Python for Data Analysis 学习心得(四) - 数据清洗、接合
一、文字处理
之前在练习爬虫时,常常爬了一堆乱七八糟的字符下来,当时就有找网络上一些清洗数据的方式,这边pandas也有提供一些,可以参考使用看看。下面为两个比较常见的指令,往往会搭配使用。
split(“,”)可以将文字串分割,冒号里的为分割依据,左边的代码就是把两个冒号中间的文字串视为一个单元。
strip()去除空白符号。
1、正则表达式
正则表达式为处理文字搜索匹配的功能,python可以直接导入re模块来使用。用法为下。


可直接用split来编译再拆解,也可以先用compile编译,再用split来拆解,后者可节省cpu的资源。
下面是几个比较常见的正则表达式指令

关于文字的处理pandas还有其他的方法,这边就不细讲了,有需要的时候再去查看就行。
二、层次化处理
一般常见的关系式数据库通常只有单一索引,对于数据量大的搜索效果通常不太好,pandas这边提供了多层索引,有点像树状图,一层一层的下来,可以提高搜索效率。

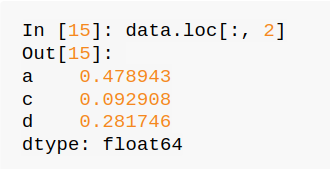
可以用loc来调取数据,以逗号“,”来间隔层数,下图就是将所有第一层的和第二层为2的数都拉出
unstack功能是把本来的第二层的拿来当列,他的相反是stack

可以自定义行列的名字

三、合并数据集
这跟表join的功能类似,也是将两张表的数据合在一起。用如下,可将df1,df2两个表相接,key就是他们接合的依据。merge默认是两张表的交集,并默认用共同有的列为依据。

如果想要将两张表的并集,或是左连接、右连接。可以在选项设定。outer代表并集、left和right代表左右连接。

DataFrame还有许多的连接方式与设定,有需要再去查看就可以。

