们引入在 Linux 下十分常见的自动编译工具——Makefile。
经常在 Linux 下装软件的朋友应该都知道,有的时候部分app只提供源代码,这样就只能按下面的三部曲安装:
./configure
make
sudo make install
这三步是什么意思呢?第一步 ./configure,生成 Makefile;第二步 make,用 make 工具调用 Makefile 编译;第三步 sudo make install,用 make 工具调用 Makefile 安装。
有三分之二的步骤都和 Makefile 相关,看来 Makefile 还真是个好工具呢。
Makefile 的实际应用比较复杂,我们这里只讲最简单的部分。一个 Makefile 是由多个块组成的,每个块的结构如下:
result : what you need
[TAB]command
需要注意的是,每个块的 command 部分必须以TAB开头,而在cnblogs编辑器里打不出TAB(会被自动替换为空格),因此只能用[TAB]来提示一下了,望大家谅解。
举个例子,如果我们想要把 kernel/monitor.c 编译为 out/monitor.o,我们应该怎样写出一个块呢?答案是这样:
out/monitor.o : kernel/monitor.c
[TAB]i686-elf-gcc -I include -c -O0 -fno-builtin -fno-stack-protector -o out/monitor.o kernel/monitor.c
新出现了 -I include 的选项,这是因为所有的头文件都在 include 文件夹下,需要这样才能被 gcc 识别。
诶诶且慢,要是每个文件都要这么来一下,那不还是没有解决问题么?
GNU 那帮人其实早就替我们想好啦,我们只需要先写好这么一个模板,然后进行一个替换:
out/%.o : kernel/%.c
[TAB]i686-elf-gcc -I include -c -O0 -fno-builtin -fno-stack-protector -o out/$*.o kernel/$*.c
这段代码与上面的 Makefile 并没有什么不同,只是把 command 中的 monitor 变成了 $*,把第一行的 monitor 变成了 % 而已。但这样一改,Makefile 就会对所有你要求编译的程序进行编译啦。
好,下面我们就继续进行对汇编的操作,其实和处理 C 几乎完全相同:
out/%.o : kernel/%.asm
[TAB]nasm -f elf -o out/$*.o kernel/$*.asm
out/%.bin : boot/%.asm
[TAB]nasm -I boot/include -o out/$*.bin boot/$*.asm
注意到 boot.bin 和 loader.bin 由汇编直接编译,所以我们也把它放在这了。添加 -I boot/include 的原因和添加 -I include 的原因相同,这里不多说了。
下面还剩下最后几步。首先,眼尖的读者可能已经发现了,在几段之前有这样一句话:
但这样一改,Makefile 就会对所有你要求编译的程序进行编译啦。
那 Makefile 怎么知道我们要编译哪些程序呢?分两种方案:
第一种,命令行指定。通过 make xxx.o 或 make xxx.bin,即可编译对应的文件。但如果这样,就又回到之前的问题了。
第二种,可以在一个块的 what you need 部分指定,然后 make result。这样,在 make result 的时候,make 会发现 what you need 还不存在,于是就会自动编译了。
看来第二种比较适合我们。不过,我们还没有链接 kernel.bin,所以可以先拿它试试手:
out/kernel.bin : $(OBJS)
[TAB]i686-elf-ld -s -Ttext 0x100000 -o out/kernel.bin $(OBJS)
这里新出现了 $(OBJS),它实际上就是 Makefile 里的变量。在 Makefile 的开头添加一行:
OBJS = out/kernel.o out/common.o out/monitor.o out/main.o
以后我们再增加新文件,就只需要在这里加一个 out/xxx.o,比之前可方便多了。
下面我们来进行测试,在命令行里输入 make out/kernel.bin:

(图 8-3 命令行输出)

(图 8-4 out 目录)
只一下,kernel.bin 便编译完成了。Makefile 的确方便哪(笑)。
但下面就是难点了:写盘操作在 Windows 和 Linux 下完全不一致。而想要判断当前操作系统是什么,并不简单,这正是 Makefile 的局限性。
(网上方法大都依赖 uname,但 Windows 没有 uname,所以会报错退出;所有依赖报错的方法会直接导致 make 终止,因此只能用其他语言的其他方法,如 Python 的 os.name。)
没办法,由于笔者是 Windows 机,所以我只好用 Windows 的方法写盘了。
a.img : out/boot.bin out/loader.bin out/kernel.bin
[TAB]dd if=out/boot.bin of=a.img bs=512 count=1
[TAB]edimg imgin:a.img copy from:out/loader.bin to:@: copy from:out/kernel.bin to:@: imgout:a.img
或许之前没提,command 部分可以有多条命令哦。
现在,make a.img,效果如下:

(图 8-5 完全胜利)
我们最后再加一条命令,make run,用于一步到位运行操作系统。
run : a.img
[TAB]qemu-system-i386 -fda a.img
执行 make run,效果如图:

(图 8-6 改造完成)
呼,经过一整节的整理,我们总算是有了一个可靠的自动编译系统。下面,我们就继续回到coding之中。
9.重设GDT、IDT
早在第5节,笔者其实就已经说过 GDT 到底是个什么东西了。但是,当时说得不够明确,语焉不详,因此在这里重新说一遍。
自 8086 时代以来,内存一直是一个PC上必不可少的物件。而在8086的时代,intel的大叔们拍着胸脯说:“内存绝不会超过1MB!”
然而,哪怕在当时,16位的寄存器最多也只能寻址64KB。于是,intel的大叔们想出了一种绝妙的方法,再加一组16位寄存器,叫做段寄存器,也就是 ds、es、fs、gs、ss,这样在寻址时,给段寄存器乘16,再加上原本的地址,就有了 64KB*16+64KB=1088KB 的寻址空间,比1MB刚刚超过一点。剩下的 64KB,intel的大叔们选择让它们指回0~64KB,完美!
进入32位之后,由32位寄存器来寻址,寻址空间可达4GB,再这么维持下去就不够用了。同时,32位模式又称“保护”模式,现有的方法也不足以进行“保护”,这就迫切地需要对段进行改革。
改革的具体方法如下。首先是段寄存器,它们不再是乘以16的这么一个代表,而是一个选择子,结构如下:
(图 9-1 选择子结构)
其中的 TI 和 RPL 正是这种改革引入的新东西,后面还要讲到,在这里不多说。多说几句的是剩下的12位,它代表的是描述符索引。何为描述符?GDT 全称 Global Descriptor Table(全局描述符表),其实就是GDT的表项。
好,段寄存器改革完毕了,但段本身也要进行改革,它不能再只代表一段连续的内存了。事实上,为了尽力压缩空间,intel的大叔们还是花了相当的功夫的,但最后也就形成了一种十分畸形的结构:
(图 9-2 描述符结构)
所谓前人挖坑,后人兼容,屎山大都是这么堆起来的,这种结构一直保存到现在的64位(笑)……不说别的了,我们来考虑些更加现实的问题。
早在 Loader 的阶段,我们已经设置过 GDT,不过它的样子大家恐怕都已经忘完了吧。所以我们需要把 GDT 移到内核来控制。
GDT 还有另外一个作用,那就是 IDT 需要依赖 GDT 提供的代码段选择子进行设置,所以必须先设置 GDT 才能设置 IDT。
那么,我们开始吧。依照上面的结构,新建 gdtidt.h,定义 GDT 描述符如下:
代码 9-1 GDT描述符(include/gdtidt.h)
struct gdt_entry_struct {
uint16_t limit_low; // BYTE 0~1
uint16_t base_low; // BYTE 2~3
uint8_t base_mid; // BYTE 4
uint8_t access_right; // BYTE 5, P|DPL|S|TYPE (1|2|1|4)
uint8_t limit_high; // BYTE 6, G|D/B|0|AVL|limit_high (1|1|1|1|4)
uint8_t base_high; // BYTE 7
} __attribute__((packed));
typedef struct gdt_entry_struct gdt_entry_t;
由于 C 语言编译器的对齐机制,如果什么都不做,会导致 GDT 的表项与硬件不符,因此需要加入 __attribute__((packed)) 禁用对齐功能。下面那个 typedef 仅仅是为了看着方便。
CPU 如何知道 GDT 的更改呢?这需要通过一个汇编指令:lgdt [addr],它可以从 addr 处读取六个字节作为新的 GDTR 寄存器,从而告知 CPU 新的 GDT 位置。
GDTR 的结构在前图 5-5 中有过标明,这里再放一遍:
(图 9-3 gdtr 结构)
以下是 C 语言定义的 GDTR 结构:
代码 9-2 GDT描述符(include/gdtidt.h)
struct gdt_ptr_struct {
uint16_t limit;
uint32_t base;
} __attribute__((packed));
typedef struct gdt_ptr_struct gdt_ptr_t;
出于同样的理由,我们使用了 __attribute__((packed))。
接下来,新建 gdtidt.c,我们来写一些实际内容。首先是几个简单的声明:
代码 9-3 头部声明(kernel/gdtidt.c)
#include "common.h"
#include "gdtidt.h"
extern void gdt_flush(uint32_t);
gdt_entry_t gdt_entries[4096];
gdt_ptr_t gdt_ptr;
紧接着是写入 GDT 表项的函数如下:
代码 9-4 写入GDT表项(kernel/gdtidt.c)
void gdt_set_gate(int32_t num, uint32_t base, uint32_t limit, uint16_t ar)
{
if (limit > 0xfffff) { // 段上限超过1MB
ar |= 0x8000; // ar的第15位(将被当作limit_high中的G位)设为1
limit /= 0x1000; // 段上限缩小为原来的1/4096,G位表示段上限为实际的4KB
}
// base部分没有其他的奇怪东西混杂,很好说
gdt_entries[num].base_low = base & 0xFFFF; // 低16位
gdt_entries[num].base_mid = (base >> 16) & 0xFF; // 中间8位
gdt_entries[num].base_high = (base >> 24) & 0xFF; // 高8位
// limit部分混了一坨ar进来,略微复杂
gdt_entries[num].limit_low = limit & 0xFFFF; // 低16位
gdt_entries[num].limit_high = ((limit >> 16) & 0x0F) | ((ar >> 8) & 0xF0); // 现在的limit最多为0xfffff,所以最高位只剩4位作为低4位,高4位自然被ar的高12位挤占
gdt_entries[num].access_right = ar & 0xFF; // ar部分只能存低4位了
}
这一部分的代码比较抽象,因为它与底层硬件逻辑密切相关,建议大家在理解时结合注释并对照前面的图9-2(描述符结构)来理解。
接下来,我们来初始化整个 GDT 表,同样位于 gdtidt.c:
代码 9-5 初始化 GDT(kernel/gdtidt.c)
static void init_gdt()
{
gdt_ptr.limit = sizeof(gdt_entry_t) * 4096 - 1; // GDT总共4096个描述符,但我们总共只用到3个
gdt_ptr.base = (uint32_t) &gdt_entries; // 基地址
gdt_set_gate(0, 0, 0, 0); // 占位用NULL段
gdt_set_gate(1, 0, 0xFFFFFFFF, 0x409A); // 32位代码段
gdt_set_gate(2, 0, 0xFFFFFFFF, 0x4092); // 32位数据段
gdt_flush((uint32_t) &gdt_ptr); // 刷新gdt
}
void init_gdtidt()
{
init_gdt(); // 目前只有gdt
}
这个0x409A、0x4092就纯靠死记硬背了,硬件规程如此。
最后是这个 gdt_flush,代码如下:
代码 9-6 刷新GDT(lib/nasmfunc.asm)
[global gdt_flush]
gdt_flush:
mov eax, [esp + 4] ; 根据C编译器约定,C语言传入的第一个参数位于内存esp + 4处,第二个位于esp + 8处,以此类推,第n个位于esp + n * 4处
lgdt [eax] ; 加载gdt并重新设置
; 接下来重新设置各段
mov ax, 0x10
mov ds, ax
mov es, ax
mov fs, ax
mov gs, ax
mov ss, ax ; 所有数据段均使用2号数据段
jmp 0x08:.flush ; 利用farjmp重置代码段为1号代码段并刷新流水线
.flush:
ret ; 完成
注释里提到了一个“编译器约定”,这个约定是传参数时候的约定;而在函数调用上,硬件本身也有一些规定,在这里一并说一说。
无论是在哪种模式下,但凡调用函数,基本都涉及一个返回的问题。既然要返回,我就得时时刻刻知道要返回到什么位置,返回地址这个东西就得保存,保在什么地方呢?intel 方面选择了 esp 的位置,也就是当前栈顶就是待返回的位置。
接下来一个自然的想法,就是把函数有关的东西全都放在栈里。由于 32 位模式地址可达 4 字节,因此下一个可用的位置是 esp + 4,这个参数又可以占用 4 字节,下一个可用的位置就是 esp + 8,以此类推。事实上,这正是 gcc 传参使用的模式(其实也可以指定 gcc 使用寄存器,__attribute__((regparm(xxx))) 其中 xxx 表示使用寄存器传参的个数)。
需要注意的是,返回的流程实际上就是 jmp [esp](默认栈平衡由被调用方保证,因此在最后栈顶应该回归到返回地址处)这么一个流程(当然还包括一些细节操作实际上比这复杂),所以只要随便找个地方写一个地址,然后把那个地方设成栈顶再调用 ret,即使根本没有调用函数,一样可以起到“从函数返回”的效果。
这样的操作有什么用呢?在同一个地址段当然没什么用,这样做甚至有些多余(完全可以直接 jmp)。这样做真正的用途,是在后面第 22 节的启动应用程序,以及 64 位模式下的时候,操作系统层级的 farjmp(直接 jmp 到其他地址段,使用例:jmp new_cs:new_ip)/farcall(直接 call 其他地址段的函数,使用例:call new_cs:new_eip)被禁用,只能使用这样的方式来代替直接跳转。同样地,farcall 需要对应 farret 来返回,而 farjmp 则和普通 jmp 一样一般不考虑返回。
那么这种 farjmp/farcall 与普通的 jmp/call 有什么区别呢?首先无疑是同时改变了 cs 的值,而 cs 除开这两种方法外,就只剩下 farret 一种改变方法了。硬说还有什么区别,也就只剩下栈了。farjmp 对栈倒是没什么改动,farcall 则会在栈里同时存一下几样东西:
esp -> 返回时 eip;esp - 4 -> 返回时 cs;esp - 8 -> 返回时 esp;esp - 12 -> 返回时 ss。
而在 farret 的时候,也就会把这四样东西从栈里弹出,最后进行一个相当于 farjmp 的操作,把 cs 和 eip 变“回去”。按照上面 ret 的道理,同样可以在栈里提前 push 好这四样东西,然后执行一个 farret(这个直接 retf 就行)同时设置好这四个寄存器的同时更改执行流。
扯得有点远了,稍微往回收一收。在接下来的操作应该都不难懂,最难以理解的地方也就是 lgdt [eax] 了。这是因为我们传入的是 gdt_ptr 结构体的地址,需要加一个 [gdt_ptr] 来获得它对应内存里的具体数值。再往下直接 mov 和上面解释过的 farjmp 应该没什么需要说的,由于 GDT 发生改动,所以需要重新设置段寄存器的值。
由于新增了一个文件夹,在这里顺便更新一下 Makefile:
代码 9-7 现在的Makefile(Makefile)
OBJS = out/kernel.o out/common.o out/monitor.o out/main.o out/gdtidt.o out/nasmfunc.o
out/%.o : kernel/%.c
i686-elf-gcc -c -I include -O0 -fno-builtin -fno-stack-protector -o out/$*.o kernel/$*.c
out/%.o : kernel/%.asm
nasm -f elf -o out/$*.o kernel/$*.asm
out/%.o : lib/%.c
i686-elf-gcc -c -I include -O0 -fno-builtin -fno-stack-protector -o out/$*.o lib/$*.c
out/%.o : lib/%.asm
nasm -f elf -o out/$*.o lib/$*.asm
out/%.bin : boot/%.asm
nasm -I boot/include -o out/$*.bin boot/$*.asm
out/kernel.bin : $(OBJS)
i686-elf-ld -s -Ttext 0x100000 -o out/kernel.bin $(OBJS)
a.img : out/boot.bin out/loader.bin out/kernel.bin
dd if=out/boot.bin of=a.img bs=512 count=1
edimg imgin:a.img copy from:out/loader.bin to:@: copy from:out/kernel.bin to:@: imgout:a.img
run : a.img
qemu-system-i386 -fda a.img
同样,使用 macOS/Linux 跟随本教程学习的需要自行更改 i686-elf-gcc、i686-elf-ld 以及对 a.img 进行写入的行为,所有的内容均在第0、1、8节有所介绍,在此不多赘述。
接下来,修改 main.c 用于测试现在的 GDT 是否有效:
代码 9-8 对重设 GDT 的测试(kernel/main.c)
#include "monitor.h"
#include "gdtidt.h"
void kernel_main() // kernel.asm会跳转到这里
{
init_gdtidt();
monitor_clear(); // 先清屏
monitor_write("Hello, kernel world!\n");
// 验证write_hex和write_dec,由于没有printf,这一步十分烦人
monitor_write_hex(0x114514);
monitor_write(" = ");
monitor_write_dec(0x114514);
monitor_write("\n");
// 悬停
while (1);
}
编译,运行,效果仍应如图 8-6所示。若您的qemu文字开始无限变换,请检查您的代码是否在运输途中出现了一些问题(?)
好了,一刻都没有为 GDT 的更改如此平淡而哀悼,立刻赶到现场的是——IDT!
事实上,前面提到的qemu内部文字的无限变换是底层 CPU 无限重启的现象,而造成它无限重启的根本原因则是找不到对应的异常处理程序。因此,现在的当务之急是为所有异常设置对应的异常处理程序,这就需要 IDT 了。
如果说重新设置 GDT 的原因是它位于 Loader 内,极不可控,那么重设 IDT 的原因就是,现在的 IDT 根本就是啥都没有。
与 GDT 相同,IDT 的每一个表项也叫做描述符,不过为了与 GDT 的描述符区分,一般称 IDT 的表项为中断描述符。由于中断描述符结构极其简单,此处不贴图。
与 GDT 类似,让 CPU 知道 IDT 在哪的方法是用 lidt 指令设置一个 IDTR 寄存器,其结构与 GDTR 寄存器完全一致。
中断描述符与 IDTR 寄存器结构定义如下:
代码 9-9 IDT表项与IDTR(include/gdtidt.h)
struct idt_entry_struct {
uint16_t offset_low, selector; // offset_low里没有一坨,selector为对应的保护模式代码段
uint8_t dw_count, access_right; // dw_count始终为0,access_right的值大多与硬件规程相关,只需要死记硬背,不需要进一步了解(
uint16_t offset_high; // offset_high里也没有一坨
} __attribute__((packed));
typedef struct idt_entry_struct idt_entry_t;
struct idt_ptr_struct {
uint16_t limit;
uint32_t base;
} __attribute__((packed));
typedef struct idt_ptr_struct idt_ptr_t;
查询资料可知,intel x86 总共有32个异常,我们记为 isr0~isr31。不过这 32 个处理程序我们不会单独列出,会放到一个数组里面。
由于没有烦人的一坨坨,IDT表项的设置十分简单:
代码 9-10 设置中断描述符、初始化IDT(kernel/gdtidt.c)
extern void *intr_table[48];
static void idt_set_gate(uint8_t num, uint32_t offset, uint16_t sel, uint8_t flags)
{
idt_entries[num].offset_low = offset & 0xFFFF;
idt_entries[num].selector = sel;
idt_entries[num].dw_count = 0;
idt_entries[num].access_right = flags;
idt_entries[num].offset_high = (offset >> 16) & 0xFFFF;
}
static void init_idt()
{
idt_ptr.limit = sizeof(idt_entry_t) * 256 - 1;
idt_ptr.base = (uint32_t) &idt_entries;
memset(&idt_entries, 0, sizeof(idt_entry_t) * 256);
for (int i = 0; i < 32; i++) {
idt_set_gate(i, (uint32_t) intr_table[i], 0x08, 0x8E);
}
idt_flush((uint32_t) &idt_ptr);
}
这里构建了一个 intr_table,到时候会在汇编里使用奇妙的小手段构建这个数组,现在先忘掉它吧,当它不存在。至于具体的设置,0x08表示内核代码段,0x8E的含义无需了解,但是只有这样设置才能正确设置异常处理程序。
代码 9-11 idt_flush(lib/nasmfunc.asm)
[global idt_flush]
idt_flush:
mov eax, [esp + 4]
lidt [eax]
ret
接下来,就是对这32个异常处理程序进行编写了。其实它们当中的相当一部分都是重复的。具体而言,先是要对中断环境进行保存,使 CPU 知道异常发生时的基本错误信息;然后,是调用对应的高层异常处理程序,这一部分可以用 C 语言完成。
因此,我们可以写出一个模糊的异常处理程序框架:
代码 9-12 模糊框架(无文件)
%macro ISR 1
[global isr%1]
isr%1:
push %1 ; 使处理程序知道异常号码
jmp isr_common_stub ; 通用部分
%endmacro
这个 %macro 在第五节已经出现过,如果忘了罚你重读。
这个宏的展开比较有意思。例如,ISR 0 展开后为:
[global isr0]
isr0:
push 0
jmp isr_common_stub
大概如此,汇编里的宏比 #define 简单一些,没有 # 和 ## 之类的奇怪东西,想拼接直接写在后面就可以了。
其实,这一部分离真正的框架已经相当近了。之所以不完全正确,是因为有的异常有错误码,而有的异常没有,我们需要让栈中的结构保持统一。这就需要我们在没有错误码的异常中压入一个假的错误码。
查询资料可知,第8、10~14、17、21号异常有错误码,其余异常无错误码,我们需要对其他的异常进行特别关照。
综上,我们得出的基本框架如下:
代码 9-13 真实框架?(kernel/interrupt.asm)
%macro ISR_ERRCODE 1
[global isr%1]
isr%1:
push %1 ; 使处理程序知道异常号码
jmp isr_common_stub ; 通用部分
%endmacro
%macro ISR_NOERRCODE 1
[global isr%1]
isr%1:
push byte 0 ; 异常错误码是四个字节,这里只push一个字节原因未知
push %1 ; 使处理程序知道异常号码
jmp isr_common_stub ; 通用部分
%endmacro
ISR_NOERRCODE 0
ISR_NOERRCODE 1
ISR_NOERRCODE 2
ISR_NOERRCODE 3
ISR_NOERRCODE 4
ISR_NOERRCODE 5
ISR_NOERRCODE 6
ISR_NOERRCODE 7
ISR_ERRCODE 8
ISR_NOERRCODE 9
ISR_ERRCODE 10
ISR_ERRCODE 11
ISR_ERRCODE 12
ISR_ERRCODE 13
ISR_ERRCODE 14
ISR_NOERRCODE 15
ISR_NOERRCODE 16
ISR_ERRCODE 17
ISR_NOERRCODE 18
ISR_NOERRCODE 19
ISR_NOERRCODE 20
ISR_ERRCODE 21
ISR_NOERRCODE 22
ISR_NOERRCODE 23
ISR_NOERRCODE 24
ISR_NOERRCODE 25
ISR_NOERRCODE 26
ISR_NOERRCODE 27
ISR_NOERRCODE 28
ISR_NOERRCODE 29
ISR_NOERRCODE 30
ISR_NOERRCODE 31
现在我们再来考虑构建 intr_table 的事。难道是要靠 dd 这一堆 isr 函数么?事实上,通过利用 section 的特性,可以轻易做到这一点:
代码 9-14 真实框架(kernel/interrupt.asm)
section .data
global intr_table
intr_table:
%macro ISR_ERRCODE 1
section .text
isr%1:
push %1 ; 使处理程序知道异常号码
jmp isr_common_stub ; 通用部分
section .data
dd isr%1
%endmacro
%macro ISR_NOERRCODE 1
section .text
isr%1:
push byte 0 ; 异常错误码是四个字节,这里只push一个字节原因未知
push %1 ; 使处理程序知道异常号码
jmp isr_common_stub ; 通用部分
section .data
dd isr%1
%endmacro
这是个什么原理?事实上,通过划分 section,nasm 就知道“哦,这些是代码,这些是数据,要分开存放”。于是,代码会按出现顺序合并,数据也会按出现顺序合并,相当于是编译器帮我们代劳了分开程序主体和程序位置的工作。这样,在 intr_table 中就是纯净的函数了。
接下来,是 isr_common_stub。这个东西写起来不麻烦,无非是保存和还原中断环境而已:
代码 9-15 异常处理公共部分(kernel/interrupt.asm)
section .text
[extern isr_handler] ; 将会在isr.c中被定义
; 通用中断处理程序
isr_common_stub:
pusha ; 存储所有寄存器
mov ax, ds
push eax ; 存储ds
mov ax, 0x10 ; 将内核数据段赋值给各段
mov ds, ax
mov es, ax
mov fs, ax
mov gs, ax
call isr_handler ; 调用C语言处理函数
pop eax ; 恢复各段
mov ds, ax
mov es, ax
mov fs, ax
mov gs, ax
popa ; 弹出所有寄存器
add esp, 8 ; 弹出错误码和中断ID
iret ; 从中断返回
这个消掉了,又出现一个 isr_handler,真是麻烦。不过这场打地鼠的游戏也要迎来收尾了,而且另一个好消息是,这个东西是用 C 语言写的,代码如下:
代码 9-16 真正的异常处理部分(kernel/isr.c)
#include "monitor.h"
#include "isr.h"
void isr_handler(registers_t regs)
{
asm("cli");
monitor_write("received interrupt: ");
monitor_write_dec(regs.int_no);
monitor_put('\n');
while (1);
}
这里为什么要 cli 和 while (1); 呢?一般出现异常时已经无可挽回,因此直接悬停在处理程序里即可。cli 防止下一节要设置的外部中断来烦人。
代码 9-17 registers_t的定义(kernel/isr.h)
#ifndef _ISR_H_
#define _ISR_H_
#include "common.h"
typedef struct registers {
uint32_t ds;
uint32_t edi, esi, ebp, esp, ebx, edx, ecx, eax;
uint32_t int_no, err_code;
uint32_t eip, cs, eflags, user_esp, ss;
} registers_t;
#endif
gdtidt.c 的开头也要作修改:
代码 9-18 新版 gdtidt 开头,替换至gdt_set_gate之前(kernel/gdtidt.c)
#include "common.h"
#include "gdtidt.h"
extern void gdt_flush(uint32_t);
extern void idt_flush(uint32_t);
gdt_entry_t gdt_entries[4096];
gdt_ptr_t gdt_ptr;
idt_entry_t idt_entries[256];
idt_ptr_t idt_ptr;
注意到 init_idt 中用到了 memset,为此将后续会用到的字符串/内存操作函数统一copy进来,组合成 lib/string.c:
代码 9-19 字符串操作函数(lib/string.c)
#include "common.h"
void *memset(void *dst_, uint8_t value, uint32_t size)
{
uint8_t *dst = (uint8_t *) dst_;
while (size-- > 0) *dst++ = value;
return dst_;
}
void *memcpy(void *dst_, const void *src_, uint32_t size)
{
uint8_t *dst = dst_;
const uint8_t *src = src_;
while (size-- > 0) *dst++ = *src++;
return (void *) src_;
}
int memcmp(const void *a_, const void *b_, uint32_t size)
{
const char *a = a_;
const char *b = b_;
while (size-- > 0) {
if (*a != *b) return *a > *b ? 1 : -1;
a++, b++;
}
return 0;
}
char *strcpy(char *dst_, const char *src_)
{
char *r = dst_;
while ((*dst_++ = *src_++));
return r;
}
uint32_t strlen(const char *str)
{
const char *p = str;
while (*p++);
return p - str - 1;
}
int8_t strcmp(const char *a, const char *b)
{
while (*a && *a == *b) a++, b++;
return *a < *b ? -1 : *a > *b;
}
char *strchr(const char *str, const uint8_t ch)
{
while (*str) {
if (*str == ch) return (char *) str;
str++;
}
return NULL;
}
代码 9-20 头文件(include/string.h)
#ifndef _STRING_H_
#define _STRING_H_
void *memset(void *dst_, uint8_t value, uint32_t size);
void *memcpy(void *dst_, const void *src_, uint32_t size);
int memcmp(const void *a_, const void *b_, uint32_t size);
char *strcpy(char *dst_, const char *src_);
uint32_t strlen(const char *str);
int8_t strcmp(const char *a, const char *b);
char *strchr(const char *str, const uint8_t ch);
#endif
最后,在 common.h 中加入 #include "string.h",在 init_gdtidt 中加入一行 init_idt(),并在 kernel_main 中,在 while (1); 之前加入一行 asm("ud2");,在 Makefile 的 OBJS 变量中加入 out/string.o out/isr.o out/interrupt.o。
若上述所有操作全部正确无误,那么编译运行后效果应如下图:

(图 9-4 运行效果)
尽管我们只测试了一个 ud2 异常,即6号异常,但我们足以相信,整个 IDT 对于异常已经设置无误了。
10.接收外部中断,从时钟开始
第9节中,我们设置的异常是一种内部的中断。而本节,我们将要接收来自外部设备的中断。
话说回来,我们前面一直提到中断,到底什么是中断?字面意思上讲,就是你正在持续的工作被突然打断。发挥联想记忆,可以知道,中断实际上就是在操作系统正常运行的过程中,让它被迫接收的信号。
与现实生活中的中断不同,操作系统中,中断是操作系统最本质的驱动力,如果没有中断,一切都会非常复杂,CPU将花费大量的时间查询设备状态;而现在,不同的硬件会发不同的中断信号,在接收的过程中慢慢处理即可。我们的中断像是打断正常工作,而 CPU 里的中断像是打断以回到正常工作,听起来似乎截然相反。
扯得有点多,往回收收。由于0-31号IDT已经归给了异常,现在又有16个外设中断信号,那么最自然的想法,就是把它们放置在32-47号IDT。
什么?你说电脑明明有一堆外设,中断号为什么这么少?仔细想想就会发现,如果所有的外设都给CPU发中断,那CPU不仅分辨不出来谁是谁,更是要炸了。因此,在x86框架下,所有的中断会被汇集到一个叫做8259A的芯片,它还有另一个名字,叫做可编程中断控制器(PIC),当然,目前已经被淘汰了。实际操作中,由PIC分辨每一个外设,并发送两个字节(0xCD 外设编号)给CPU,从而使得CPU自动执行对应外设的中断处理程序。
好了,原理大致如此,我们开始。这么一看,中断处理和IDT也脱不了干系,先对16个外设中断信号对应的IDT进行设置,以下是新的 init_idt:
代码 10-1 设置外设中断信号对应的中断描述符(kernel/gdtidt.c)
static void init_idt()
{
idt_ptr.limit = sizeof(idt_entry_t) * 256 - 1;
idt_ptr.base = (uint32_t) &idt_entries;
memset(&idt_entries, 0, sizeof(idt_entry_t) * 256);
for (int i = 0; i < 32 + 16; i++) {
idt_set_gate(i, (uint32_t) intr_table[i], 0x08, 0x8E);
}
idt_flush((uint32_t) &idt_ptr);
}
找不同环节,你能发现哪里做了修改吗?其实就是在 32 后面加了 16,因为总共有 16 个外设中断信号嘛。
interrupt.asm 中的代码几乎与异常时如出一辙,这些东西要放在 isr_common_stub 之前:
代码 10-2 外设中断信号的实现(kernel/interrupt.asm)
section .data
%macro IRQ 1
section .text
irq%1:
cli
push byte 0
push %1
jmp irq_common_stub
section .data
dd irq%1
%endmacro
IRQ 32
IRQ 33
IRQ 34
IRQ 35
IRQ 36
IRQ 37
IRQ 38
IRQ 39
IRQ 40
IRQ 41
IRQ 42
IRQ 43
IRQ 44
IRQ 45
IRQ 46
IRQ 47
section .text
[extern irq_handler]
; 通用中断处理程序
irq_common_stub:
pusha ; 存储所有寄存器
mov ax, ds
push eax ; 存储ds
mov ax, 0x10 ; 将内核数据段赋值给各段
mov ds, ax
mov es, ax
mov fs, ax
mov gs, ax
call irq_handler ; 调用C语言处理函数
pop eax ; 恢复各段
mov ds, ax
mov es, ax
mov fs, ax
mov gs, ax
popa ; 弹出所有寄存器
add esp, 8 ; 弹出错误码和中断ID
iret ; 从中断返回
结果 IRQ 宏里还是一样的小把戏,只是调用的宏换了个名字。最后是 irq_handler,放上来看看:
代码 10-3 中断处理程序的C语言接口(kernel/isr.c)
void irq_handler(registers_t regs)
{
monitor_write("received irq: ");
monitor_write_dec(regs.int_no);
monitor_put('\n');
}
甚至完全一致,除了删掉了关闭中断和无限悬停的部分。
最后,由于 kernel.asm 中关闭了外部中断,在此处需要重新打开。因此,需要在 main.c 中把上一节测试用的 asm("ud2"); 替换为 asm("sti");。
完整 main.c 如下:
代码 10-4 测试用(kernel/main.c)
#include "monitor.h"
#include "gdtidt.h"
void kernel_main() // kernel.asm会跳转到这里
{
init_gdtidt();
monitor_clear(); // 先清屏
monitor_write("Hello, kernel world!\n");
// 验证write_hex和write_dec,由于没有printf,这一步十分烦人
monitor_write_hex(0x114514);
monitor_write(" = ");
monitor_write_dec(0x114514);
monitor_write("\n");
asm("sti");
// 悬停
while (1);
}
编译,运行,效果如图:

(图 10-1 运行失败)
嗯?8号中断?这不是异常吗?这是怎么回事??
我当初做到这里的时候,一度怀疑人生,在代码中查询到底是哪里出了问题,最终没有结果(笑)。后来查阅资料发现,8号异常不会随便出现,当CPU找不到对应异常的处理程序,但是有8号异常处理程序时,才会调用8号异常处理程序(顺便说一下,如果没有8号处理程序,结果自然就是重启啦)。最终我才得以确定,程序本身并没有问题。
那么,这个神秘的8号异常是哪里来的呢?
解铃还须系铃人。我们鼓捣了半天,偏偏把最重要的 PIC 给忘了!而16位模式下,PIC默认时钟中断为对应的是 8 号而不是我们新设定的 32 号,由于我们没管PIC,所以它还是16位的状态,此时出现了时钟中断,PIC自然就会给CPU发送8号中断!
重设PIC也是非常古老、非常屎山也是非常定式的操作,由于涉及到硬件,这里不多解说。总之只要添加这8行代码,就没有问题(把它们添加在 init_idt 中的 memset 之前):
代码 10-5 重设PIC(kernel/gdtidt.c)
// 初始化PIC
outb(0x20, 0x11);
outb(0xA0, 0x11);
outb(0x21, 0x20);
outb(0xA1, 0x28);
outb(0x21, 0x04);
outb(0xA1, 0x02);
outb(0x21, 0x01);
outb(0xA1, 0x01);
outb(0x21, 0x0);
outb(0xA1, 0x0);
老样子,编译运行,效果如图:

(图 10-2 成功一半)
出现了 received irq: 32,说明我们重设PIC成功了,耶!但是仔细一想,谁家时钟只会滴答一次?那么为什么我们的时钟中断只发了一次就没有了?
这是因为,PIC非常忙,不止有这一个外设要管,鬼知道你这边完事没有。因此,我们需要向PIC发信号说“处理完毕啦”,这个信号被称作EOI。
我们在 irq_handler 中加入EOI的发送:
代码 10-6 发送EOI(kernel/isr.c)
void irq_handler(registers_t regs)
{
if (regs.int_no >= 0x28) outb(0xA0, 0x20); // 给从片发EOI
outb(0x20, 0x20); // 给主片发EOI
monitor_write("received irq: ");
monitor_write_dec(regs.int_no);
monitor_put('\n');
}
这里的从片主片又是什么东西呢?虽然总共有16个外设信号,但是一个PIC总共只有8条向外输出的线,只好搞两个PIC,一主一从,两个PIC通过两个外设中断互相交换信息。所以,其实有两个外设中断是没有用的。
这下总行了吧?编译,运行,效果如图:

(图 10-3 成功)
至此,我们成功实现了对 IRQ 的接收。不过,我们对外设中断的要求更苛刻一点——能不能让接收方自己决定怎么处置外设中断呢?
这一部分完全在软件层级,可以用 C 语言来完成。
首先,定义自定义中断处理程序函数:
代码 10-7 开始自定义中断处理程序(kernel/isr.h)
#define IRQ0 32
#define IRQ1 33
#define IRQ2 34
#define IRQ3 35
#define IRQ4 36
#define IRQ5 37
#define IRQ6 38
#define IRQ7 39
#define IRQ8 40
#define IRQ9 41
#define IRQ10 42
#define IRQ11 43
#define IRQ12 44
#define IRQ13 45
#define IRQ14 46
#define IRQ15 47
typedef void (*isr_t)(registers_t *);
void register_interrupt_handler(uint8_t n, isr_t handler);
下面已经添加了注册函数了,在 isr.c 中加入一行:
代码 10-8 自定义中断处理程序列表(kernel/isr.c)
static isr_t interrupt_handlers[256];
由于 isr_t 是函数指针,因此可以用是否为 NULL 判断是否存在自定义中断处理程序。这是新版的 irq_handler:
代码 10-9 将中断信号分发给自定义处理程序,以及注册函数(kernel/isr.c)
void irq_handler(registers_t regs)
{
if (regs.int_no >= 0x28) outb(0xA0, 0x20); // 中断号 >= 40,来自从片,发送EOI给从片
outb(0x20, 0x20); // 发送EOI给主片
if (interrupt_handlers[regs.int_no])
{
isr_t handler = interrupt_handlers[regs.int_no]; // 有自定义处理程序,调用之
handler(®s); // 传入寄存器
}
}
void register_interrupt_handler(uint8_t n, isr_t handler)
{
interrupt_handlers[n] = handler;
}
为避免 regs 在传值中出现不必要的拷贝,这里选择使用指针形式向自定义中断处理程序传入寄存器。
现在再编译运行,应该恢复到图 8-6 的状态了,一片祥和。
那么,接下来就是暴风雨了,我们来自定义一个时钟中断处理程序。
首先,对于时钟中断目前的频率,我们只知道 PIT 内部的时钟频率为 1193180 Hz(什么b数),对于具体的频率,我们是一无所知的。不过,这个值可以更改,具体方法为:
-
用 1193180 Hz 除以希望每多少毫秒给一个时钟中断的数值,记为 x;
-
向 0x43 端口(时钟 Command 寄存器)发送 0x36(设置频率)指令;
-
分两次向 0x40 端口(时钟 Counter 0 寄存器,管理和计数相关的东西)分别发送 x 的低8位和高8位。
上述逻辑并不复杂。为了管理时钟,我们新建一个 timer.c,其具体代码依照上面逻辑可如下写出:
代码 10-11 时钟管理程序(kernel/timer.c)
#include "timer.h"
#include "isr.h"
#include "monitor.h"
uint32_t tick = 0; // 这里做一下记录,不过也没什么用?
static void timer_callback(registers_t *regs)
{
tick++;
monitor_write("Tick: ");
monitor_write_dec(tick);
monitor_put('\n'); // 测试用,暂时打印一下ticks
}
void init_timer(uint32_t freq)
{
register_interrupt_handler(IRQ0, &timer_callback); // 将时钟中断处理程序注册给IRQ框架
uint32_t divisor = 1193180 / freq;
outb(0x43, 0x36); // 指令位,写入频率
uint8_t l = (uint8_t) (divisor & 0xFF); // 低8位
uint8_t h = (uint8_t) ((divisor >> 8) & 0xFF); // 高8位
outb(0x40, l);
outb(0x40, h); // 分两次发出
}
代码 10-12 声明(include/timer.h)
#ifndef _TIMER_H_
#define _TIMER_H_
#include "common.h"
void init_timer(uint32_t freq);
#endif
我们不仅增加了 init_timer,而且还注册了时钟中断的处理函数。目前它只是打印一下当前的ticks,后面会对它进行更改。
最后,在 kernel_main 中加入一行 init_timer(50);,在 Makefile 的 OBJS 变量后面追加 timer.o,编译,运行,效果如图:

(图 10-4 自定义时钟中断处理程序)
我们看到了不断增加的 ticks,这是一个极好的现象,说明我们对时钟的设置和对 IRQ 自定义处理程序的设置都成功了。
11.段式内存管理的实现
虽然说时钟中断往后的最合理的主题就是多任务,但从目录可以看出来,多任务是下一节的内容,本节我们首先实现一个极其简单的内存管理系统。
什么是内存管理?内存管理,就是管理内存(什么废话文学)。直接解释其含义有点困难,不过,内存的分配和释放,就是内存管理的主要部分。
本节内容大部分参考自《30天自制操作系统》,有原书的建议结合原书交叉参考,毕竟我这个写出来的东西和人家原书肯定是比不了的。
好了,我们开始吧。首先,既然要管理内存,必然要知道内存总共有多大。在 BIOS 中,有非常多的方法来做到(均基于 int 15h,根据 ax 的值为 0xe820、0xe801 和 0x66 分别有不同的行为),但是现在已经到了保护模式,没法用 BIOS 了,怎么办?
换个思路想:32位下内存最多为4GB,如果往没有内存的地方写入一些字节,再读出来的时候,不管长什么样,肯定不会是写入时候的样子。所以,我们只需要指定一个开头和结尾,对这一段区域的所有内存进行试写,如果遇到了边界,那么直接退出,并报告边界值即可。
看上去很美好,但intel的设计更为前卫,为了增加访问内存的效率,486之后的intel cpu加入了缓存功能。在缓存中读写自然是没有意义的,因此首先要检测是否在486以上,如果是,那么就要把缓存关掉。
因此,我们新建 memory.c,简单写一下内存检测的部分。
代码 11-1 内存检测(kernel/memory.c)
#include "common.h"
#include "memory.h"
#define EFLAGS_AC_BIT 0x00040000
#define CR0_CACHE_DISABLE 0x60000000
extern uint32_t load_eflags();
extern uint32_t load_cr0();
extern void store_eflags(uint32_t);
extern void store_cr0(uint32_t);
static uint32_t memtest_sub(uint32_t start, uint32_t end)
{
uint32_t i, *p, old, pat0 = 0xaa55aa55, pat1 = 0x55aa55aa;
for (i = start; i <= end; i += 0x1000) {
p = (uint32_t *) (i + 0xffc); // 每4KB检查最后4个字节
old = *p; // 记住修改前的值
*p = pat0; // 试写
*p ^= 0xffffffff; // 翻转
if (*p != pat1) { // ~pat0 = pat1,翻转之后如果不是pat1则写入失败
*p = old; // 写回去
break;
}
*p ^= 0xffffffff; // 再翻转
if (*p != pat0) { // 两次翻转应该转回去,如果不是pat0则写入失败
*p = old; // 写回去
break;
}
*p = old; // 试写完毕,此4KB可用,恢复为修改前的值
}
return i; // 返回内存容量
}
static uint32_t memtest(uint32_t start, uint32_t end)
{
char flg486 = 0;
uint32_t eflags, cr0, i;
eflags = load_eflags();
eflags |= EFLAGS_AC_BIT; // AC-bit = 1
store_eflags(eflags);
eflags = load_eflags();
if ((eflags & EFLAGS_AC_BIT) != 0) flg486 = 1;
// 486的CPU会把AC位当回事,但386的则会把AC位始终置0
// 这样就可以判断CPU是否在486以上
// 恢复回去
eflags &= ~EFLAGS_AC_BIT; // AC-bit = 0
store_eflags(eflags);
if (flg486) {
cr0 = load_cr0();
cr0 |= CR0_CACHE_DISABLE; // 禁用缓存
store_cr0(cr0);
}
i = memtest_sub(start, end); // 真正的内存探测函数
if (flg486) {
cr0 = load_cr0();
cr0 &= ~CR0_CACHE_DISABLE; // 允许缓存
store_cr0(cr0);
}
return i;
}
配合注释应该不难理解……吧。为了加快效率,memtest_sub 每次只检测每一个 4KB 的开头。memtest 则是对 memtest_sub 的封装,加上了判断486、关闭缓存等的过程。
在这里用到了对 eflags 和 cr0 进行操作的四个汇编函数,代码如下:
代码 11-2 操作eflags和cr0的汇编(lib/nasmfunc.asm)
[global load_eflags]
load_eflags:
pushfd ; eflags寄存器只能用pushfd/popfd操作,将eflags入栈/将栈中内容弹入eflags
pop eax ; eax = eflags;
ret ; return eax;
[global store_eflags]
store_eflags:
mov eax, [esp + 4] ; 获取参数
push eax
popfd ; eflags = eax;
ret
[global load_cr0]
load_cr0:
mov eax, cr0 ; cr0只能和eax之间mov
ret ; return cr0;
[global store_cr0]
store_cr0:
mov eax, [esp + 4] ; 获取参数
mov cr0, eax ; 赋值cr0
ret
程序写好了,怎么测试呢?看看这样行不行:
代码 11-3 init_memory(kernel/memory.c)
void init_memory()
{
uint32_t memtotal = memtest(0x00400000, 0xbfffffff); // 检测4MB~3GB范围内的内存
monitor_write("memory ");
monitor_write_dec(memtotal / 1024 / 1024);
monitor_write("MB\n"); // 以MB形式打印出来
}
代码 11-4 头文件(include/memory.h)
#ifndef _MEMORY_H_
#define _MEMORY_H_
#include "common.h"
void init_memory();
#endif
代码 11-5 测试用main(kernel/main.c)
#include "monitor.h"
#include "gdtidt.h"
#include "memory.h"
#include "timer.h"
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear(); // 先清屏
init_gdtidt();
init_timer(50);
init_memory();
monitor_write("Hello, kernel world!\n");
// 验证write_hex和write_dec,由于没有printf,这一步十分烦人
monitor_write_hex(0x114514);
monitor_write(" = ");
monitor_write_dec(0x114514);
monitor_write("\n");
//asm("sti");
// 悬停
while (1);
}
编译,运行,效果如图所示:

(图 11-1 内存检测成功)
我们的检测程序报告共有128MB内存,这与 QEMU 的默认设置相符。如果读者不放心,可以自行在 qemu 的参数中加入 -m <memsize> 参数指定内存大小,其中 memsize 以MB为单位。
检测完了,下面就该正式进行管理了。我目前看到的所有教程中,大致可将内存管理方案分为三种:位图型,表格型以及混合型。
位图型,是指用位图的方式来管理内存。位图其实就是一个字符数组,每一个数组的每一位分别代表一个管理单元(通常为4KB),若要分配连续多个4KB的内存,则需要操控位图的单独位来实现。这种方法不仅说起来麻烦,写起来也麻烦,因此不考虑了。
表格型就非常好理解了,就是把可用内存信息放在一个一个的表项中,每一个项的内容包括起始地址、内存大小等信息。在这里为了偷懒,就只包括这两项信息了。事实上,以UEFI为基础的64位操作系统内核中,离不开与这种表格的交道(在此不详谈了,更何况64位的基本属于混合型)。
混合型比这两种还要复杂,也不多考虑了。
综上,我们最终选择了表格型的方式进行管理。如果硬要写一段代码的话,大致是这样的:
代码 11-6 表格型内存管理方案示例(无文件)
// 定义
typedef struct FREEINFO {
uint32_t addr, size;
} freeinfo_t;
typedef struct MEMMAN {
int frees;
freeinfo_t free[1000];
} memman_t;
// 初始化
memman_t memman;
memman.frees = 1;
memman.free[0].addr = 0x7c00;
memman.free[0].size = 0x400;
// 分配
memman.free[0].addr += size;
memman.free[0].size -= size;
// 释放
memman.free[0].addr -= size;
memman.free[0].size += size;
可以看出来,不管是初始化、分配、还是释放,时间复杂度都是O(1)级别的。虽然表项一多,释放的代码也会跟着多,但总体而言,和释放内存多少并没有关系。如果用位图型的话,那分配和释放多少内存就要写多少个“1”和“0”,这么一看,表格型的时间复杂度也要低一些。
为了以防读者绕不过来弯,在此特别声明:内存被分配,是程序拿到了内存,所以内存分配器失去这段内存的管理权;内存被释放,是程序放弃了内存,所以内存分配器拿回这段内存的管理权。所以,当我们需要给内存分配器一点内存的时候,要调用 free 而不是 alloc。
好了,我们开始吧。首先把上面的表项依样画葫芦抄下来:
代码 11-7 表格型内存管理数据结构的定义(include/memory.h)
#define MEMMAN_FREES 4090
typedef struct FREEINFO {
uint32_t addr, size;
} freeinfo_t;
typedef struct MEMMAN {
int frees;
freeinfo_t free[MEMMAN_FREES];
} memman_t;
紧接着,是初始化、总数据和分配的代码,由于十分简单,合并为同一个部分:
代码 11-8 表格初始化、表格总数据和内存分配(kernel/memory.c)
static void memman_init(memman_t *man)
{
man->frees = 0;
}
static uint32_t memman_total(memman_t *man)
{
uint32_t i, t = 0;
for (i = 0; i < man->frees; i++) t += man->free[i].size; // 剩余内存总和
return t;
}
static uint32_t memman_alloc(memman_t *man, uint32_t size)
{
uint32_t i, a;
for (i = 0; man->frees; i++) {
if (man->free[i].size >= size) { // 找到了足够的内存
a = man->free[i].addr;
man->free[i].addr += size; // addr后移,因为原来的addr被使用了
man->free[i].size -= size; // size也要减掉
if (man->free[i].size == 0) { // 这一条size被分配完了
man->frees--; // 减一条frees
for (; i < man->frees; i++) {
man->free[i] = man->free[i + 1]; // 各free前移
}
}
return a; // 返回
}
}
return 0; // 无可用空间
}
内存分配和总数据统计就不多解释了,分配的操作大部分都已经解释过,也不多说。
接下来是内存释放,这一部分比较复杂。
代码 11-9 内存释放(kernel/memory.c)
static int memman_free(memman_t *man, uint32_t addr, uint32_t size)
{
int i, j;
for (i = 0; i < man->frees; i++) {
// 各free按addr升序排列
if (man->free[i].addr > addr) break; // 找到位置了!
// 现在的这个位置是第一个在addr之后的位置,有man->free[i - 1].addr < addr < man->free[i].addr
}
if (i > 0) {
if (man->free[i - 1].addr + man->free[i - 1].size == addr) {
// 可以和前面的可用部分合并
man->free[i - 1].size += size; // 并入
if (i < man->frees) {
if (addr + size == man->free[i].addr) {
// 可以与后面的可用部分合并
man->free[i - 1].size += man->free[i].size;
// man->free[i]删除不用
man->frees--; // frees减1
for (; i < man->frees; i++) {
man->free[i] = man->free[i + 1]; // 前移
}
}
}
return 0; // free完毕
}
}
// 不能与前面的合并
if (i < man->frees) {
if (addr + size == man->free[i].addr) {
// 可以与后面的可用部分合并
man->free[i].addr = addr;
man->free[i].size += size;
return 0; // 成功合并
}
}
// 两边都合并不了
if (man->frees < MEMMAN_FREES) {
// free[i]之后的后移,腾出空间
for (j = man->frees; j > i; j--) man->free[j] = man->free[j - 1];
man->frees++;
man->free[i].addr = addr;
man->free[i].size = size; // 更新当前地址和大小
return 0; // 成功合并
}
// 无free可用且无法合并
return -1; // 失败
}
释放的部分比上面三个部分加起来还长,解释一下。
首先,稍微分析一下就会发现,在表格中的所有表项,必然以基地址为键呈升序排列(也就是说,越往后的项,基地址也越大)。正因如此,第3~8行的判断才得以顺利进行。
第926行,是当前释放的这一段内存与前后进行合并的判断。第2835行,如果无法与前面的合并,则要进行与后面的内存合并的判断。如果不这样判断,会出现下面的情况:
内存表项0: 起始地址 0x400000,大小 3KB
内存表项1: 起始地址 0x401000,大小 4KB
当释放从 0x400c00 开始的 1KB 时,如果不进行判断,那么如果后续要分配 5KB 内存,便无从下手。然而,这三段内存(表项0、表项1、刚释放)实际上是以 0x400000 为起始、共计 8KB 的连续内存空间,完全可以分配 5KB 内存。
如果都合并不了,只好单独创建一个内存块插入在这之间。如果已经完全没有地方,只好返回-1报错了。
好了,到此为止,我们仅用了不到200行代码,就完成了段式内存管理的实现——吧。在此之前,我们要对段式内存管理进行一个基本的封装。
首先,现在的内存释放需要指定大小,这实在是非常不方便的一个因素。因此,我们需要开辟出一定的内存空间,供内存释放时读取大小使用。
具体而言,封装后的 kmalloc 和 kfree 如下:
代码 11-10 最终封装内存管理(kernel/memory.c)
void *kmalloc(uint32_t size)
{
uint32_t addr;
memman_t *memman = (memman_t *) MEMMAN_ADDR;
addr = memman_alloc(memman, size + 16); // 多分配16字节
memset((void *) addr, 0, size + 16);
char *p = (char *) addr;
if (p) {
*((int *) p) = size;
p += 16;
}
return (void *) p;
}
void kfree(void *p)
{
char *q = (char *) p;
int size = 0;
if (q) {
q -= 16;
size = *((int *) q);
}
memman_t *memman = (memman_t *) MEMMAN_ADDR;
memman_free(memman, (uint32_t) q, size + 16);
p = NULL;
return;
}
代码 11-11 MEMMAN_ADDR 的定义(include/memory.h)
#define MEMMAN_ADDR 0x003c0000
这一部分涉及到相当晦涩的指针操作,简单解释一下。
在 kmalloc 中,首先从一个固定的地址(0x3c0000)读出一个 memman_t 来,然后分配 size 字节的内存。注意这里还多分配了 16 个字节,这是干什么用的呢?
众所周知,free 是不需要知道这段内存的大小的,我们希望 kfree 也是一样。所以,我们便需要在这段内存的一开头把大小存起来。这也就是第 351 行在干的事情:把 p 转化成 int 指针,再向它这个地址处写入大小,最后把指针后移16把大小这一块空过去。
同理,在 kfree 中,先从地址最开头读出大小,然后从同一个 memman_t 处把内存释放。
最后的最后,由于 kmalloc 和 kfree 都指着这块地的 memman_t 呢,我们需要在 init_memory 中初始化 memman。代码如下:
代码 11-12 初始化 memman(kernel/memory.c)
void init_memory()
{
uint32_t memtotal = memtest(0x00400000, 0xbfffffff);
memman_t *memman = (memman_t *) MEMMAN_ADDR;
memman_init(memman);
memman_free(memman, 0x400000, memtotal - 0x400000);
}
同样删去了打印,因为用不到了。
内存管理到此结束,我们还真验证不了它能不能用,不过,很快,我们会转入另一个更具挑战性的课题——多任务。
12.多任务
注:与上一篇类似,本节同样有参考《30天自制操作系统》,但不像上一节一样没有原创的东西(kmalloc 和 kfree 的代码在29.3节中有)。
多任务,顾名思义,就是多个任务同时进行。在计算机中,这是一个非常重要的概念,否则这篇教程甚至写不出来(我需要一边打字一边写代码,显然需要两个一块开)。当然在现实生活中,不推荐使用多任务。
理论上讲,只有一个 CPU 的时候,是没有办法多个任务“同时”进行的——因为一次只能有一段代码在 CPU 上跑。但正像O(1)不是立即完成,而是“常量时间”,多任务也不是同时进行,而是“交替进行”,只是这种交替间隔时间极短。
在 intel x86 cpu 中,任务切换的核心是任务状态段(TSS),这一部分完全是 intel 硬件提供的。由于 TSS 是一个段,在实际使用时,需要把这个段注册到 GDT 中。
由于效率较低,在 Linux 等更为现代的操作系统中已经废弃了这种方法,但初学而言,还是用原生自带的比较好。
TSS 总共有 16 位、32 位和 64 位三种版本,我们来看看 32 位版的 TSS 长什么样:
代码 12-1 TSS32(include/mtask.h)
#ifndef _MTASK_H_
#define _MTASK_H_
#include "common.h"
typedef struct TSS32 {
uint32_t backlink, esp0, ss0, esp1, ss1, esp2, ss2, cr3;
uint32_t eip, eflags, eax, ecx, edx, ebx, esp, ebp, esi, edi;
uint32_t es, cs, ss, ds, fs, gs;
uint32_t ldtr, iomap;
} tss32_t;
#endif
TSS32 结构体的第二、三行,是任务切换中会随时更改的寄存器。任务切换发生时,会把当时寄存器的值存入 TSS。
第一、四行与任务切换相关,暂且按下不表。ldtr 这个名字,联想 gdtr 和 idtr,相信各位读者能够推测出它表示什么,第20节我们再回来重翻旧案。
由于 TSS32 的结构与硬件强相关,显然我们不能用它来代表一个任务,不然想给任务加点什么额外的属性,硬件就要有意见了。所以我们在外面套一层封装,构成 TASK 结构体:
代码 12-2 表示任务的结构体(include/mtask.h)
typedef struct TASK {
uint32_t sel;
int32_t flags;
tss32_t tss;
} task_t;
目前,它只有两个属性:sel 和 flags。sel 代表它对应的 TSS 的选择子,flags 代表它的标志,如是否使用过、是否在运行等。
接下来,我们来实现一个控制任务的结构体。由于注册的任务和实际的任务可能不一致,这需要两个 task_t 数组,由于较为复杂,打包为一个结构体:
代码 12-3 任务控制结构体(include/mtask.h)
#define MAX_TASKS 1000
#define TASK_GDT0 3
typedef struct TASKCTL {
int running, now;
task_t *tasks[MAX_TASKS];
task_t tasks0[MAX_TASKS];
} taskctl_t;
running 和 now 代表正在运行的任务数量和当前运行的任务编号,tasks 是实际运行任务的数组,tasks0 是任务注册时进入的数组。这样一来,我们只需要一个 taskctl_t,就可以引用到所有这些控制任务的变量了。
TASK_GDT0 表示从第多少号 GDT 开始分配给 TSS 使用。
任务控制的声明部分暂告一段落,接下来是实际的控制代码。系好安全带,我们开始吧。
首先,是初始化多任务环境的函数 task_init。首先它会初始化 taskctl,在执行完后,当前执行流将被当成一个任务来对待,这样做的目的是方便管理。
代码 12-4 初始化多任务环境(kernel/mtask.c)
#include "mtask.h"
#include "gdtidt.h"
#include "memory.h"
#include "isr.h"
extern void load_tr(int);
extern void farjmp(int, int);
taskctl_t *taskctl;
task_t *task_init()
{
task_t *task;
taskctl = (taskctl_t *) kmalloc(sizeof(taskctl_t));
for (int i = 0; i < MAX_TASKS; i++) {
taskctl->tasks0[i].flags = 0;
taskctl->tasks0[i].sel = (TASK_GDT0 + i) * 8;
gdt_set_gate(TASK_GDT0 + i, (int) &taskctl->tasks0[i].tss, 103, 0x89); // 硬性规定,0x89 代表 TSS,103 是因为 TSS 共 26 个 uint32_t 组成,总计 104 字节,因规程减1变为103
}
task = task_alloc();
task->flags = 2;
taskctl->running = 1;
taskctl->now = 0;
taskctl->tasks[0] = task;
load_tr(task->sel); // 向CPU报告当前task->sel对应的任务为正在运行的任务
return task;
}
这之中最难懂的大概就是倒数第三行的 load_tr 了吧。调用 task_init 的应该是 kernel_main,而 kernel_main 此时还没有任务形态,需要用 load_tr 来使得 CPU 认识到这是正在运行的任务。
代码 12-5 load_tr(lib/nasmfunc.asm)
[global load_tr]
load_tr:
ltr [esp + 4]
ret
在这之中,用到了 task_alloc,它是分配一个任务用的函数。先从 tasks0 中找到空项,然后进行一些初始化工作,最后返回一个崭新的任务。
代码 12-6 分配任务用 task_alloc(kernel/mtask.c)
task_t *task_alloc()
{
task_t *task;
for (int i = 0; i < MAX_TASKS; i++) {
if (taskctl->tasks0[i].flags == 0) {
task = &taskctl->tasks0[i];
task->flags = 1;
task->tss.eflags = 0x00000202;
task->tss.eax = task->tss.ecx = task->tss.edx = task->tss.ebx = 0;
task->tss.ebp = task->tss.esi = task->tss.edi = 0;
task->tss.es = task->tss.ds = task->tss.fs = task->tss.gs = 0;
task->tss.ldtr = 0;
task->tss.iomap = 0x40000000;
return task;
}
}
return NULL;
}
eflags 的这个数值表示新任务默认开启中断。iomap 本意是让应用程序能够执行 in/out 指令所设置,但我们不需要让它执行这些指令,否则到时候执行个应用程序,键盘也不发信号了,时钟也不响了,就连电脑都重启了,所以把它设置成 0x40000000(事实上只要大于等于 103 就可以)表示:当作为应用程序时,不需要执行 in/out 指令。至于 CPU 怎么判断你是不是一个应用程序,第 22 节再说。
接下来是 task_run,使一个任务开始运行。实际上只是把这个任务加入了 tasks 数组而已。
代码 12-7 运行任务用 task_run(kernel/mtask.c)
void task_run(task_t *task)
{
task->flags = 2;
taskctl->tasks[taskctl->running] = task;
taskctl->running++;
}
接下来是 task_switch,真正执行任务切换的部分。不过,我们好像还没有具体讲究竟是怎么任务切换的,我们现在来简单说一下。
其实非常简单,只需要用 farjmp 就可以了。当执行一个远跳转(就是我们之前用过的 jmp xxx:xxx)时,CPU 会检查对应的段是否是代码段,如果不是,就退而求其次检查是不是 TSS。如果是 TSS,就会先把当前任务的全部寄存器存到它的 TSS 里,然后自动读取 TSS 中的全部寄存器,这之中包括下一步执行哪里的 eip,从而恢复断点,继续执行。
代码 12-8 farjmp(lib/nasmfunc.asm)
[global farjmp]
farjmp:
jmp far [esp + 4]
ret
在实际运用中,应在 C 中如此调用:farjmp(eip, cs)。eip 为下一步执行哪里的寄存器,如果跳的是 TSS,那就必须写 0;cs 为跳入的代码段选择子,在这里是 TSS。
为什么一定要这样呢?这和我们使用了 jmp far [addr] 来进行远跳转有关。你只需要知道,在这种情况下,[addr] 的位置必须写 EIP,[addr + 4] 的位置必须写 cs。
这样一来,task_switch 就十分简单了。
代码 12-9 任务切换(kernel/mtask.c)
void task_switch()
{
if (taskctl->running >= 2) { // 显然,至少得有两个任务才能切换
taskctl->now++; // 下一个任务
if (taskctl->now == taskctl->running) { // 到结尾了
taskctl->now = 0; // 转换为第一个
}
farjmp(0, taskctl->tasks[taskctl->now]->sel); // 跳入任务对应的 TSS
}
}
结合注释应该不难理解……我是第几次说这句话了?
最后是 task_now,返回当前任务,后续会频繁用到。
代码 12-10 返回当前任务(kernel/mtask.c)
task_t *task_now()
{
return taskctl->tasks[taskctl->now];
}
至此,我们已经基本完成了一个可用的任务处理框架。但是还有最后一个问题:谁来控制任务切换的进行呢?
还记得前面说的话吗?任务需要“交替运行”,也就是说,任务切换需要一段时间发生一次。我们发现,时钟中断刚好可以胜任!
因此,进入 timer.c,删除 tick 变量和所有对 tick 变量的操作,修改 timer_callback 如下:
代码 12-11 新版时钟中断回调(kernel/timer.c)
#include "mtask.h"
static void timer_callback(registers_t *regs)
{
task_switch(); // 每出现一次时钟中断,切换一次任务
}
首先,进入到 main.c,添加一个创建内核任务的函数。由于代码量大且(将会)频繁用到,做一个小小的封装。
代码 12-12 创建内核任务(kernel/main.c)
#include "mtask.h"
task_t *create_kernel_task(void *entry)
{
task_t *new_task;
new_task = task_alloc();
new_task->tss.esp = (uint32_t) kmalloc(64 * 1024) + 64 * 1024 - 4;
new_task->tss.eip = (int) entry;
new_task->tss.es = new_task->tss.ss = new_task->tss.ds = new_task->tss.fs = new_task->tss.gs = 2 * 8;
new_task->tss.cs = 1 * 8;
return new_task;
}
然后是新任务的主体 task_b_main,目前它还没啥大作用。
代码 12-13 新任务主体 task_b_main(kernel/main.c)
void task_b_main()
{
while (1) monitor_put('B'); // 重复打印B
}
最后是新版 kernel_main:
代码 12-14 最新内核主函数(kernel/main.c)
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear(); // 先清屏
init_gdtidt();
init_memory();
init_timer(100);
asm("sti");
task_t *task_a = task_init();
task_t *task_b = create_kernel_task(task_b_main);
task_run(task_b);
// 此时kernel_main已经成为task_a的一部分
while (1) monitor_put('A');
}
首先我们将时钟中断发生频率改为每0.1s发生一次,然后是创建、运行任务的代码,应该不难理解。
在 include/gdtidt.h 中加入一行声明:
代码 12-15 声明(include/gdtidt.h)
void gdt_set_gate(int32_t num, uint32_t base, uint32_t limit, uint16_t ar);
mtask.h 也要加入声明,全文如下:
代码 12-16 include/mtask.h
#ifndef _MTASK_H_
#define _MTASK_H_
#include "common.h"
typedef struct TSS32 {
uint32_t backlink, esp0, ss0, esp1, ss1, esp2, ss2, cr3;
uint32_t eip, eflags, eax, ecx, edx, ebx, esp, ebp, esi, edi;
uint32_t es, cs, ss, ds, fs, gs;
uint32_t ldtr, iomap;
} tss32_t;
typedef struct TASK {
uint32_t sel;
int32_t flags;
tss32_t tss;
} task_t;
#define MAX_TASKS 1000
#define TASK_GDT0 3
typedef struct TASKCTL {
int running, now;
task_t *tasks[MAX_TASKS];
task_t tasks0[MAX_TASKS];
} taskctl_t;
task_t *task_init();
task_t *task_alloc();
void task_run(task_t *task);
void task_switch();
task_t *task_now();
#endif
在所有声明添加完成后,编译运行,效果如图所示:

(图 12-1 运行成功)
我们看到了交错的 A 和 B,这是个好现象。那么我们的多任务到此结束……
……那是不可能的。我们还有一些内容没有完成。我们还要实现 Linux 中 exit 和 waitpid 的功能。这一部分地基打好了,我们后面的应用程序才能更好地运行起来。
那么,我们再次开始。首先,exit 是有返回值的,我们需要在某一个地方存一下返回值。思来想去,最合适的地方还是在 TASK 结构体中,在 mtask.h 中添加这样一个定义:
代码 12-17 新声明(include/mtask.h)
typedef struct exit_retval {
int pid, val;
} exit_retval_t;
typedef struct TASK {
uint32_t sel;
int32_t flags;
exit_retval_t my_retval;
tss32_t tss;
} task_t;
删去原本的 TASK 定义,替换为上面这一段。由于 exit 的返回值可以是任何一个东西,因此特意添加了一个 pid 变量,用来确认是否退出。当然这个变量可以换成随便一个东西,这里用 pid 只是一种用法。
那么,一个任务的 pid 是什么呢?pid 自然是一个 id,是一个任务的另一个身份证。一般而言,它是一个单独的数,表示它在一个任务数组或者什么地方的索引。
在这里,由于我们的全局数组是 taskctl->tasks0,因此,一个任务的 pid 就是它在 tasks0 中的索引。看起来从一个任务找 pid 是一个 O(n) 的操作,但是注意 task_init 中的这行代码:
taskctl->tasks0[i].sel = (TASK_GDT0 + i) * 8;
倒推回去,就可以得到:一个任务对应的 pid 为 task->sel / 8 - TASK_GDT0。这是一个重要的结论,我们把它写成单独的函数 task_pid:
代码 12-18 从任务找 pid(kernel/mtask.c)
int task_pid(task_t *task)
{
return task->sel / 8 - TASK_GDT0;
}
下面就是正式的 exit 代码了。exit 必然意味着一个任务执行的终止,这也就意味着它将会被从 tasks 删除,如果正在执行这个任务,那么还要进行切换。因此,我们先单独写一个 删除任务的函数 task_remove:
代码 12-19 从 tasks 中删除任务(kernel/mtask.c)
void task_remove(task_t *task)
{
bool need_switch = false; // 是否要进行切换?
int i;
if (task->flags == 2) { // 此任务正在运行,如果不运行那就根本不在tasks里,什么都不用干
if (task == task_now()) { // 是当前任务
need_switch = true; // 待会还得润
}
for (i = 0; i < taskctl->running; i++) {
if (taskctl->tasks[i] == task) break; // 在tasks中找到当前任务
}
taskctl->running--; // 运行任务数量减1
if (i < taskctl->now) taskctl->now--; // 如果now在这个任务的后面,那now也要前移一个(因为这个任务要删了,后面的要填上来,会整体前移一个)
for (; i < taskctl->running; i++) {
taskctl->tasks[i] = taskctl->tasks[i + 1]; // 整体前移,不必多说
}
if (need_switch) { // 需要切换
if (taskctl->now >= taskctl->running) {
taskctl->now = 0; // now超限,重置为0
}
farjmp(0, task_now()->sel); // 跳入到现在的当前任务中
}
}
}
task_remove 比较长,因此给了详尽的注释。基本上就是一堆善后工作需要做,核心部分只有中间的三行整体前移。
为什么添加了一个 need_switch 的变量呢?因为如果在最上面的 if 那就切换,那下面的整体前移就根本执行不到,这样就没有删除的作用了。
有了 task_remove,task_exit 就非常简单了:
代码 12-20 任务自动退出(kernel/mtask.c)
void task_exit(int value)
{
task_t *cur = task_now(); // 当前任务
cur->my_retval.pid = task_pid(cur); // pid变为当前任务的pid
cur->my_retval.val = value; // val为此时的值
task_remove(cur); // 删除当前任务
cur->flags = 4; // 返回值还没人收,暂时还不能释放这个块为可用(0)
}
接下来是 task_wait,等待指定 pid 的进程执行 exit 退出。
代码 12-21 等待任务退出(kernel/mtask.c)
int task_wait(int pid)
{
task_t *task = &taskctl->tasks0[pid]; // 找出对应的task
while (task->my_retval.pid == -1); // 若没有返回值就一直等着
task->flags = 0; // 释放为可用
return task->my_retval.val; // 拿到返回值
}
注意,由于此处是判断 pid 是否为 -1 来判断任务是否为退出,应当在初始化任务的时候(即 task_alloc 中)加上对 pid 的设定如下:
代码 12-22 初始化 my_retval(kernel/mtask.c)
task->tss.iomap = 0x40000000;
task->my_retval.pid = -1; // 这里是新增的部分
task->my_retval.val = -114514; // 这里是新增的部分
return task;
请自行在 mtask.h 中添加 task_pid、task_exit 和 task_wait 的声明。
接下来是测试用例,直接把完整版 main.c 端上来:
代码 12-23 测试用例(kernel/main.c)
#include "monitor.h"
#include "gdtidt.h"
#include "isr.h"
#include "timer.h"
#include "memory.h"
#include "mtask.h"
task_t *create_kernel_task(void *entry)
{
task_t *new_task;
new_task = task_alloc();
new_task->tss.esp = (uint32_t) kmalloc(64 * 1024) + 64 * 1024 - 4;
new_task->tss.eip = (int) entry;
new_task->tss.es = new_task->tss.ss = new_task->tss.ds = new_task->tss.fs = new_task->tss.gs = 2 * 8;
new_task->tss.cs = 1 * 8;
return new_task;
}
void task_b_main()
{
monitor_write("Waiting for task_a to dead...\n");
int retval = task_wait(0); // kernel_main
monitor_write("R.I.P. task_a, retval: ");
monitor_write_hex(retval);
monitor_write("\nWaiting for 10 seconds (roughly)...\n");
for (int i = 0; i < 10000000; i++) for (int j = 0; j < 20; j++);
task_exit(114514);
}
void task_c_main()
{
monitor_write("Waiting for task_b to dead...\n");
int retval = task_wait(1); // task_b
monitor_write("R.I.P. task_b, retval: ");
monitor_write_dec(retval);
monitor_write("\nThey're all dead, I must live!!!");
while (1);
}
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear();
init_gdtidt();
init_memory();
init_timer(100);
asm("sti");
task_t *task_a = task_init(); // task_a: pid 0
task_t *task_b = create_kernel_task(task_b_main); // task_b: pid 1
task_t *task_c = create_kernel_task(task_c_main); // task_c: pid 2
task_run(task_b);
task_run(task_c);
monitor_write("Waiting for 10 seconds (roughly)...\n");
for (int i = 0; i < 10000000; i++) for (int j = 0; j < 20; j++);
// 悬停
task_exit(0xDEADBEEF); // 再见……
}
编译,运行,等待约半分钟后,效果如下:

(图 12-2 成功)
好了,多任务到此为止已经可以结束了。下面我们来加速冲刺,进入到人机交互的第一个里程碑——键盘驱动。
13.终于可以打字了——键盘驱动(上)
如果没有键盘,这篇文章大概是写不出来的,由此就可以看出键盘对于人机交互的重要影响。
首先是一个好消息,键盘在 PIC 里是有外设编号的(希望大家还记得 PIC,否则建议复习第10节),按我们的设定,编号为 33。并不是所有的外设都在 PIC 里自带编号,像网卡啊、声卡这些,都是没有自带编号的。
那么既然如此,新建 drivers/keyboard.c,我们来写一个最简单的键盘驱动:
代码 13-1 最简单的键盘驱动(drivers/keyboard.c)
#include "isr.h"
#include "keyboard.h"
void keyboard_handler(registers_t *regs)
{
monitor_write("*");
}
void init_keyboard()
{
register_interrupt_handler(IRQ1, keyboard_handler);
}
代码 13-2 声明(include/keyboard.h)
#ifndef _KEYBOARD_H_
#define _KEYBOARD_H_
void init_keyboard();
#endif
添加了新目录,照例放一下 Makefile:
代码 13-3 如今的 Makefile(Makefile)
OBJS = out/kernel.o out/common.o out/monitor.o out/main.o out/gdtidt.o out/nasmfunc.o out/isr.o out/interrupt.o \
out/string.o out/timer.o out/memory.o out/mtask.o out/keyboard.o
out/%.o : kernel/%.c
i686-elf-gcc -c -I include -O0 -fno-builtin -fno-stack-protector -o out/$*.o kernel/$*.c
out/%.o : kernel/%.asm
nasm -f elf -o out/$*.o kernel/$*.asm
out/%.o : lib/%.c
i686-elf-gcc -c -I include -O0 -fno-builtin -fno-stack-protector -o out/$*.o lib/$*.c
out/%.o : lib/%.asm
nasm -f elf -o out/$*.o lib/$*.asm
out/%.o : drivers/%.c
i686-elf-gcc -c -I include -O0 -fno-builtin -fno-stack-protector -o out/$*.o drivers/$*.c
out/%.o : drivers/%.asm
nasm -f elf -o out/$*.o drivers/$*.asm
out/%.bin : boot/%.asm
nasm -I boot/include -o out/$*.bin boot/$*.asm
out/kernel.bin : $(OBJS)
i686-elf-ld -s -Ttext 0x100000 -o out/kernel.bin $(OBJS)
a.img : out/boot.bin out/loader.bin out/kernel.bin
dd if=out/boot.bin of=a.img bs=512 count=1
edimg imgin:a.img copy from:out/loader.bin to:@: copy from:out/kernel.bin to:@: imgout:a.img
run : a.img
qemu-system-i386 -fda a.img
编译,运行,效果如下两图:

(图 13-1 按下第一个按键前)

(图 13-2 按下第一个按键后)
按下第一个按键后,出现了一个 *,这是非常好的现象。但是,我们发现,后续无论再怎么按键,都完全没有任何作用,屏幕上不再有新的星号出现。
这是为什么呢?查阅资料我们发现,这是键盘控制器(8042、8048)干的好事。当按键被按下时,键盘处理器将根据对应的键产生一个或多个对应的代码,我们称之为扫描码,这个或这些扫描码随即被依次写入到键盘控制器自带的缓冲区中。在写入完后,键盘控制器会立即发送一个中断信号。然而,如果内核在收到中断后不读出这个缓冲区里的扫描码,键盘就会卡死。
键盘控制器的缓冲区端口号为 0x60,我们只需要用 inb(0x60) 就可以读出键盘缓冲区中的扫描码。因此,修改 keyboard_handler,我们来看看读出的扫描码长什么样:
代码 13-4 新版键盘驱动(drivers/keyboard.c)
#include "isr.h"
#include "keyboard.h"
void keyboard_handler(registers_t *regs)
{
monitor_write_hex(inb(0x60)); // 打印读出的扫描码
}
void init_keyboard()
{
register_interrupt_handler(IRQ1, keyboard_handler);
}
编译,运行,等待约半分钟后,效果如下:

(图 13-3 运行效果)
在本图中,依次按下了shift、a、a、shift、a、lctrl、lctrl、alt、win这几个键。我们发现,虽然一共只按了9个键,但产生了20个扫描码。这是因为,扫描码不是单独出现,而是成对出现的,按下时产生一组,松开时产生一组。
那么,我们怎么知道每个按键对应的是哪个扫描码呢?一个可实践的方法是,按照上面的顺序依次分别按下,观察屏幕上扫描码的变化。不过,这对写代码解析扫描码是没有帮助的。
还有另外一个办法,就是依次按下键盘上的每一个键,看看它对应的扫描码,然后记录到一个数组或者其他什么地方。不过,这样做实在太过耗时,前人栽树,后人乘凉,我们选择直接把这个数组抄下来:
代码 13-5 从扫描码到每一个键的对应关系(drivers/keymap.c)
#include "keyboard.h"
#include "common.h"
uint32_t keymap[NR_SCAN_CODES * MAP_COLS] = {
0, 0, 0,
ESC, ESC, 0,
'1', '!', 0,
'2', '@', 0,
'3', '#', 0,
'4', '$', 0,
'5', '%', 0,
'6', '^', 0,
'7', '&', 0,
'8', '*', 0,
'9', '(', 0,
'0', ')', 0,
'-', '_', 0,
'=', '+', 0,
BACKSPACE, BACKSPACE, 0,
TAB, TAB, 0,
'q', 'Q', 0,
'w', 'W', 0,
'e', 'E', 0,
'r', 'R', 0,
't', 'T', 0,
'y', 'Y', 0,
'u', 'U', 0,
'i', 'I', 0,
'o', 'O', 0,
'p', 'P', 0,
'[', '{', 0,
']', '}', 0,
ENTER, ENTER, PAD_ENTER,
CTRL_L, CTRL_L, CTRL_R,
'a', 'A', 0,
's', 'S', 0,
'd', 'D', 0,
'f', 'F', 0,
'g', 'G', 0,
'h', 'H', 0,
'j', 'J', 0,
'k', 'K', 0,
'l', 'L', 0,
';', ':', 0,
'\'', '"', 0,
'`', '~', 0,
SHIFT_L, SHIFT_L, 0,
'\\', '|', 0,
'z', 'Z', 0,
'x', 'X', 0,
'c', 'C', 0,
'v', 'V', 0,
'b', 'B', 0,
'n', 'N', 0,
'm', 'M', 0,
',', '<', 0,
'.', '>', 0,
'/', '?', PAD_SLASH,
SHIFT_R, SHIFT_R, 0,
'*', '*', 0,
ALT_L, ALT_L, ALT_R,
' ', ' ', 0,
CAPS_LOCK, CAPS_LOCK, 0,
F1, F1, 0,
F2, F2, 0,
F3, F3, 0,
F4, F4, 0,
F5, F5, 0,
F6, F6, 0,
F7, F7, 0,
F8, F8, 0,
F9, F9, 0,
F10, F10, 0,
NUM_LOCK, NUM_LOCK, 0,
SCROLL_LOCK, SCROLL_LOCK, 0,
PAD_HOME, '7', HOME,
PAD_UP, '8', UP,
PAD_PAGEUP, '9', PAGEUP,
PAD_MINUS, '-', 0,
PAD_LEFT, '4', LEFT,
PAD_MID, '5', 0,
PAD_RIGHT, '6', RIGHT,
PAD_PLUS, '+', 0,
PAD_END, '1', END,
PAD_DOWN, '2', DOWN,
PAD_PAGEDOWN, '3', PAGEDOWN,
PAD_INS, '0', INSERT,
PAD_DOT, '.', DELETE,
0, 0, 0,
0, 0, 0,
0, 0, 0,
F11, F11, 0,
F12, F12, 0,
0, 0, 0,
0, 0, 0,
0, 0, GUI_L,
0, 0, GUI_R,
0, 0, APPS,
0, 0, 0
};
keymap 数组中的第一列代表正常按下对应的键,第二列代表按 shift 时对应的键,第三列代表同样的扫描码前面跟着 0xE0 时候对应的键。后续的解析中,这一段是有大用处的。
这一段数组中出现了非常多的宏,诸如 NR_SCAN_CODES、MAP_COLS、ESC 等等。数组中的宏是每一个键的唯一标识,在保证唯一性的情况下,读者可以任意指定;而剩下的 NR_SCAN_CODES 和 MAP_COLS 则分别为 0x7f 和 3。需要注意的是,keymap 里的索引是按下时的扫描码,而非抬起时的扫描码,实际编程时需要留意一下。
在本教程中使用的一个 keyboard.h 的示例如下:
代码 13-6 各种宏的统一声明(include/keyboard.h)
#ifndef _KEYBOARD_H_
#define _KEYBOARD_H_
void init_keyboard();
#define NR_SCAN_CODES 0x80
#define MAP_COLS 3
#define FLAG_BREAK 0x0080
#define FLAG_EXT 0x0100
#define FLAG_SHIFT_L 0x0200
#define FLAG_SHIFT_R 0x0400
#define FLAG_CTRL_L 0x0800
#define FLAG_CTRL_R 0x1000
#define FLAG_ALT_L 0x2000
#define FLAG_ALT_R 0x4000
#define FLAG_PAD 0x8000
#define MASK_RAW 0x1ff
#define ESC (0x01 + FLAG_EXT)
#define TAB (0x02 + FLAG_EXT)
#define ENTER (0x03 + FLAG_EXT)
#define BACKSPACE (0x04 + FLAG_EXT)
#define GUI_L (0x05 + FLAG_EXT)
#define GUI_R (0x06 + FLAG_EXT)
#define APPS (0x07 + FLAG_EXT)
#define SHIFT_L (0x08 + FLAG_EXT)
#define SHIFT_R (0x09 + FLAG_EXT)
#define CTRL_L (0x0A + FLAG_EXT)
#define CTRL_R (0x0B + FLAG_EXT)
#define ALT_L (0x0C + FLAG_EXT)
#define ALT_R (0x0D + FLAG_EXT)
#define CAPS_LOCK (0x0E + FLAG_EXT)
#define NUM_LOCK (0x0F + FLAG_EXT)
#define SCROLL_LOCK (0x10 + FLAG_EXT)
#define F1 (0x11 + FLAG_EXT)
#define F2 (0x12 + FLAG_EXT)
#define F3 (0x13 + FLAG_EXT)
#define F4 (0x14 + FLAG_EXT)
#define F5 (0x15 + FLAG_EXT)
#define F6 (0x16 + FLAG_EXT)
#define F7 (0x17 + FLAG_EXT)
#define F8 (0x18 + FLAG_EXT)
#define F9 (0x19 + FLAG_EXT)
#define F10 (0x1A + FLAG_EXT)
#define F11 (0x1B + FLAG_EXT)
#define F12 (0x1C + FLAG_EXT)
#define PRINTSCREEN (0x1D + FLAG_EXT)
#define PAUSEBREAK (0x1E + FLAG_EXT)
#define INSERT (0x1F + FLAG_EXT)
#define DELETE (0x20 + FLAG_EXT)
#define HOME (0x21 + FLAG_EXT)
#define END (0x22 + FLAG_EXT)
#define PAGEUP (0x23 + FLAG_EXT)
#define PAGEDOWN (0x24 + FLAG_EXT)
#define UP (0x25 + FLAG_EXT)
#define DOWN (0x26 + FLAG_EXT)
#define LEFT (0x27 + FLAG_EXT)
#define RIGHT (0x28 + FLAG_EXT)
#define POWER (0x29 + FLAG_EXT)
#define SLEEP (0x2A + FLAG_EXT)
#define WAKE (0x2B + FLAG_EXT)
#define PAD_SLASH (0x2C + FLAG_EXT)
#define PAD_STAR (0x2D + FLAG_EXT)
#define PAD_MINUS (0x2E + FLAG_EXT)
#define PAD_PLUS (0x2F + FLAG_EXT)
#define PAD_ENTER (0x30 + FLAG_EXT)
#define PAD_DOT (0x31 + FLAG_EXT)
#define PAD_0 (0x32 + FLAG_EXT)
#define PAD_1 (0x33 + FLAG_EXT)
#define PAD_2 (0x34 + FLAG_EXT)
#define PAD_3 (0x35 + FLAG_EXT)
#define PAD_4 (0x36 + FLAG_EXT)
#define PAD_5 (0x37 + FLAG_EXT)
#define PAD_6 (0x38 + FLAG_EXT)
#define PAD_7 (0x39 + FLAG_EXT)
#define PAD_8 (0x3A + FLAG_EXT)
#define PAD_9 (0x3B + FLAG_EXT)
#define PAD_UP PAD_8
#define PAD_DOWN PAD_2
#define PAD_LEFT PAD_4
#define PAD_RIGHT PAD_6
#define PAD_HOME PAD_7
#define PAD_END PAD_1
#define PAD_PAGEUP PAD_9
#define PAD_PAGEDOWN PAD_3
#define PAD_INS PAD_0
#define PAD_MID PAD_5
#define PAD_DEL PAD_DOT
#define KB_DATA 0x60
#define KB_CMD 0x64
#define LED_CODE 0xED
#define KB_ACK 0xFA
#endif
这里给所有在 keymap 数组中用到的宏统一加了 FLAG_EXT,这是为了后期处理时可以分辨可打印的字符对应的键(如asdf)与不可打印的字符对应的键(如F11、F12)。
在 Makefile 的 OBJS 中追加一个 keymap.o,由于我们尚未开始解析扫描码,所以这一部分没有变化。
接下来,为了存储获得到的扫描码,我们来做一个存储扫描码用的数据结构。显然,先按下的键需要先被处理,所以我们选择做一个队列。
基本数据结构相关的代码就不解说了,下面是一个没那么经典的环形队列的实现:
代码 13-7 FIFO队列的实现(lib/fifo.c)
#include "fifo.h"
void fifo_init(fifo_t *fifo, int size, uint32_t *buf)
{
fifo->size = size;
fifo->buf = buf;
fifo->free = size;
fifo->flags = 0;
fifo->p = 0;
fifo->q = 0;
}
int fifo_put(fifo_t *fifo, uint32_t data)
{
if (fifo->free == 0) {
fifo->flags |= FIFO_FLAGS_OVERRUN;
return -1;
}
fifo->buf[fifo->p] = data;
fifo->p++;
if (fifo->p == fifo->size) fifo->p = 0;
fifo->free--;
return 0;
}
int fifo_get(fifo_t *fifo)
{
int data;
if (fifo->free == fifo->size) return -1;
data = fifo->buf[fifo->q];
fifo->q++;
if (fifo->q == fifo->size) fifo->q = 0;
fifo->free++;
return data;
}
int fifo_status(fifo_t *fifo)
{
return fifo->size - fifo->free;
}
代码 13-8 声明(include/fifo.h)
#ifndef _FIFO_H_
#define _FIFO_H_
#include "common.h"
typedef struct FIFO {
uint32_t *buf;
int p, q, size, free, flags;
} fifo_t;
#define FIFO_FLAGS_OVERRUN 1
void fifo_init(fifo_t *fifo, int size, uint32_t *buf);
int fifo_put(fifo_t *fifo, uint32_t data);
int fifo_get(fifo_t *fifo);
int fifo_status(fifo_t *fifo);
#endif
在 Makefile 的 OBJS 中追加 out/fifo.o,编译运行,效果仍应不变,因为这个队列我们也还没开始用。
具体实践中如何使用这样一个队列呢?我们先来到 keyboard.c,创建一个存储扫描码用的 keyfifo:
代码 13-9 创建 keyfifo(drivers/keyboard.c)
#include "isr.h"
#include "keyboard.h"
#include "fifo.h"
fifo_t keyfifo;
uint32_t keybuf[32];
extern uint32_t keymap[];
void keyboard_handler(registers_t *regs)
{
monitor_write_hex(inb(0x60));
}
void init_keyboard()
{
fifo_init(&keyfifo, 32, keybuf);
register_interrupt_handler(IRQ1, keyboard_handler);
}
然后在 keyboard_handler 中,我们存储扫描码到 keyfifo:
代码 13-10 存入扫描码(drivers/keyboard.c)
static uint8_t get_scancode()
{
uint8_t scancode;
asm("cli");
scancode = fifo_get(&keyfifo);
asm("sti");
return scancode;
}
static void keyboard_read()
{
if (fifo_status(&keyfifo) > 0) {
uint8_t scancode = get_scancode();
monitor_write_hex(scancode);
}
}
void keyboard_handler(registers_t *regs)
{
fifo_put(&keyfifo, inb(KB_DATA));
keyboard_read();
}
我们同时还新建了 keyboard_read 和 get_scancode 两个函数,未来我们对键盘数据的处理将主要在 keyboard_read 当中进行。
编译,运行,效果仍应不变,因为我们还没有开始处理扫描码。事不过三,我们马上就开始处理工作。
代码 13-11 初步处理扫描码(drivers/keyboard.c)
static void keyboard_read()
{
uint8_t scancode;
int make;
if (fifo_status(&keyfifo) > 0) {
scancode = get_scancode();
if (scancode == 0xE1) {
// 特殊开头,暂不做处理
} else if (scancode == 0xE0) {
// 特殊开头,暂不做处理
} else {
make = (scancode & FLAG_BREAK ? true : false);
if (make) {
char key = keymap[(scancode & 0x7f) * MAP_COLS];
monitor_put(key);
}
}
}
}
FLAG_BREAK 在之前的 keyboard.h 中已有定义,是 0x80。多启动几次按几个键会发现,除了一部分产生多个扫描码的键以外,每次按下的扫描码比抬起的扫描码少 0x80。因此只需要探测 0x80 是否存在,就可以确定现在的这个键是被按下还是被抬起,选择一个处理即可。
这就是 else 中第一行的作用,这里选择的是被抬起时进行判断。scancode & 0x7f 可以取得对应的被按下时的扫描码,从而作为 keymap 的索引获得对应的键。
好了,现在编译运行,等待 task_c 输出完成后,输入 abc123,效果如下:

(图 13-4 成功输出)
我们看到了后面的 abc123,说明我们的键盘驱动已经初步完成。本节的篇幅已经够长了,下一节我们将继续写键盘驱动,做出一个基本的处理框架。
14.终于可以打字了——键盘驱动(下)
欢迎回来,我们继续键盘驱动的旅途。
首先,是三个最基本的东西:shift、alt 和 ctrl。这三个东西我们完全没有处理,特别是 shift,导致我们现在任何一个大写字母都打不出来。
修改一下 keyboard.c,先在最开头写下这几个全局变量,记录 shift、alt、ctrl 的状态:
代码 14-1 shift、alt、ctrl 的状态(drivers/keyboard.c)
static int code_with_E0 = 0;
static int shift_l;
static int shift_r;
static int alt_l;
static int alt_r;
static int ctrl_l;
static int ctrl_r;
static int caps_lock;
static int num_lock;
static int scroll_lock;
static int column;
然后是现在的 keyboard_read:
代码 14-2 带 shift 的扫描码解析(drivers/keyboard.c)
static void keyboard_read()
{
uint8_t scancode;
int make;
uint32_t key = 0;
uint32_t *keyrow;
if (fifo_status(&keyfifo) > 0) {
scancode = get_scancode();
if (scancode == 0xE1) {
// 特殊开头,暂不做处理
} else if (scancode == 0xE0) {
code_with_E0 = 1;
} else {
make = scancode & FLAG_BREAK ? false : true;
keyrow = &keymap[(scancode & 0x7f) * MAP_COLS];
column = 0;
if (shift_l || shift_r) {
column = 1;
}
if (code_with_E0) {
column = 2;
code_with_E0 = 0;
}
key = keyrow[column];
switch (key) {
case SHIFT_L:
shift_l = make;
key = 0;
break;
case SHIFT_R:
shift_r = make;
key = 0;
break;
case CTRL_L:
ctrl_l = make;
key = 0;
break;
case CTRL_R:
ctrl_r = make;
key = 0;
break;
case ALT_L:
alt_l = make;
key = 0;
break;
case ALT_R:
alt_r = make;
key = 0;
break;
default:
if (!make) key = 0;
break;
}
if (key) monitor_put(key);
}
}
}
在实现 shift 的同时,我们过滤了 ctrl 和 alt,判断是否释放也改为了判断是否按下,同时会在适当的时候忽略 key 的值。
编译,运行,按下 shift 和不按 shift 分别输入 abc123,效果如图所示:

(图 14-1 实现 shift)
现在的 keyboard_read 对按键的处理仅限于打印,为了匹配以后更加复杂的需求,我们单独创建一个 in_process 用来处理不同的按键。
把 if (key) monitor_put(key) 替换为:
代码 14-3 对按键进行编码(drivers/keyboard.c)
if (make) {
key |= shift_l ? FLAG_SHIFT_L : 0;
key |= shift_r ? FLAG_SHIFT_R : 0;
key |= alt_l ? FLAG_ALT_L : 0;
key |= alt_r ? FLAG_ALT_R : 0;
key |= ctrl_l ? FLAG_CTRL_L : 0;
key |= ctrl_r ? FLAG_CTRL_R : 0;
in_process(key);
}
这里相当于对 key 进行了编码,同时将当时所有的按键状态编码了进去。
然后是 in_process,把它放在 keyboard_read 之前。
代码 14-4 in_process(drivers/keyboard.c)
static void in_process(uint32_t key)
{
if (!(key & FLAG_EXT)) {
monitor_put(key & 0xFF);
}
}
编译,运行,效果仍应如图 14-1所示。
下面是对回车、退格和 tab 行为的单独处理,我们只需要找出 ENTER、 BACKSPACE 以及 TAB,改为打印 \n、 \b 以及 \t。
代码 14-5 回车、退格与 TAB(drivers/keyboard.c)
static void in_process(uint32_t key)
{
if (!(key & FLAG_EXT)) {
monitor_put(key & 0xFF);
} else {
int raw_key = key & MASK_RAW;
switch (raw_key) {
case ENTER:
monitor_put('\n');
break;
case BACKSPACE:
monitor_put('\b');
break;
case TAB:
monitor_put('\t');
break;
}
}
}
编译,运行,待 task_c 输出后连按数次退格,效果如下:

(图 14-2 BACKSPACE 的异常)
我们发现,光标虽然成功后移,但字符都还在。这是在 monitor_put 中对 \b 的判断中应当处理的,找到 monitor_put 中的第一个判断,我们来做一个专项修改:
代码 14-6 对退格键的修改(kernel/monitor.c)
if (c == 0x08 && cursor_x) // 退格,且光标不在某行开始处
{
cursor_x--; // 直接把光标向后移一格
video_memory[cursor_y * 80 + cursor_x] = 0x20 | (attributeByte << 8); // 空格
}
再次编译,运行,待 task_c 输出信息后,按若干次退格并按下 \n、\t,效果如下:

(图 14-3 成功删除字符)
由此即可证明,对这三个键的处理可以暂告一段落。乘胜追击,我们来处理键盘上有指示灯的三个键:CapsLock、NumLock 和 ScrollLock(什么?Fn?这玩意真的在 PS/2 键盘上?)。
对键盘指示灯的操控需要借助我们之前遇到的 0x60 端口,也要借助键盘控制器的另一个端口——0x64。
如何设置键盘指示灯的情况呢?非常简单,大致分为如下几步:
-
读出控制器端口
0x64对应的数据,观察其从低往高第2位是否为 0,若为 0,代表当前可向0x60端口发送命令; -
向
0x60端口发出命令0xED,意为设置键盘 LED 灯状态。键盘控制器收到命令后,会在0x60端口发送一个0xFA,我们需要等待这个0xFA返回。 -
向
0x60端口发出希望设置的键盘 LED 灯状态,它应被编码为一个字节,高5位均为0,从低往高数第1、2、3位分别为ScrollLock、NumLock和CapsLock,其中每一位的 0 为熄灭,1 为亮起。 -
键盘设置完 LED 灯状态后,会再次发送一个
0xFA需要我们读出。
好了,在我们前面设置 shift、ctrl 和 alt 状态的时候已经增加了这三个 lock 指示灯的变量,我们来针对上面的四步分别写程序。
首先,我们来创建一个设置 LED 灯状态的函数,实际使用时只需要往 caps_lock、num_lock 和 scroll_lock 三个变量中写指示灯状态即可(请把它们放在 get_scancode 之前)。
代码 14-7 设置 LED 状态(drivers/keyboard.c)
static void kb_wait()
{
uint8_t kb_stat;
do {
kb_stat = inb(KB_CMD); // KB_CMD: 0x64
} while (kb_stat & 0x02);
}
static void kb_ack()
{
uint8_t kb_data;
do {
kb_data = inb(KB_DATA); // KB_DATA: 0x60
} while (kb_data != KB_ACK); // KB_ACK: 0xFA
}
static void set_leds()
{
uint8_t led_status = (caps_lock << 2) | (num_lock << 1) | scroll_lock;
kb_wait();
outb(KB_DATA, LED_CODE); // LED_CODE: 0xED
kb_ack();
kb_wait();
outb(KB_DATA, led_status);
kb_ack();
}
其中的 KB_CMD、KB_DATA、KB_ACK 以及 LED_CODE 已经定义在 keyboard.h 之中了。
接下来我们对 init_keyboard 略作修改,初始化 LED 灯的状态。
代码 14-8 新版 init_keyboard(drivers/keyboard.c)
void init_keyboard()
{
fifo_init(&keyfifo, 32, keybuf);
shift_l = shift_r = 0;
alt_l = alt_r = 0;
ctrl_l = ctrl_r = 0;
caps_lock = 0;
num_lock = 1;
scroll_lock = 0;
set_leds();
register_interrupt_handler(IRQ1, keyboard_handler);
}
之所以设置 num_lock 为 1,是因为小键盘的数字功能一般比方向功能常用。不过,设置了也还没有用,我们紧接着对 caps_lock 和 num_lock 的状态作出判断。
我们首先添加当按下这三个键时更改状态和 LED 灯状态的处理,然后是添加了 CapsLock 按下时的实际功能。
代码 14-9 LED 灯状态的变换以及 CapsLock 的实际功能(drivers/keyboard.c)
static void keyboard_read()
{
uint8_t scancode;
int make;
uint32_t key = 0;
uint32_t *keyrow;
if (fifo_status(&keyfifo) > 0) {
scancode = get_scancode();
if (scancode == 0xE1) {
// 特殊开头,暂不做处理
} else if (scancode == 0xE0) {
code_with_E0 = 1;
} else {
make = scancode & FLAG_BREAK ? false : true;
keyrow = &keymap[(scancode & 0x7f) * MAP_COLS];
column = 0;
int caps = shift_l || shift_r;
if (caps_lock) {
if ((keyrow[0] >= 'a') && (keyrow[0] <= 'z')) caps = !caps;
}
if (caps) {
column = 1;
}
if (code_with_E0) {
column = 2;
code_with_E0 = 0;
}
key = keyrow[column];
switch (key) {
case SHIFT_L:
shift_l = make;
break;
case SHIFT_R:
shift_r = make;
break;
case CTRL_L:
ctrl_l = make;
break;
case CTRL_R:
ctrl_r = make;
break;
case ALT_L:
alt_l = make;
break;
case ALT_R:
alt_r = make;
break;
case CAPS_LOCK:
if (make) {
caps_lock = !caps_lock;
set_leds();
}
break;
case NUM_LOCK:
if (make) {
num_lock = !num_lock;
set_leds();
}
break;
case SCROLL_LOCK:
if (make) {
scroll_lock = !scroll_lock;
set_leds();
}
break;
default:
break;
}
if (make) {
key |= shift_l ? FLAG_SHIFT_L : 0;
key |= shift_r ? FLAG_SHIFT_R : 0;
key |= alt_l ? FLAG_ALT_L : 0;
key |= alt_r ? FLAG_ALT_R : 0;
key |= ctrl_l ? FLAG_CTRL_L : 0;
key |= ctrl_r ? FLAG_CTRL_R : 0;
in_process(key);
}
}
}
}
这里实际的代码增加的不多,主要是大的 switch-case 增加了几个 lock 键,以及 code_with_E0 上面几行对 caps_lock 状态的处理。
编译,运行,等待 task_c 输出完成后,依次按下:
ENTER、CapsLock、a、b、c、1、2、3、CapsLock、a、b、c、1、2、3、CapsLock、Shift+A、A,
效果如下:

(图 14-4 CapsLock 的实际效果)
最后,是对 NumLock 的处理,请用下面这一长串替换掉 keyboard_read 中 if (make) 的分支:
代码 14-10 NumLock(drivers/keyboard.c)
if (make) {
int pad = 0;
if ((key >= PAD_SLASH) && (key <= PAD_9)) {
pad = 1;
switch (key) {
case PAD_SLASH:
key = '/';
break;
case PAD_STAR:
key = '*';
break;
case PAD_MINUS:
key = '-';
break;
case PAD_PLUS:
key = '+';
break;
case PAD_ENTER:
key = ENTER;
break;
default:
if (num_lock && (key >= PAD_0) && (key <= PAD_9)) {
key = key - PAD_0 + '0';
} else if (num_lock && (key == PAD_DOT)) {
key = '.';
} else {
switch (key) {
case PAD_HOME:
key = HOME;
break;
case PAD_END:
key = END;
break;
case PAD_PAGEUP:
key = PAGEUP;
break;
case PAD_PAGEDOWN:
key = PAD_PAGEDOWN;
break;
case PAD_INS:
key = INSERT;
break;
case PAD_UP:
key = UP;
break;
case PAD_DOWN:
key = DOWN;
break;
case PAD_LEFT:
key = LEFT;
break;
case PAD_RIGHT:
key = RIGHT;
break;
case PAD_DOT:
key = DELETE;
break;
default:
break;
}
}
break;
}
}
key |= shift_l ? FLAG_SHIFT_L : 0;
key |= shift_r ? FLAG_SHIFT_R : 0;
key |= ctrl_l ? FLAG_CTRL_L : 0;
key |= ctrl_r ? FLAG_CTRL_R : 0;
key |= alt_l ? FLAG_ALT_L : 0;
key |= alt_r ? FLAG_ALT_R : 0;
key |= pad ? FLAG_PAD : 0;
in_process(key);
}
这一部分的算法其实仍旧是简单的枚举。枚举每一个键,看它是不是在小键盘上,有的键不受 NumLock 控制,因此可以不管;有的键受 NumLock 控制,所以根据 NumLock 是否亮起判断到底是原本的键还是要转换一下。
编译,运行,依次按下小键盘上的:
Enter、7、8、9、4、5、6、1、2、3、+、-、*、/、.、Enter、Enter、0、0、0、0、0、0、0、0、Enter、Enter,
然后是不在小键盘上的上下左右方向键,按下 Enter,再按下不在小键盘上的上下左右方向键,效果如下:

(图 14-5 NumLock 的实际效果)
前面小键盘的测试部分倒是符合预期,但是为什么上下左右方向键会输出一个 8 呢(有的机型甚至会输出 8246)?
通过回到第 13 节开篇的状态打印扫描码我们发现,原来是 qemu 对 PS/2 键盘的模拟出了点故障,将 0xE0 这一本该放在前面的字节放在了后面,导致我们的键盘驱动先接收到要打印小键盘的 8(没错,方向键和小键盘上的键扫描码相同,只是后面跟了个 0xE0),然后接收到 0xE0,0xE0 就被后续的方向键所匹配了(有的甚至都匹配不上)。对此我们有几个解决方案:要么干脆摆烂直接不管,要么做一个补丁。
但是,经过进一步的测试,我们发现不同版本的 QEMU 有不同的模拟逻辑,有的 QEMU 甚至直接不区分方向键和小键盘的方向键,那这个补丁自然没法打,所以就此开摆!
最后,我们把 in_process 中的打印字符改为向特定的 FIFO 中放入字符,由 kernel_main 或者别的什么地方从这里面读取。
代码 14-11 in_process 最终版(drivers/keyboard.c)
static void in_process(uint32_t key)
{
if (!(key & FLAG_EXT)) {
fifo_put(&decoded_key, key & 0xFF);
} else {
int raw_key = key & MASK_RAW;
switch (raw_key) {
case ENTER:
fifo_put(&decoded_key, '\n');
break;
case BACKSPACE:
fifo_put(&decoded_key, '\b');
break;
case TAB:
fifo_put(&decoded_key, '\t');
break;
}
}
}
在文件开头添加两行 fifo_t decoded_key; 以及 uint32_t dkey_buf[32];,在 init_keyboard 中加入一行 fifo_init(&decoded_key, 32, dkey_buf);,我们的键盘驱动就此完结。
最新版的测试用 main.c 完整版如下:
代码 14-12 键盘驱动最终测试(kernel/main.c)
#include "monitor.h"
#include "gdtidt.h"
#include "isr.h"
#include "timer.h"
#include "memory.h"
#include "mtask.h"
#include "keyboard.h"
#include "fifo.h"
extern fifo_t decoded_key;
task_t *create_kernel_task(void *entry)
{
task_t *new_task;
new_task = task_alloc();
new_task->tss.esp = (uint32_t) kmalloc(64 * 1024) + 64 * 1024 - 4;
new_task->tss.eip = (int) entry;
new_task->tss.es = new_task->tss.ss = new_task->tss.ds = new_task->tss.fs = new_task->tss.gs = 2 * 8;
new_task->tss.cs = 1 * 8;
return new_task;
}
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear();
init_gdtidt();
init_memory();
init_timer(100);
init_keyboard();
asm("sti");
task_t *task_a = task_init();
while (1) {
if (fifo_status(&decoded_key) > 0) {
monitor_put(fifo_get(&decoded_key));
}
}
}
编译,运行,输入 abc123、enter、1234567,效果如下:

(图 14-6 一片空旷)
我们看到,现在的OS启动时屏幕一片空旷,它成了一个完完全全的打字机。这也算是我们人机交互的初步成果了。
键盘相关的处理到此结束,下一节,我们开始脱离内核,向用户层迈进。
15.系统调用——应用程序与系统的交互之门
如果你没用过 Linux,只做过 Windows 开发,那么没听说过系统调用(或者其简称syscall)是比较正常的,但没听说过API是不太合理的。在本篇文章中,你可以暂时认为这两者是一样的。
如果你做过 32 位的 Linux 开发,那就比较好说了,如果没有做过也无所谓。
首先,我们得想一想:程序是如何调用系统的功能的呢?在 C 语言中,或许只是一个函数调用,那么在底层,它长什么样呢?
在 32 位的 Linux 中,它的底层是这样的:往 eax、ebx 这些寄存器里填好参数,然后执行 int 80h。这看起来很好用,我们也来抄一下。
首先,我们来在 IDT 里创建一个 0x80 编号的中断描述符。
代码 15-1 0x80 号中断描述符(kernel/gdtidt.c)
idt_set_gate(47, (uint32_t) irq15, 0x08, 0x8E);
idt_set_gate(0x80, (uint32_t) syscall_handler, 0x08, 0x8E | 0x60); // 这里是新增的
idt_flush((uint32_t) &idt_ptr);
代码 15-2 开头声明(kernel/gdtidt.c)
extern void gdt_flush(uint32_t);
extern void idt_flush(uint32_t);
extern void syscall_handler(); // 这里是新增的
和上面设置第 15 号中断的代码相对比,我们发现在最后一个参数处有些奇怪,为什么要 | 0x60 呢?事实上,| 0x60 的意思就是说,这个中断是给应用程序用的。可是我们目前还没有应用程序,因此只能让操作系统代为测试了。
接下来我们来编写 syscall_handler:
代码 15-3 系统调用入口(kernel/interrupt.asm)
[extern syscall_manager]
[global syscall_handler]
syscall_handler:
sti ; CPU 在执行 int 指令时默认关闭中断,我们只是来用一下系统功能,所以把中断打开
pushad ; 用于返回值的 pushad
pushad ; 用于给 syscall_manager 传值的 pushad
call syscall_manager
add esp, 32 ; 把给syscall_manager 传值的 pushad 部分跳过
popad ; 把希望系统调用后的寄存器情况 pop 出来
iretd ; 由于是 int 指令,所以用 iretd 返回
接着,在 kernel 目录下创建 syscall.c,我们来实现 syscall_manager:
代码 15-4 系统调用分发(kernel/syscall.c)
#include "common.h"
#include "syscall.h"
void syscall_manager(int edi, int esi, int ebp, int esp, int ebx, int edx, int ecx, int eax) // 这里的参数顺序是pushad的倒序,不可更改
{
typedef int (*syscall_t)(int, int, int, int, int); // 这里面只有五个寄存器勉强可以算正常用,所以只有五个参数
//(&eax + 1)[7] = ((syscall_t) syscall_table[eax])(ebx, ecx, edx, edi, esi); // 把下面的代码压缩成上面一行是这样的
syscall_t syscall_fn = (syscall_t) syscall_table[eax]; // 从syscall_table中拿到第 eax 个函数
int ret = syscall_fn(ebx, ecx, edx, edi, esi); // 调用并获取返回值
// 感谢编译器,即使给多了参数,被调用的函数也会把它们忽略掉
int *save_reg = &eax + 1; // 进入用于返回值的pushad
save_reg[7] = ret; // 第7个寄存器为eax,函数返回时默认将eax作为返回值
}
这里的 syscall_table 定义在 syscall.h 中,它长这样:
代码 15-5 系统调用函数表(include/syscall.h)
#ifndef _SYSCALL_H_
#define _SYSCALL_H_
typedef void *syscall_func_t;
syscall_func_t syscall_table[] = {
};
#endif
里面目前还没有任何一个函数。我们之所以采用这样一个系统调用表的方式,是因为这样便于扩展,我们只需要写好函数,然后加到数组里即可。
那么,我们现在来试试这个新框架。在 syscall.c 的下方,我们创建一个 sys_getpid:
代码 15-6 系统调用 sys_getpid(kernel/syscall.c)
int sys_getpid()
{
return task_pid(task_now());
}
添加到 syscall_table:
代码 15-7 新系统调用表(include/syscall.h)
int sys_getpid();
syscall_func_t syscall_table[] = {
sys_getpid,
};
新建 kernel/syscall_impl.asm,给 getpid 加个包装:
代码 15-8 系统调用的包装(kernel/syscall_impl.asm)
[global getpid]
getpid:
mov eax, 0
int 80h
ret
在 Makefile 中,给 OBJS 变量加上 out/syscall.o out/syscall_impl.o,理论上现在已经可以调用 getpid 了。
我们来做一个小小的测试。在 kernel_main 中加入这三行(放在 task_init 调用的后面):
代码 15-9 getpid 测试(kernel/main.c)
monitor_write("kernel_main pid: ");
monitor_write_dec(getpid());
monitor_put('\n');
编译,运行,效果如下:

(图 15-1 成功了吗?)
getpid 返回了0。这有可能有两个原因,是 int 80h 的调用失败了,所以 getpid 返回的是调用时的那个0,还是真的返回了 kernel_main 对应的那个任务的 pid 也就是 0 呢?
再创建一个任务,我们来实地验证一下:
代码 15-10 task_b 打赢复活赛(kernel/main.c)
void task_b_main()
{
monitor_write("task_b pid: ");
monitor_write_dec(getpid());
monitor_put('\n');
task_exit(0);
}
// 以下两行语句添加在kernel_main中task_init调用后
task_t *task_b = create_kernel_task(task_b_main);
task_run(task_b);
再次编译运行,效果如下:

(图 15-2 赢)
至此,我们已经初步完成了系统调用的框架。后续如果有需要,我们再对大框架进行修改。以后只要添加一个系统调用 xxx,对应的处理函数就叫 sys_xxx,这是我们后面的一个约定。
现在的篇幅略微有些短了(bushi),我们来实现一个 printf 吧。毕竟从内存管理开始,我们就在忍受着交替的 monitor_write、monitor_write_hex、monitor_write_dec,如果到了下一节的 shell 我们还在用这些,那这个画面……
所以,实现一个 printf 势在必行。之所以拖到现在,是因为前面的篇幅都被排满了。
那么,我们开始。printf 分为两个部分:print 和 f。看起来 print 简单一点,我们就先做 print 吧。
在 Linux 中,输出用的函数归根到底是 write 系统调用。我们照葫芦画瓢,也实现一个 write 系统调用。不过在 Linux 上,write 是用来写文件的,第一个参数代表对应的文件描述符(第18节会详细讲解这是个什么东西)。只要传入 1,那么 Linux 就会认为你在往标准输出写入。这个功能好,我也这么干。
那么,sys_write 的具体内容如下:
代码 15-11 只支持到标准输出的 write(kernel/syscall.c)
int sys_write(int fd, const void *msg, int len)
{
if (fd == 1) {
char *s = (char *) msg;
for (int i = 0; i < len; i++) monitor_put(s[i]);
return 0;
}
return -1;
}
代码 15-12 现在的 include/syscall.h
#ifndef _SYSCALL_H_
#define _SYSCALL_H_
typedef void *syscall_func_t;
int sys_getpid();
int sys_write(int, const void *, int);
syscall_func_t syscall_table[] = {
sys_getpid, sys_write,
};
#endif
接下来添加对应的包装:
代码 15-13 write 的包装(kernel/syscall_impl.asm)
[global write]
write:
push ebx
mov eax, 1
mov ebx, [esp + 8]
mov ecx, [esp + 12]
mov edx, [esp + 16]
int 80h
pop ebx
ret
按照 C 编译器约定,ebx 不能随便用,所以这里 push 又 pop 了一下。那么,参数的位置也就要相应顺延,从 esp + 4、esp + 8、esp + 12 都加了4。
好了,我们来测试一下 write:
代码 15-14 write 测试(kernel/main.c)
void task_b_main()
{
write(1, "task_b pid: ", strlen("task_b pid: "));
monitor_write_dec(getpid());
write(1, "\n", 2);
task_exit(0);
}
编译,运行,效果仍应如图 15-2 所示。现在,我们已经有了 print 的系统调用,该实现 f 了。
或许有人会说,你这个 write 比 monitor_write 需要的参数还要多,有什么好处可言吗?你说得对,但是 write 是系统调用,未来可以给应用程序用,但是 monitor_write 并不行。
怎样实现这个 f 呢?这个 f 背后的内容非常庞大,我们不写那么多,只支持 %d、%x、%c 以及 %s。如果只支持打印的话,功能有点少,顺便再支持一个 sprintf。涉及到 sprintf,那就必然存在要把整数转换成字符串的问题。
输出十进制和十六进制整数我们已有先例,但是那都是输出到屏幕上了,我们总不可能从屏幕里再收集一遍。所以我们只好写一个单独的函数了。
查找资料发现,在 Windows 下,对应的整数转字符串函数为 itoa,原型是 char *itoa(int num, char *ptr, int radix)。我们不需要这样一个返回值,但我们又需要写入 char *。这是因为 char * 本身是一个字符串,在别的作用域修改 char * 就需要 char * 的指针,也就是 char **。
最终,我们决定把 itoa 写成:void itoa(uint32_t num, char **ptr_addr, int radix)。它的实现也没有那么难:
代码 15-15 itoa(lib/printf.c)
#include "common.h"
static void itoa(uint32_t num, char **buf_ptr_addr, int radix)
{
uint32_t m = num % radix; // 最低位
uint32_t i = num / radix; // 最高位
if (i) itoa(i, buf_ptr_addr, radix); // 先把高位化为字符串
if (m < 10) { // 处理最低位
*((*buf_ptr_addr)++) = m + '0'; // 0~9,直接加0
} else {
*((*buf_ptr_addr)++) = m - 10 + 'A'; // 10~15,10~15->0~5->A~F
}
}
接下来我们来思考一个问题:printf 接收的参数并没有数量上的限定,它哪来的那么大能耐接收无穷无尽的参数呢?这就用到了 C 语言一个不那么鲜为人知的特性:可变参数包。
访问 Linux 的 manpage 的网页版:man7中有关 printf 的文档,我们发现,printf 的参数里冒出了一个 ...,这又是什么东西呢?这就是可变参数包的语法,你可以往 ... 里塞任意多个任意类型的东西,只要内存装得下就行。
那么,我们怎么从这坨 ... 中拿到我传入的东西呢?我们发现,除了 printf、fprintf、dprintf、sprintf 和 snprintf 这五个带 ... 的函数以外,下面还有五个类似的函数,只是在这五个函数的前面加了一个字母 v。对比一下参数,原来是把最后一个 ... 换成了 va_list ap。下面的文档也明确声明,带 v 的版本与不带 v 的版本功能相同,只是一个用了 va_list 一个没用。看来这个 va_list 最终就是可变参数包的载体。
下面还有一个链接让我们转到 stdarg(3),这四个函数应该就是对 va_list 进行操纵的函数了。va_start 是必须要调用的,last 依照描述,是 va_list 之前的最后一个参数。需要取参数,则要调用 va_arg,如果想要 int 参数,就需要调用 va_arg(ap, int),如果要 char,就是 va_arg(ap, char),以此类推。用完 va_list 之后,我们需要调用 va_end。最下面的 va_copy 我们用不到,就不用管了。
那么这四个东西是怎么实现的呢?我们找到了 mingw 中对应的头文件,位于 mingw文件夹下/lib/gcc/mingw32/9.2.0/include/stdarg.h(不同版本mingw可能变化),特此复制粘贴供诸位参考。请看 VCR:
代码 15-16 va_list 有关函数的实现(无文件)
#define va_start(v,l) __builtin_va_start(v,l)
#define va_end(v) __builtin_va_end(v)
#define va_arg(v,l) __builtin_va_arg(v,l)
#if !defined(__STRICT_ANSI__) || __STDC_VERSION__ + 0 >= 199900L \
|| __cplusplus + 0 >= 201103L
#define va_copy(d,s) __builtin_va_copy(d,s) // C99以上 或 C++11以上 或添加-ansi选项时 提供
#endif
#define __va_copy(d,s) __builtin_va_copy(d,s)
原来是编译器内置的实现,那没事了。在 i686-elf-tools 的类似路径下,我们也找到了这样的一段代码,看来我们的 gcc 也是支持这几个东西的。
有编译器内置实现我们就不管了,新建 include/stdarg.h,我们这就开抄:
代码 15-17 include/stdarg.h
#ifndef _STDARG_H_
#define _STDARG_H_
typedef char *va_list; // 我也不知道va_list是什么类型,先给个char *挂着,反正用不到
#define va_start(v,l) __builtin_va_start(v,l)
#define va_end(v) __builtin_va_end(v)
#define va_arg(v,l) __builtin_va_arg(v,l)
#define va_copy(d,s) __builtin_va_copy(d,s)
#endif
好了,现在我们已经有了处理可变参数包的手段了,我们来写一个 printf:
代码 15-18 不能格式化的 printf(lib/printf.c)
#include "stdarg.h" // 在开头添加,因为用到了va_list以及操纵va_list的这些东西
int vsprintf(char *buf, const char *fmt, va_list ap)
{
return 114514;
}
int sprintf(char *buf, const char *fmt, ...)
{
va_list ap;
va_start(ap, fmt);
int ret = vsprintf(buf, fmt, ap);
va_end(ap);
return ret;
}
int vprintf(const char *fmt, va_list ap)
{
char buf[1024] = {0}; // 理论上够了
int ret = vsprintf(buf, fmt, ap);
write(1, buf, ret);
return ret;
}
int printf(const char *fmt, ...)
{
va_list ap;
va_start(ap, fmt);
int ret = vprintf(fmt, ap);
va_end(ap);
return ret;
}
经过层层踢皮球,最终 sprintf、vprintf 和 printf 参数处理的重任都落到了 vsprintf 的头上。由于我们只支持 %s、%c、%d 和 %x,我们也就不用多麻烦地处理 % 后面那一坨,直接用一个 switch 即可。
我们先来列一下基本框架:
代码 15-19 vsprintf 的基本框架(lib/printf.c)
int vsprintf(char *buf, const char *fmt, va_list ap)
{
char *buf_ptr = buf; // 不动原来的buf,原来的buf可能还用得着
const char *index_ptr = fmt; // 不动原来的fmt,但这个好像真用不着
char index_char = *index_ptr; // fmt串中的当前字符
int32_t arg_int; // 可能会出现的int参数
char *arg_str; // 可能会出现的char *参数
while (index_char) { // 没到fmt的结尾
if (index_char != '%') { // 不是%
*(buf_ptr++) = index_char; // 直接复制到buf
index_char = *(++index_ptr); // 自动更新到下一个字符
continue; // 跳过后续对于%的判断
}
index_char = *(++index_ptr); // 先把%跳过去
switch (index_char) { // 对现在的index_char进行判断
case 's':
case 'c':
case 'x':
case 'd':
default:
break;
}
index_char = *(++index_ptr); // 再把%后面的s c x d跳过去
}
return strlen(buf); // 返回做完后buf的长度
}
基本上就是这样,对代码的解释都在注释里了。
下面我们着重对 index_char 的判断进行讲解,实际上也并不多。
首先从 %s 和 %c 开始。大致思路是这样的:获取对应的参数->写入 buf_ptr。
代码 15-20 %s、%c(lib/printf.c)
switch (index_char) { // 对现在的index_char进行判断
case 's':
arg_str = va_arg(ap, char*); // 获取char *参数
strcpy(buf_ptr, arg_str); // 直接strcpy进buf_ptr
buf_ptr += strlen(arg_str); // buf_ptr直接跳到arg_str结尾,正好在arg_str结尾的\0处
break;
case 'c':
*(buf_ptr++) = va_arg(ap, int); // 把获取到的char参数直接写进buf_ptr
break;
case 'x':
case 'd':
default:
break;
}
之所以 %c 那里没有用 va_arg(ap, char) 获取 char 类型的参数,是因为这样会报警告,原因未知。
下面的 %x 和 %d 逻辑类似,因为有 itoa 十分简单。
代码 15-21 %x、%d(lib/printf.c)
case 'x':
arg_int = va_arg(ap, int); // 获取int参数
itoa(arg_int, &buf_ptr, 16); // itoa早在设计时就可以修改buf_ptr,这样就直接写到buf_ptr里了,还自动跳到数末尾
break;
case 'd':
arg_int = va_arg(ap, int); // 获取int参数
if (arg_int < 0) { // 给负数前面加个符号
arg_int = -arg_int; // 先转负为正
*(buf_ptr++) = '-'; // 然后加负号
}
itoa(arg_int, &buf_ptr, 10); // itoa早在设计时就可以修改buf_ptr,这样就直接写到buf_ptr里了,还自动跳到数末尾
break;
现在我们的 printf 就已经写完了,在 Makefile 的 OBJS 最后加入一个 out/printf.o,准备进行测试。
代码 15-22 现在的 task_b_main(kernel/main.c)
void task_b_main()
{
printf("task_b %s %d%c", "pid:", getpid(), '\n');
task_exit(0);
}
编译,运行,效果仍应如图 15-2 所示。至此,我们的 printf 顺利完成。
最后,我们再开发一个内核专用的 printk,它直接调用 monitor_write,省略了 write 的中间步骤。
代码 15-23 printk(lib/kstdio.c)
#include "stdio.h"
#include "monitor.h"
int printk(const char *fmt, ...)
{
va_list ap;
va_start(ap, fmt);
char buf[1024] = {0};
int ret = vsprintf(buf, fmt, ap);
va_end(ap);
monitor_write(buf);
return ret;
}
代码 15-24 include/stdio.h
#ifndef _STDIO_H_
#define _STDIO_H_
#include "common.h"
#include "stdarg.h"
int vsprintf(char *buf, const char *fmt, va_list ap);
int sprintf(char *buf, const char *fmt, ...);
int vprintf(const char *fmt, va_list ap);
int printf(const char *fmt, ...);
int printk(const char *fmt, ...); // for kernel use
#endif
在 Makefile 的 OBJS 处添加 out/kstdio.o,由于测试代码未变更,暂时不需要编译运行。
好了,本节到此为止就结束了,下一节我们开始做更好的人机交互——也就是 shell。
16.shell的设计与实现
和前面几节相比,这一节应该会轻松很多,因为 shell 离用户层更近,也就更贴合日常开发时的代码习惯,再也不用去管什么硬件规程了——不过也就欢快这一节,下面两节又是硬菜了。
我们希望我们的 shell 能够很方便地移植成用户程序,所以我们要保证 shell 中调用的函数最终都是应用程序能直接用的东西,包括系统调用和 string.h 里的那一坨。
作为一个 shell,读取键盘输入是必要的,但我们目前还没有读取键盘输入的系统调用。
啊这个不是非常简单吗,键盘输入就是标准输入,读标准输入用
scanf不就行了?
你说得对,但是把一个 scanf 说明白写明白已经抵得上我至少一节的篇幅了。所以我们还是得到 Linux 里去想办法。
经过查阅资料,我们发现,归根结底,在 Linux 中,得到键盘输入的函数是 read。只要给第一个参数传 0,read 就会默认你要读键盘输入。而在 Linux 中 read 时,只要没有回车,read 就不会返回。
我们的 read 不需要那么智能,有一个键返回一个就够了。来到 kernel/syscall.c,我们来写 sys_read:
代码 16-1 read 系统调用的背后(kernel/syscall.c)
#include "fifo.h" // 加在开头
extern fifo_t decoded_key; // 加在开头
// 省略中间的 syscall_manager、sys_getpid 和 sys_write
int sys_read(int fd, void *buf, int count)
{
int ret = -1;
if (fd == 0) { // 如果是标准输入
char *buffer = (char *) buf; // 先转成char *
uint32_t bytes_read = 0; // 读了多少个
while (bytes_read < count) { // 没达到count个
while (fifo_status(&decoded_key) == 0); // 只要没有新的键我就不读进来
*buffer = fifo_get(&decoded_key); // 获取新的键
bytes_read++;
buffer++; // buffer指向下一个
}
ret = (bytes_read == 0 ? -1 : (int) bytes_read); // 如果啥也没读着就-1,否则就正常返回就行了
return ret;
}
return -1; // 还没做
}
在 syscall_table 中加入 sys_read,随后在 syscall_impl.asm 中添加 read 的实现:
代码 16-2 read 的实现(kernel/syscall_impl.asm)
[global read]
read:
push ebx
mov eax, 2
mov ebx, [esp + 8]
mov ecx, [esp + 12]
mov edx, [esp + 16]
int 80h
pop ebx
ret
目前我们输出字符串需要依靠 printf,但是 printf("%s\n") 我们要频繁用到,这又实在是太长了。
因此,我们把 lib/printf.c 改名为 lib/stdio.c,并封装了两个最基本的东西,puts 和 putchar:
代码 16-3 puts 和 putchar(lib/stdio.c)
void puts(const char *buf)
{
write(1, buf, strlen(buf));
write(1, "\n", 1);
}
int putchar(char ch)
{
printf("%c", ch);
return ch;
}
记得同时在 Makefile 的 OBJS 中把 out/printf.o 改为 out/stdio.o,并自行在 stdio.h 中添加 puts 和 putchar 的声明。
新建一个 kernel/shell.c,我们正式开始写 shell。先搭一个最基本的脚手架吧:
代码 16-4 脚手架(kernel/shell.c)
#include "shell.h" // MAX_CMD_LEN, MAX_ARG_NR
#include "stdio.h"
static char cmd_line[MAX_CMD_LEN] = {0}; // 输入命令行的内容
static char *argv[MAX_ARG_NR] = {NULL}; // argv,字面意思
static void print_prompt() // 输出提示符
{
printf("[TUTO@localhost /] $ "); // 这一部分大家随便改,你甚至可以改成>>>
}
static void readline(char *buf, int cnt) // 输入一行或cnt个字符
{
char *pos = buf; // 不想变buf
while (read(0, pos, 1) != -1 && (pos - buf) < cnt) { // 读字符成功且没到cnt个
switch (*pos) {
case '\n':
case '\r': // 回车或换行,结束
*pos = 0;
putchar('\n'); // read不自动回显,需要手动补一个\n
return; // 返回
case '\b': // 退格
if (buf[0] != '\b') { // 如果不在第一个
--pos; // 指向上一个位置
putchar('\b'); // 手动输出一个退格
}
break;
default:
putchar(*pos); // 都不是,那就直接输出刚输入进来的东西
pos++; // 指向下一个位置
}
}
}
void shell()
{
puts("TutorialOS Indev (tags/Indev:WIP, Jun 26 2024, 21:09) [GCC 32bit] on baremetal"); // 看着眼熟?这一部分是从 Python 3 里模仿的
puts("Type \"ver\" for more information.\n"); // 示例,只打算支持这一个
while (1) { // 无限循环
print_prompt(); // 输出提示符
memset(cmd_line, 0, MAX_CMD_LEN);
readline(cmd_line, MAX_CMD_LEN); // 输入一行命令
if (cmd_line[0] == 0) continue; // 啥也没有,是换行,直接跳过
}
puts("shell: PANIC: WHILE (TRUE) LOOP ENDS! RUNNNNNNN!!!"); // 到不了,不解释
}
代码 16-5 include/shell.h
#ifndef _SHELL_H_
#define _SHELL_H_
#include "common.h"
#define MAX_CMD_LEN 100
#define MAX_ARG_NR 30
void shell();
#endif
在 Makefile 的 OBJS 中添加 out/shell.o,编译运行,自然是什么都没有,因为我们根本就没有运行 shell 的入口。
在 kernel_main 中创建一个新任务用来执行 shell:
代码 16-6 shell 任务(kernel/main.c)
#include "shell.h" // 添加在开头
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear();
init_gdtidt();
init_memory();
init_timer(100);
init_keyboard();
asm("sti");
task_t *task_a = task_init();
task_t *task_b = create_kernel_task(task_b_main);
task_t *task_shell = create_kernel_task(shell);
task_run(task_b);
task_run(task_shell);
monitor_write("kernel_main pid: ");
monitor_write_dec(getpid());
monitor_put('\n');
while (1) {
if (fifo_status(&decoded_key) > 0) {
//monitor_put(fifo_get(&decoded_key));
}
}
}
我们注释掉了最后的 monitor_put,这是因为我们已经有了 shell(即使只是个脚手架),不再需要这么低级的人机交互了。
现在再次编译,运行,效果如下:

(图 16-1 脚手架)
现在我们就得到了一个 shell,一个输入什么都不会返回的 shell。
task_b_main 已经结束其历史使命,可以删掉了。现在的 main.c 就精简成了这个样子:
代码 16-7 如今的 kernel/main.c
#include "monitor.h"
#include "gdtidt.h"
#include "isr.h"
#include "timer.h"
#include "memory.h"
#include "mtask.h"
#include "keyboard.h"
#include "shell.h"
task_t *create_kernel_task(void *entry)
{
task_t *new_task;
new_task = task_alloc();
new_task->tss.esp = (uint32_t) kmalloc(64 * 1024) + 64 * 1024 - 4;
new_task->tss.eip = (int) entry;
new_task->tss.es = new_task->tss.ss = new_task->tss.ds = new_task->tss.fs = new_task->tss.gs = 2 * 8;
new_task->tss.cs = 1 * 8;
return new_task;
}
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear();
init_gdtidt();
init_memory();
init_timer(100);
init_keyboard();
asm("sti");
task_t *task_a = task_init();
task_t *task_shell = create_kernel_task(shell);
task_run(task_shell);
while (1);
}
有种回到了第12节的错觉呢?
下面我们来做对命令的解析,这一部分比较好想。
代码 16-8 命令解析 cmd_parse(kernel/shell.c)
static int cmd_parse(char *cmd_str, char **argv, char token)
{
int arg_idx = 0;
while (arg_idx < MAX_ARG_NR) {
argv[arg_idx] = NULL;
arg_idx++;
} // 开局先把上一个argv抹掉
char *next = cmd_str; // 下一个字符
int argc = 0; // 这就是要返回的argc了
while (*next) { // 循环到结束为止
if (*next != '"') {
while (*next == token) *next++; // 多个token就只保留第一个,windows cmd就是这么处理的
if (*next == 0) break; // 如果跳过完token之后结束了,那就直接退出
argv[argc] = next; // 将首指针赋值过去,从这里开始就是当前参数
while (*next && *next != token) next++; // 跳到下一个token
} else {
next++; // 跳过引号
argv[argc] = next; // 这里开始就是当前参数
while (*next && *next != '"') next++; // 跳到引号
}
if (*next) { // 如果这里有token字符
*next++ = 0; // 将当前token字符设为0(结束符),next后移一个
}
if (argc > MAX_ARG_NR) return -1; // 参数太多,超过上限了
argc++; // argc增一,如果最后一个字符是空格时不提前退出,argc会错误地被多加1
}
return argc;
}
代码的详细解释请参见注释,写的已经很详尽了。我们的 cmd_parse 支持自己传入分隔符,顺便还支持了一下引号。
下面是新版的 shell 本体:
代码 16-9 新版 shell(kernel/shell.c)
void shell()
{
puts("TutorialOS Indev (tags/Indev:WIP, Jun 26 2024, 21:09) [GCC 32bit] on baremetal"); // 看着眼熟?这一部分是从 Python 3 里模仿的
puts("Type \"ver\" for more information.\n"); // 示例,只打算支持这一个
while (1) { // 无限循环
print_prompt(); // 输出提示符
memset(cmd_line, 0, MAX_CMD_LEN);
readline(cmd_line, MAX_CMD_LEN); // 输入一行命令
if (cmd_line[0] == 0) continue; // 啥也没有,是换行,直接跳过
int argc = cmd_parse(cmd_line, argv, ' '); // 解析命令,按照cmd_parse的要求传入,默认分隔符为空格
for (int i = 0; i < argc; i++) puts(argv[i]); // 输出分段出来的每一个参数
}
puts("shell: PANIC: WHILE (TRUE) LOOP ENDS! RUNNNNNNN!!!"); // 到不了,不解释
}
编译,运行,效果如下图:

(图 16-2 没那么哑的 shell)
现在,我们的 shell 已经支持用空格分割参数,并且支持把引号括起来的部分当成整体。只有一个引号我没有测试,理论上会一直延伸到命令末尾。
最后,是命令的执行,这一部分我们单开一个 cmd_execute 来做:
代码 16-10 命令执行(kernel/shell.c)
void cmd_ver(int argc, char **argv)
{
puts("TutorialOS Indev");
}
void cmd_execute(int argc, char **argv)
{
if (!strcmp("ver", argv[0])) {
cmd_ver(argc, argv);
} else {
printf("shell: bad command: %s\n", argv[0]);
}
}
目前而言,我们只支持一个 ver 就足够了。
用 cmd_execute(argc, argv); // 执行 替换 for (int i = 0; i < argc; i++) puts(argv[i]); // 输出分段出来的每一个参数,编译运行,效果如下:

(图 16-3 ver命令)
shell 就做到这里,下面两节我们来吃一盘硬菜:文件系统。(想当年,我被文件系统卡了整整一年半,令人感叹)
17.实现FAT16文件系统(1)——基础设施建设:硬盘驱动、RTC
什么是文件系统呢?简而言之,文件系统就是管理文件的系统。当我们谈及对文件的操作的时候,文件系统是动态的,我们可以与它交互;当我们谈及文件系统的磁盘结构之类的东西的时候,文件系统又是静态的,它的每一个字节都摆在那里,随你可看。
本节我们先不着急实现文件系统,以及介绍那个怪怪的 FAT16 到底是个什么东西。我们先来完善一下基础设施建设,写一下硬盘驱动以及 RTC(Real-Time Clock,实时时钟)。
当然,我们先挑软柿子捏,从 RTC 开始实现。
与键盘类似,RTC 也是外部设备,需要使用 in/out 指令从对应的端口来读取数据。这之中,端口 0x70 是索引寄存器,用来告诉 RTC 你要读什么数据;端口 0x71 是数据寄存器,你想读的 RTC 数据就从这里读出。查阅资料可知,当前时刻的世纪、年、月、日、时、分、秒分别对应着索引 0x32、0x9、0x8、0x7、0x4、0x2 和 0x0。需要注意的是,从 RTC 读出的数据使用 8421BCD 编码,需要手动转换为十进制;具体而言,是将读出的数据的高4位当作十位,低4位当作个位。还有一点需要注意,在读取完后,需要向 0x70 端口发送 0x80,表示读取完成。
好了,我们就用上面一段话完整地描述了 RTC 的实现,相当简单吧?那么,开工。
首先,创建 include/cmos.h,我们来把上面的这一堆常数写在一个地方:
代码 17-1 RTC 声明(include/cmos.h)
#ifndef _CMOS_H_
#define _CMOS_H_
#include "common.h"
#define CMOS_INDEX 0x70
#define CMOS_DATA 0x71
#define CMOS_CUR_SEC 0x0
#define CMOS_CUR_MIN 0x2
#define CMOS_CUR_HOUR 0x4
#define CMOS_CUR_DAY 0x7
#define CMOS_CUR_MON 0x8
#define CMOS_CUR_YEAR 0x9
#define CMOS_CUR_CEN 0x32
#define bcd2hex(n) (((n >> 4) * 10) + (n & 0xf))
typedef struct {
int year, month, day, hour, min, sec;
} current_time_t;
#endif
不仅定义了这些常量,还在最后添加了 bcd2hex 和一个结构体类型,这纯粹是为了后续方便。
然后,由于 RTC 是外设,我们在 drivers 目录下添加 cmos.c,来写真正操作 RTC 的代码:
代码 17-2 读取 RTC(drivers/cmos.c)
#include "cmos.h"
static uint8_t read_cmos(uint8_t p)
{
uint8_t data;
outb(CMOS_INDEX, p);
data = inb(CMOS_DATA);
outb(CMOS_INDEX, 0x80);
return data;
}
void get_current_time(current_time_t *ctime)
{
ctime->year = bcd2hex(read_cmos(CMOS_CUR_CEN)) * 100 + bcd2hex(read_cmos(CMOS_CUR_YEAR));
ctime->month = bcd2hex(read_cmos(CMOS_CUR_MON));
ctime->day = bcd2hex(read_cmos(CMOS_CUR_DAY));
ctime->hour = bcd2hex(read_cmos(CMOS_CUR_HOUR));
ctime->min = bcd2hex(read_cmos(CMOS_CUR_MIN));
ctime->sec = bcd2hex(read_cmos(CMOS_CUR_SEC));
}
总共20行,我们就实现了对 RTC 的读取。那么让我们进入 kernel/main.c 添加测试代码看看效果:
代码 17-3 测试 RTC(drivers/cmos.c)
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear();
init_gdtidt();
init_memory();
init_timer(100);
init_keyboard();
asm("sti");
task_t *task_a = task_init();
task_t *task_shell = create_kernel_task(shell);
//task_run(task_shell);
current_time_t ctime;
get_current_time(&ctime);
printk("%d/%d/%d %d:%d:%d", ctime.year, ctime.month, ctime.day, ctime.hour, ctime.min, ctime.sec);
while (1);
}
我们注释掉了开始运行 task_shell 的这行代码,因为在这三节里都用不上它。
编译,运行,效果如下(运行效果与运行时间有关,请自行与右下角时间对照):

(图 17-1 貌似成功了?)

(图 17-2 实际时间)
我们观察到,运行时显示的 RTC 时间与实际时间相差 8 小时,这是一个非常特殊的数字,因为中国所在的时区就是东八区(UTC+8)。然而,在我换用 VMWare 虚拟机测试的时候,时钟又恢复正常了。看来这一现象的出现与不同虚拟机模拟 RTC 的策略有关。
为了与现实相符合,我们选择手动调节 RTC 的输出,让它加上 8 小时。
代码 17-4 手动加上 8 小时(drivers/cmos.c)
#include "cmos.h"
static uint8_t read_cmos(uint8_t p)
{
uint8_t data;
outb(CMOS_INDEX, p);
data = inb(CMOS_DATA);
outb(CMOS_INDEX, 0x80);
return data;
}
#ifdef NEED_UTC_8
static bool is_leap_year(int year)
{
if (year % 400 == 0) return true;
return year % 4 == 0 && year % 100 != 0;
}
#endif
void get_current_time(current_time_t *ctime)
{
ctime->year = bcd2hex(read_cmos(CMOS_CUR_CEN)) * 100 + bcd2hex(read_cmos(CMOS_CUR_YEAR));
ctime->month = bcd2hex(read_cmos(CMOS_CUR_MON));
ctime->day = bcd2hex(read_cmos(CMOS_CUR_DAY));
ctime->hour = bcd2hex(read_cmos(CMOS_CUR_HOUR));
ctime->min = bcd2hex(read_cmos(CMOS_CUR_MIN));
ctime->sec = bcd2hex(read_cmos(CMOS_CUR_SEC));
#ifdef NEED_UTC_8
int day_of_months[] = {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
if (is_leap_year(ctime->year)) day_of_months[2]++;
// 校正时间
ctime->hour += 8;
if (ctime->hour >= 24) ctime->hour -= 24, ctime->day++;
if (ctime->day > day_of_months[ctime->month]) ctime->day = 1, ctime->month++;
if (ctime->month > 12) ctime->month = 1, ctime->year++;
#endif
}
这里需要特别注意的是对边界情况的考虑,如果加上 8 小时后刚好跨天、跨月甚至是跨年,我们都需要做相应的处理,由此带来的还有闰年时 2 月天数的有关问题,但总体上也不算复杂。
同样还需要注意的是,为了应对不同虚拟机间的不同模拟情况,这里使用了宏定义 NEED_UTC_8,当定义这个宏时就会自动增加给 RTC 添加 8 小时的处理,否则就是代码 17-2 的样子。
如果你始终选择用 QEMU 进行模拟,记得在 include/cmos.h 中加入一行 #define NEED_UTC_8。
在手动加完 8 小时之后,再次编译运行,效果如下(运行效果与运行时间有关,请自行与右下角时间对照):

(图 17-3 这下对了)

(图 17-4 当前时间)
ok,那么 RTC 就这样被我们轻松拿下。然后是下一个据点:硬盘驱动。
硬盘,显然也是外部设备,如果要真正详细地去实现硬盘,那足够写出这个 OS 现在的代码三分之一的代码量的驱动来(osdev上的 IDE 驱动有 749 行)。不过,只是读取和写入的话,实际上有捷径可走,无需像 osdev 上一样费劲绕道 PCI,只需要几个简单的端口操作即可。
即使是走捷径,硬盘的端口操作仍然多且杂,具体可见下表(仍旧来自《Orange'S:一个操作系统的实现》):

(图 17-5 硬盘端口列表)
以上的部分就是我们需要用到的部分,其中的 Secondary 一列代表第二块硬盘,可以不管,反正到最后只需要操作第一块硬盘。
想要读写一块硬盘的一个扇区,大概操作是这样的:
1.等待可能存在的上一个硬盘操作完成。
2.通过向 0x1f2~0x1f6 端口写入适当数据,告知硬盘需要操作的扇区编号及个数。
3.向 0x1f7 端口写入 0x20(代表读)或者 0x30(代表写)。
4.等待硬盘操作完成。
5.从 0x1f0 端口读出数据或向 0x1f0 端口写入数据,一次两个字节。
看上去比较简单,但是有一些具体的技术细节需要注意,还是直接看代码吧:
代码 17-5 硬盘驱动:等待上一个硬盘操作完成,指定操作扇区(drivers/hd.c)
#include "common.h"
// 等待磁盘,直到它就绪
static void wait_disk_ready()
{
while (1) {
uint8_t data = inb(0x1f7); // 输入时,0x1f7端口为主硬盘状态寄存器
if ((data & 0x88) == 0x08) { // 第7位:硬盘忙,第3位:硬盘已经准备好
// 提取第7位和第3位,判断是否为0x08,即硬盘不忙且已准备好
return; // 等完了
}
}
}
// 选择要操作扇区
static void select_sector(int lba)
{
// 第一步:向0x1f2端口指定要读取扇区数
// 输出时,0x1f2端口为操作扇区数
outb(0x1f2, 1);
// 第二步:存入写入地址
// 0x1f3~0x1f5:LBA的低中高8位
// 0x1f6:REG_DEVICE,Drive | Head | LBA (24~27位)
// 在实际操作中,只有一个硬盘,Drive | Head = 0xe0
outb(0x1f3, lba);
outb(0x1f4, lba >> 8);
outb(0x1f5, lba >> 16);
outb(0x1f6, (((lba >> 24) & 0x0f) | 0xe0));
}
以上两个函数便是我前面提到过的“具体细节”,有关说明已经写在注释中了。
或许有人要问:
那你为什么一次只操作一个扇区呢?一次操作多个扇区不好吗?
你说得对,但是,由于 QEMU 的问题(这是第几遍出现了),一次操作多个扇区会莫名其妙卡住,所以只好一次操作一个扇区了。
既然技术细节已经填充上,单独读取和写入一个扇区的函数也就可以写了:
代码 17-6 硬盘驱动:读取和写入一个扇区(drivers/hd.c)
// 读取一个扇区
static void read_a_sector(int lba, uint32_t buffer)
{
while (inb(0x1f7) & 0x80); // 等硬盘不忙了再发送命令,具体意义见wait_disk_ready
select_sector(lba); // 第二步:设置读写扇区
outb(0x1f7, 0x20); // 第三步:宣布要读扇区
// 0x1f7在被写入时为REG_COMMAND,写入读写命令
wait_disk_ready(); // 第四步:检测硬盘状态,直到硬盘就绪
// 第五步:从0x1f0读取数据
// 0x1f0被读写时为REG_DATA,读出或写入数据
for (int i = 0; i < 256; i++) {
// 每次硬盘会发送2个字节数据
uint16_t data = inw(0x1f0);
*((uint16_t *) buffer) = data; // 存入buf
buffer += 2;
}
}
// 写入一个扇区
// 写入与读取基本一致,仅有的不同之处是写入的命令和写数据的操作
static void write_a_sector(int lba, uint32_t buffer)
{
while (inb(0x1f7) & 0x80); // 等硬盘不忙了再发送命令,具体意义见wait_disk_ready
select_sector(lba); // 第二步:设置读写扇区
outb(0x1f7, 0x30); // 第三步:宣布要写扇区
// 0x1f7在被写入时为REG_COMMAND,写入读写命令
wait_disk_ready(); // 第四步:检测硬盘状态,直到硬盘就绪
// 第五步:从0x1f0读取数据
// 0x1f0被读写时为REG_DATA,读出或写入数据
for (int i = 0; i < 256; i++) {
// 每次硬盘会发送2个字节数据
uint16_t data = *((uint16_t *) buffer); // 读取数据
outw(0x1f0, data); // 写入端口
buffer += 2;
}
}
这里其实有意地忽略了一个细节:硬盘操作执行完后,会发送一个硬盘中断。不过,由于我们并没有编写硬盘中断处理程序,因此它会被我们的框架自动忽略,看来几节以前我们打的地基还是很有用的。
读写多个扇区就是对读写单个扇区的简单重复:
代码 17-7 硬盘驱动:连续读写多个扇区(drivers/hd.c)
// 读取硬盘
static void read_disk(int lba, int sec_cnt, uint32_t buffer)
{
for (int i = 0; i < sec_cnt; i++) {
read_a_sector(lba, buffer); // 一次读一个扇区
lba++; // 下一个扇区
buffer += 512; // buffer也要指向下一个扇区
}
}
// 写入硬盘
static void write_disk(int lba, int sec_cnt, uint32_t buffer)
{
for (int i = 0; i < sec_cnt; i++) {
write_a_sector(lba, buffer); // 一次写一个扇区
lba++; // 下一个扇区
buffer += 512; // buffer也要指向下一个扇区
}
}
最后是两个包装函数作为公开的接口,不同之处仅仅是用 void * 替代 uint32_t 作为缓冲区类型:
代码 17-8 硬盘驱动:最终暴露的接口(drivers/hd.c)
// 包装
void hd_read(int lba, int sec_cnt, void *buffer)
{
read_disk(lba, sec_cnt, (uint32_t) buffer);
}
void hd_write(int lba, int sec_cnt, void *buffer)
{
write_disk(lba, sec_cnt, (uint32_t) buffer);
}
好,硬盘驱动到此结束,但是怎么测试呢?显然,这时并不存在一个虚拟硬盘。
为了后面行文方便,同时也是为了配置环境方便,这里引入我自制的一个开源工具:myfattools,使用它可以方便地对虚拟硬盘进行操作,包括但不限于创建、格式化、拷贝文件进出等等,目前已经在 Windows 7、Windows 11 和 iOS 上进行过测试(实际上 myfattools 就是在这三种操作系统上开发的)。为了跨平台需要 因为我懒,请读者自行下载这几个 .c 文件,然后用 gcc 自行编译为二进制,放在可以随时调用到的地方(比如这个项目的根目录处)以备调用。
(注:由于此程序目前名义上正在重构,所以请以 old 文件夹中的内容为准。当然实际上重构已经停滞了。)
本次测试需要用到的程序为 ftimgcreate 和 ftformat,确认这两个程序是否都已存在且可供调用:


(图 17-5 程序存在情况)
如果在命令行输入 ftimgcreate 与 ftformat 后,输出如上两图所示(或类似),则说明这两个程序配置相当成功;否则,请检查是否把这两个程序放在了正确的地方。
在命令行中执行这两条命令:

(图 17-6 执行命令)
若无返回消息,则说明成功。现在 hd.img 就是一个有数据的虚拟硬盘了。
在 main.c 中将 kernel_main 修改如下:
代码 17-9 测试硬盘用 kernel_main(kernel/main.c)
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear();
init_gdtidt();
init_memory();
init_timer(100);
init_keyboard();
asm("sti");
task_t *task_a = task_init();
task_t *task_shell = create_kernel_task(shell);
//task_run(task_shell);
char first_sect[512] = {0};
hd_read(0, 1, first_sect);
printk(first_sect);
while (1);
}
实际上就是读取第一个扇区的内容。
编译,运行,效果如图:

(图 17-7 啥也没有?)
什么都没有输出,这是因为我们还没有在 QEMU 上挂载这个虚拟硬盘,修改 Makefile 中的 run 指令如下:
代码 17-10 Makefile 中的 run(Makefile)
run : a.img
qemu-system-i386 -fda a.img -hda hd.img -boot a
在挂载硬盘的同时指定从软盘启动,因为硬盘里根本啥都没有,从硬盘启动就废了。
编译,运行,效果如图:

(图 17-8 成功)

(图 17-9 硬盘内真实数据)
在去掉不可打印字符后,输出与硬盘内真实数据一致。由于 FTFORMAT 后紧跟着就是 00,所以后面的问号没有输出。总之,可以认为我们的硬盘驱动已经正常工作了。
那么,实现 FAT16 的基建已经基本铺好,下面的工作就是了解什么是 FAT16,然后动手实践了。
18.实现FAT16文件系统(2)——格式化、打开文件、创建文件
什么是 FAT16 文件系统呢?这就涉及到一段比较长的科学历史,总之,FAT16 文件系统是由微软公司自主研发的一款……(后面忘了)
FAT16 文件系统由以下几个部分组成:引导扇区、FAT 表、根目录区以及数据区。其中,引导扇区就是单独的一个扇区;FAT 表共两份,互为备份,各占 32 个扇区;根目录区占 32 个扇区;数据区占据剩余部分。FAT 表和数据区我们放在下一节来讲,本节我们只处理引导扇区和根目录区。
引导扇区的结构和前面的图 2-1 完全一致,在这里重新放一遍:

(图 18-1 FAT12/16 引导扇区结构)
它对应的代码如代码 18-1 所示:
代码 18-1 FAT16 引导扇区结构(include/file.h)
typedef struct FAT_BPB_HEADER {
unsigned char BS_jmpBoot[3];
unsigned char BS_OEMName[8];
unsigned short BPB_BytsPerSec;
unsigned char BPB_SecPerClust;
unsigned short BPB_RsvdSecCnt;
unsigned char BPB_NumFATs;
unsigned short BPB_RootEntCnt;
unsigned short BPB_TotSec16;
unsigned char BPB_Media;
unsigned short BPB_FATSz16;
unsigned short BPB_SecPerTrk;
unsigned short BPB_NumHeads;
unsigned int BPB_HiddSec;
unsigned int BPB_TotSec32;
unsigned char BS_DrvNum;
unsigned char BS_Reserved1;
unsigned char BS_BootSig;
unsigned int BS_VolID;
unsigned char BS_VolLab[11];
unsigned char BS_FileSysType[8];
unsigned char BS_BootCode[448];
unsigned short BS_BootEndSig;
} __attribute__((packed)) bpb_hdr_t;
想要创建一个 FAT16 文件系统,需要把 BPB 的内容依照上面的格式填入,同时还要初始化 FAT 表——在目前的语境下,相当于向两个扇区处分别写入 4 个字节,具体是什么后面再说。
注意到,BPB 中有成员 BPB_TotSecXX,这就需要我们对硬盘的总扇区个数进行考察。可以通过向硬盘发送 IDENTIFY 命令来获取硬盘相关信息,具体步骤如下:
1.等待上一步可能存在的硬盘操作完成。
2.向0x1f6寄存器写入0x00,0x1f7寄存器写入0xec。
3.等待硬盘操作完成。
4.从0x1f0寄存器读取 512 字节的硬盘信息。
5.从硬盘信息中收集硬盘总扇区数。
详细代码如代码 18-2:
代码 18-2 获取硬盘扇区数(drivers/hd.c)
static int hd_size_cache = 0;
int get_hd_sects()
{
if (hd_size_cache) return hd_size_cache;
while (inb(0x1f7) & 0x80); // 等硬盘不忙了再发送命令,具体意义见wait_disk_ready
outw(0x1f6, 0x00);
outw(0x1f7, 0xec); // IDENTIFY 命令
wait_disk_ready();
uint16_t *hdinfo = (uint16_t *) kmalloc(512);
char *buffer = (char *) hdinfo;
for (int i = 0; i < 256; i++) {
// 每次硬盘会发送2个字节数据
uint16_t data = inw(0x1f0);
*((uint16_t *) buffer) = data; // 存入buf
buffer += 2;
}
int sectors = ((int) hdinfo[61] << 16) + hdinfo[60];
kfree(hd_info);
return (hd_size_cache = sectors);
}
由于硬盘操作可能比较耗时,这里存了一个 hd_size_cache,在第一次调用后就直接引用这里面的数据而不再向硬盘发命令了。由于用到了 kmalloc,记得在开头添加 #include "memory.h"。
那么,新建 fs 目录,并新建 fat16.c 和 file.c,由于出现了新目录,所以贴一下新 Makefile:
代码 18-3 新 Makefile(Makefile)
OBJS = out/kernel.o out/common.o out/monitor.o out/main.o out/gdtidt.o out/nasmfunc.o out/isr.o out/interrupt.o \
out/string.o out/timer.o out/memory.o out/mtask.o out/keyboard.o out/keymap.o out/fifo.o out/syscall.o out/syscall_impl.o \
out/stdio.o out/kstdio.o out/shell.o out/hd.o out/fat16.o out/cmos.o out/file.o
out/%.o : kernel/%.c
i686-elf-gcc -c -I include -O0 -fno-builtin -fno-stack-protector -o out/$*.o kernel/$*.c
out/%.o : kernel/%.asm
nasm -f elf -o out/$*.o kernel/$*.asm
out/%.o : lib/%.c
i686-elf-gcc -c -I include -O0 -fno-builtin -fno-stack-protector -o out/$*.o lib/$*.c
out/%.o : lib/%.asm
nasm -f elf -o out/$*.o lib/$*.asm
out/%.o : drivers/%.c
i686-elf-gcc -c -I include -O0 -fno-builtin -fno-stack-protector -o out/$*.o drivers/$*.c
out/%.o : drivers/%.asm
nasm -f elf -o out/$*.o drivers/$*.asm
out/%.o : fs/%.c
i686-elf-gcc -c -I include -O0 -fno-builtin -fno-stack-protector -o out/$*.o fs/$*.c
out/%.o : fs/%.asm
nasm -f elf -o out/$*.o fs/$*.asm
out/%.bin : boot/%.asm
nasm -I boot/include -o out/$*.bin boot/$*.asm
out/kernel.bin : $(OBJS)
i686-elf-ld -s -Ttext 0x100000 -o out/kernel.bin $(OBJS)
a.img : out/boot.bin out/loader.bin out/kernel.bin
dd if=out/boot.bin of=a.img bs=512 count=1
edimg imgin:a.img copy from:out/loader.bin to:@: copy from:out/kernel.bin to:@: imgout:a.img
run : a.img
qemu-system-i386 -fda a.img -hda hd.img -boot a
clean :
cmd /c del /f /s /q out
default : clean run
最下面我悄悄补了两条指令:clean 和 default,clean 用于把 out 当中的一切全部删除,default 则是先删后跑一步到位。
格式化文件系统也是相↑当↓公↑式→的操作,所以直接在下面贴代码了,具体细节会在代码里标注出来。
代码 18-4 创建 FAT16 文件系统(fs/fat16.c)
#include "hd.h"
#include "memory.h"
#include "file.h"
#include "cmos.h"
// 格式化文件系统
int fat16_format_hd()
{
static unsigned char default_boot_code[] = {
0x8c, 0xc8, 0x8e, 0xd8, 0x8e, 0xc0, 0xb8, 0x00, 0x06, 0xbb, 0x00, 0x07, 0xb9, 0x00, 0x00, 0xba,
0x4f, 0x18, 0xcd, 0x10, 0xb6, 0x00, 0xe8, 0x02, 0x00, 0xeb, 0xfe, 0xb8, 0x6c, 0x7c, 0x89, 0xc5,
0xb9, 0x2a, 0x00, 0xb8, 0x01, 0x13, 0xbb, 0x07, 0x00, 0xb2, 0x00, 0xcd, 0x10, 0xc3, 0x46, 0x41,
0x54, 0x41, 0x4c, 0x3a, 0x20, 0x6e, 0x6f, 0x74, 0x20, 0x61, 0x20, 0x62, 0x6f, 0x6f, 0x74, 0x61,
0x62, 0x6c, 0x65, 0x20, 0x64, 0x69, 0x73, 0x6b, 0x2e, 0x20, 0x53, 0x79, 0x73, 0x74, 0x65, 0x6d,
0x20, 0x68, 0x61, 0x6c, 0x74, 0x65, 0x64, 0x2e, 0x00, 0x00
}; // 这段代码的意思是:输出一段信息,是用nasm写完编译的
char *fat1 = (char *) kmalloc(512);
hd_read(FAT1_START_LBA, 1, fat1); // 读取FAT表第一个扇区
if (fat1[0] == 0xff) { // 如果第一个字节是0xff,那就是有文件系统
kfree(fat1);
return 1; // 那就没有必要格式化了
}
kfree(fat1);
int sectors = get_hd_sects(); // 获取硬盘扇区大小先存着
bpb_hdr_t hdr; // 构造一个引导扇区
hdr.BS_jmpBoot[0] = 0xeb;
hdr.BS_jmpBoot[1] = 0x3c; // jmp到default_boot_code
hdr.BS_jmpBoot[2] = 0x90; // nop凑够3字节
strcpy(hdr.BS_OEMName, "TUTORIAL"); // OEM为tutorial
hdr.BPB_BytsPerSec = 512;
hdr.BPB_SecPerClust = 1;
hdr.BPB_RsvdSecCnt = 1;
hdr.BPB_NumFATs = 2; // 总共两个FAT,这是规定
hdr.BPB_RootEntCnt = 512; // 根目录区32个扇区,一个目录项占32字节,32*512/32=512
if (sectors < (1 << 16) - 1) {
hdr.BPB_TotSec16 = sectors;
hdr.BPB_TotSec32 = 0;
} else {
hdr.BPB_TotSec16 = 0;
hdr.BPB_TotSec32 = sectors;
}
hdr.BPB_Media = 0xf8; // 硬盘统一数据
hdr.BPB_FATSz16 = 32; // FAT16是这样的
hdr.BPB_SecPerTrk = 63; // 硬盘统一数据
hdr.BPB_NumHeads = 16; // 硬盘统一数据
hdr.BPB_HiddSec = 0;
hdr.BS_DrvNum = 0x80; // 硬盘统一数据
hdr.BS_Reserved1 = 0;
hdr.BS_BootSig = 0x29;
hdr.BS_VolID = 0;
strcpy(hdr.BS_VolLab, "FOOLISHABBY"); // 可以随便改
strcpy(hdr.BS_FileSysType, "FAT16 "); // 尽量别改
memset(hdr.BS_BootCode, 0, 448);
memcpy(hdr.BS_BootCode, default_boot_code, sizeof(default_boot_code));
hdr.BS_BootEndSig = 0xaa55;
hd_write(0, 1, &hdr); // 引导扇区就这样了
char initial_fat[512] = {0xff, 0xf8, 0xff, 0xff, 0}; // 硬盘统一数据
hd_write(FAT1_START_LBA, 1, &initial_fat); // 写入FAT1
hd_write(FAT1_START_LBA + FAT1_SECTORS, 1, &initial_fat); // 写入FAT2
return 0;
}
在上面的代码中,出现了相当多的常量,它们被统一定义在 include/file.h 中:
代码 18-5 FAT16 文件系统相关常量(include/file.h)
#ifndef _FILE_H_
#define _FILE_H_
#include "common.h"
typedef struct FILEINFO {
uint8_t name[8], ext[3];
uint8_t type, reserved[10];
uint16_t time, date, clustno;
uint32_t size;
} __attribute__((packed)) fileinfo_t;
typedef struct FAT_BPB_HEADER {
unsigned char BS_jmpBoot[3];
unsigned char BS_OEMName[8];
unsigned short BPB_BytsPerSec;
unsigned char BPB_SecPerClust;
unsigned short BPB_RsvdSecCnt;
unsigned char BPB_NumFATs;
unsigned short BPB_RootEntCnt;
unsigned short BPB_TotSec16;
unsigned char BPB_Media;
unsigned short BPB_FATSz16;
unsigned short BPB_SecPerTrk;
unsigned short BPB_NumHeads;
unsigned int BPB_HiddSec;
unsigned int BPB_TotSec32;
unsigned char BS_DrvNum;
unsigned char BS_Reserved1;
unsigned char BS_BootSig;
unsigned int BS_VolID;
unsigned char BS_VolLab[11];
unsigned char BS_FileSysType[8];
unsigned char BS_BootCode[448];
unsigned short BS_BootEndSig;
} __attribute__((packed)) bpb_hdr_t;
#define SECTOR_SIZE 512
#define FAT1_SECTORS 32
#define ROOT_DIR_SECTORS 32
#define FAT1_START_LBA 1
#define ROOT_DIR_START_LBA 65
#define DATA_START_LBA 97
#define SECTOR_CLUSTER_BALANCE (DATA_START_LBA - 2)
#define MAX_FILE_NUM 512
#endif
这其中有一些常量,留待下一节处理,先放着不管。
按照上面的方法,应该就可以格式化出一个 FAT16 文件系统了。下面我们进行测试。
首先,在命令行输入 ftimgcreate hd.img -t hd -size 80,重新创建虚拟硬盘 hd.img:

(图 18-1 测试步骤1)
然后,调用 ftls hd.img -l,确认 hd.img 中不存在 FAT16 文件系统:

(图 18-2 测试步骤2)
在 main.c 中添加 fat16_format_hd(),编译,运行,等待 10 秒后,再次 ftls hd.img -l,确认文件系统已经存在:

(图 18-3 测试步骤3)
文件系统已经成功创建,说明我们的格式化函数已经完成。接下来,就可以开始进行创建文件和打开文件的操作了。
目前而言,创建文件和打开文件都只需要操作根目录区即可完成。根目录区中,一个文件对应的信息为 32 个字节,具体代码如下所示:
代码 18-6 根目录区中的文件信息(include/file.h)
typedef struct FILEINFO {
uint8_t name[8], ext[3]; // 文件名,扩展名
uint8_t type, reserved[10]; // 类型,预留
uint16_t time, date, clustno; // 修改日期,修改时间,首簇号(下一节再讲)
uint32_t size; // 文件大小
} __attribute__((packed)) fileinfo_t;
不难发现,微软在设计时显然考虑地不多,一个文件最多只能有 8 个字符作为文件名、3 个字符作为扩展名,我们称之为 8.3 文件名。事实上,微软对此有解决方案,名为长文件名(LFN),然而实现上要考虑的细节太多,所以干脆不管。
那么,首先要考虑的就是怎样把一个文件名转化为一个合法的 8.3 文件名。在转化时,要求文件名除了大小写字母、数字外,其他字符都将被替换为下划线,小写字母将会自动转为大写字母,并且在第一个字节为 0xe5 时要自动替换为 0x05。这样的工作十分繁杂,我们选择直接修改 myfattools 中的 lfn2sfn 函数(有开源抄就是好):
代码 18-7 文件名转 8.3(fs/fat16.c)
// 把原文件名改编为FAT16所要求的8.3格式
int lfn2sfn(const char *lfn, char *sfn)
{
int len = strlen(lfn), last_dot = -1;
for (int i = len - 1; i >= 0; i--) { // 从尾到头遍历,寻找最后一个.的位置
if (lfn[i] == '.') { // 找到了
last_dot = i; // 最后一个.赋值一下
break; // 跳出循环
}
}
if (last_dot == -1) last_dot = len; // 没有扩展名,那就在最后虚空加个.
if (lfn[0] == '.') return -1; // 首字符是.,不支持
int len_name = last_dot, len_ext = len - 1 - last_dot; // 计算文件名与扩展名各自有多长
if (len_name > 8) return -1; // 文件名长于8个字符,不支持
if (len_ext > 3) return -1; // 扩展名长于3个字符,不支持
// 事实上FAT对此有解决方案,称为长文件名(LFN),但实现较为复杂,暂时先不讨论
char *name = (char *) malloc(10); // 多分配点内存
char *ext = NULL; // ext不一定有
if (len_ext > 0) ext = (char *) malloc(5); // 有扩展名,分配内存
memcpy(name, lfn, len_name); // 把name从lfn中拷出来
if (ext) memcpy(ext, lfn + last_dot + 1, len_ext); // 把ext从lfn中拷出来
if (name[0] == 0xe5) name[0] = 0x05; // 如果第一个字节恰好是0xe5(已删除),将其更换为0x05
for (int i = 0; i < len_name; i++) { // 处理文件名
if (name[i] == '.') return -1; // 文件名中含有.,不支持
if ((name[i] >= 'a' && name[i] <= 'z') || (name[i] >= 'A' && name[i] <= 'Z') || (name[i] >= '0' && name[i] <= '9')) sfn[i] = name[i]; // 数字或字母留为原样
else sfn[i] = '_'; // 其余字符变为下划线
if (sfn[i] >= 'a' && sfn[i] <= 'z') sfn[i] -= 0x20; // 小写变大写
}
for (int i = len_name; i < 8; i++) sfn[i] = ' '; // 用空格填充剩余部分
for (int i = 0; i < len_ext; i++) { // 处理扩展名
if ((ext[i] >= 'a' && ext[i] <= 'z') || (ext[i] >= 'A' && name[i] <= 'Z') || (ext[i] >= '0' && ext[i] <= '9')) sfn[i + 8] = ext[i]; // 数字或字母留为原样
else sfn[i + 8] = '_'; // 其余字符变为下划线
if (sfn[i + 8] >= 'a' && sfn[i + 8] <= 'z') sfn[i + 8] -= 0x20; // 小写变大写
}
if (len_ext > 0) {
for (int i = len_ext; i < 3; i++) sfn[i + 8] = ' '; // 用空格填充剩余部分
} else {
for (int i = 0; i < 3; i++) sfn[i + 8] = ' '; // 用空格填充剩余部分
}
sfn[11] = 0; // 文件名的结尾加一个\0
return 0; // 正常退出
}
具体细节详细参见注释。
在此之前,我们先来读取一下根目录区的所有文件练练手。如果你忘了根目录区的大小和起点的话,没有关系,file.h 的宏定义已经定义好了:
代码 18-8 读取根目录所有文件 read_dir_entries(drivers/fat16.c)
// 读取根目录目录项
fileinfo_t *read_dir_entries(int *dir_ents)
{
fileinfo_t *root_dir = (fileinfo_t *) kmalloc(ROOT_DIR_SECTORS * SECTOR_SIZE);
hd_read(ROOT_DIR_START_LBA, ROOT_DIR_SECTORS, root_dir); // 将根目录的所有扇区全部读入
int i;
for (i = 0; i < MAX_FILE_NUM; i++) {
if (root_dir[i].name[0] == 0) break; // 如果名字的第一个字节是0,那就说明这里没有文件
}
*dir_ents = i; // 将目录项个数写到指针里
return root_dir; // 返回根目录
}
使用的时候,我们的调用方法和 scanf 很像:
代码 18-9 read_dir_entries 测试(kernel/main.c)
int entries;
fileinfo_t *root_dir = read_dir_entries(&entries); // 用这两行替换掉 fat16_format_hd();
作为测试,我们来新建一个文件 ilovehon.kai(没什么别的意思,名字你可以随便换,但必须遵循上面提到的 8.3 文件名规则),并填充 512 个 A 和 512 个 B(同样只是测试,内容也可以随便换):

(图 18-4 创建文件)
用 ftcopy 命令将文件写入虚拟硬盘 hd.img:

(图 18-5 写入虚拟硬盘,这里用 ftls 确认写入成功)
扩写上面的测试代码:
代码 18-10 一个啥都没有的 ls(kernel/main.c)
for (int i = 0; i < entries; i++) printk("%s\n", root_dir[i].name);
kfree(root_dir); // 前面read的时候用的malloc分配,这里用free释放
为什么不需要再 printk 一遍 ext 呢?这是因为 name 和 ext 之间并没有一个明确的 \0 作为分界,printk 在输出 name 的同时就会输出 ext。
编译,运行,效果如下:

(图 18-6 输出的文件名)
注意到,将 ilovehon.kai 手工转化为 8.3 文件名也为 ILOVEHONKAI,因此可知 read_dir_entries 实现成功。
下面就可以正式开始创建文件的操作了。想要创建一个文件,和格式化出一个文件系统是类似的,只需要把 fileinfo_t 结构体当中的各个成员分别填写好就可以。
目前来看,我们总共需要填入的东西里已经有些可以完成或忽略:填入 name 和 ext 的过程已经由 lfn2sfn 实现了;而 type 只需要填上 0x20,reserved、clustno 和 size 都设置为 0 即可。那么,就只剩下 time 和 date 了。
微软对 time 和 date 的编码如下:
time:低 5 位为秒,中 6 位为分,高 5 位为时;
date:低 5 位为日,中 4 位为月,高 7 位为年。其中,年份要减去 1980,意义不明。
在上一节的基础设施建设部分,我们已经完成了 RTC,可以畅通无阻地获取目前的时间。那么,实现文件创建的基本条件已经成熟,直接开写:
代码 18-11 创建文件(fs/fat16.c)
// 创建文件
int fat16_create_file(fileinfo_t *finfo, char *filename)
{
if (filename[0] == 0xe5) filename[0] = 0x05; // 如上,若第一个字节为 0xe5,需要更换为 0x05
char sfn[20] = {0};
int ret = lfn2sfn(filename, sfn); // 将文件名转换为8.3文件名
if (ret) return -1; // 文件名不符合8.3规范,返回
int entries;
fileinfo_t *root_dir = read_dir_entries(&entries); // 读取所有根目录项
int free_slot = entries; // 默认的空闲位置是最后一个
for (int i = 0; i < entries; i++) {
if (!memcmp(root_dir[i].name, sfn, 8) && !memcmp(root_dir[i].ext, sfn + 8, 3)) { // 文件名和扩展名都一样
kfree(root_dir); // 已经有了就不用创建了
return -1;
}
if (root_dir[i].name[0] == 0xe5) { // 已经删除(文件名第一个字节是0xe5)
free_slot = i; // 那就把这里当成空闲位置
break;
}
}
if (free_slot == MAX_FILE_NUM) { // 如果空闲位置已经到达根目录末尾
kfree(root_dir); // 没地方创建也就不用创建了
return -1;
}
// 开始填入fileinfo_t对应的项
memcpy(root_dir[free_slot].name, sfn, 8); // sfn为name与ext的合体,前8个字节是name
memcpy(root_dir[free_slot].ext, sfn + 8, 3); // 后3个字节是ext
root_dir[free_slot].type = 0x20; // 类型为0x20(正常文件)
root_dir[free_slot].clustno = 0; // 没有内容,所以没有簇号(同样放在下一节讲)
root_dir[free_slot].size = 0; // 没有内容,所以大小为0
memset(root_dir[free_slot].reserved, 0, 10); // 将预留部分全部设为0
current_time_t ctime;
get_current_time(&ctime); // 获取当前时间
// 按照前文所说依次填入date和time
root_dir[free_slot].date = ((ctime.year - 1980) << 9) | (ctime.month << 5) | ctime.day;
root_dir[free_slot].time = (ctime.hour << 11) | (ctime.min << 5) | ctime.sec;
if (finfo) *finfo = root_dir[free_slot]; // 创建完了不能不管,传给finfo留着
hd_write(ROOT_DIR_START_LBA, ROOT_DIR_SECTORS, root_dir); // 将新的根目录区写回硬盘
kfree(root_dir); // 成功完成
return 0;
}
具体细节都放在代码中了,寻找空余位置和判断文件是否存在的代码反而占了大多数,真正创建文件的代码只有最后的那十几行。
最后是打开文件,我们只需要根据文件名找到对应的 fileinfo_t 返回就可以了。
代码 18-12 打开文件(fs/fat16.c)
// 打开文件
int fat16_open_file(fileinfo_t *finfo, char *filename)
{
char sfn[20] = {0};
int ret = lfn2sfn(filename, sfn); // 将原文件名转换为8.3
if (ret) return -1; // 转换失败,不用打开了
int entries;
fileinfo_t *root_dir = read_dir_entries(&entries); // 读取所有目录项
int file_index = entries; // filename对应文件的索引
for (int i = 0; i < entries; i++) {
if (!memcmp(root_dir[i].name, sfn, 8) && !memcmp(root_dir[i].ext, sfn + 8, 3)) {
file_index = i; // 找到了
break;
}
}
if (file_index < entries) { // 如果找到了……
*finfo = root_dir[file_index]; // 那么把对应的文件存到finfo里
kfree(root_dir);
return 0;
}
else {
finfo = NULL; // 这一句实际上是没有用的
kfree(root_dir);
return -1;
}
}
最后就是喜闻乐见(非常傻逼)的测试环节。打开文件配合后面的读取和写入测试效果更佳,所以这里单独测试创建文件。
将刚才写的测试 read_dir_entries 的代码替换为:
代码 18-13 创建文件测试(kernel/main.c)
printk("create status: %d\n", fat16_create_file(NULL, "iloveado.fai"));
编译,运行,效果应如图所示:

(图 18-6 创建文件疑似成功)
在命令行中使用 ftls 工具,确认文件已经成功创建:

(图 18-7 创建文件成功)
好了,那么这一节作为我们实现 FAT16 的第一战,显然效果非常成功。下一节我们来实现文件的读取、写入和删除,从而为后续的包装打好地基。
19.实现FAT16文件系统(3)——读取文件、写入文件、删除文件
在实现文件的读取、写入和删除之前,首先还需要了解两个在上一节被刻意忽略掉的概念:FAT 表以及簇。
数据区你远看它是一整块,但是近看它被分割成了一个个的扇区,每一个扇区都还有另一个名字,这就是簇。而 FAT 表,就是簇的索引,每一个 FAT 项的位置实际上都是一个簇的编号,简称簇号。在 FAT16 文件系统中,一个 FAT 项占据 16 位,这也是这个文件系统名字的由来。
每一个 FAT 项所在的位置都对应着一个簇号,而这个 FAT 项中存放的数据,则是这个文件数据的下一个簇的所在位置。这个逻辑有点像链表:首先从文件的 clustno 属性获取第一个簇的位置,然后读取第一个簇的簇号所在的 FAT 项获取下一个簇的位置,以此类推。据规定,在 FAT16 文件系统中,若一个簇号对应的 FAT 项的值大于等于 0xFFF8,那么说明文件结束。一般而言,大多数实现都采用 0xffff 作为文件结束标志。
然而,为了软件识别的需要,微软官方直接把前两个 FAT 项砍了,并规定:数据区的第一个簇的簇号为 2,往后依次类推。这意味着,在读写簇内容的时候还需要手动减 2,才能读到正确的扇区。
那么,我们来写一个读写 FAT 项的函数。虽说没有类,做不到模拟数组操作,但是能接近还是接近一下:
代码 19-1 读写 FAT 项(fs/fat16.c)
// 获取第n个FAT项
static uint16_t get_nth_fat(uint16_t n)
{
uint8_t *fat = (uint8_t *) kmalloc(512); // 分配临时FAT内存
uint32_t fat_start = FAT1_START_LBA; // 默认从FAT1中读取FAT
uint32_t fat_offset = n * 2; // FAT项在FAT表内的偏移,FAT16一个FAT是16位,即2个字节,所以乘2
uint32_t fat_sect = fat_start + (fat_offset / 512); // 该FAT项对应的扇区编号
uint32_t sect_offset = fat_offset % 512; // 该FAT项在扇区内的偏移
hd_read(fat_sect, 1, fat); // 读取对应的一个扇区到FAT内(由于*2,FAT项必然不跨扇区)
uint16_t table_val = *(uint16_t *) &fat[sect_offset]; // 从FAT表中找到对应的FAT项
kfree(fat); // 临时FAT表就用不上了
return table_val; // 返回对应的FAT项
}
// 设置第n个FAT项
static void set_nth_fat(uint16_t n, uint16_t val)
{
int fat_start = FAT1_START_LBA; // FAT1起始扇区
int second_fat_start = FAT1_START_LBA + FAT1_SECTORS; // FAT2起始扇区
uint8_t *fat = (uint8_t *) kmalloc(512); // 临时FAT表
uint32_t fat_offset = n * 2; // FAT项在FAT表内的偏移
uint32_t fat_sect = fat_start + (fat_offset / 512); // FAT项在FAT1中对应的扇区号
uint32_t second_fat_sect = second_fat_start + (fat_offset / 512); // FAT项在FAT2中对应的扇区号
uint32_t sect_offset = fat_offset % 512; // FAT项在扇区内的偏移
hd_read(fat_sect, 1, fat); // 读入到临时FAT表
*(uint16_t *) &fat[sect_offset] = val; // 直接设置对应的FAT项即可,FAT16没有那么多弯弯绕
hd_write(fat_sect, 1, fat); // 写入FAT1
hd_write(second_fat_sect, 1, fat); // 写入FAT2
kfree(fat); // 释放临时FAT表
}
具体细节仍旧写在了注释里。具体而言,为了节省硬盘 IO 的时间(虽然读取根目录疑似也是 32 个扇区),所以在读取 FAT 项时,只读取要读的 FAT 项所在的那个扇区。由于一个 FAT 项占两个字节,所以第 n 个 FAT 项就位于到 FAT 表开始的第 2n 个字节,随后就可以计算扇区数和扇区内的偏移量了。
接下来就是给出簇号,读写对应的簇的函数了:
代码 19-2 读写一个簇(fs/fat16.c)
// 读取第n个clust
static void read_nth_clust(uint16_t n, void *clust)
{
hd_read(n + SECTOR_CLUSTER_BALANCE, 1, clust);
}
// 写入第n个clust
static void write_nth_clust(uint16_t n, const void *clust)
{
hd_write(n + SECTOR_CLUSTER_BALANCE, 1, (void *) clust);
}
其中 SECTOR_CLUSTER_BALANCE 定义于 include/file.h,其值为 DATA_START_LBA - 2。具体原因,是因为簇号要减去 2 才是数据区中的扇区编号,所以在把簇号加上数据区以找到对应扇区的同时,还要再减去 2 以找到正确的位置。
有了读取 FAT 项和读取一个簇的手段,实现读取文件几乎是水到渠成的,其具体操作如下:
1.根据打开的 fileinfo_t 找到第一个簇号。
2.读取第一个簇到缓冲区。
3.读取该簇号对应的 FAT 项,找到该文件下一个簇的簇号。
4.若该 FAT 项大于等于0xfff8,则文件结束,终止循环。
5.假装下一个簇是第一个簇,重复 2~5。
将上面的思路化为代码,就得到了:
代码 19-3 读取文件(fs/fat16.c)
// 读取文件,当然要有素质地一次读整个文件啦
int fat16_read_file(fileinfo_t *finfo, void *buf)
{
uint16_t clustno = finfo->clustno; // finfo中记录的第一个簇号
char *clust = (char *) kmalloc(512); // 单独给簇分配一个缓冲区,直接往buf里写也行
do {
read_nth_clust(clustno, clust); // 将该簇号对应的簇读取进来
memcpy(buf, clust, 512); // 拷贝入buf
buf += 512; // buf后推一个扇区
clustno = get_nth_fat(clustno); // 获取下一个簇号
if (clustno >= 0xFFF8) break; // 文件结束,退出循环
} while (1);
kfree(clust); // 读完了,释放临时缓冲区
return 0; // 返回
}
如你所见,这个读取文件的函数非常之短,甚至比前面的创建和打开还短,只有 15 行,和读写 FAT 的单个函数差不多长。这就是 FAT16 的简单之处。
作为测试,上一节我们写入了文件 ilovehon.kai,现在是时候同时对打开文件和读取文件进行一次测试了。替换掉上一节的创建文件测试代码,编写测试代码如下:
代码 19-4 读取测试(fs/fat16.c)
fileinfo_t finfo;
int status = fat16_open_file(&finfo, "ilovehon.kai"); // 打开文件 ilovehon.kai
printk("open status: %d\n", status);
if (status == -1) while (1); // 若打开失败就不用读了
char *buf = (char *) kmalloc(finfo.size + 5);
status = fat16_read_file(&finfo, buf);
printk("read status: %d\nfile content: %s\n", status, buf);
kfree(buf);

(图 19-1 读取成功,这里显示的应当是上一节填充的测试内容)
一刻也没有为读取文件的迅速结束而哀悼,立刻赶到战场的是——删除文件!
想要删除一个文件,并不需要把文件的所有内容都随机 01 啦、设成 0 或 1 啦这些,非常简单,你只需要让这个文件无法被找到就可以了。
这里总算可以填上前面挖的一个坑了:
并且在第一个字节为 0xe5 时要自动替换为 0x05
这是为什么呢?正是因为在 FAT 文件系统中,第一个字节为 0xe5 的文件被视为“已经删除”,所以才要特意和谐一下。
那么,既然这样就相当于在根目录区里消失了,数据区的簇又可以赖着,一个文件所剩的资源就只有 FAT 项了。事实上,在删除一个文件时,它所在的 FAT 项也要全部设置为 0。
只要注意这两点,那么实现删除文件也就相当简单:
代码 19-5 删除文件(fs/fat16.c)
// 删除文件
int fat16_delete_file(char *filename) // 什么?为什么不传finfo?删除一个已经打开的文件,听上去很别扭不是吗(虽然在Linux下这很正常)
{
char sfn[20] = {0};
int ret = lfn2sfn(filename, sfn); // 将文件名转换为8.3文件名
if (ret) return -1;
int entries;
fileinfo_t *root_dir = read_dir_entries(&entries); // 读取根目录
int file_ind = -1;
for (int i = 0; i < entries; i++) {
if (!memcmp(root_dir[i].name, sfn, 8) && !memcmp(root_dir[i].ext, sfn + 8, 3)) {
file_ind = i; // 找到对应文件了
break;
}
}
if (file_ind == -1) { // 没有找到
kfree(root_dir); // 不用删了
return -1;
}
root_dir[file_ind].name[0] = 0xe5; // 标记为已删除
hd_write(ROOT_DIR_START_LBA, ROOT_DIR_SECTORS, root_dir); // 更新根目录区数据
kfree(root_dir); // 释放临时缓冲区
if (root_dir[file_ind].clustno == 0) {
return 0; // 内容空空,那就到这里就可以了
}
unsigned short clustno = root_dir[file_ind].clustno, next_clustno; // 开始清理文件所占有的簇
while (1) {
next_clustno = get_nth_fat(clustno); // 找到这个文件下一个簇的簇号
set_nth_fat(clustno, 0); // 把下一个簇的簇号设为0,这样就找不到下一个簇了
if (next_clustno >= 0xfff8) break; // 已经删完了,直接返回
clustno = next_clustno; // 下一个簇设为当前簇
}
return 0; // 删除完成
}
同样,具体细节参见注释。
下面是测试环节。我们在上一节测试创建文件时创建了一个 iloveado.fai 文件,现在我们来删除它。
代码 19-6 删除文件测试(kernel/main.c)
fileinfo_t finfo;
int status = fat16_delete_file("iloveado.fai");
printk("delete status: %d\n", status);
编译,运行,效果如下图所示:

(图 19-2 删除文件疑似成功)
在命令行中调用 ftls,确认删除成功:

(图 19-3 删除成功)
现在,本节最简单的两个操作——读取和删除,已经完成,我们来进攻最后一个据点——写入。只要写入文件完成,后面就都是软件上的事了。
为了简单起见,在写入文件时,只支持将整个文件全部覆盖。相信一些开发经验比较丰富的读者已经要说了:
可是我用过 fseek/lseek,可以在任意位置进行写入呀。
为了简单起见,这些东西我们可以用纯软件来实现,就不麻烦 FAT16 的底层实现了。
实现写入文件主要的问题在于要处理的问题太多,包括但不限于:
- 如果是第一次写入的话,需要分配一个首簇号。
- 可能会出现簇混乱的情况,这种情况下需要再重新找一个新簇。
- 如果写入的部分超出原有的,还是要分配新簇。
- 如果写入的部分少于原有的,需要把原来的簇号释放。
- 需要重新写入当前日期/时间,以及大小等。
对于上面的几个东西,我们来分步解决。这一部分代码的注释非常重要,请认真阅读(?)
首先,针对第一次写入需要分配首簇号的问题,我们添加了一个判断:
代码 19-7 写入文件(1)——为第一次写入的空文件分配簇号(fs/fat16.c)
// 写入文件,为简单起见相当于覆盖了
int fat16_write_file(fileinfo_t *finfo, const void *buf, uint32_t size)
{
uint16_t clustno = finfo->clustno, next_clustno; // 从已有首簇号开始
if (finfo->size == 0 && finfo->clustno == 0) { // 没有首簇号
clustno = 2; // 从第2个簇开始分配
while (1) {
if (get_nth_fat(clustno) == 0) { // 当前簇空闲
finfo->clustno = clustno; // 分配
break; // 已找到空闲簇号
}
clustno++; // 继续寻找下一个簇
}
}
finfo->size = size; // 更新大小
再然后,是写入的主体部分,这里要处理的问题比较复杂。
代码 19-8 写入文件(2)——写入文件主体(fs/fat16.c)
int write_sects = (size + 511) / 512; // 确认要写入的扇区总数,这里向上舍入
while (write_sects) { // 只要还要写
write_nth_clust(clustno, buf); // 将当前buf的512字节写入对应簇中
write_sects--; // 要写入扇区总数-1
buf += 512; // buf后移一个扇区
next_clustno = get_nth_fat(clustno); // 寻找下一个簇
if (next_clustno == 0 || next_clustno >= 0xfff8) {
// 当前簇不可用
next_clustno = clustno + 1; // 从下一个簇开始
while (1) {
if (get_nth_fat(next_clustno) == 0) { // 这个簇是可用的
set_nth_fat(clustno, next_clustno); // 将这个簇当成下一个簇链接上去
break;
} else next_clustno++; // 否则,只好继续了
}
}
clustno = next_clustno; // 将下一个簇看做当前簇
}
最后,是收尾的部分。
代码 19-9 写入文件(3)——扫尾(fs/fat16.c)
// 最后修改一下文件属性
current_time_t ctime;
get_current_time(&ctime); // 获取当前日期
// 更新日期和时间
finfo->date = ((ctime.year - 1980) << 9) | (ctime.month << 5) | ctime.day;
finfo->time = (ctime.hour << 11) | (ctime.min << 5) | ctime.sec;
int entries;
fileinfo_t *root_dir = read_dir_entries(&entries);
for (int i = 0; i < entries; i++) {
if (!memcmp(root_dir[i].name, finfo->name, 8) && !memcmp(root_dir[i].ext, finfo->ext, 3)) {
root_dir[i] = *finfo; // 找到对应的文件,写进根目录
break;
}
}
hd_write(ROOT_DIR_START_LBA, ROOT_DIR_SECTORS, root_dir); // 同步到硬盘
kfree(root_dir);
return 0;
}
比较具体的讲解都已经写在注释当中。
好了,最后还是测试环节。
代码 19-10 写入测试(kernel/main.c)
fileinfo_t finfo;
int status = fat16_create_file(&finfo, "iloveado.fai");
printk("create status: %d\n", status);
char *buf = (char *) kmalloc(512);
strcpy(buf, "I love A Dance Of Fire and Ice!");
status = fat16_write_file(&finfo, buf, strlen(buf));
printk("write status: %d\n", status);
编译,运行,效果如下:

(图 19-4 写入文件疑似成功)
更换上面的测试代码为:
代码 19-11 写入测试II(kernel/main.c)
fileinfo_t finfo;
int status = fat16_open_file(&finfo, "iloveado.fai");
printk("open status: %d\n", status);
char *buf = (char *) kmalloc(512);
status = fat16_read_file(&finfo, buf);
printk("read status: %d\nfile content: %s\n", status, buf);
再次编译运行,效果如下:

(图 19-5 写入文件成功)
至此,我们已经彻底完成了 FAT16 的底层实现,下一章,我们来彻底完成文件系统的制作,实现用户可以使用的一套系统调用。
20.实现FAT16文件系统(4)——上层包装
本节是实现 FAT16 的最后一个小节,我们将实现一套可供用户使用的系统调用,包括 open、read、write、unlink 以及 lseek。有了这五个函数,我们就可以任意地进行文件读写以及对文件进行删除和创建。
本节代码极大程度上参照了《操作系统真象还原》以及 PlantOS 的代码,因此在细节上可能有所欠缺,请见谅。
首先,如同多任务一样,直接把 fileinfo_t 当作一个文件的底层抽象是相当不合适的:由于 fileinfo_t 与硬件强相关,所以后期将难以扩展。
所以,最终,经过包装,我们创建了一个 file_t 结构体,用于表示一个抽象的文件的概念。
代码 20-1 文件的底层抽象(include/file.h)
typedef enum FILE_TYPE {
FT_USABLE,
FT_REGULAR,
FT_UNKNOWN
} file_type_t;
typedef enum oflags {
O_RDONLY,
O_WRONLY,
O_RDWR,
O_CREAT = 4
} oflags_t;
typedef struct FILE_STRUCT {
void *handle;
void *buffer;
int pos;
int size;
int open_cnt;
file_type_t type;
oflags_t flags;
} file_t;
由于完全不打算实现目录,所以在 file_type_t 里,只有 FT_REGULAR 一种正常值,剩下两个一个用于判断文件是否已被占用,另一个则没什么用。
至于 O_RDONLY 这些,则是一个简单的判断读写的小机制,这样可以创建只读以及只写的文件,虽然这没什么用吧。
再往下的 file_t 可以说是十分灵活,我们甚至没有限制 handle 必须是 fileinfo_t,你往里面塞什么牛鬼蛇神都行,只要你能在后面的 read 这些地方圆回来。
这个 buffer 具体的用处到后面 read 和 write 时再讲。
下面的 pos 则是代表文件的读写位置,lseek 移动的就是它。
最后的 open_cnt 暂时没用,大概到了下一节或者最后一节才会有用。
下面是一些小小的改动:实际上,打开文件的操作是由任务执行的,所以至少在任务的层面,应该对文件给予一些支持。
代码 20-2 新版 task_t 结构体(include/mtask.h)
#define MAX_FILE_OPEN_PER_TASK 32
typedef struct TASK {
uint32_t sel;
int32_t flags;
exit_retval_t my_retval;
int fd_table[MAX_FILE_OPEN_PER_TASK]; // here
tss32_t tss;
} task_t;
与 Linux 0.01 不同的是,这里并未直接存储 file_t,而是存储了一个 int,它代表对应的 file_t 在一个文件表中的索引。这么做的目的是节省空间,以及可能带来的更高氨醛性——毕竟理论上可以顺着 malloc(虽然还没实现)找到 task_t 来给文件一锅端了(确信)。
这个数组需要在 task_alloc 时进行初始化:
代码 20-3 初始化任务中的文件描述符表(kernel/mtask.c)
task->fd_table[0] = 0; // 标准输入,占位
task->fd_table[1] = 1; // 标准输出,占位
task->fd_table[2] = 2; // 标准错误,占位
for (int i = 3; i < MAX_FILE_OPEN_PER_TASK; i++) {
task->fd_table[i] = -1; // 其余文件均可用
}
然后,在 fs/file.c 中,我们来添加这个文件表:
代码 20-4 创建文件表(fs/file.c)
#include "file.h"
#include "mtask.h"
#include "memory.h"
static file_t file_table[MAX_FILE_NUM];
然后我们需要提供一个/一组把 fileinfo_t 转换为 file_t 并安装到当前任务当中的函数,这由下面的 install_to_global 和 install_to_local 实现:
代码 20-5 将 fileinfo_t 安装到任务(fs/file.c)
static int install_to_global(fileinfo_t finfo)
{
int i = MAX_FILE_NUM;
for (i = 0; i < MAX_FILE_NUM; i++) {
if (file_table[i].type == FT_USABLE) break; // 当前文件空闲,则占用
}
if (i == MAX_FILE_NUM) return -1; // 没有文件空闲,则退出
fileinfo_t *safer_finfo = (fileinfo_t *) kmalloc(sizeof(fileinfo_t)); // 分配一个finfo指针,准备挂到handle上
if (!safer_finfo) return -1;
*safer_finfo = finfo; // 装入
file_table[i].handle = safer_finfo; // 这就是其内部的handle
file_table[i].type = FT_REGULAR; // 类型为正常文件
file_table[i].pos = 0; // 由于刚刚注册,pos设为0
return i; // 返回其在文件表内的索引
}
static int install_to_local(int global_fd)
{
task_t *task = task_now(); // 获取当前任务
int i;
for (i = 3; i < MAX_FILE_OPEN_PER_TASK; i++) { // fd 0 1 2分别代表标准输入 标准输出 标准错误,所以从3开始找起
if (task->fd_table[i] == -1) break; // 这里还空着,直接用
}
if (i == MAX_FILE_OPEN_PER_TASK) return -1; // 到达任务可打开的文件上限,返回-1
task->fd_table[i] = global_fd; // 将文件表索引安装到任务的文件描述符表
return i; // 返回索引,这就是对应的文件描述符了
}
有了这两个函数,实现打开文件和创建文件就畅通无阻了。在 Linux 系统中,这两个功能被整合进 open 这一个函数中,这是一个我也说不上好不好的设计,总之我决定模仿。
代码 20-6 open:打开文件、创建文件(fs/file.c)
int sys_open(char *filename, uint32_t flags)
{
fileinfo_t finfo; // 准备接收打开的文件
if (flags & O_CREAT) { // flags中含有O_CREAT,则需要创建文件
int status = fat16_create_file(&finfo, filename); // 调用创建文件的函数
if (status == -1) return status; // 创建失败则直接不管
} else {
int status = fat16_open_file(&finfo, filename); // 调用打开文件的函数
if (status == -1) return status; // 打开失败则直接不管
}
int global_fd = install_to_global(finfo); // 先安装到全局文件表
file_table[global_fd].open_cnt++; // open个数+1,没什么用
file_table[global_fd].size = finfo.size; // 设置文件大小
file_table[global_fd].flags = flags | (~O_CREAT); // flags中剔除O_CREAT
file_table[global_fd].buffer = kmalloc(finfo.size + 5); // 分配一个缓冲区
if (finfo.size) { // 如果有内容
int status = fat16_read_file(&finfo, file_table[global_fd].buffer); // 则直接读到缓冲区里来
if (status == -1) { // 如果读不进缓冲区,那就只好这样了
kfree(file_table[global_fd].handle); // 释放占有的资源
kfree(file_table[global_fd].buffer);
return status;
}
}
return install_to_local(global_fd); // 最后安装到任务里
}
这个缓冲区很快就会在下面的 read 和 write 中用到,由于这两者操作逻辑较为类似,合并到同一个代码块里来:
代码 20-7 read、write:读写文件(fs/fat16.c)
int sys_write(int fd, const void *msg, int len)
{
if (fd <= 0) return -1; // 是无效fd,返回
if (fd == 1 || fd == 2) { // 往标准输出或标准错误中输出
char *s = (char *) msg; // 转换为char *
for (int i = 0; i < len; i++) monitor_put(s[i]); // 直接用monitor_put逐字符输出
return len; // 一切正常
}
task_t *task = task_now(); // 获取当前任务
int global_fd = task->fd_table[fd]; // 获取文件表中索引
file_t *cfile = &file_table[global_fd]; // 获取文件表中的文件指针
if (cfile->flags == O_RDONLY) return -1; // 只读,不可写,返回
for (int i = 0; i < len; i++) { // 对于每一个字节
if (cfile->pos >= cfile->size) { // 如果超出了原本的范围
cfile->size++; // 大小+1
void *new_buffer = krealloc(cfile->buffer, cfile->size); // 使用krealloc扩容,增长缓冲区大小
if (new_buffer) cfile->buffer = new_buffer; // 如果缓冲区分配成功,那么这里就是新的缓冲区
}
char *buf = (char *) cfile->buffer; // 文件的缓冲区,相当于文件的当前内容了
char *content = (char *) msg; // 要写入的内容
buf[cfile->pos] = content[i]; // 向读写指针处写入当前内容
cfile->pos++; // 文件指针后移
}
int status = fat16_write_file(cfile->handle, cfile->buffer, cfile->size); // 写入完毕,立刻更新到硬盘
if (status == -1) return status; // 写入失败,返回
return len; // 否则,返回实际写入的长度len
}
int sys_read(int fd, void *buf, int count)
{
int ret = -1;
if (fd < 0 || fd == 1 || fd == 2) return ret; // 从标准输入/标准错误中读或是fd非法都是不允许的
if (fd == 0) { // 如果是标准输入
char *buffer = (char *) buf; // 先转成char *
uint32_t bytes_read = 0; // 读了多少个
while (bytes_read < count) { // 没达到count个
while (fifo_status(&decoded_key) == 0); // 只要没有新的键我就不读进来
*buffer = fifo_get(&decoded_key); // 获取新的键
bytes_read++;
buffer++; // buffer指向下一个
}
ret = (bytes_read == 0 ? -1 : (int) bytes_read); // 如果啥也没读着就-1,否则就正常返回就行了
return ret;
}
task_t *task = task_now(); // 获取当前任务
int global_fd = task->fd_table[fd]; // 获取fd对应的文件表索引
file_t *cfile = &file_table[global_fd]; // 获取文件表中对应文件
if (cfile->flags == O_WRONLY) return -1; // 只写,不可读,返回-1
ret = 0; // 记录到底读了多少个字节
for (int i = 0; i < count; i++) {
if (cfile->pos >= cfile->size) break; // 如果已经到达末尾,返回
char *filebuf = (char *) cfile->buffer; // 文件缓冲区
char *retbuf = (char *) buf; // 接收缓冲区
retbuf[i] = filebuf[cfile->pos]; // 逐字节拷贝内容
cfile->pos++; // 读写指针后移
ret++; // 读取字节数+1
}
return ret; // 返回读取字节数
}
这里从 sys_write 的实现中就可以知道 buffer 的作用了:在前面读写文件时,我们只实现了覆盖整个文件,想要对文件的特定位置进行修改,只能全部读进来,在软件层面修改后再全部写回去。而且,这样的实现还可以加快 sys_read 的速度,也算是一种奇妙的优化吧。
同时,改完这里以后,原先 kernel/syscall.c 中的 sys_read 和 sys_write 就可以删除了。
扩容用的 krealloc 写在了 kernel/memory.c 中:
代码 20-8 krealloc(kernel/memory.c)
void *krealloc(void *buffer, int size)
{
void *res = NULL;
if (!buffer) return kmalloc(size); // buffer为NULL,则realloc相当于malloc
if (!size) { // size为NULL,则realloc相当于free
kfree(buffer);
return NULL;
}
// 否则实现扩容
res = kmalloc(size); // 分配新的缓冲区
memcpy(res, buffer, size); // 将原缓冲区内容复制过去
kfree(buffer); // 释放原缓冲区
return res; // 返回新缓冲区
}
接下来是关闭文件用的 sys_close,基本上就是对文件使用资源的释放。
代码 20-9 close:关闭文件(fs/file.c)
int sys_close(int fd)
{
int ret = -1; // 返回值
if (fd > 2) { // 的确是被打开的文件
task_t *task = task_now(); // 获取当前任务
uint32_t global_fd = task->fd_table[fd]; // 获取对应文件表索引
task->fd_table[fd] = -1; // 释放文件描述符
file_t *cfile = &file_table[global_fd]; // 获取对应文件
kfree(cfile->buffer); // 释放缓冲区
kfree(cfile->handle); // install_to_global中使用kmalloc分配fileinfo指针
cfile->type = FT_USABLE; // 设置type为可用
return 0; // 关闭完成
}
return ret; // 否则返回-1
}
移动读写指针用的 sys_lseek 纯属软件操作,sys_unlink 则只是 fat16_delete_file 套皮,这里一并放上来。
代码 20-10 lseek、unlink:最后一个部分(fs/file.c)
int sys_lseek(int fd, int offset, uint8_t whence)
{
if (fd < 3) return -1; // 不是被打开的文件,返回
if (whence < 1 || whence > 3) return -1; // whence只能为123,分别对应SET、CUR、END,返回
task_t *task = task_now(); // 获取当前任务
file_t *cfile = &file_table[task->fd_table[fd]]; // 获取fd对应的文件
fileinfo_t *fhandle = (fileinfo_t *) cfile->handle; // 文件实际上对应的fileinfo
int size = fhandle->size; // 获取大小,总归是有用的
int new_pos = 0; // 新的文件位置
switch (whence) {
case SEEK_SET: // SEEK_SET就是纯设置
new_pos = offset; // 直接设置
break;
case SEEK_CUR: // 从当前位置算起移动offset位置
new_pos = cfile->pos + offset; // 用当前pos加上offset
break;
case SEEK_END: // 从结束位置算起移动offset位置
new_pos = size + offset; // 用大小加上offset
break;
}
if (new_pos < 0 || new_pos > size - 1) return -1; // 如果新的位置超出文件,返回-1
cfile->pos = new_pos; // 设置新位置
return new_pos; // 返回新位置
}
int sys_unlink(const char *filename)
{
return fat16_delete_file((char *) filename); // 直接套皮,不多说
}
好,那么到此为止,历时四节,我们的 FAT16 文件系统实现的征程到此结束!鼓掌!
或许有人会觉得:这看上去也不难嘛……那不妨自己查询资料写一个试试哦(
再往下几节,我们来实现应用程序的执行,彻底结束这个破烂不堪的操作系统教程。
21.FAT16 文件系统实战——抛弃软盘,从硬盘启动
本来是想写应用程序的,但是吧,这个问题吧,它这个这个,略微有一些难度,知道吧,所以说先挑比较简单的写。
本节我们要重温第 1-6 节的恐惧,用一节的时间速通一个在硬盘上的引导加载器,然后就可以抛掉现在这个不伦不类的软盘启动,硬盘放数据的框架了。
引导扇区比较好改,先从引导扇区开始吧。和软盘版的引导扇区相比,主要要修改的部分有以下几点:
-
ReadSector要从读取软盘改成读取硬盘。 -
硬盘使用 FAT16 文件系统,所以
GetFATEntry需要同步修改。 -
还是因为 FAT16 文件系统,主循环中判断文件是否结束的条件也要略作修改。
其余的部分均可保持不变。
我们先进入项目根目录,然后新建 boot.asm 和 loader.asm,loader.asm 我们仍旧选择使用第 3-4 节使用的白板 Loader:
代码 21-1 白板 Loader(loader.asm)
org 0100h
mov ax, 0B800h
mov gs, ax ; 将gs设置为0xB800,即文本模式下的显存地址
mov ah, 0Fh ; 显示属性,此处指白色
mov al, 'L' ; 待显示的字符
mov [gs:((80 * 0 + 39) * 2)], ax ; 直接写入显存
jmp $ ; 卡死在此处
将白板 Loader 用 ftcopy 命令写入硬盘:

(图 21-1 具体命令)
在 boot.asm 中粘贴原先软盘版的 boot.asm 的所有内容,并将 load.inc 和 pm.inc 一并复制到根目录,然后就可以开始修改了。
首先来修改 boot.asm 中获取 FAT 项的部分:
代码 21-2 硬盘版 GetFATEntry(boot.asm)
GetFATEntry: ; 返回第ax个簇的值
push es
push bx
push ax ; 都会用到,push一下
mov ax, BaseOfLoader
sub ax, 0100h
mov es, ax
pop ax
mov bx, 2
mul bx ; 每一个FAT项是两字节,给ax乘2就是偏移
LABEL_GET_FAT_ENTRY:
; 将ax变为扇区号
xor dx, dx
mov bx, [BPB_BytsPerSec]
div bx ; dx = ax % 512, ax /= 512
push dx ; 保存dx的值
mov bx, 0 ; es:bx已指定
add ax, SectorNoOfFAT1 ; 对应扇区号
mov cl, 1 ; 一次读一个扇区即可
call ReadSector ; 直接读入
; bx 到 bx + 512 处为读进扇区
pop dx
add bx, dx ; 加上偏移
mov ax, [es:bx] ; 读取,那么这里就是了
LABEL_GET_FAT_ENTRY_OK: ; 胜利执行
pop bx
pop es ; 恢复堆栈
ret
修改的部分主要有:乘1.5的部分变成了乘2;读取的扇区数由两个降到一个;删掉了 FAT12 时期对 FAT 解压缩的处理。
读取扇区的部分则直接仿着四节前的那个硬盘驱动写就行了:
代码 21-3 硬盘版 ReadSector(boot.asm)
ReadSector: ; 读硬盘扇区
; 从第eax号扇区开始,读取cl个扇区至es:bx
push esi
push di
push es
push bx
mov esi, eax
mov di, cx ; 备份ax,cx
; 读硬盘 第一步:设置要读取扇区数
mov dx, 0x1f2
mov al, cl
out dx, al
mov eax, esi ; 恢复ax
; 第二步:写入扇区号
mov dx, 0x1f3
out dx, al ; LBA 7~0位,写入0x1f3
mov cl, 8
shr eax, cl ; LBA 15~8位,写入0x1f4
mov dx, 0x1f4
out dx, al
shr eax, cl
mov dx, 0x1f5
out dx, al ; LBA 23~16位,写入0x1f5
shr eax, cl
and al, 0x0f ; LBA 27~24位
or al, 0xe0 ; 表示当前硬盘
mov dx, 0x1f6 ; 写入0x1f6
out dx, al
; 第三步:0x1f7写入0x20,表示读
mov dx, 0x1f7
mov al, 0x20
out dx, al
; 第四步:检测硬盘状态
.not_ready:
nop
in al, dx ; 读入硬盘状态
and al, 0x88 ; 分离第4位,第7位
cmp al, 0x08 ; 硬盘不忙且已准备好
jnz .not_ready ; 不满足,继续等待
; 第五步:将数据从0x1f0端口读出
mov ax, di ; di为要读扇区数,共需读di * 512 / 2次
mov dx, 256
mul dx
mov cx, ax
mov dx, 0x1f0
.go_on_read:
in ax, dx
mov [es:bx], ax
add bx, 2
loop .go_on_read
; 结束
pop bx
pop es
pop di
pop esi
ret
这里需要注意,ReadSector 调用前后会修改 bx、di 和 esi,如果自己写的话要注意备份。
由于换了 FAT16,boot.asm 开头的 %include "fat12hdr.inc" 也要同步更换为 %include "fat16hdr.inc",这里面的内容对照着格式化函数和 file.h 很容易写出:
代码 21-4 FAT16 相关常量(fat16hdr.inc)
BS_OEMName db 'tutorial' ; 固定的8个字节
BPB_BytsPerSec dw 512 ; 每扇区固定512个字节
BPB_SecPerClus db 1 ; 每簇固定1个扇区
BPB_RsvdSecCnt dw 1 ; MBR固定占用1个扇区
BPB_NumFATs db 2 ; 我们实现的FAT16文件系统有2个FAT表
BPB_RootEntCnt dw 512 ; 根目录区32个扇区,一个目录项32字节,共计32*512/32=512个目录项
BPB_TotSec16 dw 0 ; 80MB硬盘的大小过大,不足以放到TotSec16
BPB_Media db 0xF8 ; 介质描述符,硬盘为0xF8
BPB_FATSz16 dw 32 ; 一个FAT表所占的扇区数,FAT16 文件系统固定为32个扇区
BPB_SecPerTrk dw 63 ; 每磁道扇区数,80MB硬盘为63
BPB_NumHeads dw 16 ; 磁头数,bximage 的输出告诉我们是16个
BPB_HiddSec dd 0 ; 隐藏扇区数,没有
BPB_TotSec32 dd 41943040 ; 若之前的 BPB_TotSec16 处没有记录扇区数,则由此记录,如果记录了,这里直接置0即可
BS_DrvNum db 0x80 ; int 13h 调用时所读取的驱动器号,由于挂载的是硬盘所以0x80
BS_Reserved1 db 0 ; 未使用,预留
BS_BootSig db 29h ; 扩展引导标记
BS_VolID dd 0 ; 卷序列号,由于只挂载一个盘所以为0
BS_VolLab db 'OS-tutorial' ; 卷标,11个字节
BS_FileSysType db 'FAT16 ' ; 由于是 FAT16 文件系统,所以写入 FAT16 后补齐8个字节
FATSz equ 32 ; BPB_FATSz16
RootDirSectors equ 32 ; 根目录大小
SectorNoOfRootDirectory equ 65 ; 根目录起始扇区
SectorNoOfFAT1 equ 1 ; 第一个FAT表的开始扇区
DeltaSectorNo equ 63 ; 由于第一个簇不用,所以RootDirSectors要-2再加上根目录区首扇区和偏移才能得到真正的地址,故把RootDirSectors-2封装成一个常量
最后一处修改是在主循环的 LABEL_GOON_LOADING_FILE 附近:
代码 21-5 硬盘版主循环(boot.asm)
cmp ax, 0FFFFh ; 这里!原本是0FFF,但FAT16的文件结束时FFFF,所以这里要修改
jz LABEL_FILE_LOADED ; 若此项=0FFFF,代表文件结束,直接跳入Loader
push ax ; 重新存储FAT号,但此时的FAT号已经是下一个FAT了
至此,硬盘版引导扇区修改完成,完整代码如下:
代码 21-6 硬盘引导扇区-完整版(boot.asm)
org 07c00h ; 告诉编译器程序将装载至0x7c00处
BaseOfStack equ 07c00h ; 栈的基址
jmp short LABEL_START
nop ; BS_JMPBoot 由于要三个字节而jmp到LABEL_START只有两个字节 所以加一个nop
%include "fat16hdr.inc" ; 没错它会db一遍
%include "load.inc" ; 代替之前的常量
LABEL_START:
mov ax, cs
mov ds, ax
mov es, ax ; 将ds es设置为cs的值(因为此时字符串和变量等存在代码段内)
mov ss, ax ; 将堆栈段也初始化至cs
mov sp, BaseOfStack ; 设置栈顶
mov ax, 0600h ; AH=06h:向上滚屏,AL=00h:清空窗口
mov bx, 0700h ; 空白区域缺省属性
mov cx, 0 ; 左上:(0, 0)
mov dx, 0184fh ; 右下:(80, 25)
int 10h ; 执行
mov dh, 0
call DispStr ; Booting
xor ah, ah ; 复位
xor dl, dl
int 13h ; 执行软驱复位
mov word [wSectorNo], SectorNoOfRootDirectory ; 开始查找,将当前读到的扇区数记为根目录区的开始扇区(19)
LABEL_SEARCH_IN_ROOT_DIR_BEGIN:
cmp word [wRootDirSizeForLoop], 0 ; 将剩余的根目录区扇区数与0比较
jz LABEL_NO_LOADERBIN ; 相等,不存在Loader,进行善后
dec word [wRootDirSizeForLoop] ; 减去一个扇区
mov ax, BaseOfLoader
mov es, ax
mov bx, OffsetOfLoader ; 将es:bx设置为BaseOfLoader:OffsetOfLoader,暂且使用Loader所占的内存空间存放根目录区
mov ax, [wSectorNo] ; 起始扇区:当前读到的扇区数(废话)
mov cl, 1 ; 读取一个扇区
call ReadSector ; 读入
mov si, LoaderFileName ; 为比对做准备,此处是将ds:si设为Loader文件名
mov di, OffsetOfLoader ; 为比对做准备,此处是将es:di设为Loader偏移量(即根目录区中的首个文件块)
cld ; FLAGS.DF=0,即执行lodsb/lodsw/lodsd后,si自动增加
mov dx, 10h ; 共16个文件块(代表一个扇区,因为一个文件块32字节,16个文件块正好一个扇区)
LABEL_SEARCH_FOR_LOADERBIN:
cmp dx, 0 ; 将dx与0比较
jz LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR ; 继续前进一个扇区
dec dx ; 否则将dx减1
mov cx, 11 ; 文件名共11字节
LABEL_CMP_FILENAME: ; 比对文件名
cmp cx, 0 ; 将cx与0比较
jz LABEL_FILENAME_FOUND ; 若相等,说明文件名完全一致,表示找到,进行找到后的处理
dec cx ; cx减1,表示读取1个字符
lodsb ; 将ds:si的内容置入al,si加1
cmp al, byte [es:di] ; 此字符与LOADER BIN中的当前字符相等吗?
jz LABEL_GO_ON ; 下一个文件名字符
jmp LABEL_DIFFERENT ; 下一个文件块
LABEL_GO_ON:
inc di ; di加1,即下一个字符
jmp LABEL_CMP_FILENAME ; 继续比较
LABEL_DIFFERENT:
and di, 0FFE0h ; 指向该文件块开头
add di, 20h ; 跳过32字节,即指向下一个文件块开头
mov si, LoaderFileName ; 重置ds:si
jmp LABEL_SEARCH_FOR_LOADERBIN ; 由于要重新设置一些东西,所以回到查找Loader循环的开头
LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR:
add word [wSectorNo], 1 ; 下一个扇区
jmp LABEL_SEARCH_IN_ROOT_DIR_BEGIN ; 重新执行主循环
LABEL_NO_LOADERBIN: ; 若找不到loader.bin则到这里
mov dh, 2
call DispStr; 显示No LOADER
jmp $
LABEL_FILENAME_FOUND:
mov ax, RootDirSectors ; 将ax置为根目录首扇区(19)
and di, 0FFE0h ; 将di设置到此文件块开头
add di, 01Ah ; 此时的di指向Loader的FAT号
mov cx, word [es:di] ; 获得该扇区的FAT号
push cx ; 将FAT号暂存
add cx, ax ; +根目录首扇区
add cx, DeltaSectorNo ; 获得真正的地址
mov ax, BaseOfLoader
mov es, ax
mov bx, OffsetOfLoader ; es:bx:读取扇区的缓冲区地址
mov ax, cx ; ax:起始扇区号
LABEL_GOON_LOADING_FILE: ; 加载文件
push ax
push bx
mov ah, 0Eh ; AH=0Eh:显示单个字符
mov al, '.' ; AL:字符内容
mov bl, 0Fh ; BL:显示属性
; 还有BH:页码,此处不管
int 10h ; 显示此字符
pop bx
pop ax ; 上面几行的整体作用:在屏幕上打印一个点
mov cl, 1
call ReadSector ; 读取Loader第一个扇区
pop ax ; 加载FAT号
call GetFATEntry ; 加载FAT项
cmp ax, 0FFFFh
jz LABEL_FILE_LOADED ; 若此项=0FFF,代表文件结束,直接跳入Loader
push ax ; 重新存储FAT号,但此时的FAT号已经是下一个FAT了
mov dx, RootDirSectors
add ax, dx ; +根目录首扇区
add ax, DeltaSectorNo ; 获取真实地址
add bx, [BPB_BytsPerSec] ; 将bx指向下一个扇区开头
jmp LABEL_GOON_LOADING_FILE ; 加载下一个扇区
LABEL_FILE_LOADED:
mov dh, 1 ; 打印第 1 条消息(Ready.)
call DispStr
jmp BaseOfLoader:OffsetOfLoader ; 跳入Loader!
wRootDirSizeForLoop dw RootDirSectors ; 查找loader的循环中将会用到
wSectorNo dw 0 ; 用于保存当前扇区数
bOdd db 0 ; 这个其实是下一节的东西,不过先放在这也不是不行
LoaderFileName db "LOADER BIN", 0 ; loader的文件名
MessageLength equ 9 ; 下面是三条小消息,此变量用于保存其长度,事实上在内存中它们的排序类似于二维数组
BootMessage: db "Booting " ; 此处定义之后就可以删除原先定义的BootMessage字符串了
Message1 db "Ready. " ; 显示已准备好
Message2 db "No LOADER" ; 显示没有Loader
DispStr:
mov ax, MessageLength
mul dh ; 将ax乘以dh后,结果仍置入ax(事实上远比此复杂,此处先解释到这里)
add ax, BootMessage ; 找到给定的消息
mov bp, ax ; 先给定偏移
mov ax, ds
mov es, ax ; 以防万一,重新设置es
mov cx, MessageLength ; 字符串长度
mov ax, 01301h ; ah=13h, 显示字符的同时光标移位
mov bx, 0007h ; 黑底白字
mov dl, 0 ; 第0行,前面指定的dh不变,所以给定第几条消息就打印到第几行
int 10h ; 显示字符
ret
ReadSector: ; 读硬盘扇区
; 从第eax号扇区开始,读取cl个扇区至es:bx
push esi
push di
push es
push bx
mov esi, eax
mov di, cx ; 备份ax,cx
; 读硬盘 第一步:设置要读取扇区数
mov dx, 0x1f2
mov al, cl
out dx, al
mov eax, esi ; 恢复ax
; 第二步:写入扇区号
mov dx, 0x1f3
out dx, al ; LBA 7~0位,写入0x1f3
mov cl, 8
shr eax, cl ; LBA 15~8位,写入0x1f4
mov dx, 0x1f4
out dx, al
shr eax, cl
mov dx, 0x1f5
out dx, al ; LBA 23~16位,写入0x1f5
shr eax, cl
and al, 0x0f ; LBA 27~24位
or al, 0xe0 ; 表示当前硬盘
mov dx, 0x1f6 ; 写入0x1f6
out dx, al
; 第三步:0x1f7写入0x20,表示读
mov dx, 0x1f7
mov al, 0x20
out dx, al
; 第四步:检测硬盘状态
.not_ready:
nop
in al, dx ; 读入硬盘状态
and al, 0x88 ; 分离第4位,第7位
cmp al, 0x08 ; 硬盘不忙且已准备好
jnz .not_ready ; 不满足,继续等待
; 第五步:将数据从0x1f0端口读出
mov ax, di ; di为要读扇区数,共需读di * 512 / 2次
mov dx, 256
mul dx
mov cx, ax
mov dx, 0x1f0
.go_on_read:
in ax, dx
mov [es:bx], ax
add bx, 2
loop .go_on_read
; 结束
pop bx
pop es
pop di
pop esi
ret
GetFATEntry: ; 返回第ax个簇的值
push es
push bx
push ax ; 都会用到,push一下
mov ax, BaseOfLoader
sub ax, 0100h
mov es, ax
pop ax
mov bx, 2
mul bx ; 每一个FAT项是两字节,给ax乘2就是偏移
LABEL_GET_FAT_ENTRY:
; 将ax变为扇区号
xor dx, dx
mov bx, [BPB_BytsPerSec]
div bx ; dx = ax % 512, ax /= 512
push dx ; 保存dx的值
mov bx, 0 ; es:bx已指定
add ax, SectorNoOfFAT1 ; 对应扇区号
mov cl, 1 ; 一次读一个扇区即可
call ReadSector ; 直接读入
; bx 到 bx + 512 处为读进扇区
pop dx
add bx, dx ; 加上偏移
mov ax, [es:bx] ; 读取,那么这里就是了
LABEL_GET_FAT_ENTRY_OK: ; 胜利执行
pop bx
pop es ; 恢复堆栈
ret
times 510 - ($ - $$) db 0
db 0x55, 0xaa ; 确保最后两个字节是0x55AA
编译,运行,命令如下:

(图 21-2 编译运行命令)
效果如下:

(图 21-3 白色的 L,很熟悉对吧)
对于 Loader,在进行完上述修改以后,把 LABEL_FILE_LOADED 中的 call KillMotor 以及 KillMotor 函数一并删除即可,这里不多赘述,贴一遍完整代码:
代码 21-7 硬盘版 Loader-完整版(loader.asm)
org 0100h ; 告诉编译器程序将装载至0x100处
BaseOfStack equ 0100h ; 栈的基址
jmp LABEL_START
%include "fat16hdr.inc" ; 没错它会再db一遍
%include "load.inc" ; 代替之前的常量
%include "pm.inc" ; 保护模式相关
; GDT
LABEL_GDT: Descriptor 0, 0, 0 ; 占位用描述符
LABEL_DESC_FLAT_C: Descriptor 0, 0fffffh, DA_C | DA_32 | DA_LIMIT_4K ; 32位代码段,平坦内存
LABEL_DESC_FLAT_RW: Descriptor 0, 0fffffh, DA_DRW | DA_32 | DA_LIMIT_4K ; 32位数据段,平坦内存
LABEL_DESC_VIDEO: Descriptor 0B8000h, 0ffffh, DA_DRW | DA_DPL3 ; 文本模式显存,后面用不到了
GdtLen equ $ - LABEL_GDT ; GDT的长度
GdtPtr dw GdtLen - 1 ; gdtr寄存器,先放置长度
dd BaseOfLoaderPhyAddr + LABEL_GDT ; 保护模式使用线性地址,因此需要加上程序装载位置的物理地址(BaseOfLoaderPhyAddr)
SelectorFlatC equ LABEL_DESC_FLAT_C - LABEL_GDT ; 代码段选择子
SelectorFlatRW equ LABEL_DESC_FLAT_RW - LABEL_GDT ; 数据段选择子
SelectorVideo equ LABEL_DESC_VIDEO - LABEL_GDT + SA_RPL3 ; 文本模式显存选择子
LABEL_START:
mov ax, cs
mov ds, ax
mov es, ax ; 将ds es设置为cs的值(因为此时字符串和变量等存在代码段内)
mov ss, ax ; 将堆栈段也初始化至cs
mov sp, BaseOfStack ; 设置栈顶
mov dh, 0
call DispStr ; Loading
mov word [wSectorNo], SectorNoOfRootDirectory ; 开始查找,将当前读到的扇区数记为根目录区的开始扇区(19)
xor ah, ah ; 复位
xor dl, dl
int 13h ; 执行软驱复位
LABEL_SEARCH_IN_ROOT_DIR_BEGIN:
cmp word [wRootDirSizeForLoop], 0 ; 将剩余的根目录区扇区数与0比较
jz LABEL_NO_KERNELBIN ; 相等,不存在Kernel,进行善后
dec word [wRootDirSizeForLoop] ; 减去一个扇区
mov ax, BaseOfKernelFile
mov es, ax
mov bx, OffsetOfKernelFile ; 将es:bx设置为BaseOfKernel:OffsetOfKernel,暂且使用Kernel所占的内存空间存放根目录区
mov ax, [wSectorNo] ; 起始扇区:当前读到的扇区数(废话)
mov cl, 1 ; 读取一个扇区
call ReadSector ; 读入
mov si, KernelFileName ; 为比对做准备,此处是将ds:si设为Kernel文件名
mov di, OffsetOfKernelFile ; 为比对做准备,此处是将es:di设为Kernel偏移量(即根目录区中的首个文件块)
cld ; FLAGS.DF=0,即执行lodsb/lodsw/lodsd后,si自动增加
mov dx, 10h ; 共16个文件块(代表一个扇区,因为一个文件块32字节,16个文件块正好一个扇区)
LABEL_SEARCH_FOR_KERNELBIN:
cmp dx, 0 ; 将dx与0比较
jz LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR ; 继续前进一个扇区
dec dx ; 否则将dx减1
mov cx, 11 ; 文件名共11字节
LABEL_CMP_FILENAME: ; 比对文件名
cmp cx, 0 ; 将cx与0比较
jz LABEL_FILENAME_FOUND ; 若相等,说明文件名完全一致,表示找到,进行找到后的处理
dec cx ; cx减1,表示读取1个字符
lodsb ; 将ds:si的内容置入al,si加1
cmp al, byte [es:di] ; 此字符与KERNEL BIN中的当前字符相等吗?
jz LABEL_GO_ON ; 下一个文件名字符
jmp LABEL_DIFFERENT ; 下一个文件块
LABEL_GO_ON:
inc di ; di加1,即下一个字符
jmp LABEL_CMP_FILENAME ; 继续比较
LABEL_DIFFERENT:
and di, 0FFE0h ; 指向该文件块开头
add di, 20h ; 跳过32字节,即指向下一个文件块开头
mov si, KernelFileName ; 重置ds:si
jmp LABEL_SEARCH_FOR_KERNELBIN ; 由于要重新设置一些东西,所以回到查找Kernel循环的开头
LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR:
add word [wSectorNo], 1 ; 下一个扇区
jmp LABEL_SEARCH_IN_ROOT_DIR_BEGIN ; 重新执行主循环
LABEL_NO_KERNELBIN: ; 若找不到kernel.bin则到这里
mov dh, 2
call DispStr ; 显示No KERNEL
jmp $
LABEL_FILENAME_FOUND:
mov ax, RootDirSectors ; 将ax置为根目录首扇区(19)
and di, 0FFF0h ; 将di设置到此文件块开头
push eax
mov eax, [es:di + 01Ch]
mov dword [dwKernelSize], eax
pop eax
add di, 01Ah ; 此时的di指向Kernel的FAT号
mov cx, word [es:di] ; 获得该扇区的FAT号
push cx ; 将FAT号暂存
add cx, ax ; +根目录首扇区
add cx, DeltaSectorNo ; 获得真正的地址
mov ax, BaseOfKernelFile
mov es, ax
mov bx, OffsetOfKernelFile ; es:bx:读取扇区的缓冲区地址
mov ax, cx ; ax:起始扇区号
LABEL_GOON_LOADING_FILE: ; 加载文件
push ax
push bx
mov ah, 0Eh ; AH=0Eh:显示单个字符
mov al, '.' ; AL:字符内容
mov bl, 0Fh ; BL:显示属性
; 还有BH:页码,此处不管
int 10h ; 显示此字符
pop bx
pop ax ; 上面几行的整体作用:在屏幕上打印一个点
mov cl, 1
call ReadSector ; 读取Kernel第一个扇区
pop ax ; 加载FAT号
call GetFATEntry ; 加载FAT项
cmp ax, 0FFFFh
jz LABEL_FILE_LOADED ; 若此项=0FFF,代表文件结束,直接跳入Kernel
push ax ; 重新存储FAT号,但此时的FAT号已经是下一个FAT了
mov dx, RootDirSectors
add ax, dx ; +根目录首扇区
add ax, DeltaSectorNo ; 获取真实地址
add bx, [BPB_BytsPerSec] ; 将bx指向下一个扇区开头
jmp LABEL_GOON_LOADING_FILE ; 加载下一个扇区
LABEL_FILE_LOADED:
mov dh, 1 ; "Ready."
call DispStr
; 准备进入保护模式
lgdt [GdtPtr] ; 加载gdt
cli ; 关闭中断
in al, 92h ; 开启A20地址线
or al, 00000010b
out 92h, al
mov eax, cr0
or eax, 1 ; CR0.PE=1,进入保护模式
mov cr0, eax
jmp dword SelectorFlatC:(BaseOfLoaderPhyAddr + LABEL_PM_START) ; 进入32位段,彻底进入保护模式
dwKernelSize dd 0 ; Kernel大小
wRootDirSizeForLoop dw RootDirSectors ; 查找Kernel的循环中将会用到
wSectorNo dw 0 ; 用于保存当前扇区数
bOdd db 0 ; 这个其实是下一节的东西,不过先放在这也不是不行
KernelFileName db "KERNEL BIN", 0 ; Kernel的文件名
MessageLength equ 9 ; 下面是三条小消息,此变量用于保存其长度,事实上在内存中它们的排序类似于二维数组
BootMessage: db "Loading " ; 此处定义之后就可以删除原先定义的BootMessage字符串了
Message1 db "Ready. " ; 显示已准备好
Message2 db "No KERNEL" ; 显示没有Kernel
DispStr: ; void DispStr(char idx);
; idx -> dh
; 基于bios功能:
; int 10h : ah=13h, 打印字符串
mov ax, MessageLength
mul dh ; 将ax乘以dh后,结果仍置入ax(事实上远比此复杂,此处先解释到这里)
add ax, BootMessage ; 找到给定的消息
mov bp, ax ; 先给定偏移
mov ax, ds
mov es, ax ; 以防万一,重新设置es
mov cx, MessageLength ; 字符串长度
mov ax, 01301h ; ah=13h, 显示字符的同时光标移位
mov bx, 0007h ; 黑底白字
mov dl, 0 ; 第0行,前面指定的dh不变,所以给定第几条消息就打印到第几行
add dh, 3 ; 给dh加3,避免与boot打印的消息重叠
int 10h ; 显示字符
ret
ReadSector: ; 读硬盘扇区
; 从第eax号扇区开始,读取cl个扇区至es:bx
push esi
push di
push es
push bx
mov esi, eax
mov di, cx ; 备份ax,cx
; 读硬盘 第一步:设置要读取扇区数
mov dx, 0x1f2
mov al, cl
out dx, al
mov eax, esi ; 恢复ax
; 第二步:写入扇区号
mov dx, 0x1f3
out dx, al ; LBA 7~0位,写入0x1f3
mov cl, 8
shr eax, cl ; LBA 15~8位,写入0x1f4
mov dx, 0x1f4
out dx, al
shr eax, cl
mov dx, 0x1f5
out dx, al ; LBA 23~16位,写入0x1f5
shr eax, cl
and al, 0x0f ; LBA 27~24位
or al, 0xe0 ; 表示当前硬盘
mov dx, 0x1f6 ; 写入0x1f6
out dx, al
; 第三步:0x1f7写入0x20,表示读
mov dx, 0x1f7
mov al, 0x20
out dx, al
; 第四步:检测硬盘状态
.not_ready:
nop
in al, dx ; 读入硬盘状态
and al, 0x88 ; 分离第4位,第7位
cmp al, 0x08 ; 硬盘不忙且已准备好
jnz .not_ready ; 不满足,继续等待
; 第五步:将数据从0x1f0端口读出
mov ax, di ; di为要读扇区数,共需读di * 512 / 2次
mov dx, 256
mul dx
mov cx, ax
mov dx, 0x1f0
.go_on_read:
in ax, dx
mov [es:bx], ax
add bx, 2
loop .go_on_read
; 结束
pop bx
pop es
pop di
pop esi
ret
GetFATEntry: ; 返回第ax个簇的值
push es
push bx
push ax ; 都会用到,push一下
mov ax, BaseOfLoader
sub ax, 0100h
mov es, ax
pop ax
mov bx, 2
mul bx ; 每一个FAT项是两字节,给ax乘2就是偏移
LABEL_GET_FAT_ENTRY:
; 将ax变为扇区号
xor dx, dx
mov bx, [BPB_BytsPerSec]
div bx ; dx = ax % 512, ax /= 512
push dx ; 保存dx的值
mov bx, 0 ; es:bx已指定
add ax, SectorNoOfFAT1 ; 对应扇区号
mov cl, 1 ; 一次读一个扇区即可
call ReadSector ; 直接读入
; bx 到 bx + 512 处为读进扇区
pop dx
add bx, dx ; 加上偏移
mov ax, [es:bx] ; 读取,那么这里就是了
LABEL_GET_FAT_ENTRY_OK: ; 胜利执行
pop bx
pop es ; 恢复堆栈
ret
[section .s32]
align 32
[bits 32]
LABEL_PM_START:
mov ax, SelectorVideo ; 按照保护模式的规矩来
mov gs, ax ; 把选择子装入gs
mov ah, 0Fh
mov al, 'P'
mov [gs:((80 * 0 + 39) * 2)], ax ; 这一部分写入显存是通用的
mov ax, SelectorFlatRW ; 数据段
mov ds, ax
mov es, ax
mov fs, ax
mov ss, ax
mov esp, TopOfStack
; cs的设定已在之前的远跳转中完成
call InitKernel ; 重新放置内核
jmp SelectorFlatC:KernelEntryPointPhyAddr ; 进入内核,OS征程从这里开始
MemCpy: ; void memcpy(void *dest, const void *src, size_t size);
; ds:参数2 ==> es:参数1,大小:参数3
push ebp
mov ebp, esp ; 保存ebp和esp的值
push esi
push edi
push ecx ; 暂存这三个,要用
mov edi, [ebp + 8] ; [esp + 4] ==> 第一个参数,目标内存区
mov esi, [ebp + 12] ; [esp + 8] ==> 第二个参数,源内存区
mov ecx, [ebp + 16] ; [esp + 12] ==> 第三个参数,拷贝的字节大小
.1:
cmp ecx, 0 ; if (ecx == 0)
jz .2 ; goto .2;
mov al, [ds:esi] ; 从源内存区中获取一个值
inc esi ; 源内存区地址+1
mov byte [es:edi], al ; 将该值写入目标内存
inc edi ; 目标内存区地址+1
dec ecx ; 拷贝字节数大小-1
jmp .1 ; 重复执行
.2:
mov eax, [ebp + 8] ; 目标内存区作为返回值
pop ecx ; 以下代码恢复堆栈
pop edi
pop esi
mov esp, ebp
pop ebp
ret
InitKernel: ; void InitKernel();
xor esi, esi ; esi = 0;
mov cx, word [BaseOfKernelFilePhyAddr + 2Ch] ; 这个内存地址存放的是ELF头中的e_phnum,即Program Header的个数
movzx ecx, cx ; ecx高16位置0,低16位置入cx
mov esi, [BaseOfKernelFilePhyAddr + 1Ch] ; 这个内存地址中存放的是ELF头中的e_phoff,即Program Header表的偏移
add esi, BaseOfKernelFilePhyAddr ; Program Header表的具体位置
.Begin:
mov eax, [esi] ; 首先看一下段类型
cmp eax, 0 ; 段类型:PT_NULL或此处不存在Program Header
jz .NoAction ; 本轮循环不执行任何操作
; 否则的话:
push dword [esi + 010h] ; p_filesz
mov eax, [esi + 04h] ; p_offset
add eax, BaseOfKernelFilePhyAddr ; BaseOfKernelFilePhyAddr + p_offset
push eax
push dword [esi + 08h] ; p_vaddr
call MemCpy ; 执行一次拷贝
add esp, 12 ; 清理堆栈
.NoAction: ; 本轮循环的清理工作
add esi, 020h ; 下一个Program Header
dec ecx
jnz .Begin ; jz过来的话就直接ret了
ret
[section .data1]
StackSpace: times 1024 db 0 ; 栈暂且先给1KB
TopOfStack equ $ - StackSpace ; 栈顶
如今硬盘 bootloader 已成,直接把原本的 boot.asm 和 loader.asm 替换为现在的 boot.asm 和 loader.asm,并用 fat16hdr.inc 替换 fat12hdr.inc 即可。
Makefile 也要进行修改,从此以后不再生成 a.img 了,而是生成 hd.img:
代码 21-8 新版 Makefile(Makefile)
hd.img : out/boot.bin out/loader.bin out/kernel.bin
ftimgcreate hd.img -t hd -size 80
ftformat hd.img -t hd -f fat16
ftcopy out/loader.bin -to -img hd.img
ftcopy out/kernel.bin -to -img hd.img
dd if=out/boot.bin of=hd.img bs=512 count=1
run : hd.img
qemu-system-i386 -hda hd.img
由于现在每次编译都会重新创建硬盘镜像,所以之前的写入测试文件 iloveado.fai 将不复存在,那就返璞归真,用一行简单的打印证明我们进入了内核吧:
代码 21-9 kernel/main.c
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear();
init_gdtidt();
init_memory();
init_timer(100);
init_keyboard();
asm("sti");
task_t *task_a = task_init();
task_t *task_shell = create_kernel_task(shell);
//task_run(task_shell);
printk("Hello, HD Boot!");
while (1);
}
(shell:请你认真的看一看我……我至今为止有被用过哪怕一次么?)
使用 make default 全部重新编译,运行,效果如下图:

(图 21-4 硬盘启动成功)
终于,在整整21节之后,我们并不是很紧地跟上了时代潮流,将软盘扔进了历史的垃圾堆,事实证明这是颇不具有里程碑意义的一件不是很大的事。
这一节本来是想放在最后写的,耐不住老有人催,所以提前写了,应用程序什么的就放在下一节吧!
22.第一个应用程序
想要加载一个应用程序,实际上是相当简单的,我们迅速来做一个简单的示例。
首先,创建新文件 test_app.asm,内容如下:
代码 22-1 测试应用程序(test_app.asm)
ud2
这个东西本来应该在前面几节讲异常的时候提的,它可以手动触发一个 6 号异常,到时候只需要看是否触发就行了。
使用 nasm 命令将它编译为一个二进制程序:

(图 22-1 编译方法)
生成了仅两个字节的 test_app.bin,使用 ftcopy 命令将它写入虚拟硬盘 hd.img:

(图 22-2 写入硬盘,若完全跟随本教程的话,硬盘根目录应该长这样)
修改 kernel_main 中测试代码如下:
代码 22-2 执行应用程序(kernel/main.c)
int fd = sys_open("test_app.bin", O_RDWR); // 打开应用程序文件test_app.bin
char *buf = (char *) kmalloc(512); // 分配一个扇区当缓冲区
int ret = sys_read(fd, buf, 512); // 读取512字节的空间
printk("read status: %d\n", ret); // 返回读取状态
asm("jmp %0" : : "m"(buf)); // 然后直接跳入buf开始执行里面的代码
kfree(buf); // 释放缓冲区(虽然如果成了理论上执行不到这)
编译,运行,效果如下图所示:

(图 22-3 6 号异常触发,应用程序成功执行)
好了,既然我们的第一个应用程序已经成功执行,已经达到了本节标题的进度,所以本节到此结束,下一节……
乐了,你看这可能吗?那包不可能的,我们本节真正的任务其实总共有两个:
1.实现任务创建,现在的应用程序执行会直接把原来的任务顶号,这样的话多任务就跟没实现一样;
2.实现基本的保护措施,现在的应用程序随随便便就能惊动 CPU 让它爆异常,这实在是非常脆弱的,哪怕爆也只能爆一般保护性异常让 OS 做处理。
我们从易到难,从实现任务创建开始。在 Linux 中,创建任务通常使用的是 fork 函数(当然也有别的函数比如 vfork,这里不讨论),作用是复制一个当前的任务,不过由于我们使用 TSS 而非 PCB,fork 函数非常难实现。那么,就只能选择使用微软风格的 CreateProcess,后面写成 create_process:
代码 22-3 应用程序任务创建及执行 API
int create_process(const char *app_name, const char *cmdline, const char *work_dir); // 返回新任务的 PID
由于我们没有实现目录,第三个参数只能填 /。
这个系统调用怎么实现呢?希望大家都还没有忘掉第15节创建新系统调用的方法(笑)。首先实现一个对应的 sys_create_process,然后从汇编里把参数传过去。
首先来到 include/syscall.h,添加 sys_create_process 的声明并填入系统调用表:
代码 22-4 系统调用表(include/syscall.h)
int sys_create_process(const char *app_name, const char *cmdline, const char *work_dir);
// ...
syscall_func_t syscall_table[] = {
sys_getpid, sys_write, sys_read, sys_create_process, // 这里新增了一个函数
};
由于 create_process 共有三个参数,因此和 read、write 一样,用 ebx、ecx、edx 三个寄存器进行传参,所以抄一遍上面两个系统调用,然后改一下系统调用号即可:
代码 22-5 create_process 的实现(伪)(kernel/syscall_impl.asm)
[global create_process]
create_process:
push ebx
mov eax, 3
mov ebx, [esp + 8]
mov ecx, [esp + 12]
mov edx, [esp + 16]
int 80h
pop ebx
ret
对于 sys_create_process,我们需要一个单独的文件,毕竟这算是另一个主题——应用程序执行里面的东西。新建 kernel/exec.c,我们来考虑考虑怎么写这个东西。
创建新任务我们是有方法的,直接调用那个 create_kernel_task 就行了。但是这个新任务要怎么知道执行哪个应用呢?有没有什么办法让这个任务接收到参数呢?
这个任务在本质上也就是一个函数而已。而函数的传参,依靠的是 esp + 4、esp + 8 之类的特殊地址。那么,我们只需要先把 esp 减去一个特定的值,空出三个参数的量来,然后把三个参数写进那个内存里,这样就可以在新任务中读到了。
由于在任务中自己操作自己比在别的任务中操作这个任务要更为简单,所以在 sys_create_process 中我们只进行创建任务的工作。
代码 22-6 sys_create_process 的实现(kernel/exec.c)
#include "mtask.h"
int sys_create_process(const char *app_name, const char *cmdline, const char *work_dir)
{
task_t *new_task = create_kernel_task(app_entry);
new_task->tss.esp -= 12;
*((int *) (new_task->tss.esp + 4)) = (int) app_name;
*((int *) (new_task->tss.esp + 8)) = (int) cmdline;
*((int *) (new_task->tss.esp + 12)) = (int) work_dir;
task_run(new_task);
return task_pid(new_task);
}
不要忘了在 mtask.h 中添加 create_kernel_task 的声明。
三个参数一共对应 12 的栈偏移,三个参数就被顺次放在 esp + 4、esp + 8、esp + 12 的地方。最后返回了新任务的 PID,这是因为它肯定会被用到,不能让调用的啥也不知道。
这样,app_entry 应该就可以成功接收到参数了:
代码 22-7 是新任务哦(kernel/exec.c)
void app_entry(const char *app_name, const char *cmdline, const char *work_dir)
{
puts(app_name); puts(cmdline); puts(work_dir);
while (1);
}
在 kernel_main 中添加一行 create_process("test_app.bin", "nothing", "/"),然后编译运行,效果如下:

(图 22-4 接收到参数)
好了,上面两点要求里的第一点——任务创建,就这样做完了。下面该考虑实现保护功能的事了。
intel 的 cpu 一共可分为四个特权级(可以类似理解为权限),按照 0~3 标号为 ring0、ring1、ring2、ring3。其中中间两个不常用,前后两个常简称为 r0 和 r3。r0 是默认的特权级,是给操作系统内核用的;而 r3 则是给用户使用的特权级。为了实现保护,我们需要进入 r3 特权级,然后再考虑执行的事。
怎么进入 r3 特权级呢?这就不得不提到很早以前,大概十几节以前,GDT 描述符及选择子的结构图,再贴一遍(上为描述符,下为选择子):


这其中的 DPL 和 RPL 就是特权级有关的东西了。把一个段的 DPL 设为 0-3,表示这个段的特权级;而把一个选择子的 RPL 设为 0-3,表示这个选择子的特权级。由于程序执行的是代码段,所以代码段选择子的特权级,就是现在的特权级(CPL)。显然,由于选择子是描述符的代言人,DPL 与其选择子的 RPL 应当一致。想要进入 r3,也就是更改 CPL,只需要先创建一个 DPL=3 的代码段,然后想办法进去就可以了。
这个代码段放在哪呢?GDT 里?那自然不行,应用程序访问应用程序的代码段合情合理,但这个程序访问那个程序的段就不合理了。
intel 自然也考虑到了这个问题,在设计 TSS 时,搞了一个叫做 ldtr 的成员。使用联想记忆法,GDTR、IDTR 都对应 GDT、IDT,难道 LDTR 对应一个叫 LDT 的东西吗?
诶,还真是!GDT 全称是 Global Descriptor Table,这个 LDT 则与之对应,是 Local Descriptor Table。每一个 LDT 的结构,都与 GDT 完全一致,只是表项可以省略。在选择子的结构图中,可以看到有一个 TI 位,它为 1 则表示当前段在 LDT 中,否则表示当前段在 GDT 中。
在执行任务切换时,intel 会自动加载 LDT,所以这一部分就不需要我们来管了。现在唯一的问题就是:CPU 怎么知道你这个 LDT 在哪里呢?对此,intel 采取了一套与 TSS 类似的方案,那就是把 LDT 放到 GDT 里(?)。实际上,TSS 的 ldtr 成员对应的正是这个任务的 LDT 在 GDT 中对应的那个段的选择子。
在任务结构体中新增一个成员 ldt:
代码 22-8 LDT 真正存放的位置(include/mtask.h)
#include "gdtidt.h"
// 省略 tss32_t, exit_retval_t, MAX_FILE_OPEN_PER_PROC
typedef struct TASK {
uint32_t sel;
int32_t flags;
exit_retval_t my_retval;
int fd_table[MAX_FILE_OPEN_PER_TASK];
gdt_entry_t ldt[2];
tss32_t tss;
} task_t;
接着在 task_init 中,把所有任务的 LDT 注册到 GDT 并初始化 LDTR:
代码 22-9 初始化 LDT 以及 LDTR(kernel/mtask.c)
for (int i = 0; i < MAX_TASKS; i++) {
taskctl->tasks0[i].flags = 0;
taskctl->tasks0[i].sel = (TASK_GDT0 + i) * 8;
taskctl->tasks0[i].tss.ldtr = (TASK_GDT0 + MAX_TASKS + i) * 8;
gdt_set_gate(TASK_GDT0 + i, (int) &taskctl->tasks0[i].tss, 103, 0x89); // 硬性规定,0x89 代表 TSS,103 是因为 TSS 共 26 个 uint32_t 组成,总计 104 字节,因规程减1变为103
gdt_set_gate(TASK_GDT0 + MAX_TASKS + i, (int) &taskctl->tasks0[i].ldt, 15, 0x82); // 0x82 代表 LDT,两个 GDT 表项共计 16 字节
}
现在有了 LDT,该想办法进入 r3 了。或许有的读者会就此想当然:
改变 cs 和 eip?这不是一个 farjmp/farcall 就可以做到了吗?
然而,intel 实际上不允许使用 farjmp/farcall 从 r0 跳到 r3(甚至到 64 位以后直接把这俩玩意 ban 了)。当然,办法总比困难多,还可以用 far-ret 和 iretd:系统调用本质上还是中断,而系统调用执行时是 r0 权限,返回时是 r3 权限,所以从中断返回的这一步,intel 是不加限制的。far-ret 同理,可能会有一些比较古早的系统使用 farcall 来进行系统调用。
现在只是初始化了 LDT 这个表,它的表项都还没初始化,保持着一开始的样子。现在执行二进制的应用程序,代码段的大小就是文件大小,因此还需要把文件读进来:
代码 22-10 读入应用程序(kernel/exec.c)
#include "file.h"
#include "memory.h"
// ...
void app_entry(const char *app_name, const char *cmdline, const char *work_dir)
{
int fd = sys_open((char *) app_name, O_RDONLY);
int size = sys_lseek(fd, -1, SEEK_END) + 1;
sys_lseek(fd, 0, SEEK_SET);
char *buf = (char *) kmalloc(size + 5);
sys_read(fd, buf, size);
while (1);
}
这里使用了一种常见的手法,先调用 lseek 把读写指针设置到结尾,利用它返回新位置的特性得到文件大小,再用 lseek 把读写指针设置回开头,最后一次读取整个文件。由于在 lseek 中对超出 size - 1 的位置不予承认,这里需要先把指针指向 size - 1 处,最后再把 1 加回来得到文件大小。至于为什么要对文件名进行强转,是因为如果不这样 gcc 会报警告很烦。
由于 LDT 的表项与 GDT 的表项完全一致,所以复制粘贴了一个 ldt_set_gate:
代码 22-11 设置 LDT 表项的函数(kernel/exec.c)
void ldt_set_gate(int32_t num, uint32_t base, uint32_t limit, uint16_t ar)
{
task_t *task = task_now();
if (limit > 0xfffff) { // 段上限超过1MB
ar |= 0x8000; // ar的第15位(将被当作limit_high中的G位)设为1
limit /= 0x1000; // 段上限缩小为原来的1/4096,G位表示段上限为实际的4KB
}
// base部分没有其他的奇怪东西混杂,很好说
task->ldt[num].base_low = base & 0xFFFF; // 低16位
task->ldt[num].base_mid = (base >> 16) & 0xFF; // 中间8位
task->ldt[num].base_high = (base >> 24) & 0xFF; // 高8位
// limit部分混了一坨ar进来,略微复杂
task->ldt[num].limit_low = limit & 0xFFFF; // 低16位
task->ldt[num].limit_high = ((limit >> 16) & 0x0F) | ((ar >> 8) & 0xF0); // 现在的limit最多为0xfffff,所以最高位只剩4位作为低4位,高4位自然被ar的高12位挤占
task->ldt[num].access_right = ar & 0xFF; // ar部分只能存低4位了
}
LDT 的代码段应该是整个文件,那数据段呢?由于纯二进制文件结构的特殊性,我们也认为是整个文件(纯二进制的代码和数据是混在一起的,具体怎么样由程序本身来决定)。
代码 22-12 设置应用程序代码段、数据段(kernel/exec.c)
void app_entry(const char *app_name, const char *cmdline, const char *work_dir)
{
int fd = sys_open((char *) app_name, O_RDONLY);
int size = sys_lseek(fd, -1, SEEK_END) + 1;
sys_lseek(fd, 0, SEEK_SET);
char *buf = (char *) kmalloc(size + 5);
sys_read(fd, buf, size);
ldt_set_gate(0, (int) buf, size - 1, 0x409a | 0x60); // here
ldt_set_gate(1, (int) buf, size - 1, 0x4092 | 0x60); // here
while (1);
}
在最后两处或上 0x60,实际上相当于把 DPL 设置成了3。
那么最后一步,就是启动了。这启动可不能乱启动,在任务切换的时候,CPU 会观察你要跳到哪个层级,如果你在 r3 而想要跳回 r0,那么它的栈指针 esp 会从这个任务的 TSS 中的 esp0 成员来读取,ss 堆栈段也是一样。因此在程序中,还需要对这两个东西进行设置。我们使用一个单独的汇编函数 start_app 来处理这些事:
代码 22-13 应用程序启动之前(lib/nasmfunc.asm)
[global start_app]
start_app: ; void start_app(int new_eip, int new_cs, int new_esp, int new_ss, int *esp0)
pushad
mov eax, [esp + 36] ; new_eip
mov ecx, [esp + 40] ; new_cs
mov edx, [esp + 44] ; new_esp
mov ebx, [esp + 48] ; new_ss
mov ebp, [esp + 52] ; esp0
mov [ebp], esp ; *esp0 = esp
mov [ebp + 4], ss ; *ss0 = ss
; 用新的ss重设各段,实际上并不太合理而应使用ds
mov es, bx
mov ds, bx
mov fs, bx
mov gs, bx
; 选择子或上3表示要进入r3的段
or ecx, 3 ; new_cs.RPL=3
or ebx, 3 ; new_ss.RPL=3
push ebx ; new_ss
push edx ; new_esp
push ecx ; new_cs
push eax ; new_eip
retf ; 剩下的弹出的活交给 CPU 来完成
在 app_entry 中添加一行 start_app(0, 0 * 8 + 4, 0, 1 * 8 + 4, &(task_now()->tss.esp0));,同时添加 start_app 的声明,现在应该就可以正常启动应用程序了。编译,运行,我们看到效果如图所示:

(图 22-6 再次触发 6 号异常)
运行成功了!我们成功进入了 r3 用户特权级,这意味着现在操作系统已经在保护之下。不信邪的各位可以把测试代码改成 int 21h,应该能看到触发了 13 号,也就是一般保护性异常。
需要注意的是,由于每次重新编译都会清空硬盘,所以需要手动写入 test_app.bin。
不过,光能运行程序还不够,还有两件事情要办:第一,确认它可以实现系统调用;第二,把这东西接入 shell 当中。
怎么实现系统调用呢?这个好办,我们程序里怎么用的这就怎么用。至于用什么,简单输出一个字符串,用 write 系统调用就可以。
write系统调用:
eax = 1
ebx = fd
ecx = buf
edx = size
代码 22-14 使用系统调用输出字符(test_app.asm)
mov eax, 1
mov ebx, 1
mov ecx, string
mov edx, strlen
int 80h
jmp $
string: db "Hello, World!", 0x0A, 0x00
strlen equ $ - string
编译应用程序并用 ftcopy 命令写入磁盘,效果如下:

(图 22-7 失败)
唉,你怎么似了??看来实现应用程序还没有那么简单(苦笑),这一节还有很长的路要走。
我们来仔细阅读现在的系统调用处理程序 syscall_handler:
代码 22-15 现在的 syscall_handler
[extern syscall_manager]
[global syscall_handler]
syscall_handler:
sti
pushad
pushad
call syscall_manager
add esp, 32
popad
iretd
我们发现,此时所有的段全都是用户时 r3 时期的段,而内核处理系统调用的东西都在 r0,当然读不到。这就引发了一个矛盾:想要让用户程序执行系统调用,必须加载内核 r0 的段,但是这样一来就又把 r3 段中要显示的东西给丢了。
总之,切换到 r0 目前来看更为必要,那么该怎么换呢?由于 cs 已经是 r0 代码段了,所以直接赋值内核数据段选择子就可以了。
代码 22-16 新版 syscall_handler(kernel/interrupt.asm)
[extern syscall_manager]
[global syscall_handler]
syscall_handler:
sti
push ds
push es
pushad
pushad
mov ax, 0x10 ; 新增
mov ds, ax ; 新增
mov es, ax ; 新增
call syscall_manager
add esp, 32
popad
pop es
pop ds
iretd
现在再编译运行,并手动更新 test_app.bin,效果可能是这样的:

(图 22-8 至少输出了)
虽然说并没有输出 Hello World,但是至少输出了点东西了,这至少说明我们的系统调用已经成功执行。接下来就该处理输出的东西和实际不一样这件事了。
这个问题怎么解决呢?考虑到实际上它访问的地址是这个程序对应的任务 LDT 内的地址,所以只要把 LDT 基址加在这个地址上,大概就没问题了。
由于现在的系统调用采取在数组里找函数的方式,所以没法单独给一个参数加 LDT 基址。测试需要,我们给目前 write 在使用的 ecx 寄存器加上 LDT 基址。怎么加呢?其实找个地方把 buf 存一下就好了(笑)。
鉴于执行系统调用前后其实是同一个任务,所以这个东西放在任务结构体里会比较方便。
代码 22-17 任务数据段基址(include/mtask.h)
typedef struct TASK {
uint32_t sel;
int32_t flags;
exit_retval_t my_retval;
int fd_table[MAX_FILE_OPEN_PER_TASK];
gdt_entry_t ldt[2];
int ds_base; // 新增
tss32_t tss;
} task_t;
在 app_entry 中更新它:
代码 22-18 执行应用时更新数据段基址(kernel/exec.c)
void app_entry(const char *app_name, const char *cmdline, const char *work_dir)
{
int fd = sys_open((char *) app_name, O_RDONLY);
int size = sys_lseek(fd, -1, SEEK_END) + 1;
sys_lseek(fd, 0, SEEK_SET);
char *buf = (char *) kmalloc(size + 5);
sys_read(fd, buf, size);
task_now()->ds_base = (int) buf; // 这里是新增的
ldt_set_gate(0, (int) buf, size - 1, 0x409a | 0x60);
ldt_set_gate(1, (int) buf, size - 1, 0x4092 | 0x60);
start_app(0, 0 * 8 + 4, 0, 1 * 8 + 4, &(task_now()->tss.esp0));
while (1);
}
现在存是存完了,问题是怎么加到地址上?每一个系统调用都是现场从函数表里取的,不能单独处理。这里为了测试需要,不管三七二十一,直接加到 ecx 上(目前所有的系统调用都用了 ecx 传地址,但是 create_process 其实应该都加):
代码 22-19 处理地址偏移问题(临时)
void syscall_manager(int edi, int esi, int ebp, int esp, int ebx, int edx, int ecx, int eax)
{
int ds_base = task_now()->ds_base;
typedef int (*syscall_t)(int, int, int, int, int);
//(&eax + 1)[7] = ((syscall_t) syscall_table[eax])(ebx, ecx, edx, edi, esi);
syscall_t syscall_fn = (syscall_t) syscall_table[eax];
int ret = syscall_fn(ebx, ecx + ds_base, edx, edi, esi);
int *save_reg = &eax + 1;
save_reg[7] = ret;
}
这下应该处理完成了。再次编译,运行,效果如下:

(图 22-9 总算成功了……?)
至此,纯二进制应用程序应该已经可以完整执行了。没想到单是这样篇幅就已经快要爆炸了,那么集成到 shell 的问题就只好下一节再办了。
还是在下一节,我们会用 C 写一些简单的小程序来跑。
或许有人问了,那么最后一节干什么呢?先卖个关子哦。
23.C语言应用程序(上)
终于要结束啦(超大声)
本节先来处理上一节的历史遗留问题,上一节给我们留下了一个巨大的烂摊子:
系统调用中有关应用程序基址偏移的部分需要对不同的系统调用具体问题具体分析,这意味着把那个优美的系统调用表拆成一坨屎一样的 switch-case。
执行应用程序还没有集成到 shell。事实上这个功能看上去容易,其实也略有复杂,还有两个系统调用(waitpid和exit)没有实现。
单是解决这两个问题可能就要耗去一半的篇幅了,留给我们的时间不多了呀。
首先我们来把系统调用表拆掉。其实这个东西命不该绝,拆了也会让代码变得很丑,但是为了应用程序的执行,我们也只好挥泪斩马谡,对系统调用表高唱 see you again。现在的 syscall.h 长这样:
代码 23-1 想你了系统调用表(include/syscall.h)
#ifndef _SYSCALL_H_
#define _SYSCALL_H_
int sys_getpid();
int sys_create_process(const char *app_name, const char *cmdline, const char *work_dir);
// file.h
int sys_open(char *filename, uint32_t flags);
int sys_write(int fd, const void *msg, int len);
int sys_read(int fd, void *buf, int count);
int sys_close(int fd);
int sys_lseek(int fd, int offset, uint8_t whence);
int sys_unlink(const char *filename);
#endif
或许在声明中还看不出什么,你看一眼实现就明白了:
代码 23-2 想你了系统调用表-实现版(kernel/syscall.c)
void syscall_manager(int edi, int esi, int ebp, int esp, int ebx, int edx, int ecx, int eax)
{
int ds_base = task_now()->ds_base;
int ret = 0;
switch (eax) { // 从这里开始
case 0:
ret = sys_getpid();
break;
case 1:
ret = sys_write(ebx, (char *) ecx + ds_base, edx);
break;
case 2:
ret = sys_read(ebx, (char *) ecx + ds_base, edx);
break;
case 3:
ret = sys_create_process((const char *) ebx + ds_base, (const char *) ecx + ds_base, (const char *) edx + ds_base);
break;
} // 到这里结束
int *save_reg = &eax + 1;
save_reg[7] = ret;
}
和原来相比简直丑的不止一点半点。不过对于程序来说最重要的还是能不能跑,这点美学上的牺牲可以不管。
在接入到 shell 之前,我们还得实现点系统调用。首先是文件系统的全套,其次是 waitpid 和 exit。还好,这些东西的底层实现我们都已经有了:
代码 23-3 系统调用大爆炸(kernel/syscall.c)
void syscall_manager(int edi, int esi, int ebp, int esp, int ebx, int edx, int ecx, int eax)
{
int ds_base = task_now()->ds_base;
int ret = 0;
switch (eax) {
case 0:
ret = sys_getpid();
break;
case 1:
ret = sys_write(ebx, (char *) ecx + ds_base, edx);
break;
case 2:
ret = sys_read(ebx, (char *) ecx + ds_base, edx);
break;
case 3: // 从这里开始
ret = sys_open((char *) ebx + ds_base, ecx);
break;
case 4:
ret = sys_close(ebx);
break;
case 5:
ret = sys_lseek(ebx, ecx, edx);
break;
case 6:
ret = sys_unlink((char *) ebx + ds_base);
break;
case 7:
ret = sys_create_process((const char *) ebx + ds_base, (const char *) ecx + ds_base, (const char *) edx + ds_base);
break;
case 8:
ret = task_wait(ebx);
break;
case 9:
task_exit(ebx);
break; // 到这里结束
}
int *save_reg = &eax + 1;
save_reg[7] = ret;
}
为了把文件系统相关放到一块,这里把 create_process 向后推了一段距离。这些系统调用对应的高级接口如下:
代码 23-4 系统调用高层实现(kernel/syscall_impl.asm)
[global open]
open:
push ebx
mov eax, 3
mov ebx, [esp + 8]
mov ecx, [esp + 12]
int 80h
pop ebx
ret
[global close]
close:
push ebx
mov eax, 4
mov ebx, [esp + 8]
int 80h
pop ebx
ret
[global lseek]
lseek:
push ebx
mov eax, 5
mov ebx, [esp + 8]
mov ecx, [esp + 12]
mov edx, [esp + 16]
int 80h
pop ebx
ret
[global unlink]
unlink:
push ebx
mov eax, 6
mov ebx, [esp + 8]
int 80h
pop ebx
ret
[global create_process]
create_process:
push ebx
mov eax, 7
mov ebx, [esp + 8]
mov ecx, [esp + 12]
mov edx, [esp + 16]
int 80h
pop ebx
ret
[global waitpid]
waitpid:
push ebx
mov eax, 8
mov ebx, [esp + 8]
int 80h
pop ebx
ret
[global exit]
exit:
push ebx
mov eax, 9
mov ebx, [esp + 8]
int 80h
pop ebx
ret
原来的 create_process 就可以删除了。
现在,我们终于具备了把应用程序执行集成到 shell 当中的条件,是时候开搞了。
首先,在 sys_create_process 中,我们对应用程序是否存在不加任何判断,如果文件不存在的话,拖到 app_entry 再处理就晚了。因此,在创建任务之前,我们先试图打开文件以判断它是否存在:
代码 23-5 文件存在吗?(kernel/exec.c)
int sys_create_process(const char *app_name, const char *cmdline, const char *work_dir)
{
int fd = sys_open((char *) app_name, O_RDONLY);
if (fd == -1) return -1;
sys_close(fd);
// 下略
}
当文件不存在时,sys_create_process 返回-1。
然后,我们需要在内核主程序中解放 shell,自从第16节起就被封存的 shell 终于派上用场了:
代码 23-6 内核主程序之终(kernel/main.c)
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear();
init_gdtidt();
init_memory();
init_timer(100);
init_keyboard();
asm("sti");
task_t *task_a = task_init();
task_t *task_shell = create_kernel_task(shell);
task_run(task_shell);
task_exit(0);
}
在启动了 shell 任务以后,内核主程序旋即退出,并使用 0 的返回值报告正常。内核主程序以后大概还会再改最后一次,事了拂衣去,深藏身与名(泪目)
实现命令执行的函数位于 cmd_execute,因此需要在 cmd_execute 中启动应用程序。哪些是应用程序呢?我们认为只要不是内部命令的就都是应用程序(笑)。
代码 23-7 应用程序执行框架(kernel/shell.c)
void cmd_execute(int argc, char **argv)
{
if (!strcmp("ver", argv[0])) {
cmd_ver(argc, argv);
} else {
int exist;
int ret = try_to_run_external(argv[0], &exist);
if (!exist) {
printf("shell: `%s` is not recognized as an internal or external command or executable file.\n", argv[0]);
} else if (ret) {
printf("shell: app `%s` exited abnormally, retval: %d (0x%x).\n", argv[0], ret, ret);
}
}
}
由于应用程序可能返回任何返回值,所以这里必须使用两个返回值,因此使用传统的指针双返回值法,传一个指针进去表示文件是否存在。如果不存在,自然要报错,这个报错是从 Windows cmd 里抄的;否则,如果返回值不为 0,我们也报一个错,说明应用程序异常退出。
接下来的 try_to_run_external 自然就是实现应用程序执行的核心逻辑了:
代码 23-8 应用程序执行(kernel/shell.c)
int try_to_run_external(char *name, int *exist)
{
int ret = create_process(name, cmd_line, "/"); // 尝试执行应用程序
*exist = false; // 文件不存在
if (ret == -1) { // 哇真的不存在
char new_name[MAX_CMD_LEN] = {0}; // 由于还没有实现malloc,所以只能这么搞,反正文件最长就是MAX_CMD_LEN这么长
strcpy(new_name, name); // 复制文件名
int len = strlen(name); // 文件名结束位置
new_name[len] = '.'; // 给后
new_name[len + 1] = 'b'; // 缀加
new_name[len + 2] = 'i'; // 上个
new_name[len + 3] = 'n'; // .bin
new_name[len + 4] = '\0'; // 结束符
ret = create_process(new_name, cmd_line, "/"); // 第二次尝试执行应用程序
if (ret == -1) return -1; // 文件还是不存在,那只能不存在了
}
*exist = true; // 错怪你了,文件存在
ret = waitpid(ret); // 等待直到这个pid的进程返回并拿到结果
return ret; // 把返回值返回回去
}
整体逻辑应该挺好理解的。这里使用了一些新的系统调用,我们新建一个 unistd.h 存放系统调用声明:
代码 23-9 TutorialOS 系统调用列表(include/unistd.h)
#ifndef _UNISTD_H_
#define _UNISTD_H_
int open(char *filename, uint32_t flags);
int write(int fd, const void *msg, int len);
int read(int fd, void *buf, int count);
int close(int fd);
int lseek(int fd, int offset, uint8_t whence);
int unlink(const char *filename);
int waitpid(int pid);
int exit(int ret);
int create_process(const char *app_name, const char *cmdline, const char *work_dir);
#endif
在 shell.h 中包含 unistd.h 即可。
最后就是应用程序这边,要使用新的 exit 系统调用退出:
代码 23-10 应用程序(test_app.asm)
bits 32
mov eax, 1
mov ebx, 1
mov ecx, string
mov edx, strlen
int 80h
mov eax, 9
mov ebx, 114514
int 80h
jmp $
string: db "Hello, World!", 0x0A, 0x00
strlen equ $ - string
之所以加上 bits 32,是因为我们测试用的返回值(114514)超过16位最大值(65536),所以标记一下使用 32 位寄存器,把数字也看成 32 位的。
编译运行,并把 test_app.bin 写入硬盘,效果如下:

(图 23-1 在shell中执行应用程序)
可以看到,loader.bin 的执行虽然被拦下,但是程序却在异常处理程序中卡死了,没有把控制权交回到 shell。如今已经有了多任务,我们只需在 isr.c 中结束当前任务即可:
代码 23-11 发生异常时强制结束应用程序(kernel/isr.c)
#include "mtask.h"
// 中略
void isr_handler(registers_t regs)
{
asm("cli");
monitor_write("received interrupt: ");
monitor_write_dec(regs.int_no);
monitor_put('\n');
task_exit(-1); // 强制退出
}
由于在任务结束后会强制切换回 shell,从而重新开启中断,所以最上面的 asm("cli") 不用处理。
现在再试图运行 loader.bin,应该就会把控制权交还给内核了:

(图 23-2 执行中出现异常时强制结束应用程序)
至此,我们终于解决完了上一节留下的烂摊子。kernel.bin 没被拦下是因为它是有格式的,还没来得及执行到指令就已经不知道在执行什么东西了,从而导致了它的卡死。正好我们本节的任务——C语言应用程序还没开始,就顺其自然,解析 kernel.bin 的文件格式——ELF。重回第 6 节既视感(
重提一下 ELF 文件的结构:
(图 23-2 ELF 文件结构)
代码 23-12 Program Header(include/elf.h)
typedef struct {
Elf32_Word p_type; // 当前header描述的段类型
Elf32_Off p_offset; // 段的第一个字节在文件中的偏移
Elf32_Addr p_vaddr; // 段在内存中的虚拟地址
Elf32_Addr p_paddr; // 段在内存中的物理地址,为兼容不进入保护模式的OS
Elf32_Word p_filesz; // 段在文件中的长度
Elf32_Word p_memsz; // 段在内存中的长度
Elf32_Word p_flags; // 与段相关的标志
Elf32_Word p_align; // 确定段在文件和内存中如何对齐
} Elf32_Phdr;
代码 23-13 ELF 头(include/elf.h)
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT]; // ELF特征标
Elf32_Half e_type; // 文件类型
Elf32_Half e_machine; // 运行至少需要的体系结构
Elf32_Word e_version; // 文件版本
Elf32_Addr e_entry; // 程序的入口点
Elf32_Off e_phoff; // Program Header 表的偏移
Elf32_Off e_shoff; // Section Header 表的偏移
Elf32_Word e_flags; // 对于32位系统为0
Elf32_Half e_ehsize; // ELF Header 的大小,单位字节
Elf32_Half e_phentsize; // Program Header 的大小
Elf32_Half e_phnum; // Program Header 的数量
Elf32_Half e_shentsize; // Section Header 的大小
Elf32_Half e_shnum; // Section Header 的数量
Elf32_Half e_shstrndx; // 包含 Section 名称的字符串表位于哪一项
} Elf32_Ehdr;
其中数据类型 Elf32_Word、Elf32_Off 和 Elf32_Addr 均为大小为 4、对齐也为 4 的无符号类型,而 Word 为大整数,Off 为偏移,Addr 为地址。Half 则顾名思义,是前面这些类型的一半,也就是 2 个字节这么大。因此,在文件开头添加这样的类型定义:
代码 23-14 类型定义(include/elf.h)
#ifndef _ELF_H_
#define _ELF_H_
#include "common.h"
#define PT_LOAD 1
#define EI_NIDENT 16
typedef uint32_t Elf32_Word, Elf32_Off, Elf32_Addr;
typedef uint16_t Elf32_Half;
// ...
#endif
与程序执行直接相关的只有 Program Header,利用它们头中给定的地址把分割成几个部分的程序依次排列在内存中,ELF 解析工作就完成了,接下来从 ELF 头给定的入口点开始执行即可。
(严格来讲其实要做的远比这个要多,什么动态链接、调试符号之类的都要解析 Section Header,但是我们只做最基本的执行的话就不强求了)
那么,我们就来快速地解析一下 ELF 文件。首先新建一个 kernel/elf.c:
代码 23-15 准备开始解析 ELF(kernel/elf.c)
#include "elf.h"
#define min(a, b) ((a) < (b) ? (a) : (b))
#define max(a, b) ((a) < (b) ? (b) : (a))
这里定义了两个一看就懂的宏 max 和 min,个人认为不用解释。
接下来我们就开始准备加载 ELF 了。出于简单的需要,我们把可执行程序的入口点定在 0x00 处;由于这个要求完全做不到,链接器就会自己把整个代码段的开始位置定在这里,然后把入口点略微往后推一点点。既然这样,鉴于这个程序如果直接加载到内存,将位于 1MB 以内,而这一块内存我们根本就不想管,所以我们要另行分配一个缓冲区作为 ELF 解析后的存放地。
那么,知道这个 ELF 在被解析后一共多大就尤为重要了。事实上,这个过程可以在被解析之前进行,只需要遍历每一个 Program Header,同时更新加载首地址最小值与末地址最大值,最后减一下就可以了:
代码 23-16 获取 ELF 被加载后的范围(kernel/elf.c)
static void calc_load_range(Elf32_Ehdr *ehdr, uint32_t *first, uint32_t *last)
{
Elf32_Phdr *phdr = (Elf32_Phdr *) ((uint32_t) ehdr + ehdr->e_phoff); // 第一个 program header 地址
*first = 0xffffffff; // UINT32最大值
*last = 0; // UINT32最小值
for (uint16_t i = 0; i < ehdr->e_phnum; i++) { // 遍历每一个 program header
if (phdr[i].p_type != PT_LOAD) continue; // 只关心LOAD段
*first = min(*first, phdr[i].p_vaddr);
*last = max(*last, phdr[i].p_vaddr + phdr[i].p_memsz); // 每一个program header首尾取最值
}
}
在 ELF 头中放着的 e_phoff 代表第一个 Program Header 的相对 ELF 头的偏移,加上 ELF 头的地址,就得到了第一个 Program Header 的地址。由前面的结构图可以知道,所有的 Program Header 是连续的,因此可以被视为一个数组,其长度则由 ELF 头的 e_phnum 定义。在这么多 Program Header 中,只有类型为 PT_LOAD(其值为 1,在 include/elf.h 中定义)才可以加载,因此我们也就只管这些。这里还是使用经典的指针法进行多值返回。
在获取范围以后就可以分配缓冲区了。假设现在已经分配好了缓冲区,我们要把每个 Program Header 所对应的程序复制到正确的位置去,这就需要知道它们的大小和方向位置。位置比较容易,Program Header 的 p_offset 存的就是相对 ELF 头的位置;大小却有 p_memsz 和 p_filesz 两个值,采信哪个呢?由于我们是要从文件里加载,所以采用 p_filesz 的值,至于可能多出来的部分,那就只能填 0 了。
代码 23-17 复制 ELF 的各个 Program Header(kernel/elf.c)
static void copy_load_segments(Elf32_Ehdr *ehdr, char *buf)
{
Elf32_Phdr *phdr = (Elf32_Phdr *) ((uint32_t) ehdr + ehdr->e_phoff); // 第一个 program header 地址
for (uint16_t i = 0; i < ehdr->e_phnum; i++) { // 遍历每一个 program header
if (phdr[i].p_type != PT_LOAD) continue; // 只关心LOAD段
uint32_t segm_in_file = (uint32_t) ehdr + phdr[i].p_offset; // 段在文件中的位置
memcpy(buf + phdr[i].p_vaddr, (void *) segm_in_file, phdr[i].p_filesz); // 将文件中大小的部分copy过去
uint32_t remain_bytes = phdr[i].p_memsz - phdr[i].p_filesz; // 两者之差
memset(buf + (phdr[i].p_vaddr + phdr[i].p_filesz), 0, remain_bytes); // 赋值为0
}
}
最后便是融合到一起去的整体包装,它会首先检测 ELF 格式是否正确,如果错误会返回 -1,否则返回 ELF 的入口点,也就是开始执行的位置:
代码 23-18 加载 ELF(kernel/elf.c)
int load_elf(Elf32_Ehdr *ehdr, char **buf, uint32_t *first, uint32_t *last)
{
if (memcmp(ehdr->e_ident, "\177ELF\1\1\1", 7)) return -1; // 魔数不对,不予执行
calc_load_range(ehdr, first, last); // 计算加载位移
*buf = (char *) kmalloc(*last - *first + 5); // 用算得的大小分配内存
copy_load_segments(ehdr, *buf); // 把 ELF
return ehdr->e_entry;
}
ELF 头的作用不必多说,这里之所以用两重指针,是因为我们要修改单重指针 buf 的值。在实际使用时只要传一个指针进来就行了,不管这个指针长什么样子。
这样一来,在 buf 中存着的就是二进制一样的机器码了,理论上可以直接启动。事实上也的确如此,在 exec.c 中只需修改几行代码,就可以让一个 ELF 跑起来了:
代码 23-19 启动 ELF(kernel/exec.c)
void app_entry(const char *app_name, const char *cmdline, const char *work_dir)
{
// ...上略...
char *code; // 存放代码的缓冲区
int entry = load_elf((Elf32_Ehdr *) buf, &code, &first, &last); // buf是文件读进来的那个缓冲区,code是存实际代码的
if (entry == -1) task_exit(-1); // 解析失败,直接exit(-1)
// 注意:以下代码非常不安全,仅供参考;不过目前我也没有找到更优的解
// 坑比 intel 在访问 [esp + xxx] 的地址时用的是 ds,ss 完全成了摆设,所以栈和数据必须放在一个段里,于是就炸了
char *ds = (char *) kmalloc(last - first + 4 * 1024 * 1024 + 5); // 新分配一个数据段,为原来大小+4MB+5
memcpy(ds, code, last - first); // 把代码复制过来,也就包含了必须要用的数据
task_now()->ds_base = (int) ds; // 数据段基址,与下面一致
ldt_set_gate(0, (int) code, last - first - 1, 0x409a | 0x60);
ldt_set_gate(1, (int) ds, last - first + 4 * 1024 * 1024 - 1, 0x4092 | 0x60); // 大小也多了4MB
start_app(entry, 0 * 8 + 4, last - first + 4 * 1024 * 1024 - 4, 1 * 8 + 4, &(task_now()->tss.esp0)); // 把栈顶设为4MB-4
while (1);
}
坑比 intel 在访问 [esp + xxx] 的地址时用的是 ds,ss 完全成了摆设,所以栈和数据必须放在一个段里,于是就炸了(重复一遍)。
现在已经可以执行 ELF 了,我们就写一个 C 应用作为测试吧。新建 apps 文件夹,我们就写一个最简单的 Hello World:
代码 23-20 Hello, ELF World!(apps/test_c.c)
#include <stdio.h>
int main()
{
printf("Hello, World!");
return 0;
}
不知道看见这样的程序勾起了你什么回忆呢,总之我是有种回到了刚学 C 语言时的感觉……不煽情了,现在仔细回顾一下这个程序,有什么问题吗?
看似完美无缺,实际上问题非常严重。或许你曾对 main 函数的返回值谁来接收有疑问,当时的回答是操作系统。现在我们就是操作系统,那这个 main 的返回值,是不是也得接收一下?
况且在第五节中提过,ELF 程序的真正入口并不是 main,而是 _start,main 只是一个普通的函数而已。因此,我们需要定义一个 _start。
这个 _start 还是相当好写的,让应用程序接收参数是下一节的话题,不考虑参数的话,只需要调用 main,然后用 exit 结束应用程序即可:
代码 23-21 简单的入口点(apps/start.c)
int main();
void _start()
{
exit(main());
}
接下来怎么编译呢?直接 gcc?那可不行,我们的“标准库”和 Linux 还是不一样的,得链接上我们的标准库才行。
对 Makefile 这么修改一下:
代码 23-22 新的 Makefile(Makefile)
LIBC_OBJECTS = out/syscall_impl.o out/stdio.o out/string.o
out/%.bin : apps/%.asm
nasm apps/$*.asm -o out/$*.o -f elf
i686-elf-ld -s -Ttext 0x0 -o out/$*.bin out/$*.o
out/tulibc.a : $(LIBC_OBJECTS)
i686-elf-ar rcs out/tulibc.a $(LIBC_OBJECTS)
out/%.bin : apps/%.c apps/start.c out/tulibc.a
i686-elf-gcc -c -I include apps/start.c -o out/start.o -fno-builtin
i686-elf-gcc -c -I include apps/$*.c -o out/$*.o -fno-builtin
i686-elf-ld -s -Ttext 0x0 -o out/$*.bin out/$*.o out/start.o out/tulibc.a
这里先用了 ar,把我们的“标准库”——stdio.o(printf,sprintf,vprintf,vsprintf)、string.o(mem 系列和 str 系列)以及 syscall_impl.o(系统调用的实现部分)打成了一个库 tulibc.a,取 TUtorialos LIBC 的意思。libc 则是一种描述标准库的通用简写。然后,分别编译 start.c 和应用程序,最后把应用程序本体、start.o 和 tulibc.a 链接在一起,并设定入口点,形成可以让 TutorialOS 执行的应用程序。
当然,我们也是支持用汇编来编写应用程序的,这个流程就比较简洁,因为没有 main 的特殊包袱,直接编译链接即可。
下面编译硬盘映像的部分,我们也做了修改。
代码 23-23 新的 Makefile(续)(Makefile)
APPS = out/test_c.bin
# 中略
hd.img : out/boot.bin out/loader.bin out/kernel.bin $(APPS)
ftimgcreate hd.img -t hd -size 80
ftformat hd.img -t hd -f fat16
ftcopy out/loader.bin -to -img hd.img
ftcopy out/kernel.bin -to -img hd.img
ftcopy out/test_c.bin -to -img hd.img
dd if=out/boot.bin of=hd.img bs=512 count=1
在 what you need 的部分,我们新添加了一个 APPS 变量,它代表我们需要编译的所有应用,目前只有一个 test_c.bin。编译出来以后,我们在下面的命令中进行写入。
现在应该就可以开始运行了。编译,运行,效果如下:

(图 23-3 Hello, World!)
这一节实在是太长了,到此为止吧。下一节我们来支持 malloc,同时为应用程序传参,然后就可以正式结束啦!提前完结撒花.jpg
24.C语言应用程序(下)
欢迎回来。我们本节的任务十分明确:支持 malloc,同时为应用程序传参。
不过,在一开始我们先来点“轻松”的。或许在第 16 节和第 22 节的时候,有的读者会有这样的疑问:
你 shell 明明集成在内核当中,为什么还要费事去系统调用呢?
所以我们今天的第一个 surprise,就是把 shell 从内核当中给剥离出去,做成一个单独的 app。没有什么原因,只是因为这样泰裤辣!(逃
上一节已经初步支持了 C 语言应用程序,而我们的 shell 一不用传参,二来在一番微操之下规避了 malloc,因此可以直接放在这个框架里。
首先来把现在的 shell 改造成一个应用程序一样的东西:
代码 24-1 现在的 shell(apps/shell.c)
#include <stdio.h>
#include <stddef.h>
#include <stdint.h>
#include <stdbool.h>
#include <unistd.h>
#define MAX_CMD_LEN 100
#define MAX_ARG_NR 30
static char cmd_line[MAX_CMD_LEN] = {0}; // 输入命令行的内容
static char *argv[MAX_ARG_NR] = {NULL}; // argv,字面意思
static void print_prompt() // 输出提示符
{
printf("[TUTO@localhost /] $ "); // 这一部分大家随便改,你甚至可以改成>>>
}
static void readline(char *buf, int cnt) // 输入一行或cnt个字符
{
char *pos = buf; // 不想变buf
while (read(0, pos, 1) != -1 && (pos - buf) < cnt) { // 读字符成功且没到cnt个
switch (*pos) {
case '\n':
case '\r': // 回车或换行,结束
*pos = 0;
putchar('\n'); // read不自动回显,需要手动补一个\n
return; // 返回
case '\b': // 退格
if (buf[0] != '\b') { // 如果不在第一个
--pos; // 指向上一个位置
putchar('\b'); // 手动输出一个退格
}
break;
default:
putchar(*pos); // 都不是,那就直接输出刚输入进来的东西
pos++; // 指向下一个位置
}
}
}
static int cmd_parse(char *cmd_str, char **argv, char token)
{
int arg_idx = 0;
while (arg_idx < MAX_ARG_NR) {
argv[arg_idx] = NULL;
arg_idx++;
} // 开局先把上一个argv抹掉
char *next = cmd_str; // 下一个字符
int argc = 0; // 这就是要返回的argc了
while (*next) { // 循环到结束为止
if (*next != '"') {
while (*next == token) *next++; // 多个token就只保留第一个,windows cmd就是这么处理的
if (*next == 0) break; // 如果跳过完token之后结束了,那就直接退出
argv[argc] = next; // 将首指针赋值过去,从这里开始就是当前参数
while (*next && *next != token) next++; // 跳到下一个token
} else {
next++; // 跳过引号
argv[argc] = next; // 这里开始就是当前参数
while (*next && *next != '"') next++; // 跳到引号
}
if (*next) { // 如果这里有token字符
*next++ = 0; // 将当前token字符设为0(结束符),next后移一个
}
if (argc > MAX_ARG_NR) return -1; // 参数太多,超过上限了
argc++; // argc增一,如果最后一个字符是空格时不提前退出,argc会错误地被多加1
}
return argc;
}
void cmd_ver(int argc, char **argv)
{
puts("TutorialOS Indev");
}
int try_to_run_external(char *name, int *exist)
{
int ret = create_process(name, cmd_line, "/");
*exist = false;
if (ret == -1) {
char new_name[MAX_CMD_LEN] = {0};
strcpy(new_name, name);
int len = strlen(name);
new_name[len] = '.';
new_name[len + 1] = 'b';
new_name[len + 2] = 'i';
new_name[len + 3] = 'n';
new_name[len + 4] = '\0';
ret = create_process(new_name, cmd_line, "/");
if (ret == -1) return -1;
}
*exist = true;
ret = waitpid(ret);
return ret;
}
void cmd_execute(int argc, char **argv)
{
if (!strcmp("ver", argv[0])) {
cmd_ver(argc, argv);
} else {
int exist;
int ret = try_to_run_external(argv[0], &exist);
if (!exist) {
printf("shell: `%s` is not recognized as an internal or external command or executable file.\n", argv[0]);
} else if (ret) {
printf("shell: app `%s` exited abnormally, retval: %d (0x%x).\n", argv[0], ret, ret);
}
}
}
void shell()
{
puts("TutorialOS Indev (tags/Indev:WIP, Jun 26 2024, 21:09) [GCC 32bit] on baremetal"); // 看着眼熟?这一部分是从 Python 3 里模仿的
puts("Type \"ver\" for more information.\n"); // 示例,只打算支持这一个
while (1) { // 无限循环
print_prompt(); // 输出提示符
memset(cmd_line, 0, MAX_CMD_LEN);
readline(cmd_line, MAX_CMD_LEN); // 输入一行命令
if (cmd_line[0] == 0) continue; // 啥也没有,是换行,直接跳过
int argc = cmd_parse(cmd_line, argv, ' '); // 解析命令,按照cmd_parse的要求传入,默认分隔符为空格
cmd_execute(argc, argv); // 执行
}
puts("shell: PANIC: WHILE (TRUE) LOOP ENDS! RUNNNNNNN!!!"); // 到不了,不解释
}
int main()
{
shell();
return 0;
}
从上面的文件名就可以知道,我们已经把 shell 挪到了 apps 目录下;同时,在最后也加了一个 int main(),虽然说可以直接在 shell() 上改,但留点遗存也不是不行(?)
下面引入了一堆头文件,其中的 unistd.h 是上一节所造,stdio.h 早已有之,剩下的 stdint.h、 stdbool.h 以及 stddef.h 是从 common.h 里分离出来的产物:
代码 24-2 三个头文件(include/stdint.h、include/stdbool.h、include/stddef.h)
#ifndef _STDINT_H_
#define _STDINT_H_
typedef unsigned int uint32_t;
typedef int int32_t;
typedef unsigned short uint16_t;
typedef short int16_t;
typedef unsigned char uint8_t;
typedef char int8_t;
#endif
#ifndef _STDBOOL_H_
#define _STDBOOL_H_
typedef _Bool bool;
#define true 1
#define false 0
#endif
#ifndef _STDDEF_H_
#define _STDDEF_H_
#define NULL ((void *) 0)
#endif
如你所见,这三个头文件基本上全都很短小,什么安全保护措施也没加,毕竟纯玩玩也用不到,到时候从什么地方copy一个就行了(bushi)。
另外,在 stdio.h 中把 #include "common.h" 替换成了 #include "string.h" 和 #include "stdint.h" 两行,在 unistd.h 的函数声明开始前增加了一行 #include "stdint.h"。这样做是为了确保这些标准库文件与操作系统文件无关 其实就是闲的。
接下来在 kernel_main 启动 shell 的部分也要修改:
代码 24-3 启动 shell(kernel/main.c)
void kernel_main() // kernel.asm会跳转到这里
{
monitor_clear();
init_gdtidt();
init_memory();
init_timer(100);
init_keyboard();
asm("sti");
task_init();
sys_create_process("shell.bin", "", "/");
task_exit(0);
}
task_a 变量从头到尾没有被用到,因此就删了。下面的 sys_create_process 实质上开启了一个新任务执行 shell.bin。最后,调用 task_exit(0) 退出当前任务,于是操作系统就进入后台,而主要是 ring3 用户层的 shell 在起交互作用了。
在 Makefile 的 APPS 中加入 out/shell.bin,OBJS 中删除 out/shell.o,完成最后的交接。shell 的地位甚至因此还提升了(?)
最后当然是编译运行啦:

(图 24-1 效果)
执行内部命令还是应用程序都没问题,不过按理来说也算理所应当吧,到最后也没做多少修改(笑)。
热身完成,筋骨也活动得差不多了,也该回顾一下上一节的两大目标:实现 malloc 以及给应用程序传参。
说到底,这其实是同一个问题:如果应用程序能直接访问操作系统的内存不就好了?这样可以直接使用 kmalloc、kfree,传参随便写个系统调用也就可以做到了。可是应用程序只能访问应用程序段自己的地址,这是出于安全的考虑:如果应用程序能访问操作系统的内存,那不就能随便破坏了吗。
所以,现在的问题就变成了:要由操作系统提供一段位于应用程序数据段内的内存,接下来就可以让应用程序自治,通过系统调用等等手段从这里获取内存。
对 C 语言有些了解的读者应该知道,malloc 实际上是从一个叫“堆”的地方获取内存的;它并不是直接的系统调用,真正用于向操作系统申请内存的系统调用是 brk、 sbrk 和 mmap。mmap 的本意是将文件内容映射到内存当中,与普通的读取不同的是,对映射后内存的修改会立刻同步到文件;而通过使用一些特殊文件,就可以实现凭空申请内存的效果。
然而,实现一个 mmap 对我们来说太过困难,准备一个特殊文件也不在现有的框架之内,因此就算了。接下来的 brk 和 sbrk,一看名字就知道是一对函数,查阅 linux manual 知道它们操控着一个叫做 program break 的玩意。手册上说它是什么数据段的终止,这是什么不知道;不过使用这两个函数可以修改这个位置,从而给数据段里凭空多出内存来,这就是为我们所用的内存了。
brk 是直接设置 program break,我还得自己维护上一个位置才能申请,相比之下,还是直接使用 sbrk 更加直接,它的参数是增量,返回的是旧的 program break 的位置,原型如下:
void *sbrk(int incr);
和 malloc 一对比,是不是看着很接近?更棒的是,incr 还可以是负数,相当于在释放用完的内存;也就是说,用 sbrk 一个函数就可以实现内存的分配和释放,接下来就只是管理的事了。
那么我们最终的问题,就变成了两个:
-
如何实现
sbrk; -
如何通过
sbrk实现malloc。
先从第一个开始吧。既然所谓的 program break 表示数据段的终止,我们先来实现一个可以用来扩张数据段的函数。不过说是扩张,到头来其实也还是删掉旧的创建新的。
内核的数据段已经占满了 4GB,给内核实现扩张毫无意义。因此,我们给任务添加一个 is_user 标签,表示是不是应用程序:
代码 24-4 添加新标签(include/mtask.h、kernel/mtask.c、kernel/exec.c)
typedef struct TASK {
uint32_t sel;
int32_t flags;
exit_retval_t my_retval;
int fd_table[MAX_FILE_OPEN_PER_TASK];
gdt_entry_t ldt[2];
int ds_base;
bool is_user; // here
tss32_t tss;
} task_t;
for (int i = 3; i < MAX_FILE_OPEN_PER_TASK; i++) {
task->fd_table[i] = -1;
}
task->is_user = false; // here
return task;
void app_entry(const char *app_name, const char *cmdline, const char *work_dir)
{
int fd = sys_open((char *) app_name, O_RDONLY);
int size = sys_lseek(fd, -1, SEEK_END) + 1;
sys_lseek(fd, 0, SEEK_SET);
char *buf = (char *) kmalloc(size + 5);
sys_read(fd, buf, size);
int first, last;
char *code;
int entry = load_elf((Elf32_Ehdr *) buf, &code, &first, &last);
if (entry == -1) task_exit(-1);
char *ds = (char *) kmalloc(last - first + 4 * 1024 * 1024 + 5);
memcpy(ds, code, last - first);
task_now()->is_user = true; // here
task_now()->ds_base = (int) ds;
ldt_set_gate(0, (int) code, last - first - 1, 0x409a | 0x60);
ldt_set_gate(1, (int) ds, last - first + 4 * 1024 * 1024 + 1 * 1024 * 1024 - 1, 0x4092 | 0x60);
start_app(entry, 0 * 8 + 4, last - first + 4 * 1024 * 1024 - 4, 1 * 8 + 4, &(task_now()->tss.esp0));
while (1);
}
接下来就可以实现给用户扩张数据段的函数了:
代码 24-5 扩张数据段(kernel/exec.c)
static void expand_user_segment(int increment)
{
task_t *task = task_now();
if (!task->is_user) return; // 内核都打满4GB了还需要扩容?
gdt_entry_t *segment = &task->ldt[1];
// 接下来把base和limit的石块拼出来
uint32_t base = segment->base_low | (segment->base_mid << 16) | (segment->base_high << 24); // 其实可以不用拼直接用ds_base 但还是拼一下吧当练习
uint32_t size = segment->limit_low | ((segment->limit_high & 0x0F) << 16);
if (segment->limit_high & 0x80) size *= 0x1000;
size++;
// 分配新的内存
void *new_base = (void *) kmalloc(size + increment + 5);
if (increment > 0) return; // expand是扩容你缩水是几个意思
memcpy(new_base, (void *) base, size); // 原来的内容全复制进去
// 用户进程的base必然由malloc分配,故用free释放之
kfree((void *) base);
// 那么接下来就是把new_base设置成新的段了
ldt_set_gate(1, (int) new_base, size + increment - 1, 0x4092 | 0x60); // 反正只有数据段允许扩容我也就设置成数据段算了
task->ds_base = (int) new_base; // 既然ds_base变了task里的应该同步更新
}
开头三行显然不需要解释。接下来把应用程序数据段的基址(这样我才知道从哪拿到旧数据)和大小(这样我才知道新的需要多大)拼出来。死去的 GDT 又开始攻击我们了,偷一个小图过来:

(图 24-2 GDT 描述符结构)
以及它的代码表示:
struct gdt_entry_struct {
uint16_t limit_low; // BYTE 0~1
uint16_t base_low; // BYTE 2~3
uint8_t base_mid; // BYTE 4
uint8_t access_right; // BYTE 5, P|DPL|S|TYPE (1|2|1|4)
uint8_t limit_high; // BYTE 6, G|D/B|0|AVL|limit_high (1|1|1|1|4)
uint8_t base_high; // BYTE 7
} __attribute__((packed));
typedef struct gdt_entry_struct gdt_entry_t;
按照这个结构再去看上面的代码,拼 base 是显而易见的,拼 limit 则涉及到一个 G 位的问题:G 位位于 limit_high 的最高位,当它为 1 时,代表整个 limit 代表的是一个以 4KB 为单位的段(说白了就是要给 limit 乘上 4096)。拼完以后由于 limit 加 1 才是 size,所以再把 1 给加上。
接下来重新分配一段新的数据段,把旧的东西全都复制过去,唯一的变化就是大小变大了。旧的数据段留着也没有用,既然前面初始化是用 kmalloc 初始化的 ds,新的段也使用 kmalloc 分配,所以可以安全地使用 kfree 把内存释放掉。最后调用 ldt_set_gate 把数据段换成新的,同时更新 task 里的 ds_base,这样如假包换,应用程序毫无感知。
接下来就是实现 sbrk 了。上面的 program break 说是数据段结尾,但如果老是更新数据段的话,内存也吃不消,速度也会慢上一点(不过不仔细看的话,大概是看不出来的)。所以我们先临时开 1MB 缓冲区,这 1MB 用完了再扩展至少 32KB,这样也许会把占用搞小一点(心虚)。
因此,存 program break 不仅要存它现在的位置,还要存给它的缓冲区在哪里结束,这样才可以扩展数据段。
代码 24-6 实现 sbrk(1)——创建 program break(include/mtask.h)
typedef struct TASK {
uint32_t sel;
int32_t flags;
exit_retval_t my_retval;
int fd_table[MAX_FILE_OPEN_PER_TASK];
gdt_entry_t ldt[2];
int ds_base;
bool is_user;
void *brk_start, *brk_end; // here
tss32_t tss;
} task_t;
接下来在 app_entry 中初始化它:
代码 24-7 实现 sbrk(2)——初始化 program break(kernel/exec.c)
void app_entry(const char *app_name, const char *cmdline, const char *work_dir)
{
int fd = sys_open((char *) app_name, O_RDONLY);
int size = sys_lseek(fd, -1, SEEK_END) + 1;
sys_lseek(fd, 0, SEEK_SET);
char *buf = (char *) kmalloc(size + 5);
sys_read(fd, buf, size);
int first, last;
char *code;
int entry = load_elf((Elf32_Ehdr *) buf, &code, &first, &last);
if (entry == -1) task_exit(-1);
char *ds = (char *) kmalloc(last - first + 4 * 1024 * 1024 + 1 * 1024 * 1024 - 5);
memcpy(ds, code, last - first);
task_now()->is_user = true;
// 这一块就是给用户用的
task_now()->brk_start = (void *) last - first + 4 * 1024 * 1024;
task_now()->brk_end = (void *) last - first + 5 * 1024 * 1024 - 1;
task_now()->ds_base = (int) ds; // 设置ds基址
ldt_set_gate(0, (int) code, last - first - 1, 0x409a | 0x60);
ldt_set_gate(1, (int) ds, last - first + 4 * 1024 * 1024 + 1 * 1024 * 1024 - 1, 0x4092 | 0x60);
start_app(entry, 0 * 8 + 4, last - first + 4 * 1024 * 1024 - 4, 1 * 8 + 4, &(task_now()->tss.esp0));
while (1);
}
最后就是 sbrk 的本体了,为了偷懒也放在了 kernel/exec.c 下面(虽然放这里好像不大好?):
代码 24-8 实现 sbrk(3)——操控 program break(kernel/exec.c)
void *sys_sbrk(int incr)
{
task_t *task = task_now();
if (task->is_user) { // 是应用程序
if (task->brk_start + incr > task->brk_end) { // 如果超出已有缓冲区
expand_user_segment(incr + 32 * 1024); // 再多扩展32KB
task->brk_end += incr + 32 * 1024; // 由于扩展了32KB,同步将brk_end移到现在的数据段结尾
}
void *ret = task->brk_start; // 旧的program break
task->brk_start += incr; // 直接添加就完事了
return ret; // 返回之
}
return NULL; // 非用户不允许使用sbrk
}
到现在为止,就实现了最基本的向内核申请内存的函数。接下来把它搞成一个系统调用,sbrk 就可以使用了:
代码 24-9 实现 sbrk(4)——添加系统调用(include/syscall.h、kernel/syscall.c、kernel/syscall_impl.asm)
#ifndef _SYSCALL_H_
#define _SYSCALL_H_
// 上略...
// exec.c
void *sys_sbrk(int incr);
#endif
switch (eax) {
// 上略...
case 10:
ret = (int) sys_sbrk(ebx);
break;
}
// 下略...
[global sbrk]
sbrk:
push ebx
mov eax, 10
mov ebx, [esp + 8]
int 80h
pop ebx
ret
加了十个系统调用了,相信大家也应该大致熟悉了添加系统调用的流程了吧:首先实现系统调用本身,然后在 syscall.c 的 switch-case 里新加一个分支,最后用汇编仿照格式写一个实现,没有参数(getpid)、一个参数(一堆不列举)、两个参数(open)、三个参数(一堆不列举)的系统调用目前都有了。
下面执行第二步,用 sbrk 实现 malloc。这个网上教程有一大堆,你干脆直接移植 ptmalloc 都行,这里我选择了一种最简单但同时大概也是最不稳定 ??跑在 CoolPotOS 上成功造成了 114514 次异常?? 的一种。
新建 lib/malloc.c,这就是我们 malloc 的实现。
我们的堆实质上是一块一块的内存碎片,这些碎片采用链表的方式来组织,以下是每一个链表的节点:
代码 24-10 串联可用内存的链表节点(lib/malloc.c)
#include <unistd.h>
#include <stddef.h>
typedef char ALIGN[16];
typedef union header {
struct {
uint32_t size;
uint32_t is_free;
union header *next;
} s;
ALIGN stub;
} header_t;
static header_t *head, *tail;
ALIGN 纯粹是用来对齐的类型,据传给搞成 16 字节对齐的地址能够使 CPU 更高效。里面的 s 成员才是会真正用到的部分,三个成员干什么的一看就明白:size 是碎片大小,is_free 是可用与否,next 是下一个节点。
接下来我们来找一个能够盛下待分配内存的节点。这个过程很简单,顺着链表找下去就完了。
代码 24-11 寻找能盛下待分配内存的节点(lib/malloc.c)
// 寻找一个符合条件的指定大小的空闲内存块
static header_t *get_free_block(uint32_t size)
{
header_t *curr = head; // 从头开始
while (curr) {
if (curr->s.is_free && curr->s.size >= size) return curr; // 空闲,并且大小也满足条件,直接返回
curr = curr->s.next; // 下一位
}
return NULL; // 找不到
}
然后就可以开始实现 malloc 了。先把代码放在这里,后面再慢慢解说。
代码 24-12 实现 malloc(lib/malloc.c)
void *malloc(uint32_t size)
{
uint32_t total_size;
void *block;
header_t *header;
if (!size) return NULL; // size == 0,自然不用返回
header = get_free_block(size);
if (header) { // 找到了对应的header!
header->s.is_free = 0;
return (void *) (header + 1);
// header + 1,相当于把header的值在指针上后移了一个header_t,从而在返回的内存中不存在覆写header的现象
}
// 否则,申请内存
total_size = sizeof(header_t) + size; // 需要一处放header的空间
block = sbrk(total_size); // sbrk,申请total_size大小内存
if (block == (void *) -1) return NULL; // 没有足够的内存,返回NULL
// 申请成功!
header = block; // 初始化header
header->s.size = size;
header->s.is_free = 0;
header->s.next = NULL;
if (!head) head = header; // 第一个还是空的,直接设为header
if (tail) tail->s.next = header; // 有最后一个,把最后一个的next指向header
tail = header; // header荣登最后一个
return (void *) (header + 1); // 同上
}
前三行声明变量不用管,紧接着当 size 为 0 时自然无需分配,返回 NULL 即可。接下来寻找可用的节点,如果找到了,则直接暴力占用这个节点,同时返回 header + 1 这个位置。这个位置是干什么的,想必不用啰嗦。
接下来讨论没找到的情况,这时再去找操作系统使用 sbrk 申请内存。由于使用了 header + 1,内存块的开头应该是一个 header_t,要给加上这一片内存。
接下来 if (block == (void *) -1) 是在干什么呢?按照标准规定,当 sbrk 失败时应当返回 -1,但我们的 sbrk 不会失败,就导致这一行没有用了。
然后就是把这个内存块初始化,连到链表里并返回。由于只能直接知道链表末尾的位置,把它串联到末尾。最后返回 header + 1 跳过刚刚构造的 header_t 结构。
malloc 完了,紧接着实现 free,基本上差不多简单:
代码 24-13 实现 free(lib/malloc.c)
void free(void *block)
{
header_t *header, *tmp;
if (!block) return; // free(NULL),有什么用捏
header = (header_t *) block - 1; // 减去一个header_t的大小,刚好指向header_t
if ((char *) block + header->s.size == sbrk(0)) { // 正好在堆末尾
if (head == tail) head = tail = NULL; // 只有一个内存块,全部清空
else {
// 遍历整个内存块链表,找到对应的内存块,并把它从链表中删除
tmp = head;
while (tmp) {
// 如果内存在堆末尾,那这个块肯定也在链表末尾
if (tmp->s.next == tail) { // 下一个就是原本末尾
tmp->s.next = NULL; // 踢掉
tail = tmp; // 末尾位置顶替
}
tmp = tmp->s.next; // 下一个
}
}
// 释放这一块内存
sbrk(0 - sizeof(header_t) - header->s.size);
return;
}
// 否则,设置为free
header->s.is_free = 1;
}
首先判断 block 是不是 NULL,然后把 block 减去一个 header 的大小,拿到对应的 header。如果这个块正好在堆末尾,那就涉及到把这段内存归还给操作系统的事情;否则,直接把属性设置成 free 就可以为前面的 get_free_block 所用。
中间的大 if 就是在向操作系统归还内存,首先判断能不能归还,只要当前的这个内存正好抵着现在的 program break,那就可以把这段内存归还。首先判断是不是只有这一个内存块,如果是的话直接清空整个链表即可;否则,由于链表中的内存块按分配先后顺序排列,那么在堆末尾的内存块,一定也在链表末尾。所以,这里直接遍历整个链表,在即将到达末尾的时候把末尾内存块踢出链表,并同时更新现在的末尾位置。最后,就可以释放掉这个内存块对应大小的内存,以及这个内存块本身占据的内存。以免你忘了,sbrk 可以使用正数分配、负数释放。而使用 sbrk(0),则相当于返回现在的 program break,因为它的行为相当于给原 program break 加 0 再返回旧的。
好了,一个简单的 malloc/free 就已经实现了,居然连 100 行都不到,应该很简单吧。
有了 malloc 打底(事实上有 sbrk 就够了),给应用程序传参也就不是什么难事,malloc 就等着写完应用程序传参再测吧。
既然给应用程序传参是通过函数的参数,我们就操作新应用程序的栈。或许有人就要问了:
既然 shell 里解析出了 argc 和 argv,为什么不直接传,反而传的是 cmdline 呢?
这是因为,argc 固然好传,但 argv 并不好传。相比之下 cmdline 好传得多,只需要分配一块内存,把 cmdline 复制进去,然后往栈里写一个指向新内存的指针即可。
这也正是我们所要做的,请看下面的代码:
代码 24-14 向应用程序传入 cmdline(kernel/exec.c)
// 接下来把cmdline传给app,解析工作由CRT完成
// 这样我就不用管怎么把一个char **放到栈里了((((
int new_esp = last - first + 4 * 1024 * 1024 - 4;
int prev_brk = sys_sbrk(strlen(cmdline) + 5); // 分配cmdline这么长的内存,反正也输入不了1MB长的命令
strcpy((char *) (ds + prev_brk), cmdline); // sys_sbrk使用相对地址,要转换成以ds为基址的绝对地址需要加上ds
*((int *) (ds + new_esp)) = (int) prev_brk; // 把prev_brk的地址写进栈里,这个位置可以被_start访问
new_esp -= 4; // esp后移一个dword
// 中略
start_app(entry, 0 * 8 + 4, new_esp, 1 * 8 + 4, &(task_now()->tss.esp0));
sys_sbrk 返回的是相对 ds_base 的地址,所以下面的操作都要手动加上它。接下来手动存了一下新的 esp,这是为了化简程序。然后直接调用 sbrk 而不是 malloc 分配空间,没有中间商赚差价,牢记 sbrk 返回的是调用之前的 program break,所以此时的 prev_brk 正好就是新内存的起点。
接下来调用 strcpy,向新内存写入 cmdline,为什么加 ds 前面已经说了。最后往栈里写入已经指向这片区域的 prev_brk,并同时把栈后移 4 位,这样让 esp + 4 指向 prev_brk,后面就可以从这里读出 cmdline。
这边写完了,从 C 里读就更简单了,先从 shell 里偷一个 cmd_parse,然后如此修改 _start:
代码 24-15 能够接收参数的(apps/start.c)
#include <unistd.h>
#include <stddef.h>
#define MAX_ARG_NR 30
static char *argv[MAX_ARG_NR] = {NULL}; // argv,字面意思
int main(int argc, char **argv);
static int cmd_parse(char *cmd_str, char **argv, char token)
{
// shell.c里有自己抄去难道这个还要我给你写吗)))
}
void _start(char *cmdline)
{
int argc = cmd_parse(cmdline, argv, ' ');
exit(main(argc, argv));
}
看上去复杂了不少,不过没什么需要注意的,基本上都挺直接吧。
哦对了,cmd_parse 会修改 cmd_str 的内容,所以在 shell 里要备份一下 cmd_line,然后把备份的传进 create_process:
代码 24-16 shell 里杂七杂八的小修改(apps/shell.c)
static char cmd_line[MAX_CMD_LEN] = {0}; // 输入命令行的内容
static char cmd_line_back[MAX_CMD_LEN] = {0}; // 这一行是新加的
static char *argv[MAX_ARG_NR] = {NULL}; // argv,字面意思
int try_to_run_external(char *name, int *exist)
{
int ret = create_process(name, cmd_line_back, "/"); // 这里经过修改
*exist = false;
if (ret == -1) {
// 略过添加.bin的处理
ret = create_process(new_name, cmd_line_back, "/"); // 这里经过修改
if (ret == -1) return -1;
}
*exist = true;
ret = waitpid(ret);
return ret;
}
现在,应用程序应该就已经可以接收参数了,可是拿什么来测试呢?根据我的经验,自己实现的东西都不能够说明问题,所以我们直接移植一个小程序玩玩吧!
要想规模小、我们目前的系统调用就足够,还得有点实际用途能看出来成果,这条件虽然苛刻,但我还是成功找到了一个项目:C in four functions,只有区区 500 行,且用到的大部分东西都已经实现。唯一需要注意的是 memory.h 和 fcntl.h 虽然没有,但里面的东西都已经实现,把 include 他们俩那两行注释掉即可。
添加了新的应用程序,Makefile 也要修改,在 APPS 中添加一个 out/c4.bin,并在 hd.img 里写入:
代码 24-17 写入 hd.img 的内容(Makefile)
hd.img : out/boot.bin out/loader.bin out/kernel.bin $(APPS)
ftimgcreate hd.img -t hd -size 80
ftformat hd.img -t hd -f fat16
ftcopy out/loader.bin -to -img hd.img
ftcopy out/kernel.bin -to -img hd.img
ftcopy out/test_c.bin -to -img hd.img
ftcopy out/test2.bin -to -img hd.img
ftcopy out/shell.bin -to -img hd.img
ftcopy out/c4.bin -to -img hd.img
ftcopy apps/test_c.c -to -img hd.img
ftcopy apps/c4.c -to -img hd.img
dd if=out/boot.bin of=hd.img bs=512 count=1
我们不仅添加了 c4.bin,还添加了 test_c.c 和 c4.c。因为 c4 其实是一个小型的 C 解释器,可以直接执行 C 代码,但它是移植来的,这里不多做讲解。总之,既然能执行 C 代码,就得有 C 代码,c4.c 和 test_c.c 就是两个规模大和规模小的测试文件。
现在终于可以编译运行,效果应如下图:

(图 24-2 来自 c4 的 Hello, World!)
首先执行了编译的原生 test_c,然后用 c4 执行源代码 test_c.c,都没有问题;后来又先用 c4 自己运行自己 c4.c,然后再执行 test_c.c,再往下甚至又多套了一层,也是毫无问题。当然了,执行速度肯定是顺次往下越来越慢。c4 里也用到了 malloc,一石二鸟,这说明我们做的工作都成功了!
忽然想起我们分配的资源来,之前在 exit 的时候都没有妥善释放,但经过测试,exit 的时候释放会出现莫名其妙的问题,所以只能放在 wait 里释放了,不知道这算不算一种我们 OS 特有的僵尸进程……(笑)
代码 24-18 释放任务所占资源(kernel/mtask.c)
int task_wait(int pid)
{
task_t *task = &taskctl->tasks0[pid]; // 找出对应的task
while (task->my_retval.pid == -1); // 若没有返回值就一直等着
task->flags = 0; // 释放为可用
// 总算把你等死了,释放该任务所占资源
for (int i = 3; i < MAX_FILE_OPEN_PER_TASK; i++) {
if (task->fd_table[i] != -1) sys_close(task->fd_table[i]); // 关闭所有打开的文件
}
// 该任务malloc的所有东西都在数据段里,所以释放了数据段就相当于全释放了
if (task->is_user) kfree((void *) task->ds_base); // 释放数据段
return task->my_retval.val; // 拿到返回值
}
再编译运行一遍,当然是毫无问题啦。这意味着我们的 OS 之旅终于可以暂告一段落了。
不过告一段落是一方面,怎么总感觉差点东西?这个 work_dir 参数加了怎么没有用到呢?既然 ftcopy 支持目录为什么我们不支持呢?嗯……
本来以为这一节就可以结束教程了,没想到还留了这一个瑕疵,就当是一个小尾巴吧。下一节我们将在原有文件系统的基础上进行修改,实现目录,或许还有一些其他的高级玩意哦。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)