【tensorflow:Google】三、tensorflow入门
【一】计算图模型
节点是计算,边是数据流,
a = tf.constant( [1., 2.] )定义的是节点,节点有属性 a.graph
取得默认计算图 g1 = tf.get_default_graph()
初始化计算图 g1 = tf.Graph()
设置default图 g1.as_default()
定义变量: tf.get_variable('v')
读取变量也是上述函数
对图指定设备 g.device('/gpu:0')
可以定义集合来管理计算图中的资源,
加入集合 tf.add_to_collection
获取集合 tf.get_collection
自动管理一些集合
【二】数据模型——张量
所有的数据都用张量表示,n阶张量是n维数据,0维为标量(scalar)
张量中不保存数字,而是计算过程!得到的是对结果的一个引用。(如果还没run,那么一定是没结果的)
主要有三个属性:
1、名字
2、维度
3、数据类型
命名:节点的名称 + 是节点的第几个输出。节点本身没有这个数据类型,只有张量这个数据类型。
张量的使用
1、记录中间计算结果,提高代码可读性
2、计算图构造完成之后,获得计算结果(需要通过Session) tf.Session().run(result)
【三】运行模型——会话 Session
sess = tf.Session()
两种等价的表达:
sess.run(result)
result.eval(session = sess)
sess.close()
默认会话机制:
sess = tf.InteractiveSession()
之后.eval()不需要指定session参数
在生成session的过程中也可以使用config来管理,
config = tf.ConfigProto(并行的线程数,GPU分配策略,运算超时时间,)
allow_soft_placement的意思是不支持GPU的时候使用CPU。
log_device_placement是记录每个节点被安排在哪个设备上,方便测试。
【四】利用tensorflow实现神经网络
前向传播算法简介:就是一步一步传过来。。。完全没说参数是怎么训练的。。。
tf.Variable生成变量
tf.random_xxx是随机数生成函数
tf.matmul()矩阵乘法
前向传播过程:
1、定义变量、常量、矩阵乘法
2、初始化变量: sess.run(w1.initializer)
另外的方案:使用 init_op = tf.initialize_all_variables() sess.run(init_op)来实现。
3、运行: sess.run(y)
变量是张量的一个特殊形式,一般有 .assign和.read方法,分别实现写/读功能
变量一般分两种:
1、可训练的:神经网络权重
2、不可训练:迭代轮数
优化算法的默认优化对象是tf.GraphKeys.TRAINABLE_VARIABLES里面的变量。
变量类型不可改变,但是变量维度可以改变
改变方式为 assign的时候加入参数 validate_shape=False
训练流程:
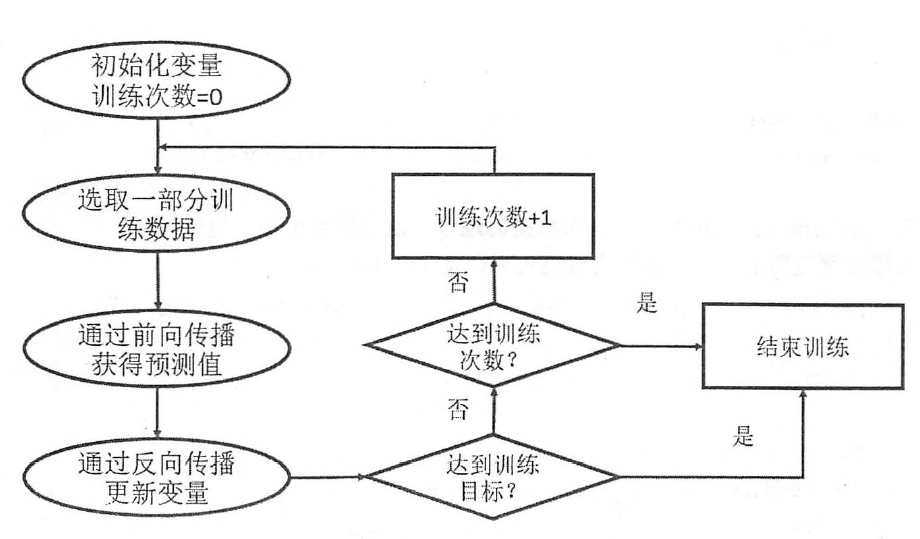
placeholder机制:定义一个位置,需要在程序运行的时候填充数据,
计算前向传播结果的伪代码:
init 权重variable
init x placeholder
init a = tf.matmul(x, w1)
sess = Session()
init_op = init_all
sess.run(init_op)
sess.run(y, feed_dict={x: [0.1, 0.2]})
接下来定义损失函数、反向传播算法
实现一个简单的神经网络解决手写数字识别问题!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号