
论文阅读笔记02-rcnn
最近跟着导师做 anchor-free的detection,看paper时总感觉对detecction的细节了解不够,于是再次阅读rcnn系列paper。其实之前也断断续续读过这几篇文章,不过了解不够深入,这次打算认真梳理一次。记录总结。
1. RCNN
流程
RCNN算法分为4个步骤
- 生成候选区域:一张图像生成1K~2K个候选区域
- 提取特征:对每个候选区域,使用深度网络提取特征
- 分类:特征送入每一类的SVM 分类器,判别是否属于该类
- 边框回归:使用回归器精细修正候选框位置
下面依次介绍上述四个过程:
####### 1. 生成候选区域
使用Selective Search算法生成候选区域,这一算法不详细讲解,由于生成候选区域过程与后续过程相互独立,可以使用任意算法完成。
####### 2.提取特征
预处理:使用深度网络提取特征之前,首先把候选区域归一化成同一尺寸227×227。
训练时分预训练和调优训练两个阶段
预训练:
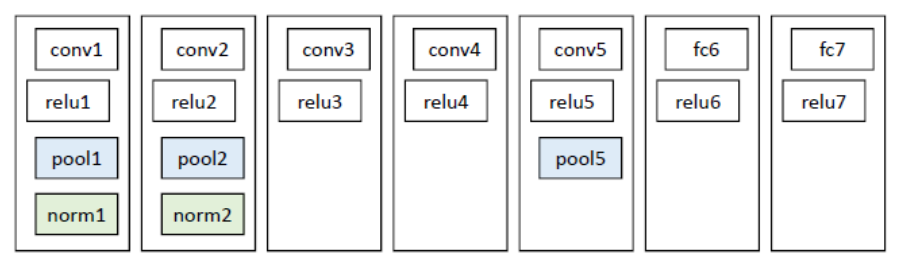
网络结构:此网络提取的特征为4096维,之后送入一个4096->1000的全连接(fc)层进行分类。
训练数据 :使用ILVCR 2012的全部数据进行训练,输入一张图片,输出1000维的类别标号。
调优训练:
网络结构 :同样使用上述网络,最后一层换成4096->21的全连接网络。
训练数据 :使用PASCAL VOC 2007的训练集,输入一张图片,输出21维的类别标号,表示20类+背景。
关于背景和前景的划分:
考察一个候选框和当前图像上所有标定框重叠面积最大的一个。如果重叠比例大于0.5,则认为此候选框为此标定的类别;否则认为此候选框为背景。
####### 3.分类
对每一类目标,使用一个线性SVM二类分类器进行判别。输入为深度网络输出的4096维特征,输出是否属于此类。
由于负样本很多,使用hard negative mining方法。
正样本 :本类的真值标定框。
负样本 :考察每一个候选框,如果和本类所有标定框的重叠都小于0.3,认定其为负样本
####### 4.边框回归
目标检测问题的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要一个位置精修步骤。
位置精修时使用回归器完成:
对每一类目标,使用一个线性脊回归器进行精修。正则项λ=10000λ=10000。
输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。
训练样本
判定为本类的候选框中,和真值重叠面积大于0.6的候选框。
补充:下面介绍一下边框回归(bounding box regression)的原理
对于窗口一般使用四维向量(x,y,w,h)来表示,分别表示窗口的中心点坐标和宽高。Bounding Box Regression的目标是找到一种映射f, 使得初始Bounding Box经过映射后,尽量接近 ground truth。
回归网络的输入:真正的输入是这个窗口对应的 CNN 特征,也就是 R-CNN 中的 Pool5 feature(特征向量)

本文仅作为个人学习时笔记使用,内容大量引用自下面几篇博客:
RCNN
bounding box Regression

 浙公网安备 33010602011771号
浙公网安备 33010602011771号