基于Flume的美团日志收集系统(二)改进和优化
问题导读:
1.Flume的存在些什么问题?
2.基于开源的Flume美团增加了哪些功能?
3.Flume系统如何调优?
在《基于Flume的美团日志收集系统(一)架构和设计》中,我们详述了基于Flume的美团日志收集系统的架构设计,以及为什么做这样的设计。在本节中,我们将会讲述在实际部署和使用过程中遇到的问题,对Flume的功能改进和对系统做的优化。
1 Flume的问题总结
在Flume的使用过程中,遇到的主要问题如下:
a. Channel“水土不服”:使用固定大小的MemoryChannel在日志高峰时常报队列大小不够的异常;使用FileChannel又导致IO繁忙的问题;
b. HdfsSink的性能问题:使用HdfsSink向Hdfs写日志,在高峰时间速度较慢;
c. 系统的管理问题:配置升级,模块重启等;
2 Flume的功能改进和优化点
从上面的问题中可以看到,有一些需求是原生Flume无法满足的,因此,基于开源的Flume我们增加了许多功能,修改了一些Bug,并且进行一些调优。下面将对一些主要的方面做一些说明。
2.1 增加Zabbix monitor服务
一方面,Flume本身提供了http, ganglia的监控服务,而我们目前主要使用zabbix做监控。因此,我们为Flume添加了zabbix监控模块,和sa的监控服务无缝融合。
另一方面,净化Flume的metrics。只将我们需要的metrics发送给zabbix,避免 zabbix server造成压力。目前我们最为关心的是Flume能否及时把应用端发送过来的日志写到Hdfs上, 对应关注的metrics为:
- Source : 接收的event数和处理的event数
- Channel : Channel中拥堵的event数
-
Sink : 已经处理的event数
首先,我们的HdfsSink写到hadoop的文件采用lzo压缩存储。 HdfsSink可以读取hadoop配置文件中提供的编码类列表,然后通过配置的方式获取使用何种压缩编码,我们目前使用lzo压缩数据。采用lzo压缩而非bz2压缩,是基于以下测试数据:
其次,我们的HdfsSink增加了创建lzo文件后自动创建index功能。Hadoop提供了对lzo创建索引,使得压缩文件是可切分的,这样
Hadoop
Job可以并行处理数据文件。HdfsSink本身lzo压缩,但写完lzo文件并不会建索引,我们在close文件之后添加了建索引功能。
2.3 增加HdfsSink的开关
我们在HdfsSink和DualChannel中增加开关,当开关打开的情况下,HdfsSink不再往Hdfs上写数据,并且数据只写向DualChannel中的FileChannel。以此策略来防止Hdfs的正常停机维护。
2.4 增加DualChannel
Flume本身提供了MemoryChannel和FileChannel。MemoryChannel处理速度快,但缓存大小有限,且没有持久
化;FileChannel则刚好相反。我们希望利用两者的优势,在Sink处理速度够快,Channel没有缓存过多日志的时候,就使用
MemoryChannel,当Sink处理速度跟不上,又需要Channel能够缓存下应用端发送过来的日志时,就使用FileChannel,由此我
们开发了DualChannel,能够智能的在两个Channel之间切换。
其具体的逻辑如下:
2.5 增加NullChannel
Flume提供了NullSink,可以把不需要的日志通过NullSink直接丢弃,不进行存储。然而,Source需要先将events存放到
Channel中,NullSink再将events取出扔掉。为了提升性能,我们把这一步移到了Channel里面做,所以开发了
NullChannel。
2.6 增加KafkaSink
为支持向Storm提供实时数据流,我们增加了KafkaSink用来向Kafka写实时数据流。其基本的逻辑如下:
2.7 修复和scribe的兼容问题
Scribed在通过ScribeSource发送数据包给Flume时,大于4096字节的包,会先发送一个Dummy包检查服务器的反应,而
Flume的ScribeSource对于logentry.size()=0的包返回TRY_LATER,此时Scribed就认为出错,断开连接。这
样循环反复尝试,无法真正发送数据。现在在ScribeSource的Thrift接口中,对size为0的情况返回OK,保证后续正常发送数据。
3. Flume系统调优经验总结3.1
基础参数调优经验
-
HdfsSink中默认的serializer会每写一行在行尾添加一个换行符,我们日志本身带有换行符,这样会导致每条日志后面多一个空行,修改配置不要自动添加换行符;
-
调大MemoryChannel的capacity,尽量利用MemoryChannel快速的处理能力;
-
调大HdfsSink的batchSize,增加吞吐量,减少hdfs的flush次数;
-
适当调大HdfsSink的callTimeout,避免不必要的超时错误;
HdfsSink的path参数指明了日志被写到Hdfs的位置,该参数中可以引用格式化的参数,将日志写到一个动态的目录中。这方便了日志的管理。例如我们可以将日志写到category分类的目录,并且按天和按小时存放:
HdfsS ink中处理每条event时,都要根据配置获取此event应该写入的Hdfs
path和filename,默认的获取方法是通过正则表达式替换配置中的变量,获取真实的path和filename。因为此过程是每条event都要
做的操作,耗时很长。通过我们的测试,20万条日志,这个操作要耗时6-8s左右。
由于我们目前的path和filename有固定的模式,可以通过字符串拼接获得。而后者比正则匹配快几十倍。拼接定符串的方式,20万条日志的操作只需要几百毫秒。
3.3 HdfsSink的b/m/s优化
在我们初始的设计中,所有的日志都通过一个Channel和一个HdfsSink写到Hdfs上。我们来看一看这样做有什么问题。
首先,我们来看一下HdfsSink在发送数据的逻辑:
假设我们的系统中有100个category,batchSize大小设置为20万。则每20万条数据,就需要对100个文件进行append或者flush操作。
其次,对于我们的日志来说,基本符合80/20原则。即20%的category产生了系统80%的日志量。这样对大部分日志来说,每20万条可能只包含几条日志,也需要往Hdfs上flush一次。
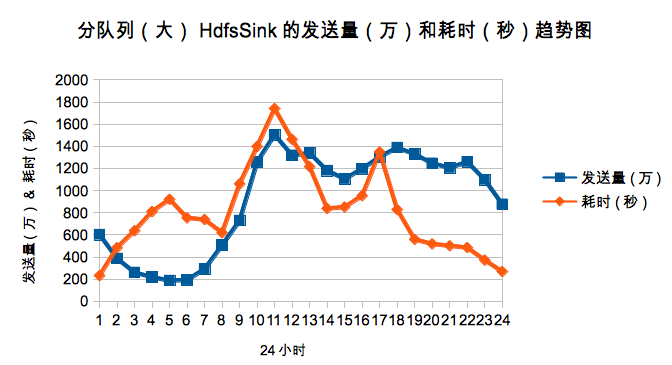
上述的情况会导致HdfsSink写Hdfs的效率极差。下图是单Channel的情况下每小时的发送量和写hdfs的时间趋势图。

鉴于这种实际应用场景,我们把日志进行了大小归类,分为big, middle和small三类,这样可以有效的避免小日志跟着大日志一起频繁的flush,提升效果明显。下图是分队列后big队列的每小时的发送量和写hdfs的时间趋势图。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号