
【论文阅读】CAT: Cross Attention in Vision Transformer
来自快手(ฅ′ω`ฅ)
论文地址:[2106.05786] CAT: Cross Attention in Vision Transformer (arxiv.org)
项目地址:https://github.com/linhezheng19/CAT
一、Abstract
由于Transformer在NLP中得到了广泛的应用,Transformer在CV中的潜力得到了实现,并激发了许多新的方法。然而,在对图像进行标记化之后,用图像补丁替换Transformer的单词标记所需的计算量是巨大的(例如, ViT),这阻碍了模型训练和推理。本文在Transformer中提出了一种新的注意机制,称为交叉注意,它将注意力转移到图像块内部而不是整个图像以获取局部信息,并将注意力转移到由单通道特征图划分的图像块之间以获取全局信息。这两个操作的计算量都比Transformer中的标准自注意力要少。通过在patch内部和patch之间交替应用注意,实现了以较低的计算成本保持性能的交叉注意,并建立了用于其他视觉任务的分层网络,称为交叉注意转换器(CAT)。我们的基础模型在ImageNet-1K上达到了最先进的水平,并在COCO和ADE20K上提高了其他方法的性能,说明我们的网络具有作为通用骨干的潜力。
二、Motivation
1.历史遗留问题
在NLP任务中,文本的长度是固定的,在CV任务中,由于输入图像的分辨率是多样的,导致了Transformer处理图像能力的下降。在Transformer处理图像处理的过程中,一种原始的的方法是将输入图内的每个像素视作是全局关注的token,类似于工作token。一些工作已经证明这种方式的计算成本是巨大的。ViT等工作将一个区域内的一组像素视作为一个token,在一定程度上减少了计算量。但是当输入大小变大时,计算量会急剧增加,并且,这些方法生成的特征图尺寸是一致的,缺乏多尺度的信息,不利于下游任务(目标检测、语义分割等)的完成。
2.受到CNN的启发
CNN使用“滑动窗”的方式获取信息,受到这种局部特征提取能力的启发,我们采用在一个patch的所有像素中计算注意力来模拟CNN的这种特性,将计算量从随着输入大小呈指数增长减少到与patch大小呈指数相关。
三、Contribution
考虑到图像的整体信息提取和传播,我们设计了一种对单通道特征图进行注意的方法-交叉注意(Cross Attention)。交叉注意是通过交替对patch的内部注意和对单通道特征映射的注意来实现的。我们可以利用Cross Attention构建强大的骨干,生成不同尺度的特征图,满足下游任务不同粒度特征的需求,如图1所示。我们在不增加计算量或少量增加计算量的情况下引入全局关注,这是一种更合理的结合Transformer和CNN特征的方法。
Transformer和CNN的功能是相辅相成的,我们的长期目标是将它们更有效、更完美地结合起来,以充分利用两者的优势。我们提出的CAT就是朝这个方向迈出的一步,希望在这个方向上有更好的发展。

四、CAT
我们的方法旨在将斑块内的注意力和斑块之间的注意力结合起来,通过堆叠基本块构建一个分层网络,可以简单地应用于其他视觉任务。(结构是经典的PVT式的层叠结构,不提了。)
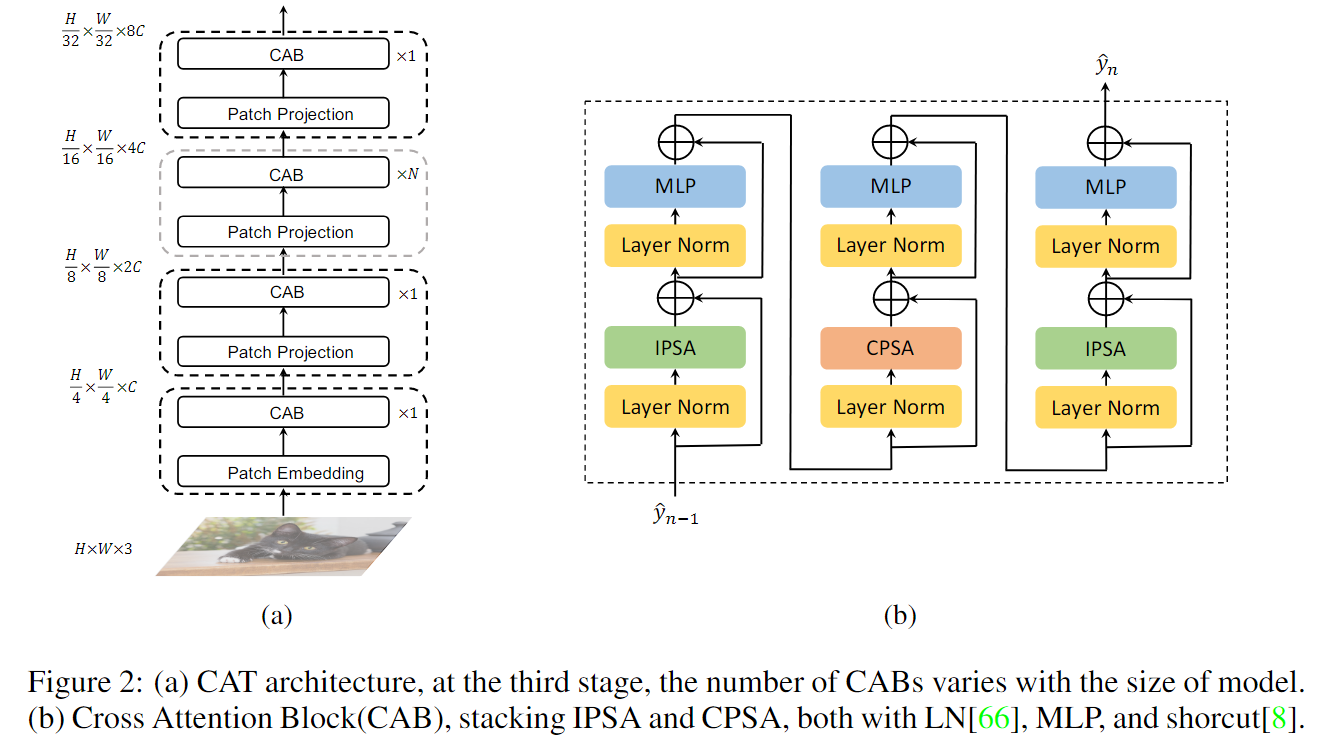
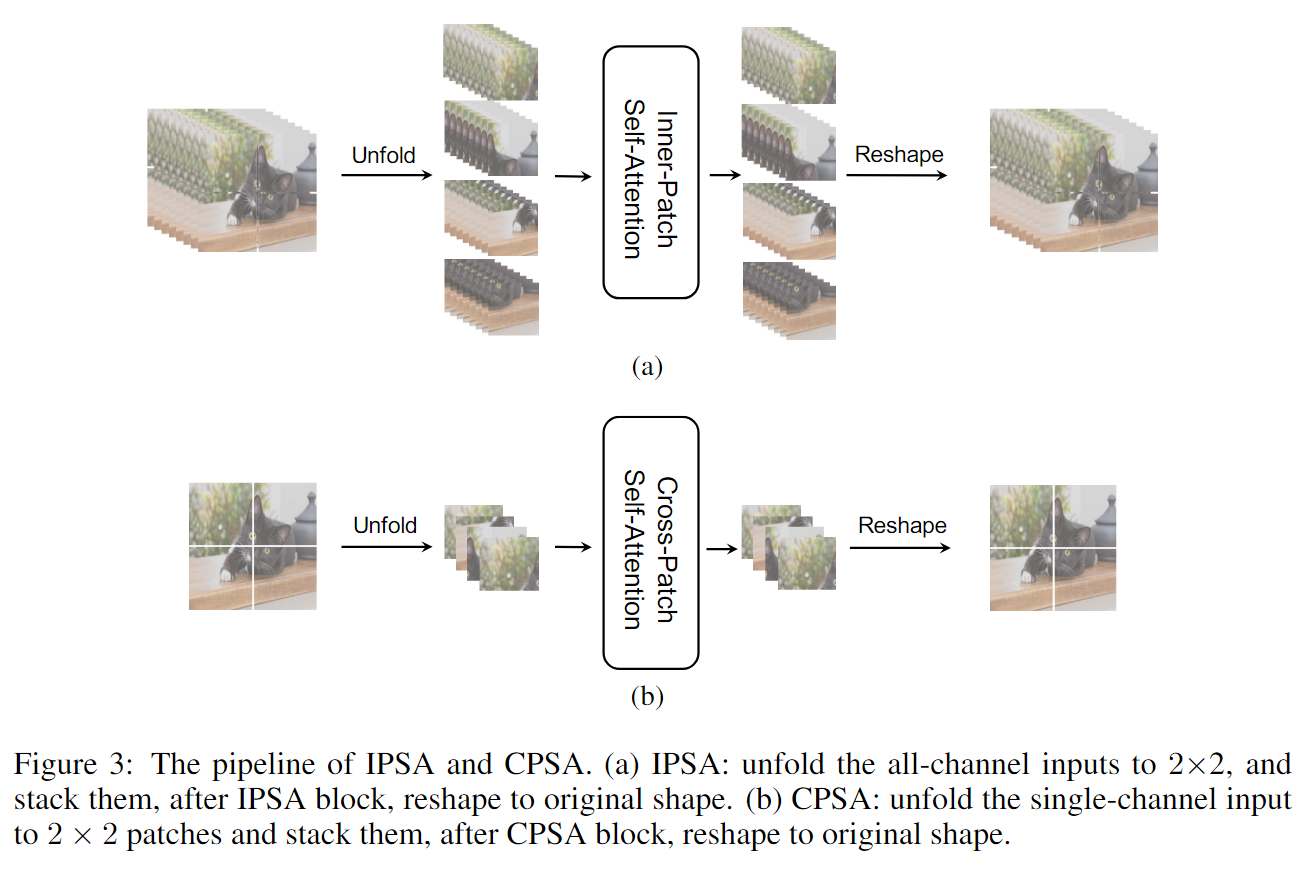
4.1 Inner-Patch Self-Attention Block
在计算机视觉中,每一个像素都需要一个特定的通道一个特定的通道来表示其不同的语义特征。理想的情况下,我们希望将每一个像素都视作一个token,但是计算量巨大,受到CNN局部特征提取特性的启发,我们将CNN的局部卷积方法引入到了Transformer中,在每个单独的patch中逐像素的计算self-attetion,就是文中的Inner-Patch Self-Attention (IPSA),我们把一个局部当作一个注意范围,而不是整个画面。同时,Transformer可以根据输入生成不同的注意图,这与固定参数的CNN相比具有明显的优势,类似于卷积方法中的动态参数。这和swin中的窗口自注意力相似。
4.2 Cross-Patch Self-Attention Block
像素间的自注意力机制仅仅是为了捕捉到一个patch内像素之间的相互关系,整个图片的信息交换也是非常关键的。在基于cnn的网络中,堆叠卷积核通常用于扩展接受域。对于更大的感受野,提出了空洞卷积,在实践中,最终的感受野扩展到整个图像。Transformer自然能够捕获全局信息,但像ViT和Deit这样的结构获取的特征图最终并不是最好的分辨率。
每个单通道的特征图同样具有全局信息,我们提出了Cross-Patch Self-Attention方法,将每个通道特征映射分离,并将每个通道划分为H/N × W/N个patches,利用自注意在整个特征映射中获取全局信息。这类似于Xception和MobileNet中使用的深度可分离卷积。
将IPSA块和CPSA块进行叠加,提取并整合一个patch中像素之间和一个feature map中patch之间的特征。Swin中手动设计的移位窗口,实现难度大,捕获全局信息的能力较弱,相比之下,我们的窗口更合理,更容易理解。
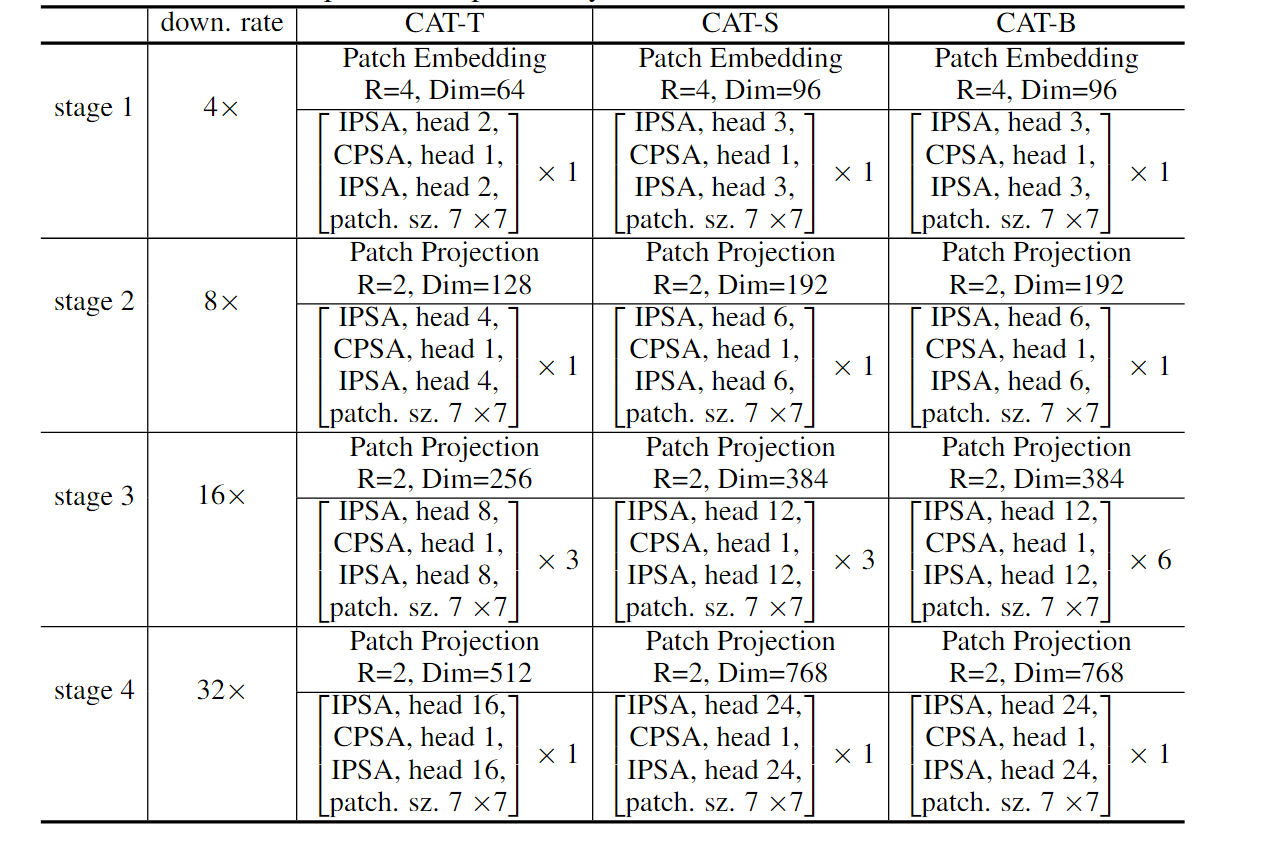
五、CAT变体
六、Conclusion
本文提出交叉注意,是为了更好地将CNN的局部特征提取的优点与Transformer的全局信息提取的优点结合起来,构建一个鲁棒的主干,即CAT。它可以像大多数基于cnn的网络一样生成不同尺度的特征,也可以适应其他视觉任务的不同大小的输入。
七、Thinking
CPSA的设计确实比SWIN好理解,代码实现也很容易,只是做了维度的转换。CAT的核心在于将SA替换为patch内的注意力计算和单通道特征图的注意力计算,在不增加计算成本的前提下更好的捕获局部和全局信息。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律