Django-Rest-Framework

#前后端混合开发(前后端不分离):返回的是html的内容,需要写模板 #前后端分离:只专注于写后端接口,返回json,xml格式数据 # xml格式 <xml> <name>lqz</name> </xml> # json {"name":"lqz"} # java---》jsp https://www.pearvideo.com/category_loading.jsp #php写的 http://www.aa7a.cn/user.php # python写的 http://www.aa7a.cn/user.html #什么是动态页面(查数据库的),什么是静态页面(静止的html) #页面静态化
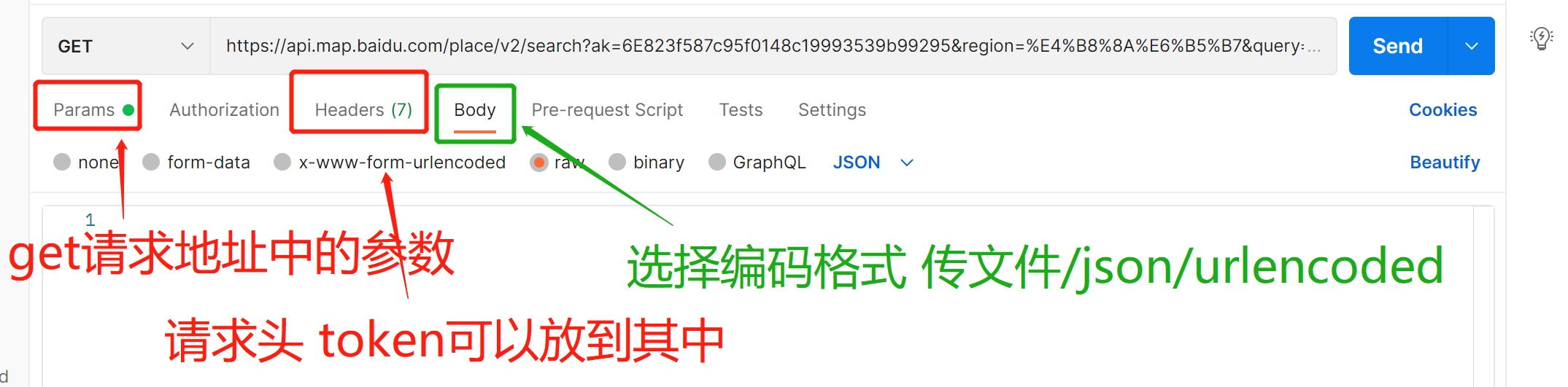
#通过网络,规定了前后台信息交互规则的url链接,也就是前后台信息交互的媒介 #百度地图的api接口 https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=%E4%B8%8A%E6%B5%B7&query=%E8%82%AF%E5%BE%B7%E5%9F%BA&output=xml
# postman是目前最好用的,模拟发送http请求的工具 # 双击安装,安装完成自动打开 # 解析json的网站 http://www.json.cn/ #请求头中User-Agent:客户端的类型 # 请求头中加其他参数: # 批量接口导出和测试(实操一下)
REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征性状态转移)。 它首次出现在2000年Roy Fielding的博士论文中。 RESTful是一种定义Web API接口的设计风格,尤其适用于前后端分离的应用模式中。 这种风格的理念认为后端开发任务就是提供数据的,对外提供的是数据资源的访问接口,所以在定义接口时,客户端访问的URL路径就表示这种要操作的数据资源。 事实上,我们可以使用任何一个框架都可以实现符合restful规范的API接口。 # 抓包工具:fiddler,charles # 10条规范 1 数据的安全保障:url链接一般都采用https协议进行传输 注:采用https协议,可以提高数据交互过程中的安全性 2 接口特征表现,一看就知道是个api接口 - 用api关键字标识接口url: - [https://api.baidu.com](https://api.baidu.com/) - https://www.baidu.com/api 注:看到api字眼,就代表该请求url链接是完成前后台数据交互的 -路飞的接口:https://api.luffycity.com/api/v1/course/free/ 3 多数据版本共存 - 在url链接中标识数据版本 - https://api.baidu.com/v1 - https://api.baidu.com/v2 注:url链接中的v1、v2就是不同数据版本的体现(只有在一种数据资源有多版本情况下) 4 数据即是资源,均使用名词(可复数) - 接口一般都是完成前后台数据的交互,交互的数据我们称之为资源 - https://api.baidu.com/users - https://api.baidu.com/books - https://api.baidu.com/book 注:一般提倡用资源的复数形式,在url链接中奖励不要出现操作资源的动词,错误示范:https://api.baidu.com/delete-user - 特殊的接口可以出现动词,因为这些接口一般没有一个明确的资源,或是动词就是接口的核心含义 - https://api.baidu.com/place/search - https://api.baidu.com/login 5 资源操作由请求方式决定(method) - 操作资源一般都会涉及到增删改查,我们提供请求方式来标识增删改查动作 - https://api.baidu.com/books - get请求:获取所有书 - https://api.baidu.com/books/1 - get请求:获取主键为1的书 - https://api.baidu.com/books - post请求:新增一本书书 - https://api.baidu.com/books/1 - put请求:整体修改主键为1的书 - https://api.baidu.com/books/1 - patch请求:局部修改主键为1的书 - https://api.baidu.com/books/1 - delete请求:删除主键为1的书 6 过滤,通过在url上传参的形式传递搜索条件 - https://api.example.com/v1/zoos?limit=10:指定返回记录的数量 - https://api.example.com/v1/zoos?offset=10:指定返回记录的开始位置 - https://api.example.com/v1/zoos?page=2&per_page=100:指定第几页,以及每页的记录数 - https://api.example.com/v1/zoos?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序 - https://api.example.com/v1/zoos?animal_type_id=1:指定筛选条件 7 响应状态码 7.1 正常响应 - 响应状态码2xx - 200:常规请求 - 201:创建成功 7.2 重定向响应 - 响应状态码3xx - 301:永久重定向 - 302:暂时重定向 7.3 客户端异常 - 响应状态码4xx - 403:请求无权限 - 404:请求路径不存在 - 405:请求方法不存在 7.4 服务器异常 - 响应状态码5xx - 500:服务器异常 8 错误处理,应返回错误信息,error当做key { error: "无权限操作" } 9 返回结果,针对不同操作,服务器向用户返回的结果应该符合以下规范 GET /collection:返回资源对象的列表(数组) GET /collection/resource:返回单个资源对象 POST /collection:返回新生成的资源对象 PUT /collection/resource:返回完整的资源对象 PATCH /collection/resource:返回完整的资源对象 DELETE /collection/resource:返回一个空文档 10 需要url请求的资源需要访问资源的请求链接 # Hypermedia API,RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么 { "status": 0, "msg": "ok", "results":[ { "name":"肯德基(罗餐厅)", "img": "https://image.baidu.com/kfc/001.png" } ... ] }
# 安装:pip install djangorestframework==3.10.3 # 使用 1 在setting.py 的app中注册 INSTALLED_APPS = [ 'rest_framework' ] 2 在models.py中写表模型 class Book(models.Model): nid=models.AutoField(primary_key=True) name=models.CharField(max_length=32) price=models.DecimalField(max_digits=5,decimal_places=2) author=models.CharField(max_length=32) 3 新建一个序列化类(听不懂) from rest_framework.serializers import ModelSerializer from app01.models import Book class BookModelSerializer(ModelSerializer): class Meta: model = Book fields = "__all__" 4 在视图中写视图类 from rest_framework.viewsets import ModelViewSet from .models import Book from .ser import BookModelSerializer class BooksViewSet(ModelViewSet): queryset = Book.objects.all() serializer_class = BookModelSerializer 5 写路由关系 from app01 import views from rest_framework.routers import DefaultRouter router = DefaultRouter() # 可以处理视图的路由器 router.register('book', views.BooksViewSet) # 向路由器中注册视图集 # 将路由器中的所有路由信息追到到django的路由列表中 urlpatterns = [ path('admin/', admin.site.urls), ] #这是什么意思?两个列表相加 # router.urls 列表 urlpatterns += router.urls 6 启动,在postman中测试即可
# ModelViewSet继承View(django原生View) # APIView继承了View # 先读View的源码 from django.views import View # urls.py path('books1/', views.Books.as_view()), #在这个地方应该写个函数内存地址,views.Books.as_view()执行完,是个函数内存地址,as_view是一个类方法,类直接来调用,会把类自动传入 放了一个view的内存地址(View--》as_view--》内层函数) # 请求来了,如果路径匹配,会执行, 函数内存地址(request) def view(request, *args, **kwargs): #request是当次请求的request self = cls(**initkwargs) #实例化得到一个对象,Book对象 if hasattr(self, 'get') and not hasattr(self, 'head'): self.head = self.get self.request = request self.args = args self.kwargs = kwargs return self.dispatch(request, *args, **kwargs) def dispatch(self, request, *args, **kwargs): #request是当次请求的request self是book对象 if request.method.lower() in self.http_method_names: #handler现在是: handler=getattr(self,'get'),你写的Book类的get方法的内存地址 handler = getattr(self, request.method.lower(), self.http_method_not_allowed) else: handler = self.http_method_not_allowed return handler(request, *args, **kwargs) #执行get(request)
#from rest_framework.views import APIView # urls.py path('booksapiview/', views.BooksAPIView.as_view()), #在这个地方应该写个函数内存地址 #APIView的as_view方法(类的绑定方法) def as_view(cls, **initkwargs): view = super().as_view(**initkwargs) # 调用父类(View)的as_view(**initkwargs) view.cls = cls view.initkwargs = initkwargs # 以后所有的请求,都没有csrf认证了,只要继承了APIView,就没有csrf的认证 return csrf_exempt(view) #请求来了---》路由匹配上---》view(request)---》调用了self.dispatch(),会执行apiview的dispatch # APIView的dispatch方法 def dispatch(self, request, *args, **kwargs): self.args = args self.kwargs = kwargs # 重新包装成一个request对象,以后再用的request对象,就是新的request对象了 request = self.initialize_request(request, *args, **kwargs) self.request = request self.headers = self.default_response_headers # deprecate? try: # 三大认证模块 self.initial(request, *args, **kwargs) # Get the appropriate handler method if request.method.lower() in self.http_method_names: handler = getattr(self, request.method.lower(), self.http_method_not_allowed) else: handler = self.http_method_not_allowed # 响应模块 response = handler(request, *args, **kwargs) except Exception as exc: # 异常模块 response = self.handle_exception(exc) # 渲染模块 self.response = self.finalize_response(request, response, *args, **kwargs) return self.response # APIView的initial方法 def initial(self, request, *args, **kwargs): # 认证组件:校验用户 - 游客、合法用户、非法用户 # 游客:代表校验通过,直接进入下一步校验(权限校验) # 合法用户:代表校验通过,将用户存储在request.user中,再进入下一步校验(权限校验) # 非法用户:代表校验失败,抛出异常,返回403权限异常结果 self.perform_authentication(request) # 权限组件:校验用户权限 - 必须登录、所有用户、登录读写游客只读、自定义用户角色 # 认证通过:可以进入下一步校验(频率认证) # 认证失败:抛出异常,返回403权限异常结果 self.check_permissions(request) # 频率组件:限制视图接口被访问的频率次数 - 限制的条件(IP、id、唯一键)、频率周期时间(s、m、h)、频率的次数(3/s) # 没有达到限次:正常访问接口 # 达到限次:限制时间内不能访问,限制时间达到后,可以重新访问 self.check_throttles(request)
from rest_framework.request import Request # 只要继承了APIView,视图类中的request对象,都是新的,也就是上面那个request的对象了 # 老的request在新的request._request # 以后使用reqeust对象,就像使用之前的request是一模一样(因为重写了__getattr__方法) def __getattr__(self, attr): try: return getattr(self._request, attr) #通过反射,取原生的request对象,取出属性或方法 except AttributeError: return self.__getattribute__(attr) # request.data 感觉是个数据属性,其实是个方法,@property,修饰了 它是一个字典,post请求不管使用什么编码,传过来的数据,都在request.data #get请求传过来数据,从哪取? request.GET @property def query_params(self): """ More semantically correct name for request.GET. """ return self._request.GET #视图类中 print(request.query_params) #get请求,地址中的参数 # 原来在 print(request.GET)
# 在视图函数上加装饰器@csrf_exempt # csrf_exempt(view)这么写和在视图函数上加装饰器是一毛一样的 #urls.py中看到这种写法 path('tset/', csrf_exempt(views.test)),
总结1
1 web的两种开发模式 2 web api 3 posman的使用(路径必须完全正确) 4 restful规范 10条 5 drf的安装和使用 6 cbv源码分析 -视图类,必须继承View(读View的源码) -在类里写get,post方法就可以了,只要get请求来,就会走get方法(方法跟之前的fbv写法完全一样) -路由:views.Books.as_view()---这个函数执行完一定是一个内存地址---》view(闭包函数)内存函数的地址 -请求来了,路由匹配上--->view(request)--->self.dispatch(request, *args, **kwargs) -dispatch-->把请求方法转成小写---》通过反射,去对象中找,有没有get方法,有就加括号执行,并且把request传进去了 7 APIView源码分析(drf提供的,扩展了View的功能) -视图类,继承APIView(读APIView的源码) -在类里写get,post方法就可以了,只要get请求来,就会走get方法(方法跟之前的fbv写法完全一样) -路由:views.Books.as_view()---这个函数执行完一定是一个内存地址---》view(闭包函数)内存函数的地址,处理了csrf,所有请求,都没有csrf校验了 -请求来了,路由匹配上--->view(request)--->self.dispatch(request, *args, **kwargs),现在这个dispatch不是View中的dispatch,而是APIView中的dispatch -def dispatch(self, request, *args, **kwargs): self.args = args self.kwargs = kwargs # self.initialize_request(request, *args, **kwargs) request是当次请求的request # request = self.initialize_request request是一个新的Request对象 request = self.initialize_request(request, *args, **kwargs) self.request = request self.headers = self.default_response_headers # deprecate? try: # 三大认证模块(request是新的request) self.initial(request, *args, **kwargs) # Get the appropriate handler method if request.method.lower() in self.http_method_names: handler = getattr(self, request.method.lower(), self.http_method_not_allowed) else: handler = self.http_method_not_allowed # 响应模块 response = handler(request, *args, **kwargs) except Exception as exc: # 异常模块 response = self.handle_exception(exc) # 渲染模块 self.response = self.finalize_response(request, response, *args, **kwargs) return self.response
# 分为两大类: 1. serializers.Serializer # 需要自己重写 create和 update方法 2. serializers.ModelSerializer # 推荐使用 简单方便 # ModelSerializer一般不需要自己写create和update方法 除非特殊需求
1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串 2. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型 3. 反序列化,完成数据校验功能
1 写一个序列化的类,继承Serializer 2 在类中写要序列化的字段,想序列化哪个字段,就在类中写哪个字段 3 在视图类中使用,导入--》实例化得到序列化类的对象,把要序列化的对象传入 4 序列化类的对象.data 是一个字典 5 把字典返回,如果不使用rest_framework提供的Response,就得使用JsonResponse
from rest_framework import serializers # ser.py class BookSerializer(serializers.Serializer): # id=serializers.CharField() name=serializers.CharField() # price=serializers.DecimalField() price=serializers.CharField() author=serializers.CharField() publish=serializers.CharField() # views.py class BookView(APIView): def get(self,request,pk): book=Book.objects.filter(id=pk).first() #用一个类,毫无疑问,一定要实例化 #要序列化谁,就把谁传过来 book_ser=BookSerializer(book) # 调用类的__init__ # book_ser.data 序列化对象.data就是序列化后的字典 return Response(book_ser.data) # urls.py re_path('books/(?P<pk>\d+)', views.BookView.as_view()),
IntegerField 整型
CharField 字符型
FloatField 浮点型
BooleanField 布尔型
EmailField 邮箱类型
DecimalField 保留小数点型
ImageField 图片型
FileField 文件型
ChoiceField 多重选择型
DateField 日期型
TimeField 时间型
DateTimeField 日期时间型
PrimaryKeyRelatedField 外键关联型
max_length 字符串最大长度
min_length 字符串最小长度
max_value 数字最大值
min_value 数字最小值
read_only 默认False,若设置为True,表明对应字段只在序列化操作中起作用
write_only 默认作用False,若设置为True,表明对应字段只在反序列化操作中起作用
required 默认True,表明对应字段在反序列化操作进行数据校验时必须传入
defalut 字段设置的默认值,设置的同时,required值自动变为False
label 字段的描述
error_messages 字典类型,自定义错误描述,可针对长度、大小、是否必填来设置,如{“required”:“XXX字段不能为空”}
1 写一个序列化的类,继承Serializer 2 在类中写要反序列化的字段,想反序列化哪个字段,就在类中写哪个字段,字段的属性(max_lenth......) max_length 最大长度 min_lenght 最小长度 allow_blank 是否允许为空 trim_whitespace 是否截断空白字符 max_value 最小值 min_value 最大值 3 在视图类中使用,导入--》实例化得到序列化类的对象,把要要修改的对象传入,修改的数据传入 boo_ser=BookSerializer(book,request.data) # 方式一 boo_ser=BookSerializer(instance=book,data=request.data) # 方式二,推荐
# 推荐用方式二:关键字传参的方式 4 数据校验 if boo_ser.is_valid() 5 如果校验通过,就保存 boo_ser.save() # 注意不是book.save() 6 如果不通过,逻辑自己写 7 如果字段的校验规则不够,可以写钩子函数(局部和全局) # 局部钩子 def validate_price(self, data): # validate_字段名 接收前端传过来的该字段参数 #如果价格小于10,就校验不通过 # print(type(data)) # print(data) if float(data)>10: return data else: #校验失败,抛异常 raise ValidationError('价格太低') # 全局钩子 def validate(self, validate_data): # 全局钩子 print(validate_data) author=validate_data.get('author') publish=validate_data.get('publish') if author == publish: raise ValidationError('作者名字跟出版社一样') else: return validate_data 8 可以使用字段的author=serializers.CharField(validators=[check_author]) ,来校验 -写一个函数 def check_author(data): if data.startswith('sb'): raise ValidationError('作者名字不能以sb开头') else: return data -配置:validators=[check_author]
# models.py class Book(models.Model): id=models.AutoField(primary_key=True) name=models.CharField(max_length=32) price=models.DecimalField(max_digits=5,decimal_places=2) author=models.CharField(max_length=32) publish=models.CharField(max_length=32) # ser.py # from rest_framework.serializers import Serializer # 就是一个类 from rest_framework import serializers from rest_framework.exceptions import ValidationError # 需要继承 Serializer def check_author(data): if data.startswith('sb'): raise ValidationError('作者名字不能以sb开头') else: return data class BookSerializer(serializers.Serializer): # id=serializers.CharField() name=serializers.CharField(max_length=16,min_length=4) # price=serializers.DecimalField() price=serializers.CharField() author=serializers.CharField(validators=[check_author]) # validators=[] 列表中写函数内存地址 publish=serializers.CharField() def validate_price(self, data): # validate_字段名 接收前端传过来的该字段参数 #如果价格小于10,就校验不通过 # print(type(data)) # print(data) if float(data)>10: return data else: #校验失败,抛异常 raise ValidationError('价格太低') def validate(self, validate_data): # 全局钩子 print(validate_data) author=validate_data.get('author') publish=validate_data.get('publish') if author == publish: raise ValidationError('作者名字跟出版社一样') else: return validate_data def update(self, instance, validated_data): #instance是book这个对象 #validated_data是校验后的数据 instance.name=validated_data.get('name') instance.price=validated_data.get('price') instance.author=validated_data.get('author') instance.publish=validated_data.get('publish') instance.save() #book.save() django 的orm提供的 return instance #views.py class BookView(APIView): def get(self,request,pk): book=Book.objects.filter(id=pk).first() #用一个类,毫无疑问,一定要实例化 #要序列化谁,就把谁传过来 book_ser=BookSerializer(book) # 调用类的__init__ # book_ser.data 序列化对象.data就是序列化后的字典 return Response(book_ser.data) # return JsonResponse(book_ser.data) def put(self,request,pk): response_msg={'status':100,'msg':'成功'} # 找到这个对象 book = Book.objects.filter(id=pk).first() # 得到一个序列化类的对象,这里跟forms组件类似,
# forms组件校验数据:form_obj=MyForm(request.POST) # boo_ser=BookSerializer(book,request.data) boo_ser=BookSerializer(instance=book,data=request.data) # 要数据验证(回想form表单的验证) if boo_ser.is_valid(): # 返回True表示验证通过 boo_ser.save() # 直接保存会报错,需要在序列化组件的ser.py文件中重写update方法 response_msg['data']=boo_ser.data else: response_msg['status']=101 response_msg['msg']='数据校验失败' response_msg['data']=boo_ser.errors return Response(response_msg) # urls.py re_path('books/(?P<pk>\d+)', views.BookView.as_view()),
read_only 表明该字段仅用于序列化输出,默认False,如果设置成True,postman中可以看到该字段,修改时,不需要传该字段 write_only 表明该字段仅用于反序列化输入,默认False,如果设置成True,postman中看不到该字段,修改时,该字段需要传 # 以下的了解 required 表明该字段在反序列化时必须输入,默认True default 反序列化时使用的默认值 allow_null 表明该字段是否允许传入None,默认False validators 该字段使用的验证器 error_messages 包含错误编号与错误信息的字典
# views.py class BooksView(APIView): def get(self,request): response_msg = {'status': 100, 'msg': '成功'} books=Book.objects.all() book_ser=BookSerializer(books,many=True) #序列化多条,如果序列化一条,不需要写 response_msg['data']=book_ser.data return Response(response_msg) #urls.py path('books/', views.BooksView.as_view()),
# views.py class BooksView(APIView): # 新增 def post(self,request): response_msg = {'status': 100, 'msg': '成功'} #修改才有instance,新增没有instance,只有data book_ser = BookSerializer(data=request.data) # book_ser = BookSerializer(request.data) # 这个按位置传request.data会给instance,就报错了 # 校验字段 if book_ser.is_valid(): book_ser.save() response_msg['data']=book_ser.data else: response_msg['status']=102 response_msg['msg']='数据校验失败' response_msg['data']=book_ser.errors return Response(response_msg) #ser.py 序列化类重写create方法 def create(self, validated_data): instance=Book.objects.create(**validated_data) return instance # urls.py path('books/', views.BooksView.as_view()),
# views.py class BookView(APIView): def delete(self,request,pk): ret=Book.objects.filter(pk=pk).delete() return Response({'status':100,'msg':'删除成功'}) # urls.py re_path('books/(?P<pk>\d+)', views.BookView.as_view()),
class BookModelSerializer(serializers.ModelSerializer): class Meta: model=Book # 对应上models.py中的模型 fields='__all__' # fields=('name','price','id','author') # 只序列化指定的字段 # exclude=('name',) #跟fields不能都写,写谁,就表示排除谁 # read_only_fields=('price',) # write_only_fields=('id',) #弃用了,使用extra_kwargs extra_kwargs = { # 类似于这种形式name=serializers.CharField(max_length=16,min_length=4) 'price': {'write_only': True}, } # 其他使用一模一样 #不需要重写create和updata方法了
# 序列化多条,需要传many=True # book_ser=BookModelSerializer(books,many=True) book_one_ser=BookModelSerializer(book) print(type(book_ser)) #<class 'rest_framework.serializers.ListSerializer'> print(type(book_one_ser)) #<class 'app01.ser.BookModelSerializer'> # 对象的生成--》先调用类的__new__方法,生成空对象 # 对象=类名(name=lqz),触发类的__init__() # 类的__new__方法控制对象的生成 def __new__(cls, *args, **kwargs): if kwargs.pop('many', False): return cls.many_init(*args, **kwargs) # 没有传many=True,走下面,正常的对象实例化 return super().__new__(cls, *args, **kwargs)
# source的使用 1 可以改字段名字 xxx=serializers.CharField(source='title') # 隐藏了一个模型表类book,相当于book.xxx 2 可以.跨表publish=serializers.CharField(source='publish.email') # 相当于book.publish变为book.publish.email 3 可以执行方法pub_date=serializers.CharField(source='test') test是Book表模型中的方法
# 第3详情见下面的示例2
这里需要注意:
要是字段中用了source参数,就在后面的update/局部钩子/全局钩子中,如果使用到该字段校验,
必须使用source指定的参数作为值,否则会出错
# SerializerMethodField()的使用(详情见下面的示例1) 1 它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西 authors=serializers.SerializerMethodField() #它需要有个配套方法,方法名叫get_字段名,返回值就是要显示的东西 def get_authors(self,instance): # 这里的instance就是book对象 authors=instance.authors.all() # 取出所有作者 ll=[] for author in authors: ll.append({'name':author.name,'age':author.age}) return ll
1 可以改字段名字 xxx=serializers.CharField(source='title') 2 可以.跨表publish=serializers.CharField(source='publish.email') 3 可以执行方法pub_date=serializers.CharField(source='test') test是Book表模型中的方法 # 上面的序列化类中其实隐藏了一个模型类 publish=serializers.CharField(source='publish.email') # 相当于book.publish=serializers.CharField(source='book.publish.email')
SerializerMethodField


# models.py from django.db import models class BaseModel(models.Model): create_time = models.DateTimeField(auto_now_add=True) is_delete = models.BooleanField(default=False) last_update_time = models.DateTimeField(auto_now=True) class Meta: # abstract=True说明是一个抽象类,不会生成表 abstract = True class Book(BaseModel): name = models.CharField(max_length=32) price = models.DecimalField(max_digits=5,decimal_places=2) # db_constraint表示实质上没有外键联系,只是逻辑上的关联,增删不会有影响,同时不影响我们orm查询 publish = models.ForeignKey(to='Publish',db_constraint=False,on_delete=models.DO_NOTHING) # 自动:中间表只有两个表的关联字段,用自动创第三张表的方式 # 手动:中间表有扩展字段,需要用手动的方式,through,through_fields, authors = models.ManyToManyField(to='Author') class Meta: verbose_name_plural = '图书表' def __str__(self): return '%s'% self.name class Publish(BaseModel): name = models.CharField(max_length=32) addr = models.CharField(max_length=255) class Meta: verbose_name_plural = '出版社表' def __str__(self): return '%s'% self.name class Author(BaseModel): name = models.CharField(max_length=32) gender = models.IntegerField(choices=((1,'男'), (2,'女')), ) # OneToOneField本质就是ForeignKey+unique,自己手动写也可以 author_detail = models.OneToOneField(to='AuthorDetail',db_constraint=False,on_delete=models.CASCADE) class Meta: verbose_name_plural = '作者表' def __str__(self): return '%s'% self.name class AuthorDetail(BaseModel): phone = models.CharField(max_length=32) class Meta: verbose_name_plural = '作者详情表' # common_seriralizer.py 序列化器 from rest_framework import serializers from api import models class BookModelSerializer(serializers.ModelSerializer): # SerializerMethodField需要一个配套方法,方法名:get_字段名 publish = serializers.SerializerMethodField() def get_publish(self, instance): # 这里的instance就是模型类 publish_name = instance.publish.name return publish_name authors = serializers.SerializerMethodField() # SerializerMethodField需要一个配套方法,方法名:get_字段名 def get_authors(self, instance): authors = instance.authors.all() # 这里的instance就是模型类中的book对象 l = [] for author in authors: l.append({'name':author.name,'gender':author.get_gender_display()}) return l class Meta: model = models.Book fields = ('name','price','publish','authors',) # depth = 1 # 可以设置深度,查询联表下一级的数据 # views.py 视图函数 from rest_framework.generics import GenericAPIView from rest_framework.response import Response from api import models from api.common_serializers import BookModelSerializer class BookGenericAPIView(GenericAPIView): queryset = models.Book.objects.all().filter(is_delete=False) serializer_class = BookModelSerializer def get(self,request,*args,**kwargs): books = self.get_queryset() book_ser = self.get_serializer(instance=books,many=True) return Response(book_ser.data)
from django.db import models # Create your models here. class BaseModel(models.Model): create_time = models.DateTimeField(auto_now_add=True) is_delete = models.BooleanField(default=False) last_update_time = models.DateTimeField(auto_now=True) class Meta: # abstract=True说明是一个抽象类,不会生成表 abstract = True class Book(BaseModel): name = models.CharField(max_length=32) price = models.DecimalField(max_digits=5,decimal_places=2) # db_constraint表示实质上没有外键联系,只是逻辑上的关联,增删不会有影响,同时不影响我们orm查询 publish = models.ForeignKey(to='Publish',db_constraint=False,on_delete=models.DO_NOTHING) # 自动:中间表只有两个表的关联字段,用自动创第三张表的方式 # 手动:中间表有扩展字段,需要用手动的方式,through,through_fields, authors = models.ManyToManyField(to='Author') class Meta: verbose_name_plural = '图书表' @property def publish_name(self): return self.publish.name def author_list(self): author_list = self.authors.all() # 可以用列表生成式代替下面代码块 # l = [] # for author in author_list: #l.append({'name':author.name,'gender':author.get_gender_display()}) # return l return [{'name':author.name,'gender':author.get_gender_display()} for author in author_list] def __str__(self): return '%s'% self.name class Publish(BaseModel): name = models.CharField(max_length=32) addr = models.CharField(max_length=255) class Meta: verbose_name_plural = '出版社表' def __str__(self): return '%s'% self.name class Author(BaseModel): name = models.CharField(max_length=32) gender = models.IntegerField(choices=((1,'男'), (2,'女')), ) # OneToOneField本质就是ForeignKey+unique,自己手动写也可以 author_detail = models.OneToOneField(to='AuthorDetail',db_constraint=False,on_delete=models.CASCADE) class Meta: verbose_name_plural = '作者表' def __str__(self): return '%s'% self.name class AuthorDetail(BaseModel): phone = models.CharField(max_length=32) class Meta: verbose_name_plural = '作者详情表' # common_serializer.py 序列化器 from rest_framework import serializers from api import models class BookModelSerializer(serializers.ModelSerializer): class Meta: model = models.Book # 在模型类中定义一个publish_name方法,推荐 # 但是这种方法会有两个publish,所以要在extra_kwargs中设置只读/只写 fields = ('name','price','publish','publish_name','authors','author_list') # depth = 1 # 可以设置深度,查询联表下一级的数据 extra_kwargs = { 'publish':{"write_only":True}, 'publishj_name':{'read_only':True}, 'authors': {"write_only": True}, 'author_list': {'read_only': True}, } # views.py 视图 from rest_framework.generics import GenericAPIView from rest_framework.response import Response from api import models from api.common_serializers import BookModelSerializer class BookGenericAPIView(GenericAPIView): queryset = models.Book.objects.all().filter(is_delete=False) serializer_class = BookModelSerializer def get(self,request,*args,**kwargs): books = self.get_queryset() book_ser = self.get_serializer(instance=books,many=True) return Response(book_ser.data)
某些需要用到的字段,可以单独写一个序列化器,然后调用该序列化器就可以获取该字段的详细数据
如下面的示例中的teacher字段,我们可以单独写一个teacher的序列化器,
如果要获取teacher相关的字段信息,只需要在CourseModelSerializer中调用该序列化器即可
# 路由 router = SimpleRouter() router.register('categories', views.CourseCategoryView, 'categories') router.register('free', views.CouresView, 'free') urlpatterns = [ path('', include(router.urls)), ] # 视图 views.py from .paginations import PageNumberPagination from django_filters.rest_framework import DjangoFilterBackend from rest_framework.filters import OrderingFilter,SearchFilter from .filters import MyFilter class CouresView(GenericViewSet,ListModelMixin,RetrieveModelMixin): queryset = models.Course.objects.filter(is_delete=False,is_show=True).order_by('orders') serializer_class = serializer.CourseModelSerializer pagination_class = PageNumberPagination filter_backends=[DjangoFilterBackend,OrderingFilter] ordering_fields=['id', 'price', 'students'] filter_fields=['course_category','students'] ###serializer from rest_framework import serializers from . import models class CourseCategorySerializer(serializers.ModelSerializer): class Meta: model = models.CourseCategory fields = ['id', 'name'] class TeacherSerializer(serializers.ModelSerializer): class Meta: model = models.Teacher fields = ('name', 'role_name', 'title', 'signature', 'image', 'brief') class CourseModelSerializer(serializers.ModelSerializer): # 子序列化的方式 teacher = TeacherSerializer() class Meta: model = models.Course fields=[ 'id', 'name', 'course_img', 'brief', 'attachment_path', 'pub_sections', 'price', 'students', 'period', 'sections', 'course_type_name', 'level_name', 'status_name', 'teacher', 'section_list', ] # models.py class Course(BaseModel): ... @property def course_type_name(self): return self.get_course_type_display() @property def level_name(self): return self.get_level_display() @property def status_name(self): return self.get_status_display() @property def section_list(self): ll=[] # 根据课程取出所有章节(正向查询,字段名.all()) course_chapter_list=self.coursechapters.all() for course_chapter in course_chapter_list: # 通过章节对象,取到章节下所有的课时(反向查询) # course_chapter.表名小写_set.all() 现在变成了course_chapter.coursesections.all() course_sections_list=course_chapter.coursesections.all() for course_section in course_sections_list: ll.append({ 'name': course_section.name, 'section_link': course_section.section_link, 'duration': course_section.duration, 'free_trail': course_section.free_trail, }) if len(ll)>=4: return ll return ll class Teacher(BaseModel): ... def role_name(self): # 返回角色的中文 return self.get_role_display()
class MyResponse(): def __init__(self): self.status=100 self.msg='成功' @property def get_dict(self): return self.__dict__ if __name__ == '__main__': res=MyResponse() res.status=101 res.msg='查询失败' # res.data={'name':'lqz'} print(res.get_dict)
write_only_fields 不能使用,被弃用了,使用extra_kwargs解决了 extra_kwargs = { 'id': {'write_only': True}, }
总结2
#1 Serializer类,需要序列化什么,必须写一个类继承,想序列化什么字段,就在里面写字段,source的作用(很多字段类) #2 序列化queryset(列表)对象和真正的对象,many=True的作用,instance=要序列化的对象, #3 反序列化 instance=要序列化的对象,data=request.data #4 字段验证,序列化类中,给字段加属性,局部和全局钩子函数,字段属性的validators=[check_author] #5 当在视图中调用 序列化对象.is_valid() boo_ser.is_valid(raise_exception=True) 只要验证不通过,直接抛异常 #6 修改保存---》调用序列化对象.save(),重写Serializer类的update方法 def update(self, instance, validated_data): #instance是book这个对象 #validated_data是校验后的数据 instance.name=validated_data.get('name') instance.price=validated_data.get('price') instance.author=validated_data.get('author') instance.publish=validated_data.get('publish') instance.save() #book.save() django 的orm提供的 return instance #7 序列化得到字典,序列化对象.data #8 自己定义了一个Response对象 class MyResponse(): def __init__(self): self.status=100 self.msg='成功' @property def get_dict(self): return self.__dict__ #9 反序列化的新增 序列化类(data=request.data),如果只传了data,当调用 序列化对象.save(),会触发序列化类的create方法执行,当传了instance和data时,调用 序列化对象.save(),会触发序列化类的update方法执行 #10 重写create方法(可以很复杂) def create(self, validated_data): instance=Book.objects.create(**validated_data) return instance #11 ModelSerializer 跟Model做了一个对应 可以不用重写create/update方法 但是如果他的不符合我们的需求 也可以重写 优先生效自己重写的 class BookModelSerializer(serializers.ModelSerializer): def validate_price(self, data): pass publish=serializers.CharField(source='publish.name') class Meta: model=Book # 对应上models.py中的模型 fields='__all__' # fields=('name','price','id','author','publish') # 只序列化指定的字段 # exclude=('name',) #跟fields不能都写,写谁,就表示排除谁 # read_only_fields=('price',) # write_only_fields=('id',) #弃用了,使用extra_kwargs extra_kwargs = { # 类似于这种形式name=serializers.CharField(max_length=16,min_length=4) 'price': {'write_only': True,'max_length':'16','min_length':'4'}, } ModelSerializer扩展: 1.可以写publish=serializers.CharField(source='publish.name'), 2.可以在extra_kwargs里面扩展,对通过参数进行数据限制 3.可以写局部/全局钩子,跟class Meta同级 #12 如果在ModelSerializer中写一个局部钩子或者全局钩子,如何写? -跟之前一模一样,跟class Meta同级 #13 many=True 能够序列化多条的原因---》__new__是在__init__之前执行的,造出一个空对象 #14 接口:统一子类的行为
请求/响应
drf
# 请求对象 # from rest_framework.request import Request def __init__(self, request, parsers=None, authenticators=None, negotiator=None, parser_context=None): # 二次封装request,将原生request作为drf request对象的 _request 属性 self._request = request def __getattr__(self,item): return getattr(self._request,item) # 请求对象.data:前端以三种编码方式传入的数据,都可以取出来 # 请求对象.query_params 与Django标准的request.GET相同,只是更换了更正确的名称而已。
#from rest_framework.response import Response def __init__(self, data=None, status=None, template_name=None, headers=None, exception=False, content_type=None): #data:你要返回的数据,字典 #status:返回的状态码,默认是200, -from rest_framework import status在这个路径下,它把所有使用到的状态码都定义成了常量 #template_name 渲染的模板名字(自定制模板),不需要了解 #headers:响应头,可以往响应头放东西,就是一个字典 #content_type:响应的编码格式,application/json和text/html; # 浏览器响应成浏览器的格式,postman响应成json格式,通过配置实现的(默认配置) #不管是postman还是浏览器,都返回json格式数据 # drf有默认的配置文件---》先从项目的setting中找,找不到,采用默认的 # drf的配置信息,先从自己类中找--》项目的setting中找---》默认的找 -局部使用:对某个视图类有效 -在视图类中写如下 from rest_framework.renderers import JSONRenderer renderer_classes=[JSONRenderer,] -全局使用:全局的视图类,所有请求,都有效 -在setting.py中加入如下 REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES': ( # 默认响应渲染类 'rest_framework.renderers.JSONRenderer', # json渲染器 'rest_framework.renderers.BrowsableAPIRenderer', # 浏览API渲染器 ) }
# 两个视图基类 APIView GenericAPIView
#### views.py from rest_framework.generics import GenericAPIView from app01.models import Book from app01.ser import BookSerializer # 基于APIView写的 class BookView(APIView): def get(self,request): book_list=Book.objects.all() book_ser=BookSerializer(book_list,many=True) return Response(book_ser.data) def post(self,request): book_ser = BookSerializer(data=request.data) if book_ser.is_valid(): book_ser.save() return Response(book_ser.data) else: return Response({'status':101,'msg':'校验失败'}) class BookDetailView(APIView): def get(self, request,pk): book = Book.objects.all().filter(pk=pk).first() book_ser = BookSerializer(book) return Response(book_ser.data) def put(self, request,pk): book = Book.objects.all().filter(pk=pk).first() book_ser = BookSerializer(instance=book,data=request.data) if book_ser.is_valid(): book_ser.save() return Response(book_ser.data) else: return Response({'status': 101, 'msg': '校验失败'}) def delete(self,request,pk): ret=Book.objects.filter(pk=pk).delete() return Response({'status': 100, 'msg': '删除成功'}) #models.py class Book(models.Model): name=models.CharField(max_length=32) price=models.DecimalField(max_digits=5,decimal_places=2) publish=models.CharField(max_length=32) #ser.py class BookSerializer(serializers.ModelSerializer): class Meta: model=Book fields='__all__' # urls.py path('books/', views.BookView.as_view()), re_path('books/(?P<pk>\d+)', views.BookDetailView.as_view()),
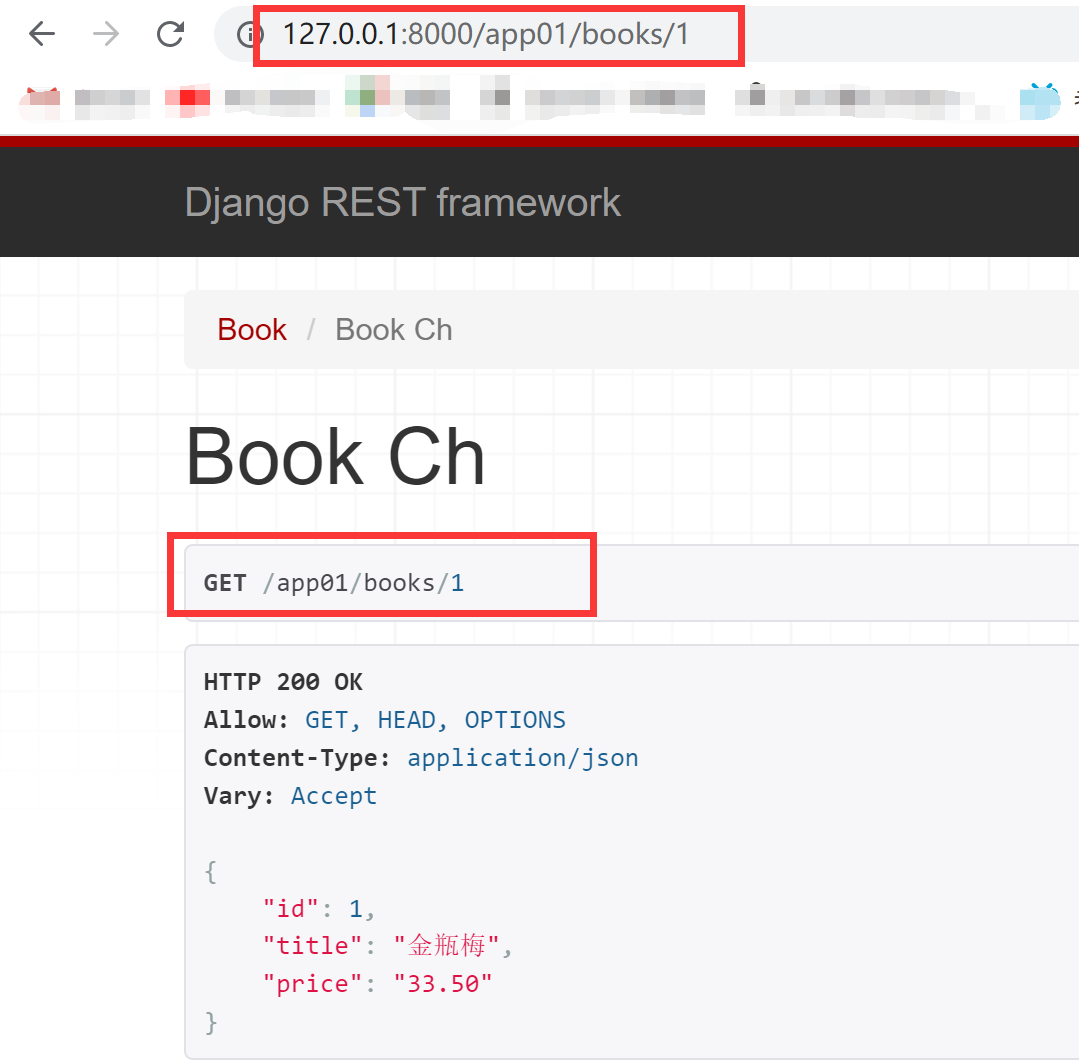
# views.py class Book2View(GenericAPIView): #queryset要传queryset对象,查询了所有的图书 # serializer_class使用哪个序列化类来序列化这堆数据 queryset=Book.objects # queryset=Book.objects.all() serializer_class = BookSerializer def get(self,request): book_list=self.get_queryset() book_ser=self.get_serializer(book_list,many=True) return Response(book_ser.data) def post(self,request): book_ser = self.get_serializer(data=request.data) if book_ser.is_valid(): book_ser.save() return Response(book_ser.data) else: return Response({'status':101,'msg':'校验失败'}) class Book2DetailView(GenericAPIView): queryset = Book.objects serializer_class = BookSerializer def get(self, request,pk): book = self.get_object() book_ser = self.get_serializer(book) return Response(book_ser.data) def put(self, request,pk): book = self.get_object() book_ser = self.get_serializer(instance=book,data=request.data) if book_ser.is_valid(): book_ser.save() return Response(book_ser.data) else: return Response({'status': 101, 'msg': '校验失败'}) def delete(self,request,pk): ret=self.get_object().delete() return Response({'status': 100, 'msg': '删除成功'}) #url.py # 使用GenericAPIView重写的 path('books2/', views.Book2View.as_view()), re_path('books2/(?P<pk>\d+)', views.Book2DetailView.as_view()),
from rest_framework.mixins import ListModelMixin,CreateModelMixin,UpdateModelMixin,DestroyModelMixin,RetrieveModelMixin # views.py class Book3View(GenericAPIView,ListModelMixin,CreateModelMixin): queryset=Book.objects serializer_class = BookSerializer def get(self,request): return self.list(request) def post(self,request): return self.create(request) class Book3DetailView(GenericAPIView,RetrieveModelMixin,DestroyModelMixin,UpdateModelMixin): queryset = Book.objects serializer_class = BookSerializer def get(self, request,pk): return self.retrieve(request,pk) def put(self, request,pk): return self.update(request,pk) def delete(self,request,pk): return self.destroy(request,pk) # urls.py # 使用GenericAPIView+5 个视图扩展类 重写的 path('books3/', views.Book3View.as_view()), re_path('books3/(?P<pk>\d+)', views.Book3DetailView.as_view()),
# views.py from rest_framework.generics import ListAPIView from rest_framework.generics import CreateAPIView from rest_framework.generics import UpdateAPIView from rest_framework.generics import RetrieveAPIView from rest_framework.generics import DestroyAPIView from rest_framework.generics import ListCreateAPIView from rest_framework.generics import RetrieveUpdateAPIView from rest_framework.generics import RetrieveDestroyAPIView from rest_framework.generics import RetrieveUpdateDestroyAPIView # 共9个视图子类 class BookView5(ListAPIView,CreateAPIView): # 查询所有,新增一个 queryset = models.Book.objects serializer_class = BookSerializer # class BookDetailView5(RetrieveAPIView,UpdateAPIView,DestroyAPIView): # 一个个写 class BookDetailView5(RetrieveUpdateDestroyAPIView): # 查1个,删1个,改1个,统一写 queryset = models.Book.objects serializer_class = BookSerializer # urls.py url(r'^books5/',views.BookView5.as_view()), url(r'^book5/(?P<pk>\d+)/',views.BookDetailView5.as_view())
# views.py from rest_framework.viewsets import ModelViewSet class Book5View(ModelViewSet): #5个接口都有,但是路由有点问题 queryset = Book.objects serializer_class = BookSerializer # urls.py # 使用ModelViewSet编写5个接口 path('books5/', views.Book5View.as_view(actions={'get':'list','post':'create'})), #当路径匹配,又是get请求,会执行Book5View的list方法 re_path('books5/(?P<pk>\d+)', views.Book5View.as_view(actions={'get':'retrieve','put':'update','delete':'destroy'})),
# 重写了as_view # 核心代码(所以路由中只要配置了对应关系,比如{'get':'list'}),当get请求来,就会执行list方法 for method, action in actions.items(): #method:get # action:list handler = getattr(self, action) #执行完上一句,handler就变成了list的内存地址 setattr(self, method, handler) #执行完上一句 对象.get=list #for循环执行完毕 对象.get:对着list 对象.post:对着create
继承了ViewSetMixin类后,我们还可以自定义请求方法,
当发起get/post/put/delete/retrieve等这些请求的时候,
可以通过利用actions的反射来执行我们自己写的方法,如下:
# views.py from rest_framework.viewsets import ViewSetMixin class Book6View(ViewSetMixin,APIView): #一定要放在APIVIew前 因为继承类的查找顺序关系 def get_all_book(self,request): print("xxxx") book_list = Book.objects.all() book_ser = BookSerializer(book_list, many=True) return Response(book_ser.data) # urls.py #继承ViewSetMixin的视图类,路由可以改写成这样 path('books6/', views.Book6View.as_view(actions={'get': 'get_all_book'})),
继承ModelViewSet并自定制查询
假如我现在有一个类继承了ModelViewSet类,但是在群查接口中,我只想查出2条或者指定数量的数据,这时我们可以在类内重写list方法,如下
# views.py class BookView2(ModelViewSet): queryset = models.Book.objects serializer_class = BookSerializer # 重写list方法,然后返回的数据截取自己想要的数量即可 def list(self, request, *args, **kwargs): queryset = self.filter_queryset(self.get_queryset()) page = self.paginate_queryset(queryset) if page is not None: serializer = self.get_serializer(page, many=True) return self.get_paginated_response(serializer.data) serializer = self.get_serializer(queryset, many=True) return Response((serializer.data)[:3]) # 只需要在这里截取3条数据 # urls.py path('books2/', views.BookView2.as_view(actions={'get':'list','post':'create'})), re_path('books2/(?P<pk>\d+)', views.BookView2.as_view(actions={'get':'retrieve','put':'update','delete':'destroy'})),
同理,如果我们新增数据的时候不想用框架指定好的方式,我们可以自己在类内重写这个方法。
补充
DRF中通过请求方式不同使用不同的序列化器
在pycharm中查看类的继承关系
总结3
# 1 请求和响应 # 2 请求 Request对象,drf新包装的,Request.data,Request.query_params, 重写了__getattr__, request._request # 3 json模块是否执行反序列化bytes格式 python3.6之后才支持 3.5之前的版本不支持 # 4 考你:视图类的方法中:self.request,就是当次请求的request # 5 Response:类,实例化传一堆参,data=字典,status=状态码(有一堆常量),headers=响应头(字典),content_type=响应的编码方式 # 6 全局和局部配置,响应格式 # 7 drf默认配置文件,查找顺序--》先从类中属性找---》项目的setting找---》drf默认的配置找 # 8 视图家族 -APIView---》继承自View -GenicAPIView---》APIView,做了一些扩展: -queryset = None -serializer_class = None -get_queryset() 经常用 -get_serializer() 经常用 -get_serializer_class() 内部来用,外部会重写 -get_object() 经常用,获取一条数据(pk传过来) -源码解析 queryset = self.filter_queryset(self.get_queryset()) #返回所有数据queryset对象 # lookup_url_kwarg就是pk,路由中有名分组分出来的pk
lookup_url_kwargs=None or pk 得到 ==> lookup_url_kwargs= pk lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field # {pk:4} 4 浏览器地址中要查询的id号http://127.0.0.1:8000/books6/4/ filter_kwargs = {self.lookup_field: self.kwargs[lookup_url_kwarg]} # 根据pk=4去queryset中get单个对象 obj = get_object_or_404(queryset, **filter_kwargs) self.check_object_permissions(self.request, obj) return obj -5 个视图扩展类(继承了object),每个里面写了一个方法(ListModelMixin:list方法) ListModelMixin, CreateModelMixin, UpdateModelMixin, DestroyModelMixin, RetrieveModelMixin -GenericAPIView的视图子类,9个,继承了GenicAPIView+一个或者两个或者三个视图扩展类 CreateAPIView, ListAPIView, UpdateAPIView, RetrieveAPIView, DestroyAPIView, ListCreateAPIView, RetrieveUpdateDestroyAPIView, RetrieveDestroyAPIView, RetrieveUpdateAPIView -视图集:ModelViewSet,ReadOnlyModelViewSet:继承了上面一堆(5个视图扩展和GenicAPIView)+自己写了一个ViewSetMixin(as_view方法),只要继承它的,路由得写成{‘get’:‘自己定义的方法’} -ViewSet=ViewSetMixin, views.APIView :ViewSetMixin要放在前面 -GenericViewSet=ViewSetMixin+GenicAPIView -ViewSetMixin(as_view方法) -ViewSetMixin+APIView=ViewSet -ViewSetMixin+GenicAPIView=GenericViewSet
# 1 在urls.py中配置 path('books4/', views.Book4View.as_view()), re_path('books4/(?P<pk>\d+)', views.Book4DetailView.as_view()),
# 2 一旦视图类,继承了ViewSetMixin,路由 path('books5/', views.Book5View.as_view(actions={'get':'list','post':'create'})), #当路径匹配,又是get请求,会执行Book5View的list方法 re_path('books5/(?P<pk>\d+)', views.Book5View.as_view(actions={'get':'retrieve','put':'update','delete':'destroy'})), # 3 继承自视图类,ModelViewSet的路由写法(自动生成路由) -urls.py # 第一步:导入routers模块 from rest_framework import routers
# 第二步:有两个类,实例化得到对象 # routers.DefaultRouter 生成的路由更多 # routers.SimpleRouter router=routers.DefaultRouter()
# 第三步:注册 # router.register('前缀','继承自ModelViewSet视图类','别名') router.register('books',views.BookViewSet) # 不要加斜杠了 # 第四步 # router.urls # 自动生成的路由,加入到原路由中 # print(router.urls) # urlpatterns+=router.urls
''' -views.py from rest_framework.viewsets import ModelViewSet from app01.models import Book from app01.ser import BookSerializer class BookViewSet(ModelViewSet): queryset =Book.objects serializer_class = BookSerializer
# action干什么用?为了给继承自ModelViewSet的视图类中定义的函数也添加路由
from rest_framework.decorators import action
# 使用 class BookViewSet(ModelViewSet): queryset =Book.objects.all() serializer_class = BookSerializer # methods第一个参数,传一个列表,列表中放请求方式, # ^books/get_1/$ [name='book-get-1'] 当向这个地址发送get请求,会执行下面的函数 # detail:布尔类型 如果是True,参数中需要带pk,如果detail为False,则不需要带pk #^books/(?P<pk>[^/.]+)/get_1/$ [name='book-get-1'] @action(methods=['GET','POST'],detail=True) # detail为True则需要带pk def get_1(self,request,pk): print(pk) book=self.get_queryset()[:2] # 从0开始截取一条 ser=self.get_serializer(book,many=True) return Response(ser.data) # 装饰器,放在被装饰的函数上方,method:请求方式,detail:是否带pk
# 认证的实现 1 写一个类,继承BaseAuthentication,重写authenticate,认证的逻辑写在里面,
认证通过,返回两个值,一个值最终给了Requet对象的user,一个给Request对象的auth,
认证失败,抛异常:APIException或者AuthenticationFailed
2 全局使用:在settings.py中配置 局部使用:在需要认证的函数上方加上 authentication_classes=[自己写的认证类]
#1 APIVIew----》dispatch方法---》self.initial(request, *args, **kwargs)---->有认证,权限,频率 #2 只读认证源码: self.perform_authentication(request) #3 self.perform_authentication(request)就一句话:request.user,需要去drf的Request对象中找user属性(方法) #4 Request类中的user方法,刚开始来,没有_user,走 self._authenticate() #5 核心,就是Request类的 _authenticate(self): def _authenticate(self): # 遍历拿到一个个认证器,进行认证 # self.authenticators自己在视图函数配置的一堆认证类产生的认证类对象组成的 list #self.authenticators 你在视图类中配置的一个个的认证类:authentication_classes=[认证类1(),认证类2()],对象的列表 for authenticator in self.authenticators: try: # 认证器(对象)调用认证方法authenticate(认证类对象self, request请求对象) # 返回值:登陆的用户与认证的信息组成的 tuple # 该方法被try包裹,代表该方法会抛异常,抛异常就代表认证失败 user_auth_tuple = authenticator.authenticate(self) #注意这self是request对象 except exceptions.APIException: self._not_authenticated() raise # 返回值的处理 if user_auth_tuple is not None: self._authenticator = authenticator # 如何有返回值,就将 登陆用户 与 登陆认证 分别保存到 request.user、request.auth self.user, self.auth = user_auth_tuple return # 如果返回值user_auth_tuple为空,代表认证通过,但是没有 登陆用户 与 登陆认证信息,代表游客 self._not_authenticated()
# 自定义认证类: 1.写一个认证类,继承BaseAuthentication,重写authenticate方法, 2.在该方法中书写认证逻辑,如果认证通过返回两个值,分别给user对象和auth对象 如果认证失败则抛出AuthenticationFailed异常 3.在视图类或者settings中配置即可
# 写一个认证类 app_auth.py from rest_framework.authentication import BaseAuthentication from rest_framework.exceptions import AuthenticationFailed from app01.models import UserToken class MyAuthentication(BaseAuthentication): def authenticate(self, request): # 认证逻辑,如果认证通过,返回两个值 #如果认证失败,抛出AuthenticationFailed异常 token=request.GET.get('token') if token: user_token=UserToken.objects.filter(token=token).first() # 认证通过 if user_token: return user_token.user,token else: raise AuthenticationFailed('认证失败') else: raise AuthenticationFailed('请求地址中需要携带token') # 可以有多个认证,从左到右依次执行 # 全局使用,在setting.py中配置 REST_FRAMEWORK={ "DEFAULT_AUTHENTICATION_CLASSES":["app01.app_auth.MyAuthentication",] } # 局部使用,在视图类上写 authentication_classes=[MyAuthentication] # 局部禁用 authentication_classes=[]
示例
# models.py from django.db import models class Book(models.Model): bid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) price = models.DecimalField(max_digits=5,decimal_places=2) author = models.CharField(max_length=32) class MyUser(models.Model): username = models.CharField(max_length=32) password = models.CharField(max_length=32) user_type = models.IntegerField(choices=((1,'超级用户'),(2,'普通用户'),(3,'沙雕用户'))) class UserToken(models.Model): token = models.CharField(max_length=64) user = models.OneToOneField(to='MyUser') # ser.py 自定义序列化器 from rest_framework.serializers import ModelSerializer from app01 import models class MyBook(ModelSerializer): class Meta: model = models.Book fields = '__all__' #user_auth.py 自定义认证组件 from rest_framework.authentication import BaseAuthentication from rest_framework.exceptions import AuthenticationFailed from app01 import models class MyAuthentication(BaseAuthentication): def authenticate(self, request): ''' 书写认证逻辑 如果认证通过,返回两个值,一个给request的user,一个给request的auth 如果认证失败,抛出AuthenticationFailed异常 ''' # 让用户必须在请求地址中带上token(在哪里带上token由我们决定) token = request.GET.get('token') print(token) if token: user_obj = models.UserToken.objects.filter(token=token).first() # 如果用户存在,说明认证通过 if user_obj: print('111',user_obj.token) return user_obj.user,token else: raise AuthenticationFailed('认证失败') else: raise AuthenticationFailed('你给我在地址中带着token来') # views.py from rest_framework.viewsets import ModelViewSet from app01 import models from app01.ser import MyBook from rest_framework.views import APIView from rest_framework.response import Response import uuid class LoginView(APIView): def post(self,request): username = request.data.get('username') password = request.data.get('password') user_obj = models.MyUser.objects.filter(username=username,password=password).first() if user_obj: token = uuid.uuid4() # 通过uuid生成随机字符串 models.UserToken.objects.update_or_create(defaults={'token':token},user=user_obj) return Response({'status':'100','msg':'登录成功','token':token}) else: return Response({'status':'101','msg':'用户名或密码错误'}) from app01.user_auth import MyAuthentication class BookViewSet(ModelViewSet): authentication_classes = [MyAuthentication,] queryset = models.Book.objects.all() serializer_class = MyBook # urls.py from django.conf.urls import url from django.contrib import admin from app01 import views from rest_framework.routers import DefaultRouter,SimpleRouter router = SimpleRouter() router.register('book',views.BookViewSet,) urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^login/',views.LoginView.as_view()), url(r'^test/',views.TestApi.as_view()), ] urlpatterns += router.urls
总结
# 1 路由 # 2 3种写法 -django传统的路由(cvb路由)path('test/', views.TestView.as_view()), -只要继承ViewSetMixin:path('books/', views.BookViewSet.as_view({'get':'list','post':'create'})), -自动生成路由 -SimpleRouter -DefaultRouter -使用: # 第一步:导入routers模块 from rest_framework import routers # 第二步:有两个类,实例化得到对象 # routers.DefaultRouter 生成的路由更多 # routers.SimpleRouter router=routers.SimpleRouter() # 第三步:注册 # router.register('前缀','继承自ModelViewSet视图类','别名') router.register('books',views.BookViewSet) # 不要加斜杠了 urlpatterns+=router.urls #3 action的使用:装饰器给继承了ModeViewSet的视图类中自定义的方法,自动生成路由 #4 method=['get','post'],detail=True(带pk的)/False(不带pk) # 5 认证 -使用 -定义一个类,继承BaseAuthentication,重写def authenticate(self, request),校验成功返回两个值,一个是user对象,第二个是token -需要注意,如果配置多个认证类,要把返回两个值的放到最后 -全局使用:setting配置 REST_FRAMEWORK={ "DEFAULT_AUTHENTICATION_CLASSES":["app01.app_auth.MyAuthentication",], } -局部使用: authentication_classes=[MyAuthentication] -局部禁用:authentication_classes = []
# APIView---->dispatch---->initial--->self.check_permissions(request)(APIView的对象方法) def check_permissions(self, request): # 遍历权限对象列表得到一个个权限对象(权限器),进行权限认证 for permission in self.get_permissions(): # 权限类一定有一个has_permission权限方法,用来做权限认证的 # 参数:权限对象self、请求对象request、视图类对象 # 返回值:有权限返回True,无权限返回False if not permission.has_permission(request, self): self.permission_denied( request, message=getattr(permission, 'message', None) )
# 自定义权限 1.写一个类,继承BasePermission,重写has_permission方法, 2.书写逻辑,如果权限通过,返回True,如果不通过,返回False 3.配置在视图类或settings中即可
# 写一个类,继承BasePermission,重写has_permission,如果权限通过,就返回True,不通过就返回False from rest_framework.permissions import BasePermission class UserPermission(BasePermission): def has_permission(self, request, view): # 不是超级用户,不能访问 # 由于认证已经过了,request内就有user对象了,当前登录用户 user=request.user # 当前登录用户 # 如果该字段用了choice,通过get_字段名_display()就能取出choice后面的中文 print(user.get_user_type_display()) if user.user_type==1: return True else: return False # 局部使用 class TestView(APIView): permission_classes = [app_auth.UserPermission] # 全局使用 REST_FRAMEWORK={ "DEFAULT_AUTHENTICATION_CLASSES":["app01.app_auth.MyAuthentication",], 'DEFAULT_PERMISSION_CLASSES': [ 'app01.app_auth.UserPermission', ], } # 局部禁用 class TestView(APIView): permission_classes = []
# 演示一下内置权限的使用:IsAdminUser,控制是否对网站后台有权限的人 # 1 创建超级管理员 # 2 写一个测试视图类 from rest_framework.permissions import IsAdminUser from rest_framework.authentication import SessionAuthentication class TestView3(APIView): authentication_classes=[SessionAuthentication,] permission_classes = [IsAdminUser] def get(self,request,*args,**kwargs): return Response('这是22222222测试数据,超级管理员可以看') # 3 超级用户登录到admin,再访问test3就有权限 # 4 正常的话,普通管理员,没有权限看(判断的是is_staff字段)
# 自定义频率 1.写一个类,继承SimpleRateThrottle,重写get_cache_key方法, 2.该方法返回什么就以什么为key进行限制, scope字段需要和settings中的对应 3.在视图类或者settings中配置即可
# 全局配置 # 自定义频率,必须重写get_cache_key # 继承SimpleRateThrottle # 重写get_cache_key,返回什么就以什么为key进行限制 # scope字段,需要与setting中对应 REST_FRAMEWORK = { 'DEFAULT_THROTTLE_CLASSES': [ 'rest_framework.throttling.AnonRateThrottle', 'rest_framework.throttling.UserRateThrottle', ], 'DEFAULT_THROTTLE_RATES': { 'anon': '2/min', 'user': '10/min' } }
# 全局使用 限制未登录用户1分钟访问5次 REST_FRAMEWORK = { 'DEFAULT_THROTTLE_CLASSES': ( 'rest_framework.throttling.AnonRateThrottle', ), 'DEFAULT_THROTTLE_RATES': { 'anon': '3/m', } } ##############views.py from rest_framework.permissions import IsAdminUser from rest_framework.authentication import SessionAuthentication,BasicAuthentication class TestView4(APIView): authentication_classes=[] permission_classes = [] def get(self,request,*args,**kwargs): return Response('我是未登录用户') # 局部使用 from rest_framework.permissions import IsAdminUser from rest_framework.authentication import SessionAuthentication,BasicAuthentication from rest_framework.throttling import AnonRateThrottle class TestView5(APIView): authentication_classes=[] permission_classes = [] throttle_classes = [AnonRateThrottle] def get(self,request,*args,**kwargs): return Response('我是未登录用户,TestView5')
# 需求:未登录用户1分钟访问5次,登录用户一分钟访问10次 全局:在setting中 'DEFAULT_THROTTLE_CLASSES': ( 'rest_framework.throttling.AnonRateThrottle', 'rest_framework.throttling.UserRateThrottle' ), 'DEFAULT_THROTTLE_RATES': { 'user': '10/m', 'anon': '5/m', } 局部配置:throttle_classes = [UserRateThrottle] class TestView6(APIView): authentication_classes=[] permission_classes = [] # 局部配置限制登录用户访问频次 throttle_classes = [UserRateThrottle] def get(self,request,*args,**kwargs): return Response('我是登录用户,TestView6')
DEFAULT_FILTER_BACKENDS' ,
所以这两个组件要不就一起全局配置,要不就一起局部配置,
如果某个视图类局部配置了过滤,全局的就会过滤、排序都会失效(因为共用配置项),
导致这个视图类的排序功能也失效了,所以一定要注意。
#1 安装:pip3 install django-filter #2 注册,在app中注册:'django_filters' #3 全局配,或者局部配 'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',) #4 视图类
from django_filters.rest_framework import DjangoFilterBackend
from rest_framework.filters import OrderingFilter
class BookView(ListAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializer
# 局部使用
filter_backends = [DjangoFilterBackend] filter_fields = ('name','price') #配置可以按照哪个字段来过滤 # urls.py path('books/', views.BookView.as_view()), # 使用: http://127.0.0.1:8000/books/?name=微信 http://127.0.0.1:8000/books/?name=微博 http://127.0.0.1:8000/books/?price=12
所以这两个组件要不就一起全局配置,要不就一起局部配置,
如果某个视图类局部配置了排序,全局的排序、过滤都会失效(因为共用配置项),
所以会导致这个视图类过滤功能也失效了,所以一定要注意
# 局部使用和全局使用
# 注册app:在settings文件中注册'django_filters'
# 全局使用
'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',) # 局部使用 from rest_framework.generics import ListAPIView
from django_filters.rest_framework import DjangoFilterBackend from rest_framework.filters import OrderingFilter from app01.models import Book from app01.ser import BookSerializer
class Book2View(ListAPIView): queryset = Book.objects.all() serializer_class = BookSerializer filter_backends = [OrderingFilter] # 局部使用 ordering_fields = ('id', 'price')
# 还可以过滤、排序两个一起使用
# filter_backends = [DjangoFilterBackend, OrderingFilter] # filter_fileds = ('name','price')
# ordering_fields = ('id','price')
# urls.py path('books2/', views.Book2View.as_view()), ] # 使用: http://127.0.0.1:8000/books2/?ordering=-price # 降序 http://127.0.0.1:8000/books2/?ordering=price # 升序 http://127.0.0.1:8000/books2/?ordering=-id
# 自定义过滤类:
1.写一个类,继承BaseFilterBackend,
2.重写filter_queryset方法,方法返回queryset对象,就是过滤后的对象,
(前端传过来的url中的参数,可以重query_params中取,其他的规则自己定)
3.配置在视图类中即可
# 借助django-filter实现区间过滤 # 实现区间过滤 ########## 1 filters.py from django_filters import filters from django_filters import FilterSet class CourseFilterSet(FilterSet): # 课程的价格范围要大于min_price,小于max_price min_price = filters.NumberFilter(field_name='price', lookup_expr='gt') max_price = filters.NumberFilter(field_name='price', lookup_expr='lt') class Meta: model=models.Course fields=['course_category'] ##### 2 视图类中配置 -filter_backends=[DjangoFilterBackend] # 配置类:(自己写的类) -filter_class = CourseFilterSet
''' 内置排序:不需要借助第三方模块,rest_framework自带的排序 from rest_framework.filters import OrderingFilter,SearchFilter 按id正序倒叙排序,按price正序倒叙排列 使用:http://127.0.0.1:8000/course/free/?ordering=-id 配置类: filter_backends=[OrderingFilter] 配置字段: ordering_fields=['id','price'] 内置过滤:rest_framework自带的过滤 不支持外键字段来过滤 只支持自有字段的过滤 from rest_framework.filters import OrderingFilter,SearchFilter 使用:http://127.0.0.1:8000/course/free/?search=39 按照price过滤(表自有的字段直接过滤) 配置类: filter_backends=[SearchFilter] 配置字段: search_fields=['price']
自定义过滤:
继承类BaseFilterBackend,重写filter_queryset方法,该方法返回一个queryset对象,
就是过滤后的对象,配置在视图类中即可(过滤需要的参数可以重前端url传过来的query_params中取)
用第三方模块来过滤: 扩展:django-filter 安装:pip install django-filter
注册:在settings配置中注册应用:'django_filters' 支持自有字段的过滤还支持外键字段的过滤 from django_filters.rest_framework import DjangoFilterBackend
http://127.0.0.1:8000/course/free/?course_category=1 # 过滤分类为1 (python的所有课程) 配置类: filter_backends=[DjangoFilterBackend] 配置字段: filter_fields=['course_category'] '''
#统一接口返回 # 自定义异常方法,在settings中替换原本的异常捕获 # 写一个方法 # 自定义异常处理的方法 from rest_framework.views import exception_handler from rest_framework.response import Response from rest_framework import status def my_exception_handler(exc, context): response=exception_handler(exc, context) # 上面那句话调用原来处理异常的函数,赋值给response # 这时response会有两种情况,一个是None,drf没有处理异常 # 另一个是原来的response对象,django处理了异常,但是处理的不符合咱们的要求 # print(type(exc)) # exc就是异常类型 if not response: # 即如果response为None if isinstance(exc, ZeroDivisionError): #可以分的更细,每种异常状态码不同 return Response(data={'status': 777, 'msg': "除以0的错误" + str(exc)}, status=status.HTTP_400_BAD_REQUEST) return Response(data={'status':999,'msg':str(exc)},status=status.HTTP_400_BAD_REQUEST) else: # return response # 就是原来的response对象,处理了异常,但是格式不符合我们要求 # 所以,在下面,我们自己封装响应的格式 return Response(data={'status':888,'msg':response.data.get('detail')},status=status.HTTP_400_BAD_REQUEST) # 全局配置setting.py 'EXCEPTION_HANDLER': 'app01.app_auth.my_exception_handler', ''' 总结: 1.自定义一个异常捕获方法,在该方法内调用drf的异常捕获方法,赋值给response 2.看源码得知,这个response会有两种情况,一种是处理了异常,另一个就是None(没处理异常) 3.我们通过判断response是否为None,来分情况处理异常 如果为response为None:我们自己通过drf的Response对象封装一个字典返回给前端(包含错误信息) 如果response不为None:drf本身已经处理过异常,只是响应的格式不符合我们的要求, 我们也是自己通过drf的Response对象,把drf处理过的异常信息提取出来, 封装到字典中,然后返回给前端。 甚至:在response不为None时,我们可以分的更细,不同的异常类型可以返回不同的响应状态码,如上面的 if isinstance(exc, ZeroDivisionError): return Response{data:xxx,status:xxx,msg:xxx} '''
# 以后都用自己封装的 from rest_framework.response import Response class APIResponse(Response): # 继承drf的Response def __init__(self,code=100,msg='成功',data=None,status=None,headers=None,**kwargs): dic = {'code': code, 'msg': msg} if data: # 如果有data值,将data也封装到字典中 dic = {'code': code, 'msg': msg,'data':data} dic.update(kwargs) # 没有data值,直接用更新字典的方式,将多传入的参数加到字典中 super().__init__(data=dic, status=status,headers=headers) # 继承需要用的父类字段,不用的可以不加,如果后续需要可以再加 # 使用 return APIResponse(data={"name":'lqz'},token='dsafsdfa',aa='dsafdsafasfdee') return APIResponse(data={"name":'lqz'}) return APIResponse(code='101',msg='错误',data={"name":'lqz'},token='dsafsdfa',aa='dsafdsafasfdee',header={})
a=(3,) a=3, # a是元组 print(type(a))
总结
# 1 web开发模型,混合开发和前后端分离 # 2 web api:接口 # 3 postman的使用 # 4 restful规范:10条 # 5 djangorestframework,django的第三方插件(app) # 6 drf几大组件 请求(APIView源码,Requset对象)和响应(Response,自己封装Response), 序列化, 视图, 路由, 解析器(DEFAULT_PARSER_CLASSES,全局配置,局部配置), 响应器(DEFAULT_RENDERER_CLASSES,全局配,局部配), 认证:校验是否登录(有内置,自定义,全局配置,局部配置) 权限:是否有权限访问某些接口(有内置,自定义,全局配置,局部配置) 频率:限制访问频次(有内置,自定义,全局配置,局部配置),根据用户ip,根据用户id限制 过滤:筛选,查询出符合条件的 排序:结果进行排序 异常:全局异常(自定义,全局配置) 版本控制 分页器 文档生成 jwt认证 Xadmin的使用 路飞项目 git redis 短信 支付宝支付
# models.py from django.db import models from django.contrib.auth.models import AbstractUser class BaseModel(models.Model): is_delete=models.BooleanField(default=False) # auto_now_add=True 只要记录创建,不需要手动插入时间,自动把当前时间插入 create_time=models.DateTimeField(auto_now_add=True) # auto_now=True,只要更新,就会把当前时间插入 last_update_time=models.DateTimeField(auto_now=True) # import datetime # create_time=models.DateTimeField(default=datetime.datetime.now) class Meta: # 单个字段,有索引,有唯一 # 多个字段,有联合索引,联合唯一 abstract=True # 抽象表,不再数据库建立出表 class Book(BaseModel): id=models.AutoField(primary_key=True) # verbose_name admin中显示中文 name=models.CharField(max_length=32,verbose_name='书名',help_text='这里填书名') price=models.DecimalField(max_digits=5,decimal_places=2) # 一对多的关系一旦确立,关联字段写在多的一方 #to_field 默认不写,关联到Publish主键 #db_constraint=False 逻辑上的关联,实质上没有外键练习,增删不会受外键影响,但是orm查询不影响 publish=models.ForeignKey(to='Publish',on_delete=models.DO_NOTHING,db_constraint=False) # 多对多,跟作者,关联字段写在 查询次数多的一方 # 什么时候用自动,什么时候用手动?第三张表只有关联字段,用自动 第三张表有扩展字段,需要手动写 # 不能写on_delete authors=models.ManyToManyField(to='Author',db_constraint=False) class Meta: verbose_name_plural='书表' # admin中表名的显示 def __str__(self): return self.name @property def publish_name(self): return self.publish.name # def author_list(self): def author_list(self): author_list=self.authors.all() # ll=[] # for author in author_list: # ll.append({'name':author.name,'sex':author.get_sex_display()}) # return ll return [ {'name':author.name,'sex':author.get_sex_display()}for author in author_list] class Publish(BaseModel): name = models.CharField(max_length=32) addr=models.CharField(max_length=32) def __str__(self): return self.name class Author(BaseModel): name=models.CharField(max_length=32) sex=models.IntegerField(choices=((1,'男'),(2,'女'))) # 一对一关系,写在查询频率高的一方 #OneToOneField本质就是ForeignKey+unique,自己手写也可以 authordetail=models.OneToOneField(to='AuthorDetail',db_constraint=False,on_delete=models.CASCADE) class AuthorDetail(BaseModel): mobile=models.CharField(max_length=11) # 二、表断关联 # 1、表之间没有外键关联,但是有外键逻辑关联(有充当外键的字段) # 2、断关联后不会影响数据库查询效率,但是会极大提高数据库增删改效率(不影响增删改查操作) # 3、断关联一定要通过逻辑保证表之间数据的安全,不要出现脏数据,代码控制 # 4、断关联 # 5、级联关系 # 作者没了,详情也没:on_delete=models.CASCADE # 出版社没了,书还是那个出版社出版:on_delete=models.DO_NOTHING # 部门没了,员工没有部门(空不能):null=True, on_delete=models.SET_NULL # 部门没了,员工进入默认部门(默认值):default=0, on_delete=models.SET_DEFAULT
ser.py
ser.py from rest_framework import serializers from api import models #写一个类,继ListSerializer,重写update class BookListSerializer(serializers.ListSerializer): # def create(self, validated_data): # print(validated_data) # return super().create(validated_data) def update(self, instance, validated_data): print(instance) print(validated_data) # 保存数据 # self.child:是BookModelSerializer对象 # ll=[] # for i,si_data in enumerate(validated_data): # ret=self.child.update(instance[i],si_data) # ll.append(ret) # return ll return [ # self.child.update(对象,字典) for attrs in validated_data self.child.update(instance[i],attrs) for i,attrs in enumerate(validated_data) ] #如果序列化的是数据库的表,尽量用ModelSerializer class BookModelSerializer(serializers.ModelSerializer): # 一种方案(只序列化可以,反序列化有问题) # publish=serializers.CharField(source='publish.name') # 第二种方案,models中写方法 class Meta: list_serializer_class=BookListSerializer model=models.Book # fields='__all__' # 用的少 # depth=0 fields = ('name','price','authors','publish','publish_name','author_list') extra_kwargs={ 'publish':{'write_only':True}, 'publish_name':{'read_only':True}, 'authors':{'write_only':True}, 'author_list':{'read_only':True} }
views.py
# views.py from rest_framework.response import Response from api import models from rest_framework.views import APIView from rest_framework.generics import GenericAPIView from api.ser import BookModelSerializer class BookAPIView(APIView): def get(self,request,*args,**kwargs): #查询单个和查询所有,合到一起 # 查所有 book_list=models.Book.objects.all().filter(is_delete=False) book_list_ser=BookModelSerializer(book_list,many=True) return Response(data=book_list_ser.data) #查一个 def post(self,request,*args,**kwargs): # 具备增单条,和增多条的功能 if isinstance(request.data,dict): book_ser=BookModelSerializer(data=request.data) book_ser.is_valid(raise_exception=True) book_ser.save() return Response(data=book_ser.data) elif isinstance(request.data,list): #现在book_ser是ListSerializer对象 from rest_framework.serializers import ListSerializer book_ser = BookModelSerializer(data=request.data,many=True) #增多条 print('--------',type(book_ser)) book_ser.is_valid(raise_exception=True) book_ser.save() # 新增---》ListSerializer--》create方法 # def create(self, validated_data): # self.child是BookModelSerializer对象 # print(type(self.child)) # return [ # self.child.create(attrs) for attrs in validated_data # ] return Response(data=book_ser.data) def put(self,request,*args,**kwargs): # 改一个,改多个 #改一个个 if kwargs.get('pk',None): book=models.Book.objects.filter(pk=kwargs.get('pk')).first() book_ser = BookModelSerializer(instance=book,data=request.data,partial=True) # 增多条 book_ser.is_valid(raise_exception=True) book_ser.save() return Response(data=book_ser.data) else: #改多个, # 前端传递数据格式[{id:1,name:xx,price:xx},{id:1,name:xx,price:xx}] # 处理传入的数据 对象列表[book1,book2] 修改的数据列表[{name:xx,price:xx},{name:xx,price:xx}] book_list=[] modify_data=[] for item in request.data: #{id:1,name:xx,price:xx} pk=item.pop('id') book=models.Book.objects.get(pk=pk) book_list.append(book) modify_data.append(item) # 第一种方案,for循环一个一个修改 #把这个实现 # for i,si_data in enumerate(modify_data): # book_ser = BookModelSerializer(instance=book_list[i], data=si_data) # book_ser.is_valid(raise_exception=True) # book_ser.save() # return Response(data='成功') # 第二种方案,重写ListSerializer的update方法 book_ser = BookModelSerializer(instance=book_list,data=modify_data,many=True) book_ser.is_valid(raise_exception=True) book_ser.save() #ListSerializer的update方法,自己写的update方法 return Response(book_ser.data) # request.data # # book_ser=BookModelSerializer(data=request.data) def delete(self,request,*args,**kwargs): #单个删除和批量删除 pk=kwargs.get('pk') pks=[] if pk: # 单条删除 pks.append(pk) #不管单条删除还是多条删除,都用多条删除 #多条删除 # {'pks':[1,2,3]} else: pks=request.data.get('pks') #把is_delete设置成true # ret返回受影响的行数 ret=models.Book.objects.filter(pk__in=pks,is_delete=False).update(is_delete=True) if ret: return Response(data={'msg':'删除成功'}) else: return Response(data={'msg': '没有要删除的数据'})
urls.py
# urls.py from django.urls import path,re_path from api import views urlpatterns = [ path('books/', views.BookAPIView.as_view()), re_path('books/(?P<pk>\d+)', views.BookAPIView.as_view()), ]
# 查所有,才需要分页 from rest_framework.generics import ListAPIView # 内置三种分页方式 from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination ''' PageNumberPagination page_size:每页显示的条数 '''
# 第一种分页 from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
class MyPageNumberPagination(PageNumberPagination): #http://127.0.0.1:8000/api/books2/?aaa=1&size=6 page_size=3 #每页条数 page_query_param='aaa' #查询第几页的key page_size_query_param='size' # 可以在前端通过size=xxx控制每一页显示的条数 max_page_size=5 # 每页最大显示条数 class BookView(ListAPIView): # queryset = models.Book.objects.all().filter(is_delete=False) queryset = models.Book.objects.all() serializer_class = BookModelSerializer #配置分页 pagination_class = MyPageNumberPagination
二、标杆分页
# 第二种分页 from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination class MyLimitOffsetPagination(LimitOffsetPagination): default_limit = 3 # 每页条数 limit_query_param = 'limit' # 往后拿几条 offset_query_param = 'offset' # 标杆 max_limit = 5 # 每页最大几条 class BookView(ListAPIView): # queryset = models.Book.objects.all().filter(is_delete=False) queryset = models.Book.objects.all() serializer_class = BookModelSerializer #配置分页 pagination_class = MyLimitOffsetPagination
三、排序分页
# 第三种分页 from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination class MyCursorPagination(CursorPagination): cursor_query_param = 'cursor' # 每一页查询的key page_size = 2 #每页显示的条数 ordering = '-id' #排序字段 class BookView(ListAPIView): # queryset = models.Book.objects.all().filter(is_delete=False) queryset = models.Book.objects.all() serializer_class = BookModelSerializer #配置分页 pagination_class = MyCursorPagination
如果继承APIView/GenericAPIView类的分页使用
# 如果使用APIView/GenericAPIView分页 from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination from utils.throttling import MyThrottle class MyPageNumberPagination(PageNumberPagination): page_size=1 #每页条数 page_query_param='page' #查询第几页的key page_size_query_param='size' # 可以在前端通过size=xxx控制每一页显示的条数 max_page_size=5 # 每页最大显示条数 class BookView(APIView): # throttle_classes = [MyThrottle,]
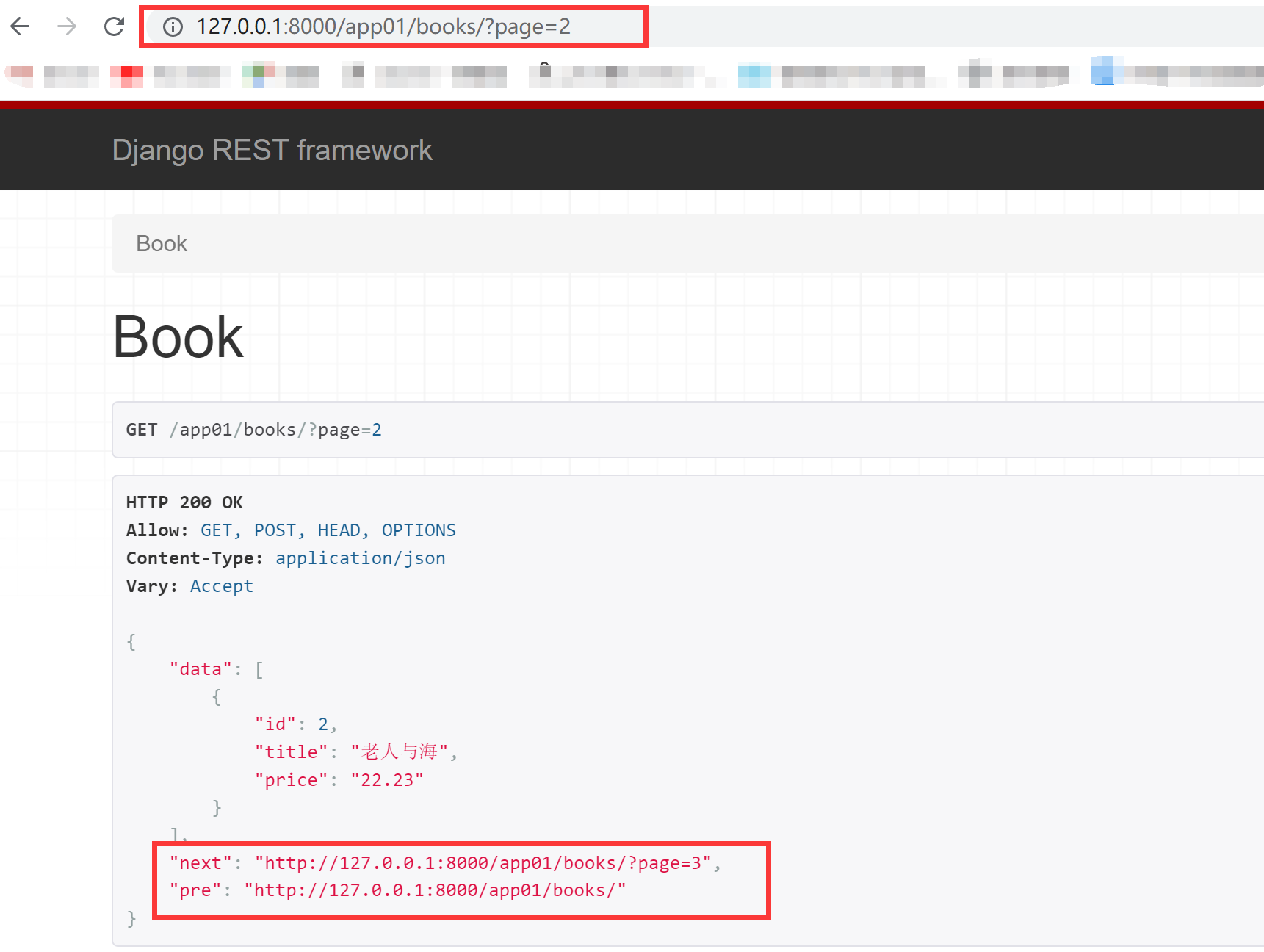
def get(self,request,*args,**kwargs): book_list=models.Book.objects.all()
# 实例化得到一个分页器对象 page_cursor=MyPageNumberPagination() book_list=page_cursor.paginate_queryset(book_list,request,view=self) next_url =page_cursor.get_next_link() # 需要return才会显示 pr_url=page_cursor.get_previous_link() # 需要return才会显示 # print(next_url) # print(pr_url) book_ser=BookModelSerializer(book_list,many=True) return Response({'data':book_ser.data, 'next':next_url,'pre': pre_url}) #settings.py REST_FRAMEWORK={ 'PAGE_SIZE': 2, }
# 写一个类,继承SimpleRateThrottle,只需要重写get_cache_key from rest_framework.throttling import SimpleRateThrottle #继承SimpleRateThrottle class MyThrottle(SimpleRateThrottle): scope='luffy' def get_cache_key(self, request, view): print(request.META.get('REMOTE_ADDR')) return request.META.get('REMOTE_ADDR') # 返回 # 局部使用,全局使用 REST_FRAMEWORK={ 'DEFAULT_THROTTLE_CLASSES': ( 'utils.throttling.MyThrottle', ), 'DEFAULT_THROTTLE_RATES': { 'luffy': '3/m' # key要跟类中的scop对应 }, } # python3 manage.py runserver 0.0.0.0:8000 你们局域网就可以相互访问 # 内网穿透
总结
#1 book 其实是5个表(自动生成了一个), -一对一关系,其实是Forainkey,unique -on_delete:级联删除,设置为空,什么都不干,设置成默认值 -字段建索引,字段唯一 -联合索引,联合唯一 -日期类型 auto_now 和 auto_now_add -基表 abstract #2 book -单条查询,多条查询 -单条增,多条增(生成序列化对象,many=True) -单条修改,多条修改(BookListSerializer:重写了update方法) -单删,群删(is_delete),统一用群删 pk__in=[1,2,3] # 3 频率 -自定义频率(ip,user_id) -继承SimpleRateThrottle -重写get_cache_key,返回什么就以什么为key进行限制 -scope字段,需要与setting中对应 #4 分页 -PageNumberPagination,基本分页 # page_size-每页显示大小 # page_query_param-get请求路径中查询的key # page_size_query_param-前端控制get请求路径中每页显示条数 # max_page_size-每页最大显示多少条 -LimitOffsetPagination,偏移量分页 # default_limit = 3 # 每页条数 # limit_query_param = 'limit' # 往后拿几条 # offset_query_param = 'offset' # 标杆 # max_limit = 5 # 每页最大几条 -CursorPagination,游标分页 # cursor_query_param = 'cursor' # 每一页查询的key # page_size = 2 #每页显示的条数 # ordering = '-id' #排序字段-
# 自定制频率类,需要写两个方法 -# 判断是否限次:没有限次可以请求True,限次了不可以请求False def allow_request(self, request, view): -# 限次后调用,显示还需等待多长时间才能再访问,返回等待的时间seconds def wait(self): # 代码 import time class IPThrottle(): #定义成类属性,所有对象用的都是这个 VISIT_DIC = {} def __init__(self): self.history_list=[] def allow_request(self, request, view): ''' #(1)取出访问者ip #(2)判断当前ip不在访问字典里,添加进去,并且直接返回True,表示第一次访问,在字典里,继续往下走 #(3)循环判断当前ip的列表,有值,并且当前时间减去列表的最后一个时间大于60s,把这种数据pop掉,这样列表中只有60s以内的访问时间, #(4)判断,当列表小于3,说明一分钟以内访问不足三次,把当前时间插入到列表第一个位置,返回True,顺利通过 #(5)当大于等于3,说明一分钟内访问超过三次,返回False验证失败 ''' ip=request.META.get('REMOTE_ADDR') ctime=time.time() if ip not in self.VISIT_DIC: self.VISIT_DIC[ip]=[ctime,] return True self.history_list=self.VISIT_DIC[ip] #当前访问者时间列表拿出来 while True: if ctime-self.history_list[-1]>60: self.history_list.pop() # 把最后一个移除 else: break if len(self.history_list)<3: self.history_list.insert(0,ctime) return True else: return False def wait(self): # 当前时间,减去列表中最后一个时间 ctime=time.time() return 60-(ctime-self.history_list[-1]) #全局使用,局部使用
# SimpleRateThrottle源码分析 def get_rate(self): """ Determine the string representation of the allowed request rate. """ if not getattr(self, 'scope', None): msg = ("You must set either `.scope` or `.rate` for '%s' throttle" % self.__class__.__name__) raise ImproperlyConfigured(msg) try: return self.THROTTLE_RATES[self.scope] # scope:'user' => '3/min' except KeyError: msg = "No default throttle rate set for '%s' scope" % self.scope raise ImproperlyConfigured(msg) def parse_rate(self, rate): """ Given the request rate string, return a two tuple of: <allowed number of requests>, <period of time in seconds> """ if rate is None: return (None, None) #3 mmmmm num, period = rate.split('/') # rate:'3/min' num_requests = int(num) duration = {'s': 1, 'm': 60, 'h': 3600, 'd': 86400}[period[0]] return (num_requests, duration) def allow_request(self, request, view): if self.rate is None: return True #当前登录用户的ip地址 self.key = self.get_cache_key(request, view) # key:'throttle_user_1' if self.key is None: return True # 初次访问缓存为空,self.history为[],是存放时间的列表 self.history = self.cache.get(self.key, []) # 获取一下当前时间,存放到 self.now self.now = self.timer() # Drop any requests from the history which have now passed the # throttle duration # 当前访问与第一次访问时间间隔如果大于60s,第一次记录清除,不再算作一次计数 # 10 20 30 40 # self.history:[10:23,10:55] # now:10:56 while self.history and self.now - self.history[-1] >= self.duration: self.history.pop() # history的长度与限制次数3进行比较 # history 长度第一次访问0,第二次访问1,第三次访问2,第四次访问3失败 if len(self.history) >= self.num_requests: # 直接返回False,代表频率限制了 return self.throttle_failure() # history的长度未达到限制次数3,代表可以访问 # 将当前时间插入到history列表的开头,将history列表作为数据存到缓存中,key是throttle_user_1,过期时间60s return self.throttle_success()
# 1 安装:pip install coreapi # 2 在总路由中配置 from rest_framework.documentation import include_docs_urls urlpatterns = [ ... path('docs/', include_docs_urls(title='站点页面标题')) ] #3 视图类:自动接口文档能生成的是继承自APIView及其子类的视图。 -1 ) 单一方法的视图,可直接使用类视图的文档字符串,如 class BookListView(generics.ListAPIView): """ 返回所有图书信息. """ -2)包含多个方法的视图,在类视图的文档字符串中,分开方法定义,如 class BookListCreateView(generics.ListCreateAPIView): """ get: 返回所有图书信息. post: 新建图书. """ -3)对于视图集ViewSet,仍在类视图的文档字符串中封开定义,但是应使用action名称区分,如 class BookInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet): """ list: 返回图书列表数据 retrieve: 返回图书详情数据 latest: 返回最新的图书数据 read: 修改图书的阅读量 """ -4)基于APIView的接口,定义在对应的方法下面,如: class BookAPIView(APIView): def get(self, request, *args, **kwargs): ''' get查所有的接口文档 ''' book = models.Book.objects.all() book_ser = BookModelSerializer(instance=book, many=True) return Response(book_ser.data) def post(self, request, *args, **kwargs): ''' post添加数据接口 ''' book = models.Book.objects.all() book_ser = BookModelSerializer(instance=book, data=request.data) if book_ser.is_valid(): book_ser.save() return Response(book_ser.data) 如果进入docs报了下面的错误,说明我们缺少一个依赖, 'AutoSchema' object has no attribute 'get_link'
只需要在setting中配置如下: REST_FRAMEWORK = { 'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.AutoSchema', } 两点说明: 1) 视图集ViewSet中的retrieve名称,在接口文档网站中叫做read 2)参数的Description需要在模型类或序列化器类的字段中以help_text选项定义,如: class Student(models.Model): ... age = models.IntegerField(default=0, verbose_name='年龄', help_text='年龄') ...
注意,如果你多个应用使用同一个序列化器,可能会导致help_text的内容显示有些问题,小事情 class StudentSerializer(serializers.ModelSerializer): class Meta: model = Student fields = "__all__" extra_kwargs = { 'age': { 'required': True, 'help_text': '年龄' } }
详情见drf自动生成API文档
jwt=Json Web token #原理 """ 1)jwt分三段式:头.体.签名 (head.payload.sgin) 2)头和体是可逆加密,让服务器可以反解出user对象;签名是不可逆加密,保证整个token的安全性的 3)头体签名三部分,都是采用json格式的字符串,进行加密,可逆加密一般采用base64算法,不可逆加密一般采用hash(md5)算法 4)头中的内容是基本信息:公司信息、项目组信息、token采用的加密方式信息 { "company": "公司信息", ... } 5)体中的内容是关键信息:用户主键、用户名、签发时客户端信息(设备号、地址)、过期时间 { "user_id": 1, ... } 6)签名中的内容时安全信息:头的加密结果 + 体的加密结果 + 服务器不对外公开的安全码 进行md5加密 { "head": "头的加密字符串", "payload": "体的加密字符串", "secret_key": "安全码" } """ 校验 """ 1)将token按 . 拆分为三段字符串,第一段 头加密字符串 一般不需要做任何处理 2)第二段 体加密字符串,要反解出用户主键,通过主键从User表中就能得到登录用户,过期时间和设备信息都是安全信息,确保token没过期,且时同一设备来的 3)再用 第一段 + 第二段 + 服务器安全码 不可逆md5加密,与第三段 签名字符串 进行碰撞校验,通过后才能代表第二段校验得到的user对象就是合法的登录用户 """ drf项目的jwt认证开发流程(重点) """ 1)用账号密码访问登录接口,登录接口逻辑中调用 签发token 算法,得到token,返回给客户端,客户端自己存到cookies中 2)校验token的算法应该写在认证类中(在认证类中调用),全局配置给认证组件,所有视图类请求,都会进行认证校验,所以请求带了token,就会反解出user对象,在视图类中用request.user就能访问登录的用户 注:登录接口需要做 认证 + 权限 两个局部禁用 """ # 第三方写好的 django-rest-framework-jwt # 安装pip install djangorestframework-jwt # 新建一个项目,继承AbstractUser表() # 创建超级用户 # 简单使用 #urls.py from rest_framework_jwt.views import ObtainJSONWebToken,VerifyJSONWebToken,RefreshJSONWebToken,obtain_jwt_token path('login/', obtain_jwt_token),
# 1 控制用户登录后才能访问,和不登录就能访问 from rest_framework.permissions import IsAuthenticated class OrderAPIView(APIView):# 登录才能 authentication_classes = [JSONWebTokenAuthentication,] # 权限控制 permission_classes = [IsAuthenticated,] def get(self,request,*args,**kwargs): return Response('这是订单信息') class UserInfoAPIView(APIView):# 不登录就可以 只需要去除权限控制 authentication_classes = [JSONWebTokenAuthentication,] # 权限控制 # permission_classes = [IsAuthenticated,] def get(self,request,*args,**kwargs): return Response('UserInfoAPIView')
# 2 控制登录接口返回的数据格式 -第一种方案,自己写登录接口 -第二种写法,用内置,控制登录接口返回的数据格式 -jwt的settings.py中有这个属性 'JWT_RESPONSE_PAYLOAD_HANDLER':'rest_framework_jwt.utils.jwt_response_payload_handler', -重写jwt_response_payload_handler,配置成咱们自己的
# 方式一:基于BaseAuthentication from rest_framework.authentication import BaseAuthentication from rest_framework.exceptions import AuthenticationFailed from rest_framework_jwt.authentication import jwt_decode_handler import jwt from api import models class MyJwtAuthentication(BaseAuthentication): def authenticate(self, request): jwt_value=request.META.get('HTTP_AUTHORIZATION') # 获取前端token if jwt_value: try: #jwt提供了通过三段token,取出payload的方法,并且有校验功能 payload=jwt_decode_handler(jwt_value) # 通过token反解出payload except jwt.ExpiredSignature: raise AuthenticationFailed('签名过期') except jwt.InvalidTokenError: raise AuthenticationFailed('用户非法') except Exception as e: # 所有异常都会走到这 raise AuthenticationFailed(str(e)) # 因为payload就是用户信息的字典 print(payload) # return payload, jwt_value # 需要得到user对象, # 第一种,payload中包含用户信息 # 通过payload中提取的数据去数据库校验用户是否存在 # user=models.User.objects.get(pk=payload.get('user_id')) # 第二种不查库 user=models.User(id=payload.get('user_id'),username=payload.get('username')) return user,jwt_value # 没有值,直接抛异常 raise AuthenticationFailed('您没有携带认证信息') # 方式二:基于BaseJSONWebTokenAuthentication from rest_framework_jwt.authentication import BaseJSONWebTokenAuthentication from rest_framework.exceptions import AuthenticationFailed from rest_framework_jwt.authentication import jwt_decode_handler import jwt class MyJwtAuthentication(BaseJSONWebTokenAuthentication): def authenticate(self, request): jwt_value=request.META.get('HTTP_AUTHORIZATION') if jwt_value: try: #jwt提供了通过三段token,取出payload的方法,并且有校验功能 payload=jwt_decode_handler(jwt_value) except jwt.ExpiredSignature: raise AuthenticationFailed('签名过期') except jwt.InvalidTokenError: raise AuthenticationFailed('用户非法') except Exception as e: # 所有异常都会走到这 raise AuthenticationFailed(str(e)) # self.authenticate_credentials本质也是查数据库 user=self.authenticate_credentials(payload) return user,jwt_value # 没有值,直接抛异常 raise AuthenticationFailed('您没有携带认证信息') ''' jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER payload = jwt_payload_handler(user) # 把user传入,得到payload token = jwt_encode_handler(payload) # 把payload传入,得到token '''
# 使用用户名,手机号,邮箱,都可以登录# # 前端需要传的数据格式 { "username":"lqz/1332323223/33@qq.com", "password":"lqz12345" } # views.py 视图类 from rest_framework.views import APIView from rest_framework.viewsets import ViewSetMixin, ViewSet from app02 import ser class Login2View(ViewSet): # 跟上面完全一样 def login(self, request, *args, **kwargs): # 1 需要 有个序列化的类 login_ser = ser.LoginModelSerializer(data=request.data,context={'request':request}) # 2 生成序列化类对象 # 3 调用序列号对象的is_validad login_ser.is_valid(raise_exception=True) token=login_ser.context.get('token') # 4 return return Response({'status':100,'msg':'登录成功','token':token,'username':login_ser.context.get('username')})
# ser.py 序列化类
from rest_framework import serializers from api import models import re from rest_framework.exceptions import ValidationError from rest_framework_jwt.utils import jwt_encode_handler,jwt_payload_handler class LoginModelSerializer(serializers.ModelSerializer): username=serializers.CharField() # 重新覆盖username字段,数据中它是unique唯一,post请求认为你在新增数据,校验会不通过 class Meta: model=models.User fields=['username','password'] def validate(self, attrs): print(self.context) # 在这写逻辑 username=attrs.get('username') # 用户名有三种方式 password=attrs.get('password') # 通过判断,username数据不同,查询字段不一样 # 正则匹配,如果是手机号 if re.match('^1[3-9][0-9]{9}$',username): user=models.User.objects.filter(mobile=username).first() elif re.match('^.+@.+$',username):# 邮箱 user=models.User.objects.filter(email=username).first() else: user=models.User.objects.filter(username=username).first() if user: # 存在用户 # 校验密码,因为是密文,要用check_password if user.check_password(password): # 签发token payload = jwt_payload_handler(user) # 把user传入,得到payload token = jwt_encode_handler(payload) # 把payload传入,得到token self.context['token']=token self.context['username']=user.username return attrs else: raise ValidationError('密码错误') else: raise ValidationError('用户不存在')
# settings.py
# jwt的配置 import datetime JWT_AUTH={ 'JWT_RESPONSE_PAYLOAD_HANDLER':'app02.utils.my_jwt_response_payload_handler', 'JWT_EXPIRATION_DELTA': datetime.timedelta(days=7), # 过期时间,手动配置 }
# RBAC :是基于角色的访问控制(Role-Based Access Control ),公司内部系统 # django的auth就是内置了一套基于RBAC的权限系统 # django中 # 后台的权限控制(公司内部系统,crm,erp,协同平台) user表 permssion表 group表 user_groups表是user和group的中间表 group_permissions表是group和permssion中间表 user_user_permissions表是user和permission中间表 # 前台(主站),需要用三大认证 # 演示:
# 前端混合开发缓存的使用 -缓存的位置,通过配置文件来操作(以文件为例) -缓存的粒度: -全站缓存 中间件 MIDDLEWARE = [ 'django.middleware.cache.UpdateCacheMiddleware', 。。。。 'django.middleware.cache.FetchFromCacheMiddleware', ] CACHE_MIDDLEWARE_SECONDS=10 # 全站缓存时间 -单页面缓存 在视图函数上加装饰器 from django.views.decorators.cache import cache_page @cache_page(5) # 缓存5s钟 def test_cache(request): import time ctime=time.time() return render(request,'index.html',context={'ctime':ctime}) -页面局部缓存 {% load cache %} {% cache 5 'name' %} # 5表示5s钟,name是唯一key值 {{ ctime }} {% endcache %} # 前后端分离缓存的使用 - 如何使用 from django.core.cache import cache cache.set('key',value可以是任意数据类型) cache.get('key') -应用场景: -第一次查询所有图书,你通过多表联查序列化之后的数据,直接缓存起来 -后续,直接先去缓存查,如果有直接返回,没有,再去连表查,返回之前再缓存
# base64编码和解码 #md5固定长度,不可反解 #base63 变长,可反解 #编码(字符串,json格式字符串) import base64 import json dic={'name':'lqz','age':18,'sex':'男'} dic_str=json.dumps(dic) ret=base64.b64encode(dic_str.encode('utf-8')) print(ret) # 解码 # ret是带解码的串 ret2=base64.b64decode(ret) print(ret2)
整体总结
# 1 restful规范--10条 # 2 django上写符合restful规范的接口 # 3 drf写接口 # 4 APIView--》继承了原生View---》get,post方法 -(为什么get请求来了,就会执行get方法:原生View的dispatch控制的) -路由配置:视图类.as_view()---->view(闭包函数)的内存地址 -请求来了,就会执行view(requst,分组分出的字段,默认传的字段)---》self.dispatch()-->处理的 -APIView重写了dispatch:包装了request对象,解析器,分页,三大认证,响应器,全局异常,去掉了csrf # 5 Request对象:request._request,request.data,重写了__getattr__,request.method-->去原生request中拿 -前端传过来的数据从那取? -地址栏里:request.GET/query_params -请求体中的数据:request.data/POST(json格式解释不了)---》request.body中取 -请求头中数据:request.META.get("HTTP_变成大写") #6 Response对象---》封装了原生的HttpResponse,Response(data,headers={},status=1/2/3/4/5开头的) #7 自己封装了Response对象 # 8 序列化类: -Serializer -写字段,字段名要跟表的字段对应,想不对应(source可以修改),有属性,read_only,max_len... -SerializerMethodField必须配套一个get_字段名,返回什么,前台就看到什么 -ModelSerializer -class Meta: 表对应 取出的字段(__all__,列表) 排除的字段(用的很少) extra_kwargs会给字段的属性 -重写某个字段 password=serializers.SerializerMethodField() def get_password(self,instance): return "***" -校验:字段自己的校验,局部钩子,全局钩子 -只要序列化类的对象执行了is_valiad(),这些钩子都会走,可以再钩子里写逻辑 -在表模型(model)中写方法,可以在上面取出的字段中直接写,不参与反序列化 -序列化多条(many=True):本质,ListSerializer内部套了一个个的serializer对象 -重写ListSerializer,让序列化对象和自己写的ListSerializer对应上(了解) -序列化类(instance,data,many,context={requtst:request}) -视图函数中给序列化对象传递数据,使用context,传回来,放进去直接使用序列化对象.context.get() # 9 视图 -两个视图基类 APIView,GenericAPIView(继承APIView):涉及到数据库和序列化类的操作,尽量用GenericAPIView -5个视图扩展类(父类都是object) CreateModelMixin:create DestroyModelMixin:destory ListModelMixin RetrieveModelMixin UpdateModelMixin -9个视图子类(GenericAPIView+上面5个视图扩展类中的一个或多个) RetrieveUpdateDestroyAPIView CreateAPIView RetrieveAPIView DestroyAPIView RetrieveUpdateAPIView ListCreateAPIView UpdateAPIView ListAPIView RetrieveDestroyAPIView -视图集 -ModelViewSet:5大接口都有了 -ReadOnlyModelViewSet:获取一条和获取多条的接口 -GenericViewSet:ViewSetMixin+GenericAPIView ViewSet:ViewSetMixin+APIView ViewSetMixin:类重写了as_view,路由配置就变样了 # 10 路由 -基本配置:跟之前一样 -有action的:必须继承ViewSetMixin -自动生成:DefaultRouter和SimpleRouter -导入,实例化得到对象,注册多个,对象.urls(自动生成的路由) -路由相加urlpatterns+=router.urls/include:path('', include(router.urls)) -视图类中自己定义的方法,如何自动生成路由 -在自己定义的方法上加装饰器(action) -两个参数methods=[GET,POST],表示这两种请求都能接受 -两个参数detail=True,表示生成带pk的连接 # 11 三大认证 -认证组件:校验用户是否登录 -写一个认证类,继承BaseAuthentication,重写authenticate,内部写认证逻辑,认证通过返回两个值,第一个是user,认证失败,抛去异常 -全局使用,局部使用,局部禁用 -权限:校验用户是否有权限进行后续操作 -写一个类,继承BasePermission,重写has_permission,True和False -全局使用,局部使用,局部禁用 -频率:限制用户访问频次 -写一个类,继承SimpleRateThrottle,重写get_cache_key,返回什么,就以谁做限制,scop=luffy字段,需要跟setting中的key对应 luffy:3/h(一小时访问三次) -全局配置,局部配置,局部禁用 -需求:发送短信验证码的接口,一分钟只能发送一次,局部使用,配在视图类上 # 12 解析器:前端传的编码格式,能不能解析(默认三种全配了,基本不需要改),可能你写了个上传文件接口,局部配置一下,只能传form-data格式 局部使用:MultiPartParser # 13 响应器:响应的数据,是json格式还是带浏览器的那种(不需要配) # 14 过滤器:借助于第三方django-filter -注册应用 -setting中配置DjangoFilterBackend或者局部配置 -filter_fields = ('age', 'sex') # 15 排序 -全局或者局部配置rest_framework.filters.OrderingFilter -视图类中配置: ordering_fields = ('id', 'age') # 16 分页 -使用: 继承了APIView的视图类中使用 page=Mypage() # 在数据库中获取分页的数据 page_list=page.paginate_queryset(queryset对象,request,view=self) # 对分页进行序列化 ser=BookSerializer1(instance=page_list,many=True) # return Response(ser.data) 继承了视图子类的视图中使用 pagination_class = PageNumberPagination(配置成自己重写的,可以修改字段) -CursorPagination cursor_query_param:默认查询字段,不需要修改 page_size:每页数目 ordering:按什么排序,需要指定 -LimitOffsetPagination default_limit 默认限制,默认值与PAGE_SIZE设置一直 limit_query_param limit参数名,默认’limit’ offset_query_param offset参数名,默认’offset’ max_limit 最大limit限制,默认None -PageNumberPagination:最常用的,需要在setting中配置page_size,四个参数 page_size 每页数目 page_query_param 前端发送的页数关键字名,默认为”page” page_size_query_param 前端发送的每页数目关键字名,默认为None max_page_size 前端最多能设置的每页数量 # 17 全局异常 -写一个方法 def exception_handler(exc, context): # 走drf原来的异常,原理异常有一些处理 response = drf_exception_handler(exc, context) # 我们自己处理,drf没有处理,丢给django的异常 if response is None: if isinstance(exc, DatabaseError):#处理了一下数据库错误 response = Response({'detail': '数据库错误'}, status=status.HTTP_507_INSUFFICIENT_STORAGE) else:#其他异常 response = Response({'detail': '未知错误'}, status=status.HTTP_500_INTERNAL_SERVER_ERROR) return response -配置文件中配置(以后所有drf的异常,都会走到这里) REST_FRAMEWORK = { 'EXCEPTION_HANDLER': 'my_project.my_app.utils.custom_exception_handler' } -18 jwt -是什么json web token 新的认证方式 -三段:头,荷载(用户信息),签名 -使用:最简单方式(在路由中配置) -path('login/', obtain_jwt_token), -自定制: 多方式登录,手动签发token(两个方法) -自定制基于jwt的认证类 -取出token -调用jwt提供的解析出payload的方法(校验是否过期,是否合法,如果合法,返回荷载信息) -转成user对象 -返回 -19 RBAC:基于角色的权限控制(django默认的auth就是给你做了这个事),公司内部权限管理 对外的权限管理就是用三大认证 -用户表 -用户组表 -权限表 -用户对用户组中间表 -用户组对权限中间表 -用户对权限中间表


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix