大数据分析———(3)数据清洗
3.3.1 在Eclipse创建代码文件
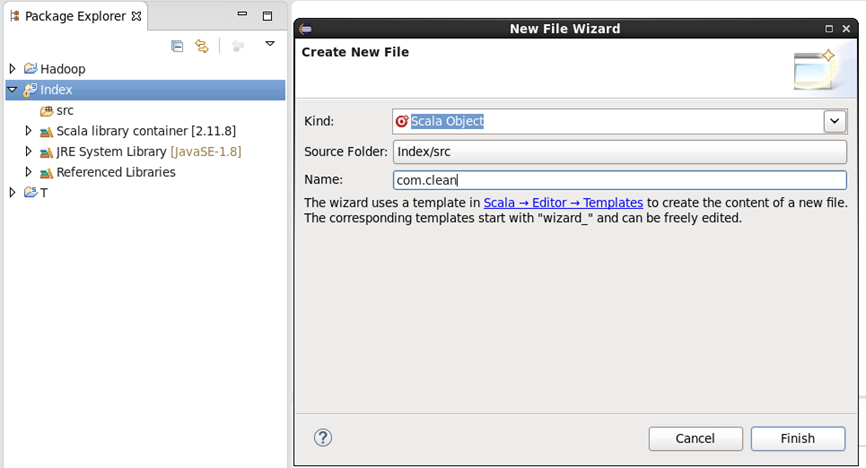
在项目上右键==>New==>Scala Object,进入spark文件的创建菜单

设置包名.类名后点击Finish创建成功
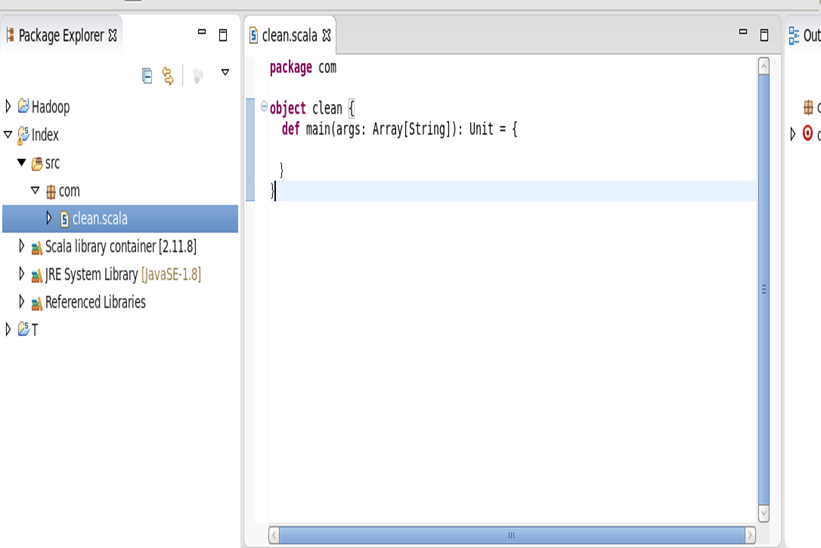
3.3.2 代码文件书写与运行
完整代码 clean.scala 如下:
package com import org.apache.spark.SparkConf import org.apache.spark.SparkContext import au.com.bytecode.opencsv.CSVReader import java.io.StringReader import scala.collection.JavaConversions._ object clean { def main(args: Array[String]): Unit = { val conf=new SparkConf().setAppName("Word").setMaster("local") val sc=new SparkContext(conf) //读取上传的csv文件 val test1=sc.wholeTextFiles("/home/data.csv") //进行分割方便读取 val test2=test1.flatMap{ case(_,txt)=> val reader=new CSVReader(new StringReader(txt)) //只读取球员编号、球员名、位置、命中率、进攻、得分列 reader.readAll().map(x => (x(0),x(1),x(3),x(7),x(12),x(20))) } //将清洗好的文件另存为新的文件 test2.saveAsTextFile("/home/out") } }
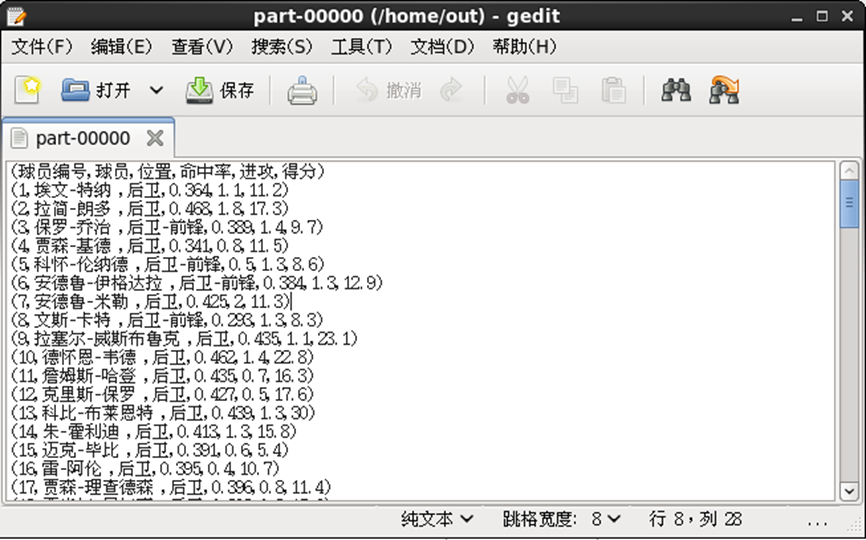
运行后会在 /home 目录下生成 out 目录,打开out目录下的 part-00000 文件即可看到清洗结果,至此数据清洗完成。