【论文阅读】CONDITIONAL POSITIONAL ENCODINGS FOR VISIONTRANSFORMERS
来自美团技术团队2023年ICLR会议上发表的论文
论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2102.10882.pdf
一、Motivation
由于Transformer中的Self-Attention操作是Permutation-Invariant的,也就是说,对于同一个序列,任意顺序进行排列,Self-Attention得到的一样的结果。关于置换不变性的推导如下:

这种置换不变性显然不是我们所期望的,为了打破这种性质,不难看出,我们需要为每个位置赋予一个独特的标志,这样当求和过程中各个item的位置发生变化后,其对应的item的值也会发生变化,从而打破了这种排列不变性。 这个独特的标志即为Positional Encodings。
Positional Encodings的重要性:
由于self-attention的permutation-invariant使得transformer需要一个特殊的positional encodings来显式地引入sequence中tokens的位置信息,因为无论是文本还是图像sequence,位置信息都是非常重要的。论文中以DeiT-tiny为实验模型,分别采用no positional encodings,learnable absolute positional encodings,fixed sin-cos positional encodings以及relative postional encodings等,不同的策略在ImageNet下的效果如下表所示:
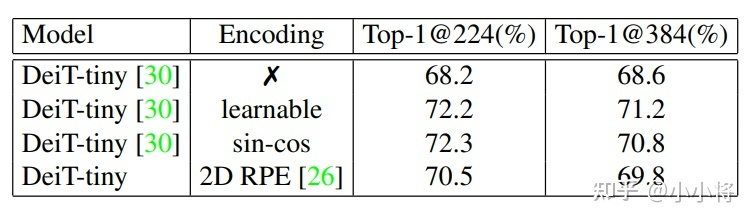
主要结论如下:
- positional encodings对模型性能比较关键,不采用任何PE效果最差;
- relative postional encodings相比absolute positional encodings效果稍差,绝对位置编码比较重要;
- 用显式的PE,当图像分辨率提升时直接对PE插值处理,性能会下降;
目前的位置编码分为两种类型:
- Fixed Positional Encodings:将各个位置设置为固定值,例如ViT中的绝对位置编码,就是固定位置编码
- Learnable Positional Encoding:即训练开始时,初始化一个和输入token数目一致的tensor,这个tensor会在训练过程中逐步更新。
但是,以上的编码方式都存在一些问题:
- 位置编码的长度是固定的,如果在测试过程中,遇到了更大尺寸的输入序列,通常的解决方式是通过插值进行上采样来改变序列的长度,在没有fine-tune的情况下,这种方式会影响模型的效果
- 对于视觉任务来说,我们期待的模型是平移等变的,但是加上了位置编码后,模型不再具有平移等变性
- 即使是相对位置编码,一方面引入了额外的计算量,另一方面,需要对原始的ViT进行修改。并且对于分类任务而言,相对位置编码无法提供绝对位置信息,会干扰分类效果
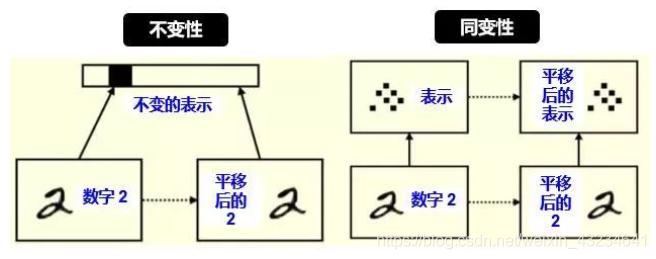
在这里,顺便解释一下平移不变性和平移等变性,Translation Invariance和Translation Equivariance
- 平移不变性(Translation Invariance):在图像分类任务中,不变性意味着,当所需要识别的目标出现在图像的不同位置时,模型对其识别所得到的标签应该相同。即当输出进行变换后,还能得到相同的输出。
- 平移等变性(Translation Equivariance):例如在目标检测任务中,如果输入的图像中,对应的目标发生了平移,那么最终检测出的候选框也应发生相应的变化。即对输入进行变换后,输出也会发生相应的变换。
二、Method
这篇文章为 ViT 提出了条件位置编码 (CPE) 方案。与以前的固定或可学习的位置编码不同,它们是预先定义的并且独立于输入标记,CPE 是动态生成的,并且以输入标记的本地邻域为条件。因此,CPE 可以很容易地泛化到比模型在训练期间看到的更长的输入序列。此外,CPE 可以在图像分类任务中保持所需的平移不变性,从而提高分类精度。
一个理想的、对视觉任务有效的positional encoding应该满足以下条件:
- 使得网络具有Permutation-Variant,但是具有Translation-Invariant
- 具有较强的归纳能力,能够处理不同长度的序列
- 具有一定的提供绝对位置的能力
利用局部关系的构建的Positional Encoding即可满足以上要求,为什么呢,论文没有仔细写,我认为有以下原因:
- 首先,这是一个置换变量,当输入序列发生了变化,那么也会影响某些局部邻域的顺序
- 当图像中物体的位置发生了平移,并不会影响局部邻域,所以满足了平移等变性
- 因为计算过程中只涉及到邻域的计算,所以可以很好地推广到不同长度的序列
- 如果已知任意一个输入的token绝对位置,就可以通过token间的相互关系得到所有token的位置
Positional Encoding Generator
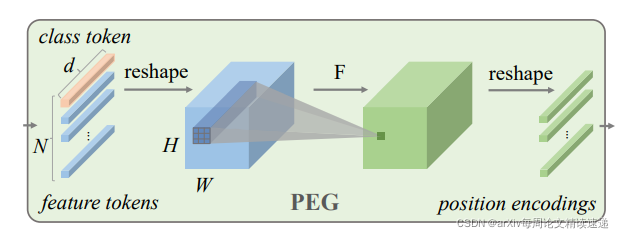
首先分割原图像,产生的小块图像进行 feature tokens,再 reshape 成二维数据(蓝色),再基于一个 F 函数进行转换(绿色)尺寸不变,再分割成小块,输入进 Transformer 中,其中 F 函数,即为条件。F 函数是一个二维卷积,理论上可以是任何形式的二维卷积。这里强调是二维卷积,而不是三维卷积,因为首先进行分割,再将分割后的特征进行了扁平化,所以是二维的(如果直接对图片使用卷积,那卷积核应该是三维的)
这里解释一下为什么二维卷积就变成条件位置编码了呢?卷积操作大家都可以理解,卷积核越大,包含的周边信息就越多,这个过程可以理解为将原始图像的顺序排列的特征有了空间信息,空间信息越多,分类的准确率就越高。
本质上说:CPE 本质解决的问题就是提高了分割后的小图片的空间信息,由于将图片分割成小图片后,排成一排输入进 Transformer 中时,会失去原本的图片的空间信息,最开始的位置编码,并不能完美的解决这个问题,而修改后的条件编码,一定程度上解决了这个问题。
写在最后
CNN + Transformer 的架构值得尝试!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号