
【CVPR2022】CMT: Convolutional Neural Networks Meet Vision Transformers
来自华为(❤ ω ❤)
论文地址:[2107.06263] CMT: Convolutional Neural Networks Meet Vision Transformers (arxiv.org)
项目地址:https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/cmt_pytorch
一、Motivation
1.尽管ViT已经广泛的应用于图像识别任务,但是ViT的性能和计算成本与现有的CNN还存在着一定的差距,例如类似规模的EfficientNet,作者认为原因有三个方面:
- 经典的ViT和大多数基于ViT的模型,通常将输入的图像划分为不同大小的图像补丁(patch),补丁序列被输入到标准的ViT中,捕捉补丁之间的长距离依赖关系,然而这样做忽略了补丁内的2D结构和空间局部信息;
- 对于固定的补丁大小(16×16),ViT很难明确的提取出低分辨率和多尺度特征;
- 计算成本:卷积神经网络的计算成本为(ON²C),而ViT的自注意力的计算成本为(ONC²),对于高分辨率的输入来说,ViT的计算压力比较大。
2.开发一个不仅优于经典的ViT,而且性能优于现有的卷积神经网络的模型
二、Contribution
建立了一个混合网络,该网络结合了传统的CNN和Transformer,以多层次的Transformer为基础,在网络的层与层之间插入传统卷积,通过卷积+全局注意力的方式层次化提取图像局部和全局特征。
三、CMT
3.1 Convolution Stem
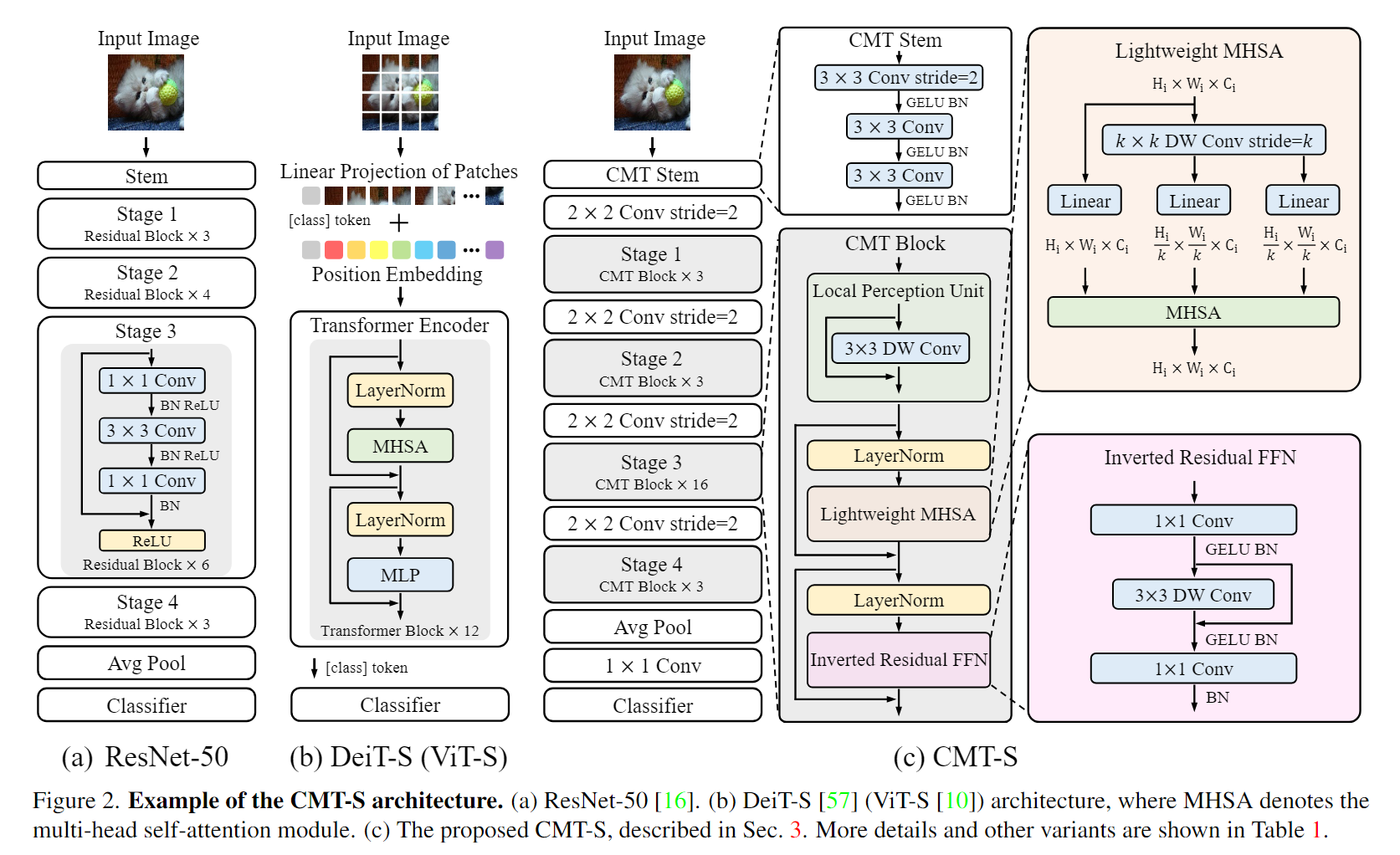
在Figure2(b)中展示了ViT-S的架构,图片被分成一系列的不重叠的图像补丁,这种做法直接失去了patch中的2D空间特征以及很多细节和边缘等信息,虽然可以进行补丁间的长距离建模,但是补丁内部的信息只能通过线性映射来表达,建模效果较差。为了克服这个限制,CVT使用Stem架构,该架构利用多个3x3卷积堆叠而成的结构来达到下采样及提取细节特征的目的。首先通过一个3×3,步长为2的卷积来降低输入图像的大小,借着使用另外3×3,步长为1的卷积来更好的提取局部信息。遵循了CNN的结构,CMT有四个阶段来生成不同尺寸的特征图,在每个阶段之前,应用一个由卷积层和归一化层组成的Patch Embedding层来减少特征图的尺寸并将其投影到更高的维度,产生层级的结构。
3.2 CMT Block
CMT Block由三部分组成,分别是局部感知单元(LPU),轻量化的多头自注意力模块(LMHSA)和反向残差前馈网络(ITFFN)组成。
3.2.1 局部感知单元
去看条件位置编码,写过了不重复了o(* ̄▽ ̄*)ブ
3.2.2 轻量化的多头自注意力模块(LMHSA)
在进行MHSA前,对K和V进行了k×k的步长为k的DW卷积来减小序列长度,减少参数量,常规操作不推导了。
3.2.3 反向残差前馈网络(ITFFN)
ViT中提出的原始FFN由两个线性层组成,由GELU激活隔开。第一层将维度扩大了4倍,第二层将维度缩小了四倍。
反向残差前馈网络(IRFFN)与反向残差块(MobileNetV2)相似,由扩展层、深度卷积和投影层组成。具体来说,CMT改变快捷连接的位置以获得更好的性能。全程并没有采用CLS token,直接最后一个stage的结果进行平均池化和1×1的卷积,利用FC层进行分类。
所以,整体的模型结构就一目了然了,假设输入为 224x224x3, 经过 CMT-STEM 和第一次下采样后,得到了一个 56x56 的 featuremap,然后进入 stage1,输出不变,经过下采样后,输入为 28x28,进入 stage2,输出后经过下采样,输入为 14x14,进入 stage3,输出后经过最后的下采样,输入为 7x7,进入 stage4,最后输出 7x7 的特征图,后面接 avgpool 和分类,达到分类的效果。
四、Thingking
没啥新意,代码解读稍后再写


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律