
openpyxl/csv--python处理excel表格模块
#conding='utf-8'
#属性方法参考:https://zhuanlan.zhihu.com/p/43186995
#Workbook ;worksheet;active;load_workbook;cell;value;rows;append
"""
workbook对象属性:
- active:获取当前活跃的Worksheet
- worksheets:以列表的形式返回所有的Worksheet(表格)
- read_only:判断是否以read_only模式打开Excel文档
- encoding:获取文档的字符集编码
- properties:获取文档的元数据,如标题,创建者,创建日期等
- sheetnames:获取工作簿中的表(列表)
workbook对象方法:
- get_sheet_names:获取所有表格的名称(新版已经不建议使用,通过Workbook的sheetnames属性即可获取) ws = wb["frequency"] == ws2 = wb.get_sheet_by_name('frequency')
- get_sheet_by_name:通过表格名称获取Worksheet对象(新版也不建议使用,通过Worksheet[‘表名‘]获取)
- get_active_sheet:获取活跃的表格(新版建议通过active属性获取)
- remove_sheet:删除一个表格
- create_sheet:创建一个空的表格
- copy_worksheet:在Workbook内拷贝表格
worksheet对象属性:- title:表格的标题
- dimensions:表格的大小,这里的大小是指含有数据的表格的大小,即:左上角的坐标:右下角的坐标
- max_row:表格的最大行
- min_row:表格的最小行
- max_column:表格的最大列
- min_column:表格的最小列
- rows:按行获取单元格(Cell对象) - 生成器
- columns:按列获取单元格(Cell对象) - 生成器
- freeze_panes:冻结窗格
- values:按行获取表格的内容(数据) - 生成器
worksheet对象方法:
- iter_rows:按行获取所有单元格,内置属性有(min_row,max_row,min_col,max_col)
- iter_columns:按列获取所有的单元格
- append:在表格末尾添加数据
- merged_cells:合并多个单元格
- unmerged_cells:移除合并的单元格
Cell对象:
- row:单元格所在的行
- column:单元格坐在的列
- value:单元格的值 返回字符串格式数据,可应用字符串方法
- coordinate:单元格的坐标
"""
import openpyxl
#test1:新建excel
#1.创建工作簿
wb=openpyxl.Workbook()
#2.找到当前工作簿中处于激活状态的工作表
ws=wb.active
#print(ws) <Worksheet "Sheet">
#也可以使用create_sheet方法
#ws1=wb.create_sheet('工作1')
#print(ws1) <Worksheet "工作1">name为工作1的sheet
#3.查看工作表标题文字属性;也可进行赋值操作
print(ws.title) #"Sheet"
#查看当前工作簿下所有工作表名
print(wb.sheetnames) #返回一个列表
#4.操作
#设置某一单元格内容
ws['A1']=41
ws['c1']='姓名'
ws.cell(row=7,column=3,value='("python","123456")')
#写入一行
ws.append([1,2,3,4])
data=[(1,'tom',90),
(2,'ham',153),
(3,'fs',153),
(4,'hha',133)
]
##这里注意写入数据会在接在上面写入的位置之后,根据行列的情况继续向下写
print('---方法一、写入一个序列数据--')
#通过enumerate获取index进行数据写入
for i,row in enumerate(data):
for j,col in enumerate(row):
ws.cell(row=i+2,column=j+1,value=col)
print('----方法二、写入一个序列数据--------')
#(append方法)
for i,row in enumerate(data):
ws.append(row)
#保存文件
wb.save('test_creat_excel.xlsx')
#打开工作簿
wb=openpyxl.load_workbook('case.xlsx')
#选择工作表对象
#a查看所有表名称
print(wb.sheetnames)
#创建表一对象
ws=wb['表一']
#修改表名称
#ws.title='新建表格1'
#print(wb.sheetnames)
#读取表内信息
#A.cell()方法获取单元格数据
data =ws.cell(row=5,column=4)
#value方法获得内容,获取D5的值
print(data,'的值为',data.value)
#通过列表单元格获取对象同样返回所有行元组对象
#ws['A1':'C6']
print(ws['A1':'C6'])
"""
((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>),
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>),
(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>),
(<Cell 'Sheet1'.A4>, <Cell 'Sheet1'.B4>, <Cell 'Sheet1'.C4>),
(<Cell 'Sheet1'.A5>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.C5>),
(<Cell 'Sheet1'.A6>, <Cell 'Sheet1'.B6>, <Cell 'Sheet1'.C6>))
"""
#读取行列信息返回单行/列元组对象,不具有value属性 #通过迭代ws.rows方法读取所有行信息 print('----ws.rows------') row_list=ws.rows for i in row_list: print(i)# (<Cell '表一'.A1>, <Cell '表一'.B1>, <Cell '表一'.C1>, <Cell '表一'.D1>) print('---ws.columns----')
#通过迭代ws.columns方法获取所有列信息 columns_list=ws.columns for i in columns_list: print(i)
#通过迭代ws.rows方法读取,读取第一列value数据
#如:提取第一列数据
import openpyxl
wb=openpyxl.load_workbook('进程.xlsx')
ws=wb.active
for row in ws.rows:
print(row[0].value)
"""
None None 一人之下 None None 完美世界 None 火影忍者 None None 天刀
"""

print('---ws.cell()错误用法-----')
#这里ws.rows;ws.column都是迭代器,因此没有len()
"""for r in range(len(row_list)):
for c in range(len(columns_list)):
print(ws.cell(row=r, column=c).value)
"""
#通过max_row和max_column的len()方法获取长度迭代
print('-----方法一、ws.cell().value读取全部数据---------')
for r in range(1,ws.max_row):
for c in range(ws.max_column):
data=ws.cell(row=r,column=c+1).value #Row or column values must be at least 至少要第二行起
print(data,end='\t')
print(end='\n')
print('-----------方法二、已知列数,通过row检索的方式获得row.value-----------------------')
for row in ws.rows:
#这里的row[0],指向行元组中对的第一个cell,获得
print(row[0].value,row[1].value,row[2].value,row[3].value)
#通过enumerate的方式读取, 所有数据
import openpyxl
wb=openpyxl.load_workbook('test.xlsx')
ws=wb.active
for index,row in enumerate(ws.rows):
for i,col in enumerate(row):
if row[i].value !=None:
print(row[i].value,end='')
print('')
"""
由于最后一行会出现None,为了不打印None故进行了判断
时间地点人物年龄 44113上海王王12 44173北京智能13 43832东京张三23 44028河北李静16 43897山西能者18
"""
csv模块
csv测试数据时,可以以文件形式进行读写('r','w')
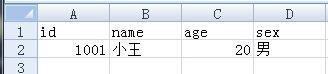
import csv #写入 f=open(r'C:\Users\Administrator\Desktop\test.csv','a') cont=csv.writer(f) data=['id','name','age','sex'] #写入列表数据 cont.writerow(data)f.close()

#写入元组数据
data2=('1001','小王','20','男')
cont.writerow(data2)
f.close()
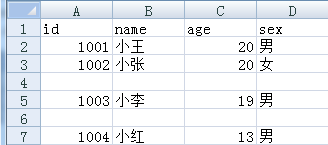
#写入列表集数据
data3=[['1002','小张','20','女'],['1003','小李','19','男'],['1004','小红','13','男']]
cont.writerows(data3)
f.close()
#注意:打印会出现空行,需要在打开文件时,在open内需要重写参数newline(newline='')
f=open(r'C:\Users\Administrator\Desktop\test.csv','a',newline='')
cont=csv.writer(f)
data=['id','name','age','sex']
#写入列表集数据
#writerow 与 writerows的区别
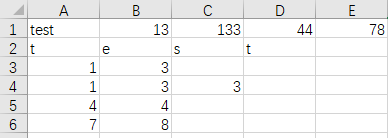
import csv
file=open('csv_test.csv','a',newline='')
writer=csv.writer(file)
data=['test','13','133','44','78']#python中的int类型在写入csv报错,变为str即可
#writerow 与writerows的区别
print('----writerow----')
writer.writerow(data)
print('----writerows----')
writer.writerows(data)
#1.使用writerows写入数据集数据
data3=[['1002','小张','20','女'],['1003','小李','19','男'],['1004','小红','13','男']]
cont.writerows(data3)
f.close()
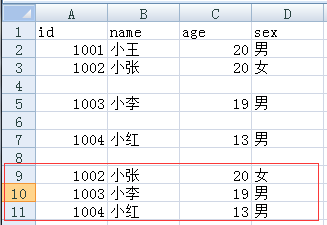
#2.使用writerow迭代写入数据集内单元数据
for i in data3:
cont.writerow(i)
f.close()
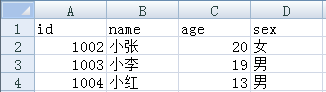
#读取数据
f=open(r'C:\Users\Administrator\Desktop\test.csv','r')
cont=csv.reader(f)
for i in cont:
print(i)
"""
['id', 'name', 'age', 'sex'] ['1002', '小张', '20', '女'] ['1003', '小李', '19', '男'] ['1004', '小红', '13', '男']
"""
#字典类型数据写入
datas = [{'name': 'Bob', 'age': 23},{'name': 'Jerry', 'age': 44},{'name': 'Tom', 'age': 15} ]
with open('test_csv_data.csv', 'w', newline='') as f:
writer = csv.DictWriter(f, ['name', 'age'])# 标头在这里传入,作为第一行数据
writer.writeheader()
for row in datas:
writer.writerow(row)
# 还可以写入多行
#writer.writerows(datas)
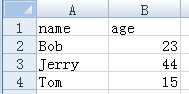
#字典类型数据读取
with open('test_csv_data.csv','r') as f:
reader = csv.DictReader(f)
for row in reader:
print(row['name'], row['age'])
"""
Bob 23 Jerry 44 Tom 15
"""

