reidis笔记大全
一:redis基本操作
官方中文文档:http://redis.cn/
1.redis安装、配置、连接
1.下载
wget http://download.redis.io/releases/redis-5.0.7.tar.gz
2.解压
tar -xzf redis-5.0.7.tar.gz
3.建立软连接
ln -s redis-5.0.7 redis # 可以软连接到sbin目录下,这样不用指定路径就可以启动redis
4.进入redis并安装
cd redis
make&&make install
#在redis目录的src目录下可以看到 redis-server--->redis服务器 redis-cli---》redis命令行客户端 redis-benchmark---》redis性能测试工具 redis-check-aof--->aof文件修复工具 redis-check-dump---》rdb文件检查工具 redis-sentinel---》sentinel服务器,哨兵
6.redis的三种启动方式:
6.1.没有配置文件的默认启动方式(用的很少)
./src/redis-server
6.2.指定一些配置启动(用的很少)
./src/redis-server --port 6380
6.3.通过配置文件启动
./src/redis-server conf/redis_6379.conf
daemonize yes # 是否以守护进程启动 pidfile /var/run/redis.pid # 进程号的位置,杀死进程可以直接找到这个进程文件,删除即可 port 6379 # 端口号 dir "/opt/lqz/redis/data" # 工作目录 logfile "6379.log" # 日志文件位置 #bind 127.0.0.1 # 绑定127.0.0.1不支持远程连接 bind 0.0.0.0 # 绑定0.0.0.0支持远程连接,通过输入宿主机的ip地址即可 protected-mode no # 保护模式选项:yes或no requirepass 123456 # 需要远程连接密码:auth+空格+xxx
ps aux|grep redis
redis-cli -h 127.0.0.1 -p 6379 redis-cli # 不指定ip和端口,默认就连接本地6379
kill -9 进程id号 # 强制关闭 redis-cli shutdown
# 方式一: redis-cli -h 10.0.0.200 -p 6379 -a 123456 # -a参数后面直接跟密码 # 方式二: redis-cli -h 10.0.0.200 -p 6379 # 不指定端口默认6379端口 auth 123456 # 注意中间的空格别忘了,密码是根据配置文件中的密码
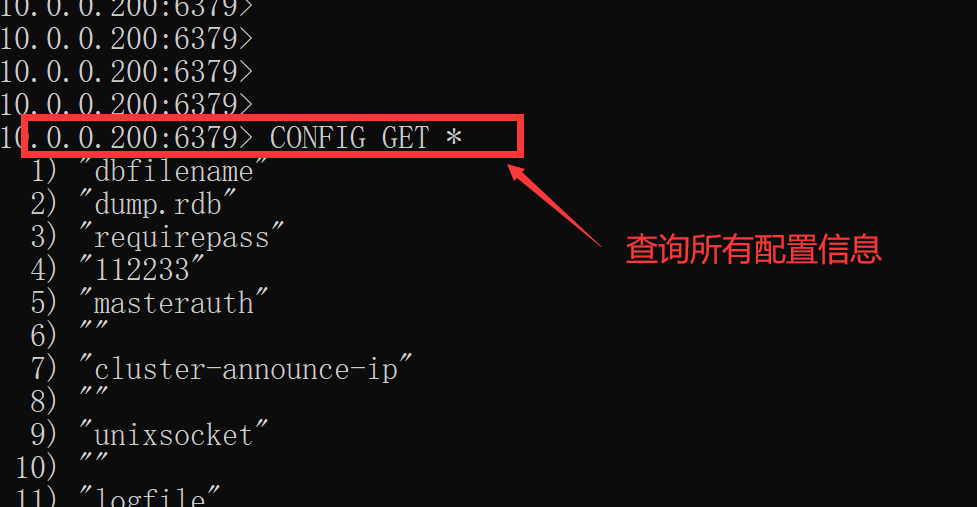
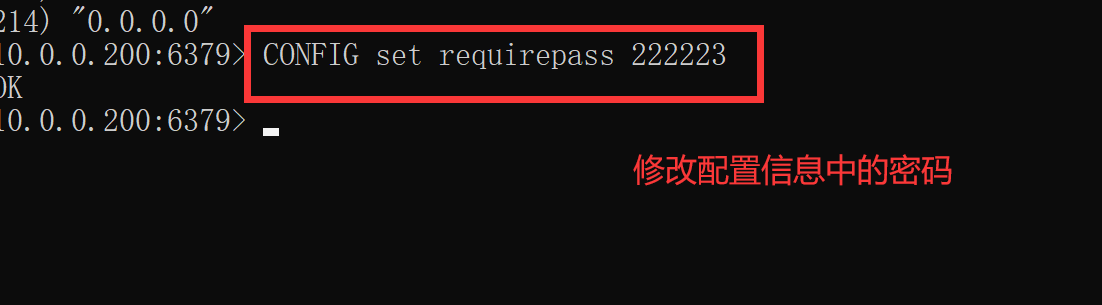
CONFIG GET * # 查看所有配置信息 CONFIG SET maxmemory 128M # 设置最大使用的内存 CONFIG SET requirepass 123456 # 设置密码 CONFIG REWRITE # 把修改写到配置文件中
缓存系统
计数器:网站访问量,转发量,评论数(文章转发,商品销量,单线程模型,不会出现并发问题)
消息队列:发布订阅,阻塞队列实现(简单的分布式,blpop:阻塞队列,生产者消费者)
排行榜:有序集合(阅读排行,点赞排行,推荐(销量高的,推荐))
社交网络:很多特效跟社交网络匹配,粉丝数,关注数
实时系统:垃圾邮件处理系统,布隆过滤器
二:
####1-keys #打印出所有key keys * #打印出所有以he开头的key keys he* #打印出所有以he开头,第三个字母是h到l的范围 keys he[h-l] #三位长度,以he开头,?表示任意一位 keys he? #keys命令一般不在生产环境中使用,生产环境key很多,时间复杂度为o(n),用scan命令 ####2-dbsize 计算key的总数 dbsize #redis内置了计数器,插入删除值该计数器会更改,所以可以在生产环境使用,时间复杂度是o(1) ###3-exists key 时间复杂度o(1) #设置a set a b #查看a是否存在 exists a (integer) 1 #存在返回1 不存在返回0 ###4-del key 时间复杂度o(1) 删除成功返回1,key不存在返回0 ###5-expire key seconds 时间复杂度o(1) expire name 3 #3s 过期 ttl name #查看name还有多长时间过期 persist name #去掉name的过期时间 ###6-type key 时间复杂度o(1) type name #查看name类型,返回string ### 7 其他(自动化监控redis相关项目写一写) info命令:内存,cpu,主从相关 client list 正在连接的会话 (./src/redis-cli -a 123456 client list) client kill ip:端口 dbsize 总共有多少个key flushall 清空所有 flushdb 只清空当前库 select 数字 选择某个库 总共16个库 monitor 记录操作日志,夯住(日志审计)
###1---基本使用get,set,del get name #时间复杂度 o(1) set name lqz #时间复杂度 o(1) del name #时间复杂度 o(1) ###2---其他使用incr,decr,incrby,decrby incr age #对age这个key的value值自增1 decr age #对age这个key的value值自减1 incrby age 10 #对age这个key的value值增加10 decrby age 10 #对age这个key的value值减10 #统计网站访问量(单线程无竞争,天然适合做计数器) #缓存mysql的信息(json格式) #分布式id生成(多个机器同时并发着生成,不会重复) ###3---set,setnx,setxx set name lqz #不管key是否存在,都设置 setnx name lqz #key不存在时才设置(新增操作) set name lqz nx #同上 set name lqz xx #key存在,才设置(更新操作) ###4---mget mset mget key1 key2 key3 #批量获取key1,key2.。。时间复杂度o(n) mset key1 value1 key2 value2 key3 value3 #批量设置时间复杂度o(n) #n次get和mget的区别 #n次get时间=n次命令时间+n次网络时间 #mget时间=1次网络时间+n次命令时间 ###5---其他:getset,append,strlen getset name lqznb #设置新值并返回旧值 时间复杂度o(1) append name 666 #将value追加到旧的value 时间复杂度o(1) strlen name #计算字符串长度(注意中文) 时间复杂度o(1) ###6---其他:incrybyfloat,getrange,setrange increbyfloat age 3.5 #为age自增3.5,传负值表示自减 时间复杂度o(1) getrange key start end #获取字符串制定下标所有的值 时间复杂度o(1) setrange key index value #从指定index开始设置value值 时间复杂度o(1)
###1---hget,hset,hdel hget key field #获取hash key对应的field的value 时间复杂度为 o(1) hset key field value #设置hash key对应的field的value值 时间复杂度为 o(1) hdel key field #删除hash key对应的field的值 时间复杂度为 o(1) #测试 hset user:1:info age 23 hget user:1:info ag hset user:1:info name lqz hgetall user:1:info hdel user:1:info age ###2---hexists,hlen hexists key field #判断hash key 是否存在field 时间复杂度为 o(1) hlen key #获取hash key field的数量 时间复杂度为 o(1) hexists user:1:info name hlen user:1:info #返回数量 ###3---hmget,hmset hmget key field1 field2 ...fieldN #批量获取hash key 的一批field对应的值 时间复杂度是o(n) hmset key field1 value1 field2 value2 #批量设置hash key的一批field value 时间复杂度是o(n) ###4--hgetall,hvals,hkeys hgetall key #返回hash key 对应的所有field和value 时间复杂度是o(n) hvals key #返回hash key 对应的所有field的value 时间复杂度是o(n) hkeys key #返回hash key对应的所有field 时间复杂度是o(n) ###小心使用hgetall ##1 计算网站每个用户主页的访问量 hincrby user:1:info pageview count # user:1:info表示用户1,pageview主页访问量,count访问量的值 hincrby userinfopagecount user:1:info count # userinfopagecount是所有人的主页访问量,user:1:info是用户1的主页,count是用户1主页访问量的值 ##2 缓存mysql的信息,直接设置hash格式
# 有序队列,可以从左侧添加,右侧添加,可以重复,可以从左右两边弹出 ########插入操作 #rpush 从右侧插入 rpush key value1 value2 ...valueN #时间复杂度为o(1~n) #lpush 从左侧插入 #linsert linsert key before|after value newValue #从元素value的前或后插入newValue 时间复杂度o(n) ,需要遍历列表 linsert listkey before b java linsert listkey after b php ############删除操作 lpop key #从列表左侧弹出一个item 时间复杂度o(1) rpop key #从列表右侧弹出一个item 时间复杂度o(1) lrem key count value #根据count值,从列表中删除所有value相同的项 时间复杂度o(n) 1 count>0 从左到右,删除最多count个value相等的项 2 count<0 从右向左,删除最多 Math.abs(count)个value相等的项 3 count=0 删除所有value相等的项 lrem listkey 0 a #删除列表中所有值a lrem listkey -1 c #从右侧删除1个c ltrim key start end #按照索引范围修剪列表 o(n) ltrim listkey 1 4 #只保留下表1--4的元素 ##########查询操作 lrange key start end #包含end获取列表指定索引范围所有item o(n) lrange listkey 0 2 lrange listkey 1 -1 #获取第一个位置到倒数第一个位置的元素 lindex key index #获取列表指定索引的item o(n) lindex listkey 0 lindex listkey -1 llen key #获取列表长度 ##########修改操作 lset key index newValue #设置列表指定索引值为newValue o(n) lset listkey 2 ppp #把第二个位置设为ppp
sadd key element #向集合key添加element(如果element存在,添加失败) o(1) srem key element #从集合中的element移除掉 o(1) scard key #计算集合大小 sismember key element #判断element是否在集合中 srandmember key count #从集合中随机取出count个元素,不会破坏集合中的元素(抽奖) spop key #从集合中随机弹出一个元素 smembers key #获取集合中所有元素 ,无序,小心使用,会阻塞住 sdiff user:1:follow user:2:follow #计算user:1:follow和user:2:follow的差集 sinter user:1:follow user:2:follow #计算user:1:follow和user:2:follow的交集 sunion user:1:follow user:2:follow #计算user:1:follow和user:2:follow的并集 sdiff|sinter|suion + store destkey... #将差集,交集,并集结果保存在destkey集合中
zadd key score element #score可以重复,可以多个同时添加,element不能重复 o(logN) zrem key element #删除元素,可以多个同时删除 o(1) zscore key element #获取元素的分数 o(1) zincrby key increScore element #增加或减少元素的分数 o(1) zcard key #返回元素总个数 o(1) zrank key element #返回element元素的排名(从小到大排) zrange key 0 -1 #返回排名,不带分数 o(log(n)+m) n是元素个数,m是要获取的值 zrange player:rank 0 -1 withscores #返回排名,带分数 zrangebyscore key minScore maxScore #返回指定分数范围内的升序元素 o(log(n)+m) n是元素个数,m是要获取的值 zrangebyscore user:1:ranking 90 210 withscores #获取90分到210分的元素 zcount key minScore maxScore #返回有序集合内在指定分数范围内的个数 o(log(n)+m) zremrangebyrank key start end #删除指定排名内的升序元素 o(log(n)+m) zremrangebyrank user:1:rangking 1 2 #删除升序排名中1到2的元素 zremrangebyscore key minScore maxScore #删除指定分数内的升序元素 o(log(n)+m) zremrangebyscore user:1:ranking 90 210 #删除分数90到210之间的元素
3.1 慢查询(假设redis性能不高了,如何取排除)
3.2 pipline和watch
# pipline 命令中不支持,各个语言客户端支持 # watch实现乐观锁
pfadd urls www.baidu.com pfadd urls www.baidu.com # 放不进去 pfcount urls # 取出来只有1 布隆过滤器(有误差)
### 移动端有定位,往后台传,就是经纬度 geoadd cities:locations 116.28 39.55 beijing geoadd cities:locations 117.12 39.08 tianjin geoadd cities:locations 114.29 38.02 shijiazhuang geoadd cities:locations 118.01 39.38 tangshan geoadd cities:locations 115.29 38.51 baoding # 计算北京到唐山的直线距离 geodist cities:locations beijing tianjin km # 计算北京周五150千米内的城市 georadiusbymember cities:locations beijing 150 km
总结
# 1 redis安装,二进制安装 把命令软连接到bin,做成服务 # 2 三种启动方式:咱们用配置文件启动(一百多个配置) redis-cli 连进去 config get * 修改配置,CONFIG REWRITE 直接写道配置文件中 # 3 查看客户端连接数,把客户端踢下线,监控别人输入的命令,日志审计(自动化运维) # 4 基本api -通用命令 key * dbsize,ttl -字符命令 计数 -列表命令 blpop(阻塞),时间轴 -hash命令 -集合 (抽奖) -有序集合:排行榜 # 5 高级使用 -慢查询 -位图:字符串 (独立用户统计) -hyperloglog (独立用户统计,去重) -发布订阅 -地理位置信息geo(zset)
四:redis持久化
4.1 redis持久化
# 快照:某时某刻数据的一个完成备份, -mysql的Dump -redis的RDB # 写日志:任何操作记录日志,要恢复数据,只要把日志重新走一遍即可 -mysql的 Binlog -Redis的 AOF
# 触发机制-主要三种方式 -save:客户端执行save命令----》redis服务端----》同步创建RDB二进制文件,如果老的RDB存在,会替换老的 -bgsave:客户端执行save命令----》redis服务端----》异步创建RDB二进制文件,如果老的RDB存在,会替换老的 -配置文件 save 900 1 save 300 10 save 60 10000 如果60s中改变了1w条数据,自动生成rdb 如果300s中改变了10条数据,自动生成rdb 如果900s中改变了1条数据,自动生成rdb
# 客户端每写入一条命令,都记录一条日志,放到日志文件中,如果出现宕机,可以将数据完全恢复 # AOF的三种策略 always:redis–》写命令刷新的缓冲区—》每条命令fsync到硬盘—》AOF文件 everysec(默认值):redis——》写命令刷新的缓冲区—》每秒把缓冲区fsync到硬盘–》AOF文件 no:redis——》写命令刷新的缓冲区—》操作系统决定,缓冲区fsync到硬盘–》AOF文件 # AOF重写 -本质:本质就是把过期的,无用的,重复的,可以优化的命令,来优化 -使用: -在客户端主动输入:bgrewriteaof -配置文件: # AOF持久化配置最优方案 appendonly yes #将该选项设置为yes,打开 appendfilename "appendonly.aof" #文件保存的名字 appendfsync everysec #采用第二种策略 dir ./data #存放的路径 no-appendfsync-on-rewrite yes #在aof重写的时候,是否要做aof的append操作,因为aof重写消耗性能,磁盘消耗,正常aof写磁盘有一定的冲突,这段期间的数据,允许丢失
# 原理: # 如何配置: 方式一:(从库的redis-cli中输入) -在从库执行 SLAVEOF 127.0.0.1 6379, -断开关系 slaveof no one 方式二:配置文件(配在从库的配置文件中) slaveof 127.0.0.1 6379 slave-read-only yes
4.3 哨兵
步骤
1.配置一主两从redis的配置文件 2.启动三个redis服务 3.配置三个哨兵的配置文件 4.启动三个哨兵服务 5../src/redis-cli -p 26377连接其中一个哨兵客户端,info查看信息 6.停掉主redis,哨兵会自动指定一个从库作为主库 7.在哨兵客户端查看现在的主库是谁(输入info即可)
详细操作及配置
# 让redis的主从复制高可用 1 搭一个一主两从 #创建三个配置文件: #第一个是主配置文件 daemonize yes pidfile /var/run/redis.pid port 6379 dir "/opt/soft/redis/data" logfile “6379.log” #第二个是从配置文件 daemonize yes pidfile /var/run/redis2.pid port 6378 dir "/opt/soft/redis/data2" logfile “6378.log” slaveof 127.0.0.1 6379 slave-read-only yes #第三个是从配置文件 daemonize yes pidfile /var/run/redis3.pid port 6377 dir "/opt/soft/redis/data3" logfile “6377.log” slaveof 127.0.0.1 6379 slave-read-only yes #把三个redis服务都启动起来 ./src/redis-server redis_6379.conf ./src/redis-server redis_6378.conf ./src/redis-server redis_6377.conf 2 搭建哨兵 # sentinel.conf这个文件 # 把哨兵也当成一个redis服务器 创建三个配置文件分别叫sentinel_26379.conf sentinel_26378.conf sentinel_26377.conf # 当前路径下创建 data1 data2 data3三个文件夹 #sentinel_26379.conf配置如下(其他的需要修改端口,文件地址日志文件名字) port 26379 daemonize yes dir ./data3 protected-mode no bind 0.0.0.0 logfile "redis_sentinel3.log" sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 30000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 180000 #启动三个哨兵 ./src/redis-sentinel sentinel_26379.conf ./src/redis-sentinel sentinel_26378.conf ./src/redis-sentinel sentinel_26377.conf # 登陆哨兵 ./src/redis-cli -p 26377 # 输入 info # 查看哨兵的配置文件被修改了,自动生成的 # 主动停掉主redis 6379,哨兵会自动选择一个从库作为主库 redis-cli -p 6379 shutdown #等待原来的主库启动,该主库会变成从库
import redis from redis.sentinel import Sentinel # 连接哨兵服务器(主机名也可以用域名) # 10.0.0.101:26379 sentinel = Sentinel([('10.0.0.101', 26379), ('10.0.0.101', 26378), ('10.0.0.101', 26377) ], socket_timeout=5) print(sentinel) # 获取主服务器地址 master = sentinel.discover_master('mymaster') print(master) # 获取从服务器地址 slave = sentinel.discover_slaves('mymaster') print(slave) ##### 读写分离 # 获取主服务器进行写入 # master = sentinel.master_for('mymaster', socket_timeout=0.5) # w_ret = master.set('foo', 'bar') # slave = sentinel.slave_for('mymaster', socket_timeout=0.5) # r_ret = slave.get('foo') # print(r_ret)
# 集群是3.0以后加的,3.0----5.0之间,ruby脚本,5.0以后,内置了
步骤:
1.为每个redis服务器配置对应的配置文件 2.以对应的配置文件启动6个redis-server服务器 3.创建集群 4.用redis-cli -p 7000 连接其中一个redis客户端,查看信息 5.
集群配置:redis-7000.conf
port 7000 daemonize yes dir "/opt/soft/redis/data/" logfile "7000.log" dbfilename "dump-7000.rdb" cluster-enabled yes cluster-config-file nodes-7000.conf cluster-require-full-coverage yes
用sed快速替换7000为其他数值并输入到对应的配置文件下:
sed "s/7000/7001/g" redis-7000.conf > redis-7001.conf sed "s/7000/7002/g" redis-7000.conf > redis-7002.conf sed "s/7000/7003/g" redis-7000.conf > redis-7003.conf sed "s/7000/7004/g" redis-7000.conf > redis-7004.conf sed "s/7000/7005/g" redis-7000.conf > redis-7005.conf
以对应的配置文件启动redis-server服务器
./src/redis-server ./redis-7000.conf ./src/redis-server ./redis-7001.conf ./src/redis-server ./redis-7002.conf ./src/redis-server ./redis-7003.conf ./src/redis-server ./redis-7004.conf ./src/redis-server ./redis-7005.conf
创建集群
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 # 创建集群并指定它的从节点个数为1,这里指定了6台机器,3主3从, # 如果设置从节点个数为2,就得有9台机器,3主6从 redis-cli -p 7000 cluster replicate 16c49dd91001529792f0425b46c6757080125732 redis-cli --cluster reshard --cluster-from 16c49dd91001529792f0425b46c6757080125732 --cluster-to 4ee63c79b7ab594414068099c12668ffc6698dbc --cluster-slots 1366 127.0.0.1:7000 redis-cli --cluster reshard --cluster-from 16c49dd91001529792f0425b46c6757080125732 --cluster-to 4ee63c79b7ab594414068099c12668ffc6698dbc --cluster-slots 1366 127.0.0.1:7000
连接其中一个redis
./src/redis-cli -c -p 7000 # 这里必须加-c参数,否则会无法存取数据
查看信息
CLUSTER INFO # 查看集群节点信息 CLUSTER NODES # 查看集群节点信息 CLUSTER SLOTS # 查看槽的信息
