
python --bs4
#https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/#attributes &https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
| 属性: | 返回值 | 返回类型 |
| soup.prettify()方法 | 友好显示,在内容中加入\n | str |
| soup.(Tag.name) (ex:soup.title) | <meta content="text/html;charset=utf-8" http-equiv="Content-Type"/> | bs4.element.Tag( bs4标签) |
| soup.(Tag.name).attrs (ex:soup.meta.attrs) |
{'class': ['align-left'], 'data-v-45ac69d8': ''}
|
dict |
| soup.(Tag.name) .attrs['key'] (ex:soup.td.attrs['class']) | ['align-left'] or ' ' | str ,list (value的数据类型) |
|
soup.(Tag.name) .string/soup.标签.text (ex:soup.p.string) |
The demo python introduces several python courses
|
<class 'bs4.element.NavigableString'>/text方法返回字符串
|
| comment 通过string方法进行获取 | ||
| 遍历(针对标签进行遍历) | ||
| 下行遍历 | ||
|
soup.(Tag.name) .contents/soup.find('Tag.name').contents (ex:soup.td.contents/soup.find('td').contents) |
[<a data-v-45ac69d8="" href="/institution/tsinghua-university">清华大学</a>, |
list |
|
soup.(Tag.name) .children/soup.find('Tag.name').children (ex:soup.td.children/soup.find('td').children) |
<list_iterator at 0x2354835ed90>; 可使用for循环调用: <a data-v-45ac69d8="" href="/institution/tsinghua-university">清华大学</a> <p data-v-45ac69d8="" style="display:none"></p> |
list_iterator 使用for循环调用结果返回数据类型:
<class 'bs4.element.Tag'>
|
|
soup.(Tag.name) .descendants/soup.find('Tag.name').descendants (ex:soup.td.descendants/soup.find('td').descendants)
|
||
| 上行遍历 | ||
|
soup.(Tag.name) .parent/soup.find('Tag.name').parent (ex:soup.td.parent/soup.find('td').parent) |
<td class="align-left" data-v-45ac69d8=""><a data-v-45ac69d8="" href="/institution/tsinghua-university">清华大 学</a> <p data-v-45ac69d8="" style="display:none"></p></td> | bs4.element.Tag |
|
soup.(Tag.name) .parents/soup.find('Tag.name').parents (ex:soup.td.parents/soup.find('td').parents) |
可用for循环进行调用 | generator |
soup.prettify()方法
基于bs4库HTML的格式输出(即在内容中加入换行符)
如何让<html>页面更友好的显示
import requests
from bs4 import BeautifulSoup
res=requests.get('http://python123.io/ws/demo.html')
demo=res.text
print(demo)

soup=BeautifulSoup('demo',"html.parser")
print(soup.prettify())

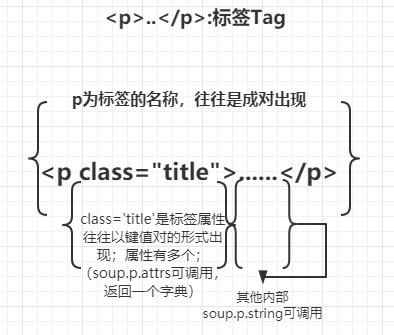
HTML标签格式:
Beautiful Soup
库的引用:
#这里BeautifulSoup中的BS为大写
from bs4 import BeautifulSoup
import bs4
soup中html获取方式
如果是requests爬虫获取的内容需要转化为beautifulsoup能解析的对象,传入response.content的对象即可
from bs4 import BeautifulSoup
soup1=BeautifulSoup('<html>data<html>','html.parser')#1.直接解析html
soup2=BeautifulSoup(open("D://demo.html"),'html.parser')#2.打开一个html文件
Beautiful Soup解析器

Beautiful Soup类的基本元素

如:soup.title
from bs4 import BeautifulSoup
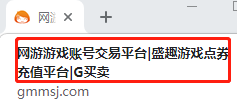
soup=BeautifulSoup(open(r"C:\Users\**\Desktop\gmm.html",'rb'),'html.parser')
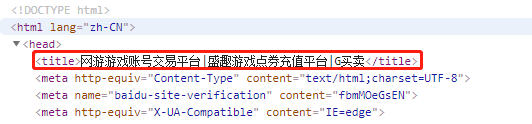
print(soup.title)#<title>网游游戏账号交易平台|盛趣游戏点券充值平台|G买卖</title>
soup.标签名
获得tag标签,如:meta
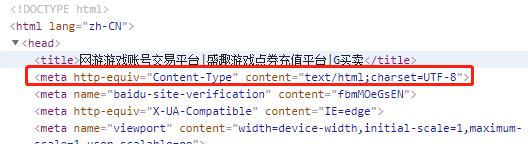
print(soup.meta)
#获得第一个meta标签内容:<meta content="text/html;charset=utf-8" http-equiv="Content-Type"/>
soup.标签名.attrs
查看第一个标签的属性,返回一个字典,可以查看对应key和value
print(soup.meta.attrs) #{'http-equiv': 'Content-Type', 'content': 'text/html;charset=UTF-8'}
print(soup.meta.attrs['content']) #text/html;charset=UTF-8
soup.标签名.string (NavigableString)
print(soup.p.string) #The demo python introduces several python courses.
print(type(soup.p.string))
#<class 'bs4.element.NavigableString'>
navigablestring能跨标签
如图垮了B标签

tag.text,tag.get_text()
如果只想得到tag中包含的文本内容,那么可以调用 get_text() 方法,这个方法获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回:
tag.text也可以使用
返回标签下所有的文本内容,
Comment
comment!并不会输出,因此需要对string的类型进行分析,判断是否为comment
soup2=BeautifulSoup("<b><!--This is a comment --></b><p>This is not a comment</p>","html.parser")
print(soup2.b.string) #This is a comment
print(type(soup2.b.string)) #<class 'bs4.element.Comment'>
基于bs4库的HTML内容遍历方法
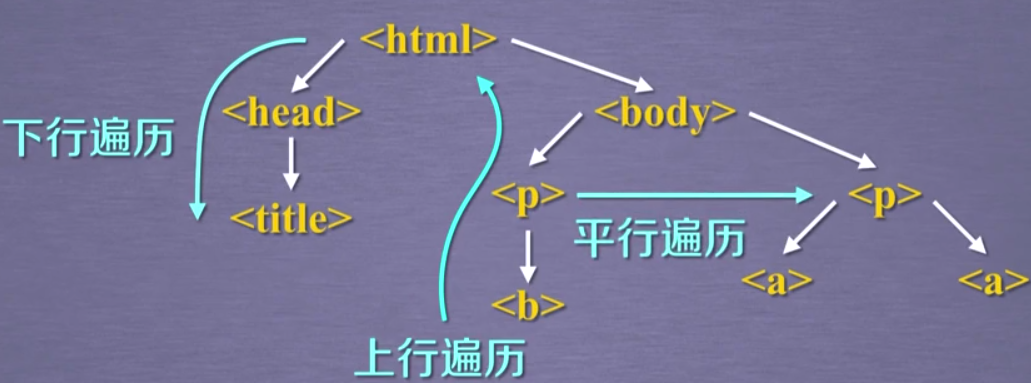
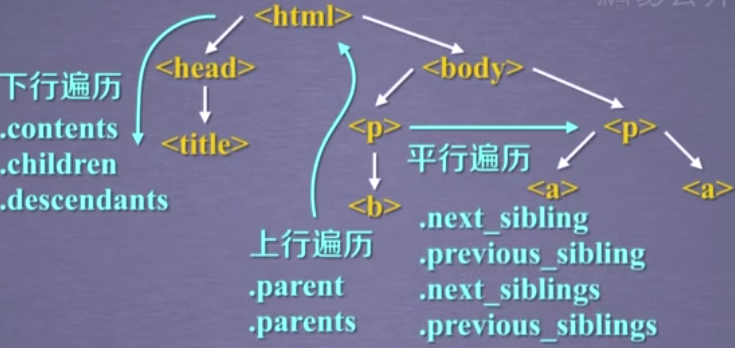
标签树的下行遍历
这里 .contents .children .descendants 前面的标签是<>中的标签名(如head)
也就是soup.标签名,返回的带有属性标签(如<title>The Dormouse's story</title>)
因此在实际应用中可以通过soup.find('标签名').children进行迭代生成


1.soup.标签.contents
返回一个列表
print('---head标签---')
print(soup.head)
print('---head.contents---')
print(soup.head.contents)#返回一个列表 [<title>This is a python demo page</title>]
print('---body.contents--')
print(soup.body.contents)
2.通过标签的 .children 生成器,可以对tag的子节点进行循环:
通过for循环对.children 进行遍历print("---body.children---")
print("---body.children---")
for child in soup.body.children:
print(child)
#因为列表内有换行符因此之间留空
"""
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
"""
3..descendants 属性可以对所有tag的子孙节点进行递归循环
print('---body.descendants')
for i in soup.body.descendants:
print(i)
注意:在标签树中navigablestring也构成了标签树的节点
标签树的上行遍历


标签树的平行遍历
同一个父节点下才能进行平行遍历
这里平行遍历返回的对象类型为NavigableString
In [24]: for i in soup.meta.previous_siblings:
...: print(type(i))
...:
<class 'bs4.element.NavigableString'>
print('----平行标签------')
print('-------下一个标签---------')
print(soup.a.next_sibling) # and
print(soup.a.next_sibling.next_sibling) #<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
print('----前一个标签--------')
print(soup.a.previous_sibling)#Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
print(soup.a.previous_sibling.previous_sibling) #None
print('-------遍历后续节点-------')
for slibing in soup.a.next_siblings:
print(slibing)
print('-------遍历前续节点-------')
for slibing2 in soup.a.previous_siblings:
print(slibing2)
"""
-------遍历后续节点-------
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
.
-------遍历前续节点-------
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses"
"""
总结:
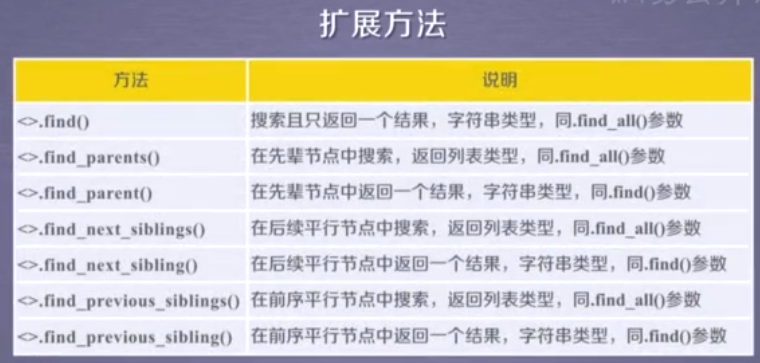
基于bs4的内容查找方法
<>.find_all(name,attrs,recursive,string,**kwargs).
返回一个列表类型,存储查找的结果
name:对标签名称的检索字符串
注意:搜索 name 参数的值可以使任一类型的 过滤器 ,字符窜,正则表达式,列表,方法或是 True ;
应用:

1.找到所有a标签内容(str)
In [5]: soup.find_all('a')
Out[5]:
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>,
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
2.将所有要找的标签作为列表传入(list)
找到所有a、b标签内容
In [8]: soup.find_all(['a','b'])
Out[8]:
[<b>The demo python introduces several python courses.</b>,
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>,
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
3.True查找符合条件的所有标签
#所有有id属性的标签
In [10]: soup.find_all(id=True) Out[10]: [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
#打印所有标签名
In [19]: for i in soup.find_all(True): ...: print(i.name) ...: html head title body p b p a a
4.使用正则表达式查找包含某字符的所有标签名
In [24]: for i in soup.find_all(re.compile('b')):
...: print(i.name)
...:
body
b
attrs:对标签属性值得检索字符串,可标注属性检索
应用:
千万不好搞错soup.find('标签名',"属性key")无此用法但是可以soup.find('标签名'['属性key'])
soup.find_all('标签名','属性value')
soup.find_all(属性key="属性value")
soup.find_all(属性key=re.compile('属性value内容部分需要查找内容'))
1.查找p标签中包含course字符串的
In [25]: soup.find_all('p','course')
Out[25]:
[<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>]
2.直接查找属性对应元素
In [26]: soup.find_all(id='link1') Out[26]: [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>]
#属性赋值查找不存在时
In [27]: soup.find_all(id='link')
Out[27]: []
3.使用正则表达式,进行属性查找
In [28]: soup.find_all(id=re.compile('link'))
Out[28]:
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>,
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
recursive:是否对子孙全部检索,默认True(默认全部检索)
应用
In [29]: soup.find_all('a')
Out[29]:
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>,
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
In [30]: soup.find_all('a',recursive=False)
Out[30]: [] soup根节点没有,a标签在之后的子孙节点中
string:<>....</>中字符串区域的检索字符串
应用
In [33]: soup.find_all(string='Basic Python') Out[33]: ['Basic Python']
#正则表达式,string
Out[34]:
['This is a python demo page',
'The demo python introduces several python courses.']
便捷用法
<tag>(..) 等价于 <tag>.find_all(..)
soup(..) 等价于 soup.find_all(..)
#a属性
In [35]: soup('a') == soup.find_all('a') Out[35]: [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
扩展方法:
select的用法:select(某选择器(标签,attrskey,attrsvalue)),返回符合要求的标签
CSS选择器 对应soup.select()在源代码中的原型为:
select(self, selector, namespaces=None, limit=None,**kwargs)
Beautiful Soup支持大部分的CSS选择器 http://www.w3.org/TR/CSS2/selector.html [6] , 在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数, 即可使用CSS选择器的语法找到tag:
soup.select("title") # [<title>The Dormouse's story</title>] soup.select("p:nth-of-type(3)") # [<p class="story">...</p>]
通过tag标签逐层查找:
soup.select("body a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("html head title") # [<title>The Dormouse's story</title>]
找到某个tag标签下的直接子标签 [6] :
soup.select("head > title") # [<title>The Dormouse's story</title>] soup.select("p > a") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("p > a:nth-of-type(2)") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>] soup.select("p > #link1") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] soup.select("body > a") # []
找到兄弟节点标签:
soup.select("#link1 ~ .sister") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("#link1 + .sister") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
通过CSS的类名查找:
soup.select(".sister") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.select("[class~=sister]") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
通过tag的id查找:
soup.select("#link1") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] soup.select("a#link2") # [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
同时用多种CSS选择器查询元素:
soup.select("#link1,#link2") # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
通过是否存在某个属性来查找:
soup.select('a[href]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
通过属性的值来查找:
soup.select('a[href="http://example.com/elsie"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
soup.select('a[href^="http://example.com/"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select('a[href$="tillie"]') # [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select('a[href*=".com/el"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
通过语言设置来查找:
multilingual_markup = """ <p lang="en">Hello</p> <p lang="en-us">Howdy, y'all</p> <p lang="en-gb">Pip-pip, old fruit</p> <p lang="fr">Bonjour mes amis</p> """ multilingual_soup = BeautifulSoup(multilingual_markup) multilingual_soup.select('p[lang|=en]') # [<p lang="en">Hello</p>, # <p lang="en-us">Howdy, y'all</p>, # <p lang="en-gb">Pip-pip, old fruit</p>]
返回查找到的元素的第一个
soup.select_one(".sister") # <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
对于熟悉CSS选择器语法的人来说这是个非常方便的方法.Beautiful Soup也支持CSS选择器API, 如果你仅仅需要CSS选择器的功能,那么直接使用 lxml 也可以, 而且速度更快,支持更多的CSS选择器语法,但Beautiful Soup整合了CSS选择器的语法和自身方便使用API.
select('某种选择器(id,class,标签.....选择器)'),返回一个列表
层级选择器:
--soup.select('.tang>ul>li>a')表示一个层级
--soup.select('.tang>ul a')表示多个层级层级
获取标签之间的文本数据
--soup.a.text/string/get_text()
--text/get_text():可以获取某一个标签中所有的文本内容
--string:只可以获取该标签下面直系的文本内容
--获取标签中属性值:
--soup.a['href']
可能存在的问题:
tag.string返回None值
原因可能一:
发现.string方法在tag包含多个子节点时,tag无法确定,则.string方法不知道该调用哪个tag,所以输出None。(用 .string 属性来提取标签里的内容时,该标签应该是只有单个节点的。比如 <td>1</td> 标签那样。)
解决:
.text可以输出多节点内的全部字符串
原因可能二:
可能检索的attrs或tag内容有误,或者由于多个attrs未能成功返回
重新调整调试对应attrs和tag
原因可能三:
解析器有问题,‘html.parser’
pycharm中使用lxml解析器时容易出错
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
1, easy_install html5lib
2, pip install html5lib
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,
如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
解析器
使用方法
优势
劣势
Python标准库
BeautifulSoup(markup, “html.parser”)
Python的内置标准库
执行速度适中
文档容错能力强
Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差
lxml HTML 解析器
BeautifulSoup(markup, “lxml”)
速度快
文档容错能力强
需要安装C语言库
lxml XML 解析器
BeautifulSoup(markup, [“lxml”, “xml”])
BeautifulSoup(markup, “xml”)
速度快
唯一支持XML的解析器
需要安装C语言库
html5lib
BeautifulSoup(markup, “html5lib”)
最好的容错性
以浏览器的方式解析文档
生成HTML5格式的文档
速度慢
不依
