

大数据分析———(4)数据分析
我们采用 hive 数据仓库,把上面用 Spark 清洗完成的数据进行数据的存储与分析。
3.4.1 Hive的启动与数据上传
首先在 Linux 终端界面任意目录下输入 hive shell 进入 hive shell 界面
进入 shell 成功后,通过 create database test; 命令创建数据库,用 show databases; 命令查看数据库是否成功创建

然后用 use test; 选择刚才创建的数据库,在数据库中创建表,完整的代码为
create table stst1(str1 string, str2 string, str3 string,str4 string, str5 string, str6 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location '/home'

最后从文件中导入数据到刚刚建立的表中,完整命令为
load data local inpath '/home/part-00000' overwrite into table stst1;

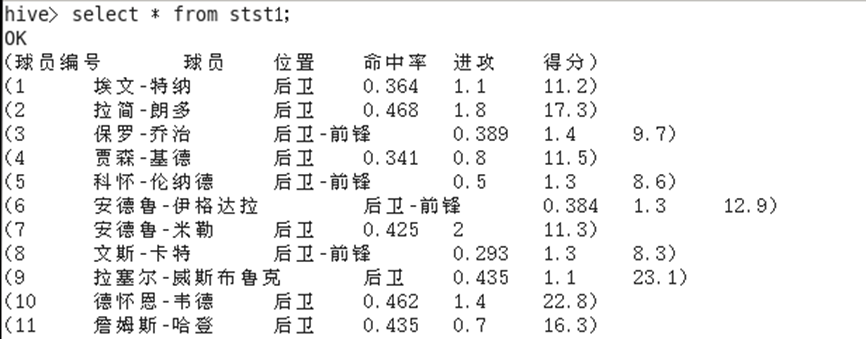
至此,数据导入数据库完成,我们可通过 select * from stst1; 查看数据的导入情况
3.4.2 用Hive进行数据统计分析
数据库中拥有相当丰富的查询与筛选排序命令,所以用数据库命令对数据进行分析,相对来说是比较方便快捷的选择。
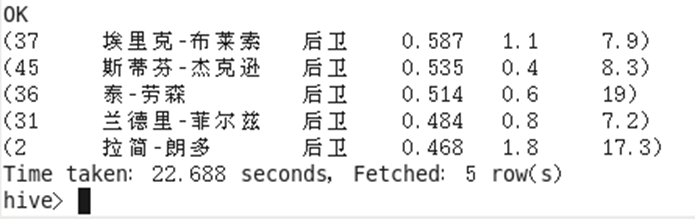
在本次课题中,我们来对 NBA2011-2012季后赛球员 ,位置为后卫的命中率前五名进行分析展示。具体代码为
select * from stst1 where str3='后卫' order by str3 DESC limit 5;

我们可以看到,其在运行查询筛选的过程中,自动调动了 MapReduce 进行数据计算

至此,数据的分析统计已经完成,最后的结果如下图所示


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通