大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
个人观点:大数据我们都知道hadoop,但并不都是hadoop.我们该如何构建大数据库项目。对于离线处理,hadoop还是比较适合的,但是对于实 时性比较强的,数据量比较大的,我们可以采用Storm,那么Storm和什么技术搭配,才能够做一个适合自己的项目。下面给大家可以参考。
可以带着下面问题来阅读本文章:
1.一个好的项目架构应该具备什么特点?
2.本项目架构是如何保证数据准确性的?
3.什么是Kafka?
4.flume+kafka如何整合?
5.使用什么脚本可以查看flume有没有往Kafka传输数据
做软件开发的都知道模块化思想,这样设计的原因有两方面:
一方面是可以模块化,功能划分更加清晰,从“数据采集--数据接入--流失计算--数据输出/存储”

1).数据采集
负责从各节点上实时采集数据,选用cloudera的flume来实现
2).数据接入
由于采集数据的速度和数据处理的速度不一定同步,因此添加一个消息中间件来作为缓冲,选用apache的kafka
3).流式计算
对采集到的数据进行实时分析,选用apache的storm
4).数据输出
对分析后的结果持久化,暂定用mysql
另一方面是模块化之后,假如当Storm挂掉了之后,数据采集和数据接入还是继续在跑着,数据不会丢失,storm起来之后可以继续进行流式计算;
那么接下来我们来看下整体的架构图
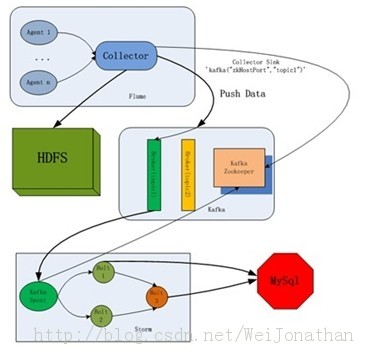
详细介绍各个组件及安装配置:
操作系统:ubuntu
Flume
Flume是Cloudera提供的一个分布式、可靠、和高可用的海量日志采集、聚合和传输的日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
下图为flume典型的体系结构:
Flume数据源以及输出方式:
Flume
提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX
tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力,在我们的系统中目前
使用exec方式进行日志采集。
Flume的数据接受方,可以是console(控制台)、text(文件)、dfs(HDFS文件)、RPC(Thrift-RPC)和syslogTCP(TCP syslog日志系统)等。在我们系统中由kafka来接收。
Flume下载及文档:
http://flume.apache.org/
Flume安装:
- $tar zxvf apache-flume-1.4.0-bin.tar.gz/usr/local
- $bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name producer -Dflume.root.logger=INFO,console
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
- 支持通过kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
kafka的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数
据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。
这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。
对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过Hadoop的并行加载机
制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
kafka分布式订阅架构如下图:--取自Kafka官网
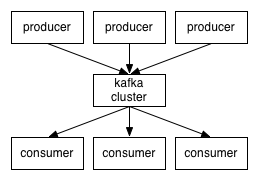
罗宝兄弟文章上的架构图是这样的
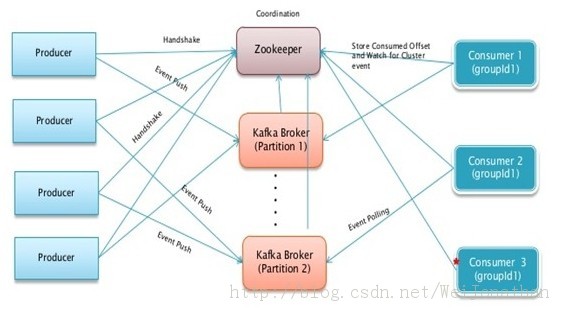
其实两者没有太大区别,官网的架构图只是把Kafka简洁的表示成一个Kafka Cluster,而上面架构图就相对详细一些;
Kafka版本:0.8.0
Kafka下载及文档:http://kafka.apache.org/
Kafka安装:
- > tar xzf kafka-<VERSION>.tgz
- > cd kafka-<VERSION>
- > ./sbt update
- > ./sbt package
- > ./sbt assembly-package-dependency
启动及测试命令:
(1) start server
- > bin/zookeeper-server-start.shconfig/zookeeper.properties
- > bin/kafka-server-start.shconfig/server.properties
配置独立的zookeeper集群需要配置server.properties文件,讲zookeeper.connect修改为独立集群的IP和端口
- zookeeper.connect=nutch1:2181
- > bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 1 --partition 1 --topic test
- > bin/kafka-list-topic.sh --zookeeperlocalhost:2181
- > bin/kafka-console-producer.sh--broker-list localhost:9092 --topic test
- > bin/kafka-console-consumer.sh--zookeeper localhost:2181 --topic test --from-beginning
kafka-console-producer.sh和kafka-console-cousumer.sh只是系统提供的命令行工具。这里启动是为了测试是否能正常生产消费;验证流程正确性
在实际开发中还是要自行开发自己的生产者与消费者;
kafka的安装也可以参考我之前写的文章:http://blog.csdn.net/weijonathan/article/details/18075967
Storm
Twitter
将Storm正式开源了,这是一个分布式的、容错的实时计算系统,它被托管在GitHub上,遵循 Eclipse Public License
1.0。Storm是由BackType开发的实时处理系统,BackType现在已在Twitter麾下。GitHub上的最新版本是Storm
0.5.2,基本是用Clojure写的。
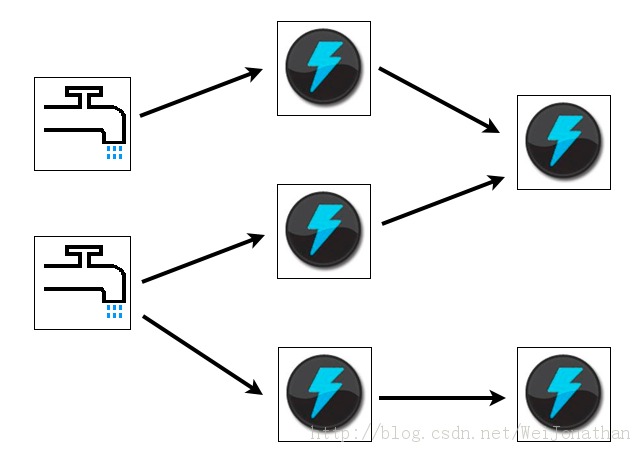
Storm的主要特点如下:
- 简单的编程模型。类似于MapReduce降低了并行批处理复杂性,Storm降低了进行实时处理的复杂性。
- 可以使用各种编程语言。你可以在Storm之上使用各种编程语言。默认支持Clojure、Java、Ruby和Python。要增加对其他语言的支持,只需实现一个简单的Storm通信协议即可。
- 容错性。Storm会管理工作进程和节点的故障。
- 水平扩展。计算是在多个线程、进程和服务器之间并行进行的。
- 可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
- 快速。系统的设计保证了消息能得到快速的处理,使用ØMQ作为其底层消息队列。(0.9.0.1版本支持ØMQ和netty两种模式)
- 本地模式。Storm有一个“本地模式”,可以在处理过程中完全模拟Storm集群。这让你可以快速进行开发和单元测试。
由于篇幅问题,具体的安装步骤可以参考:Storm-0.9.0.1安装部署 指导
接下来重头戏开始拉!那就是框架之间的整合啦
flume和kafka整合
1.下载flume-kafka-plus:https://github.com/beyondj2ee/flumeng-kafka-plugin
2.提取插件中的flume-conf.properties文件
修改该文件:#source section
producer.sources.s.type = exec
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c
修改所有topic的值改为test
将改后的配置文件放进flume/conf目录下
在该项目中提取以下jar包放入环境中flume的lib下:
注:这里的flumeng-kafka-plugin.jar这个包,后面在github项目中已经移动到package目录了。找不到的童鞋可以到package目录获取。
完成上面的步骤之后,我们来测试下flume+kafka这个流程有没有走通;
我们先启动flume,然后再启动kafka,启动步骤按之前的步骤执行;接下来我们使用kafka的kafka-console-consumer.sh脚本查看是否有flume有没有往Kafka传输数据;
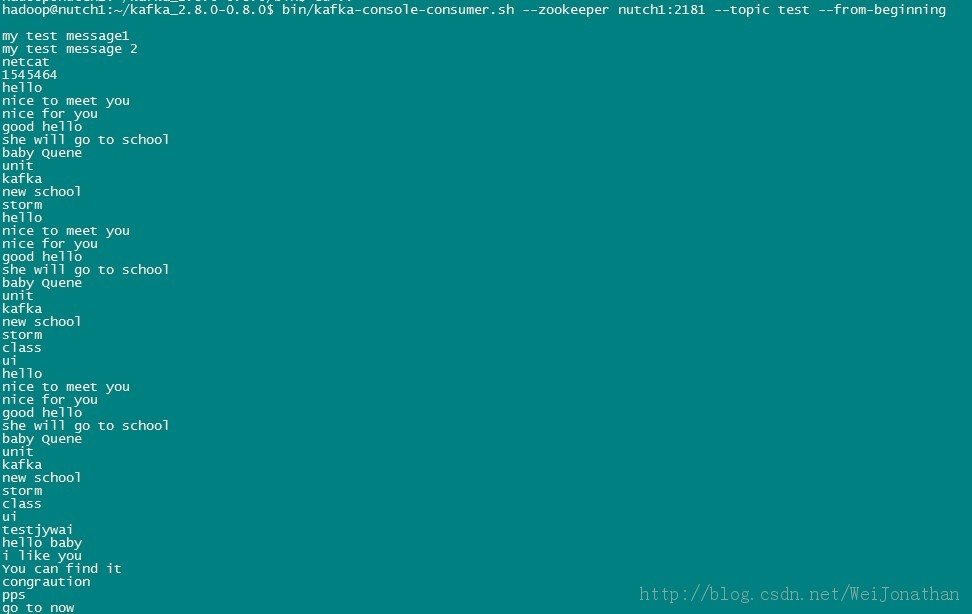
以上这个是我的test.log文件通过flume抓取传到kafka的数据;说明我们的flume和kafka流程走通了;
大家还记得刚开始我们的流程图么,其中有一步是通过flume到kafka,还有一步是到hdfs的;而我们这边还没有提到如何存入kafka且同时存如hdfs;
flume是支持数据同步复制,同步复制流程图如下,取自于flume官网,官网用户指南地址:http://flume.apache.org/FlumeUserGuide.html

怎么设置同步复制呢,看下面的配置:
- #2个channel和2个sink的配置文件 这里我们可以设置两个sink,一个是kafka的,一个是hdfs的;
- a1.sources = r1
- a1.sinks = k1 k2
- a1.channels = c1 c2
kafka和storm的整合
1.下载kafka-storm0.8插件:https://github.com/wurstmeister/storm-kafka-0.8-plus
2.使用maven package进行编译,得到storm-kafka-0.8-plus-0.3.0-SNAPSHOT.jar包 --有转载的童鞋注意下,这里的包名之前写错了,现在改正确了!不好意思!
3.将该jar包及kafka_2.9.2-0.8.0-beta1.jar、metrics-core-2.2.0.jar、scala-library-2.9.2.jar (这三个jar包在kafka项目中能找到)
备注:如果开发的项目需要其他jar,记得也要放进storm的Lib中比如用到了mysql就要添加mysql-connector-java-5.1.22-bin.jar到storm的lib下
那么接下来我们把storm也重启下;
完成以上步骤之后,我们还有一件事情要做,就是使用kafka-storm0.8插件,写一个自己的Storm程序;
这里我给大伙附上一个我弄的storm程序,百度网盘分享地址:链接: http://pan.baidu.com/s/1jGBp99W 密码: 9arq
先稍微看下程序的创建Topology代码

数据操作主要在WordCounter类中,这里只是使用简单JDBC进行插入处理

这里只需要输入一个参数作为Topology名称就可以了!我们这里使用本地模式,所以不输入参数,直接看流程是否走通;
- storm-0.9.0.1/bin/storm jar storm-start-demo-0.0.1-SNAPSHOT.jar com.storm.topology.MyTopology
先看下日志,这里打印出来了往数据库里面插入数据了
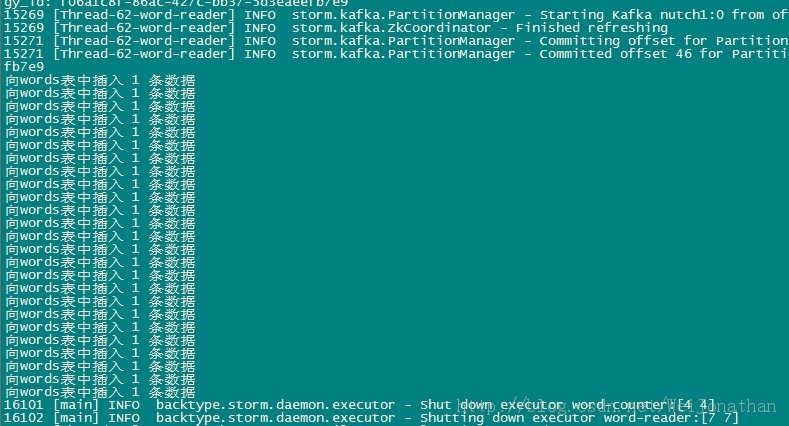
然后我们查看下数据库;插入成功了!
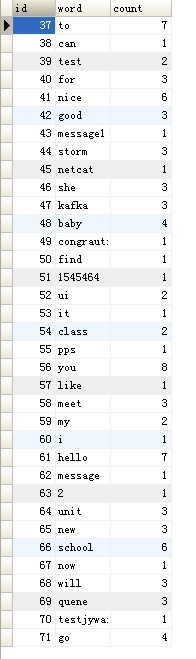
到这里我们的整个整合就完成了!
但是这里还有一个问题,不知道大伙有没有发现。
由于我们使用storm进行分布式流式计算,那么分布式最需要注意的是数据一致性以及避免脏数据的产生;所以我提供的测试项目只能用于测试,正式开发不能这样处理;
晨色星空J2EE(一个网名)给的建议是建立一个zookeeper的分布式全局锁,保证数据一致性,避免脏数据录入!
zookeeper客户端框架大伙可以使用Netflix Curator来完成,由于这块我还没去看,所以只能写到这里了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号