
有了DD,还会有人用LEX & YACC?
第一章 如何用DD设计词法分析器
用 DD 打开 xml.ddw,第一个 diagram 看到的就是词法分析器的定义,其中定义了各种数据类型(integer,float,string),定义了indentifier,定义了c++应该有的操作符。第一节 可视化定义
1 先看identifier(标识符)怎么定义:
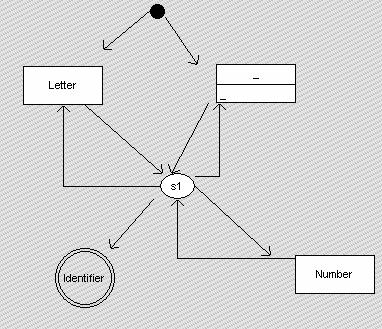
先从黑色小圆点开始,它可以首先遇到letter(a-z大小写字符),或者首先遇到下划线。然后进入状态s1,在s1状态,它有3个去向,letter(字符)、下划线、或者数字。如果都不是,就出来,成为identifier(标识符)。这就是“以字母开头,可以是字母或数字”的标识符定义。
这个定义可以参照加利福尼亚大学的图:http://www-ccs.ucsd.edu/c/syntax.html
2 再看看数字怎么定义

可以看到,如果是全部为数字,则视作整数,如果存在小数点,则视作浮点。
这个定义可以参照加利福尼亚大学的图:http://www-ccs.ucsd.edu/c/syntax.html
其他定义也一幕了然不再赘述。
第二节 生成的代码
通过菜单
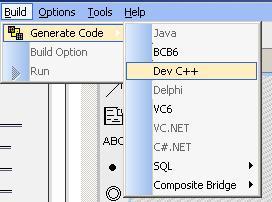
产生代码,看看文件Lex.cpp的GetNextWord函数
.....
584 if(Source[CurrPos]>=L'0' && Source[CurrPos]<=L'9')
585 {
586 CurrPos++;
587 Colume++;
588 goto s101;
589
590 }
.....
643
644 s101:
645 if(Source[CurrPos]>=L'0' && Source[CurrPos]<=L'9')
646 {
647 CurrPos++;
648 Colume++;
649 goto s101;
650
651 }
其中s101的跳转,正是图中s101状态,原来,这段程序都是利用C++的跳转进行状态维护的。584 if(Source[CurrPos]>=L'0' && Source[CurrPos]<=L'9')
585 {
586 CurrPos++;
587 Colume++;
588 goto s101;
589
590 }
.....
643
644 s101:
645 if(Source[CurrPos]>=L'0' && Source[CurrPos]<=L'9')
646 {
647 CurrPos++;
648 Colume++;
649 goto s101;
650
651 }
第二章 如何定义语法
第一节 认识图中用到的元件




元件有:总开始,节点开始,节点结束,常数,节点,标识,关键字,数字,符号,状态等。
第二节 符号
符号是分号,都好,等号等定义,名字要和词法定义的名字一致。
第三节 状态
状态是一种分析状态。在严格的情况下是不必的,但是对于“多入多出”的语法点,用状态可以减少连线。
第四节 节点
节点就是规式左部,要实现它的定义,用节点开始到节点结束来表示。
第五节 XML的语法定义

第六节 生成代码
1 点击菜单:
然后就会得到1600行左右的 Parser.cpp。其中对于XML的TAG的分析都在Is_Tag函数里面实现。
2 所生成的代码如何处理 LR(n)
433 S_E2E8839C55C64321BA2B03B1BEE49BA7://Tag
434 if(current_word->Type==ltLess)//'<'
435 {
436 index_1=index;
437 lookup_right_pass=false;
438 if(!lookup_right_pass)
439 {
440 index_1++;
441 if((*words)[index_1]->Type==ltDiv/*'/'*/)
442 lookup_right_pass=true;
443 index_1--;
444 }
445
446 if(lookup_right_pass)
447 {
448 AddNode(tree,sxtNone,current_word->Type,current_word->Value);
449
450 index++;
451 current_word=(*words)[index];
452 goto S_3446830BCAD449E6A9EBD0512F60EC93;//Less
453 }
454 }

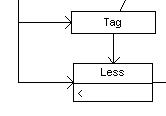
那为什么需要lookup right呢?
因为它为了避免和 TAG 的头冲突 ,所以要往右边多看一个字符,就是看是不是有'/',如果有,则认为是 TAG结束,否则是下一层 TAG :
第三章 如何使用所生成的代码
1 请参看main.cpp的main函数int main(int argc, char* argv[])
{
LFileLoader f(CPP_SYNTAX);
LLex l(CPP_SYNTAX);
.......
f.LoadFile(file_name,true);
l.Compile(f.GetSourceCode());
.....
LParser p(CPP_SYNTAX);
p.Parse(&l.Words);
LWideString prints;
PrintGrammaTree(&p.GrammarTree,prints);
wprintf(prints.GetText());
return 0;
}
首先用f.LoadFile(file_name,true);进行内容装入,并且进行预处理;然后l.Compile(f.GetSourceCode());进行词法分析;接着p.Parse(&l.Words);就是语法分析。最后得到p.GrammarTree的语法树。{
LFileLoader f(CPP_SYNTAX);
LLex l(CPP_SYNTAX);
.......
f.LoadFile(file_name,true);
l.Compile(f.GetSourceCode());
.....
LParser p(CPP_SYNTAX);
p.Parse(&l.Words);
LWideString prints;
PrintGrammaTree(&p.GrammarTree,prints);
wprintf(prints.GetText());
return 0;
}
2 语法树如何遍历
下面代码简单的递归就可以遍历整棵树了。
void PrintGrammaTree(LGrammarTree *tree,LWideString &ret)
{
LGrammarTree::LoopVariant begin,end;
LGrammarTree *theTree;
end=tree->Children.end();
for(begin=tree->Children.begin();begin!=end;begin++)
{
theTree=*begin;
if(theTree->Children.size()==0)
{
ret.Append(L" ");
ret.Append(theTree->Node->Value);
}else
{
ret.Append(L"/*");
ret.Append(theTree->Node->Value);
ret.Append(L"*/");
PrintGrammaTree(theTree,ret);
}
}
}
如果再加上对theTree->Node->Type或者theTree->Node->ExtType的判断就能做语义分析了。注:theTree->Node->Type为sxtNone的时候theTree->Node->ExtTyp才有效,一般用在符号的语法点。{
LGrammarTree::LoopVariant begin,end;
LGrammarTree *theTree;
end=tree->Children.end();
for(begin=tree->Children.begin();begin!=end;begin++)
{
theTree=*begin;
if(theTree->Children.size()==0)
{
ret.Append(L" ");
ret.Append(theTree->Node->Value);
}else
{
ret.Append(L"/*");
ret.Append(theTree->Node->Value);
ret.Append(L"*/");
PrintGrammaTree(theTree,ret);
}
}
}
如果到此还不是很清楚如何遍历语法树的话,再看看一个 XML Reader的 源代码会更清楚(这里下载全部源代码XmlParser.zip)
i 读入TAG是这样写的
static void ReadTag(LGrammarTree *pGrammarTree,tagXmlTree *pXmlTree)
{
LGrammarTree *theTree;
LGrammarTree::LoopVariant begin,end;
tagXmlTree the_xml_tree;
begin=pGrammarTree->Children.begin();
//跳过 '<'
begin++;
//到了tag名字
theTree=*begin;
PrintSyntaxTree(theTree,pXmlTree->TagName);
begin++;
end=pGrammarTree->Children.end();
while(begin!=end)
{
theTree=*begin;
if(theTree->Node->Type==sxtAttributes)
{
ReadAttributes(theTree,pXmlTree->Properties);
}else
if(theTree->Node->Type==sxtTag)
{
the_xml_tree.Children.clear();
ReadTag(theTree,&the_xml_tree);
pXmlTree->Children.push_back(the_xml_tree);
}
begin++;
}
}
{
LGrammarTree *theTree;
LGrammarTree::LoopVariant begin,end;
tagXmlTree the_xml_tree;
begin=pGrammarTree->Children.begin();
//跳过 '<'
begin++;
//到了tag名字
theTree=*begin;
PrintSyntaxTree(theTree,pXmlTree->TagName);
begin++;
end=pGrammarTree->Children.end();
while(begin!=end)
{
theTree=*begin;
if(theTree->Node->Type==sxtAttributes)
{
ReadAttributes(theTree,pXmlTree->Properties);
}else
if(theTree->Node->Type==sxtTag)
{
the_xml_tree.Children.clear();
ReadTag(theTree,&the_xml_tree);
pXmlTree->Children.push_back(the_xml_tree);
}
begin++;
}
}
ii 而读入属性是这样写的
static void ReadAttributes(LGrammarTree *pGrammarTree,StringProperties &pProperties)
{
LGrammarTree *theTree;
LGrammarTree::LoopVariant begin;
wchar_t *attr_name;
wchar_t *attr_value;
int len;
begin=pGrammarTree->Children.begin();
theTree=*begin;
attr_name=theTree->Node->Value.GetText();
begin++;
//跳过 '='
begin++;
theTree=*begin;
attr_value=theTree->Node->Value.GetText();
if(attr_value[0]==L'\"')
{
len=wcslen(attr_value);
if(len>1)
{
attr_value[len-1]=0;
attr_value++;
}
}
LWideString w;
w=attr_name;
pProperties[w]=attr_value;
}
{
LGrammarTree *theTree;
LGrammarTree::LoopVariant begin;
wchar_t *attr_name;
wchar_t *attr_value;
int len;
begin=pGrammarTree->Children.begin();
theTree=*begin;
attr_name=theTree->Node->Value.GetText();
begin++;
//跳过 '='
begin++;
theTree=*begin;
attr_value=theTree->Node->Value.GetText();
if(attr_value[0]==L'\"')
{
len=wcslen(attr_value);
if(len>1)
{
attr_value[len-1]=0;
attr_value++;
}
}
LWideString w;
w=attr_name;
pProperties[w]=attr_value;
}
是不是很简单?
