大数据分析———(2)准备工作
3.2.1 环境安装
本次项目使用Spark进行数据清洗,首先需要安装Scala环境。下载解压后,修改 ~/.bashrc文件,把Scala添加到系统环境变量中。

3.2.2 环境运行
在启动Spark之前,首先要启动Hadoop。进入Hadoop目录后,在sbin下运行./~bashrc启动

然后启动Spark,进入Spark目录,在sbin下运行./~bashrc启动
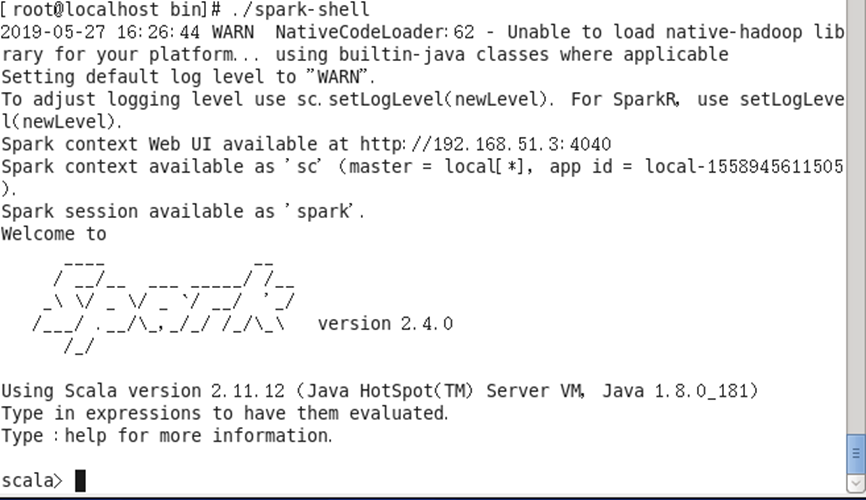
再进入Spark的bin目录,运行 ./spark-shell ,进入Spark的shell模式。至此,spark已正常启动.

3.2.3 Spark在Eclipse中的运行
在shell界面虽然也可完成数据清洗,但代码的修改和排错较为麻烦。所以把Spark环境添加到Eclipse上,可较为方便的实现代码的修改、排错与重现。
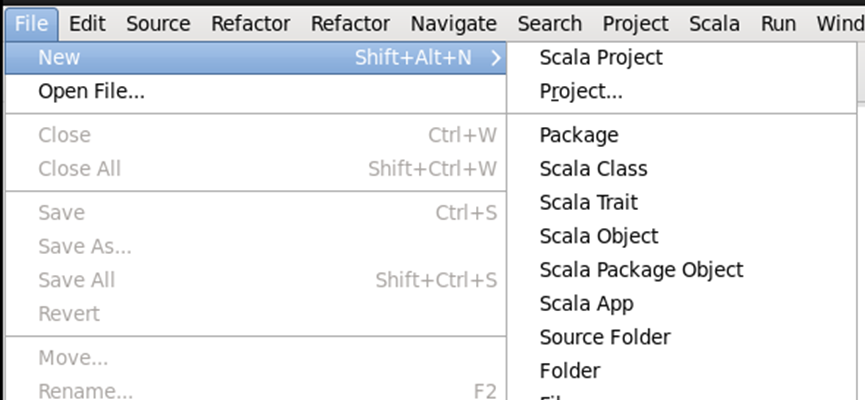
第一步,打开Eclipse界面后,点击左上角的File==>New==>Scala Project,新建Scala项目
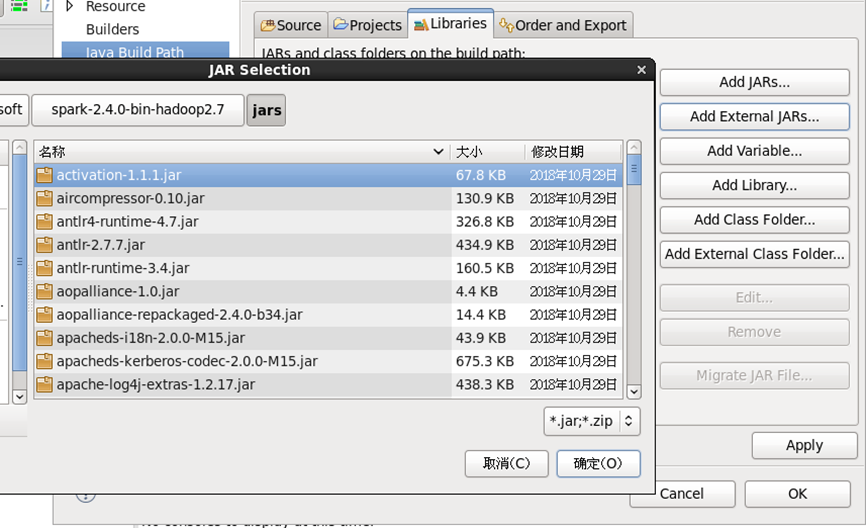
第二步,为项目添加构建路径,在项目名上右键==>Build Path==>Configure Build Path…
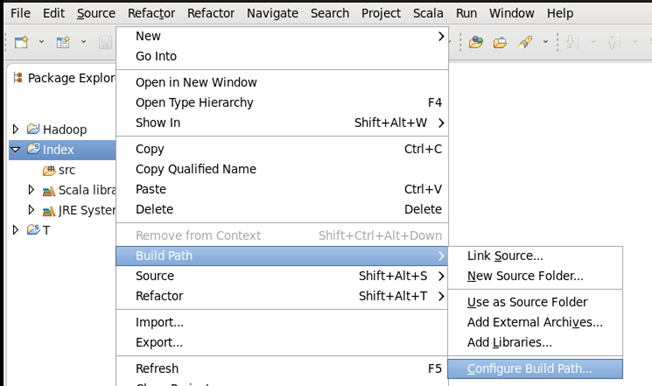
点击进入构建路径设置界面后,点击Libraries==>Add Extemal JARs…,找到spark目录下的jars目录,全选目录下的jar包,点击确定后完成设置。