DBSCAN算法
英文全称为Density-Based Spatial Clustering of Applications with Noise。
它是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。它是一种无监督学习算法。
以上是百度百科的解释,其实已经粗略的解释了它的机制。在具体描述算法的机制之前,我先解释几个基本概念。分别为1个核心思想、2个算法参数、3种点的区别和4种点的关系。
基本概念
1个核心思想:基于密度
直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
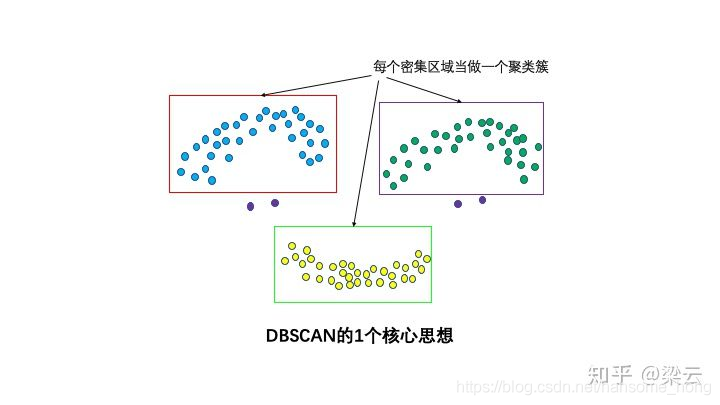
2个算法参数:邻域半径R和最少点数目minpoints
这两个算法参数实际可以刻画什么叫密集——当邻域半径R内的点的个数大于最少点数目minpoints时,就是密集。
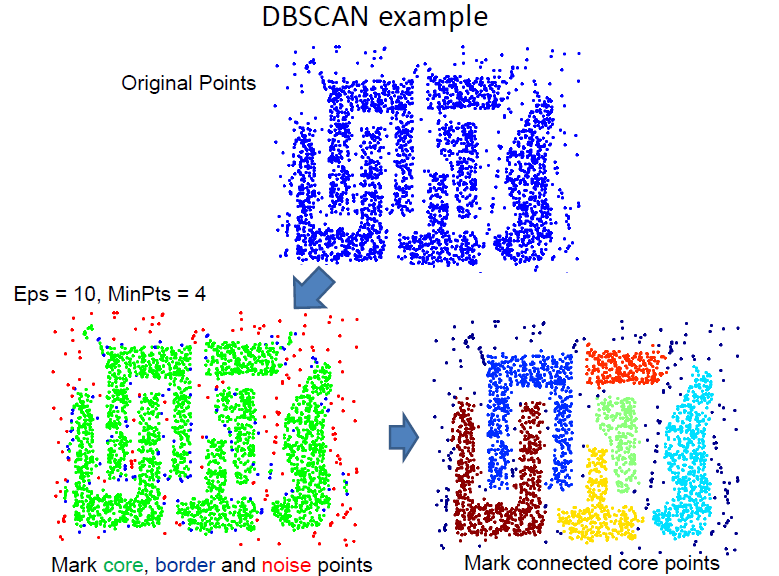
3种点的类别:核心点,边界点和噪声点
- 邻域半径R内样本点的数量大于等于minpoints的点叫做核心点。
- 不属于核心点但在某个核心点的邻域内的点叫做边界点。
- 既不是核心点也不是边界点的是噪声点。
4种点的关系:密度直达,密度可达,密度相连,非密度相连
- 如果P为核心点,Q在P的R邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度直达,那么Q到P不一定密度直达。
- 如果存在核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn到Q密度直达,则P1到Q密度可达。密度可达也不具有对称性。
- 如果存在核心点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连。密度相连的两个点属于同一个聚类簇。
- 如果两个点不属于密度相连关系,则两个点非密度相连。非密度相连的两个点属于不同的聚类簇,或者其中存在噪声点。

算法描述
输入:数据集,邻域半径 Eps,邻域中数据对象数目阈值 MinPts;
输出:密度联通簇。
具体流程如下:
1)从数据集中任意选取一个数据对象点 p;
2)如果对于参数 Eps 和 MinPts,所选取的数据对象点 p 为核心点,则找出所有从 p 密度可达的数据对象点,形成一个簇;
3)如果选取的数据对象点 p 是边缘点,选取另一个数据对象点;
4)重复 2)、3)步,直到所有点被处理。
算法复杂度
O(n²)
n 为数据对象的数目。这种算法对于输入参数 Eps 和 MinPts 是敏感的。
优缺点
和传统的 k-means 算法相比,DBSCAN 算法不需要输入簇数 k 而且可以发现任意形状的聚类簇,同时,在聚类时可以找出异常点。
优点
1)可以对任意形状的稠密数据集进行聚类,而 k-means 之类的聚类算法一般只适用于凸数据集。
2)可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3)聚类结果没有偏倚,而 k-means 之类的聚类算法的初始值对聚类结果有很大影响。
缺点
1)样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用 DBSCAN 算法一般不适合。
2)样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的 KD 树或者球树进行规模限制来进行改进。
3)调试参数比较复杂时,主要需要对距离阈值 Eps,邻域样本数阈值 MinPts 进行联合调参,不同的参数组合对最后的聚类效果有较大影响。
4)对于整个数据集只采用了一组参数。如果数据集中存在不同密度的簇或者嵌套簇,则 DBSCAN 算法不能处理。为了解决这个问题,有人提出了 OPTICS 算法。
5)DBSCAN 算法可过滤噪声点,这同时也是其缺点,这造成了其不适用于某些领域,如对网络安全领域中恶意攻击的判断。
引用
https://blog.csdn.net/hansome_hong/article/details/107596543

 浙公网安备 33010602011771号
浙公网安备 33010602011771号