


浏览器 密码破解
本文前半部分科普 KDF 函数的意义,后半部分探讨 KDF 在前端计算的可行性。
前言
几乎每隔一段时间,就会听到“XX 网站被拖库”的新闻。之后又会出现一些报道,分析该网站使用最多的密码是什么、有多少等等。
众所周知,密码在数据库中通常是以 Hash 值存储的,并且还加了盐。攻击者即使知道具体的 Hash 算法,也只能暴力破解。照理说这是极其费劲的,然而现实中却总有大量密码被破解,是什么导致安全性如此脆弱?
究其原因,莫过于这两点:口令密码、算法成本。
口令密码
密码可以记在很多地方。最常见的,就是记在自己脑袋里。当然还可以记在属于你的物品上,例如小本子、卡片等等,反正不用脑子记,不如设置的很长很乱,例如:
QQ: n5Py 2r8W qGyg 4tU6
GMail: 3TkS mVwQ hUrs wtmA
...这种无意义的长串作密码,是很安全的。即使它们的 Hash 值以及算法泄露,攻击者想得到明文,只能暴力穷举所有组合:
泄露的值是 BF656DEC5DD8BA0B,泄露的算法是 f(x)。开始穷举...
尝试组合 f(x) 结果
aaaa aaaa aaaa aaaa 02F49B3EA5592B14 ×
aaaa aaaa aaaa aaab BD4E960D990DA3F3 ×
...
n5Py 2r8W qGyg 4tU5 4CEA28A904326A26 ×
n5Py 2r8W qGyg 4tU6 BF656DEC5DD8BA0B √就算只有字母和数字,也要近 10^28 次才猜到。这是个天文数字,几乎不可行。所以,这种类型的密码还是很安全的。
然而现实中这么做的并不多。物品需要随身携带,非常不便,要是弄丢或者被偷,就更麻烦了。除非把它们都背下来,但这不又回到“记在脑袋里”这种方式了!
脑袋确实很安全,但容量也很有限。像上面那种毫无规律的字串,背一句都难,更别说多个了。所以,大家多少都会选些有意义、有规律的字串作为密码,例如 iloveyou2016、qwert12345,或是手机号、生日等组合。这种不用死记硬背的字串,就是口令(pass word)。
口令虽然方便,但缺陷也很明显:因为它是有规律的,所以猜起来就容易多了。攻击者只需测试常用单词组合,没准就能猜到了:
泄露的值是 2B649D47C4546A3E,泄露的算法是 f(x)。开始跑字典...
尝试组合 f(x) 结果
...
qwert yuiop 52708233CFFD6BFD ×
qwert asdfg CD07933880702B97 ×
qwert zxcvb 343F78782D73AB3A ×
qwert 12345 2B649D47C4546A3E √这个过程,就是所谓的“跑字典”。一本好的字典,可以极大的提升猜中几率。
算法成本
在字典相同的情况下,速度就显得尤为重要了。每秒可以猜多少次?这得看具体的算法。
例如 MD5 函数,每次调用大约需要 1 微秒,这意味着每秒可以猜 100 万次!(而且这还只是单线程的速度,用上多并发更是恐怖)
由此可见,算法越快,对破解者就越有利。假如每次调用需要 10 毫秒,那么每秒只能猜 100 次,这样就足足慢了一万倍!
然而不幸的是,常用的 Hash 函数都是很快的。因为它们生来就有多种用途,并非为口令处理而设计。例如计算一个大文件的校验值,速度显然很重要。
所以,用 MD5、SHA256 之类的“快函数”处理口令,是不合理的。包括一些简单的变种,例如 MD5(SHA256(x)),仍然属于“快函数”。一旦 Hash 值和算法泄露,很容易被“跑字典”破解。
现实中,由于不少网站使用了“快函数”来处理口令,因此数据库泄露后,大量口令被还原也就在所难免了。
增加成本
虽然 Hash 函数单次执行很快,但我们可以反复执行大量次数,这样总体耗时就变长了。例如:
function slow_sha256(x)
for i = 0 to 100000
x = sha256(x)
end
return x
end在密码学中,这种方式叫做 拉伸。现实中有不少方案,例如 PBKDF2 —— 它没有重头设计一种新算法,而是对现有的函数进行封装,从而更适合用于口令处理:
function pbkdf2(fn, ..., iter)
...
for i = 0 to iter
...
x = fn(x, ...)
...
end
...
return x
end它有一个迭代参数,用于指定反复 Hash 的次数 —— 迭代次数越多,执行时间越长,破解也就越困难。
PBKDF(Password-Based Key Derivation Function,基于口令的秘钥导出函数),顾名思义,就是输入“口令”(有规律的字串)输出“秘钥”(无规律的长串)的函数,并且计算过程会消耗一定资源。本质上也是 Hash 函数,输出结果称之 DK(derived key)。
前端拉伸
拉伸次数越多虽然越安全,但这是以消耗服务端大量计算资源为代价的!为了能在安全和性能之间折衷,通常只选择几十到几百毫秒的计算时间。
服务端的计算量如此沉重,以至于不堪重负;而如今的客户端,系统资源却普遍过剩。能否让用户来分担一些计算量?
听起来似乎不可行。毕竟前端意味着公开,将密码相关的算法公开,不会产生安全问题吗。
先来回顾下,传统网站是如何处理口令的 —— 前端通常什么都不做,仅仅用于提交,口令都是由后端处理的:

现在,我们尝试对前端进行改造 —— 当用户在注册、登录等页面中提交时,不再发送原始口令,而是口令的 DK:
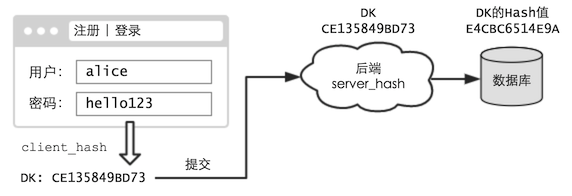
后端,则不做任何改动。(当然这会影响已有账号的使用,这里暂时先不考虑,假设这是个新网站)
这样,即使用户的口令很简单,但相应的 DK 却仍是个毫无意义的长串。通过 DK 的 Hash 值,是极难还原出 DK 的。(在本文开头就提到过了)
当然,攻击者更感兴趣的不是 DK,而是口令。这倒是可以破解的 —— 只需将前后端算法结合,形成一个新函数:
F(x) = server_hash(client_hash(x))用这个最终函数 F 跑字典,还是可以猜口令的:
尝试组合 耗时 F(x) 结果
...
qwert yuiop 1s 1C525DC73898A8EF ×
qwert asdfg 1s F9C0A131F43F1969 ×
qwert zxcvb 1s 08F026D689D26746 ×
...只不过其中有 client_hash 这道障碍,破解速度就大幅降低了!
所以,我们需要:
-
一个缓慢的 client_hash,增加跑字典的成本
-
一个快速的 server_hash,防止 DK 泄露
这样,就能将绝大多数的计算转移到前端,后端只需极少的处理,即可实现一个高强度的密码保护系统。
对抗预算
由于前端的一切都是公开的,所以 client_hash 的算法大家都知道。攻击者可以把常用口令的 DK 提前算出来,编成一个新字典。将来拖库后,直接跑这个“新字典”,就能节省大量时间了。
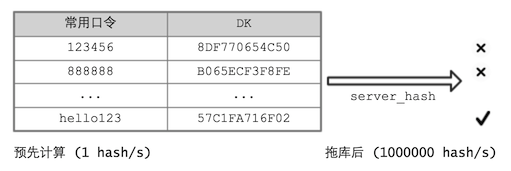
对于这种方式,就需要使用“加盐”处理(事实上 PBKDF 本身就需要提供盐参数)。例如,选择用户 ID 作为盐:
function client_hash(password, salt) {
return pbkdf2(sha256, password, salt, 1000000);
}
client_hash('888888', 'tom@163.com'); // b80c97beaa7ca316...
client_hash('888888', 'jack@qq.com'); // 465e26b9d899b05f...这样即使口令相同,但用户不同,生成的 DK 也是不同的。攻击者只能针对特定账号生成字典,适用范围就小多了。
更进一步,我们甚至可将“网站 ID”也掺入盐中:
function client_hash(password, salt) {
return pbkdf2(sha256, password, salt, 1000000);
}
client_hash('888888', 'jack@qq.com/www.site-a.com'); // 77a1b139aa93ac8b...
client_hash('888888', 'jack@qq.com/www.site-b.com'); // fab6b82e6a1d17d7...这样即使同样的“账号密码”,在不同网站上生成的 DK 也是不一样了!
思考题:ID 是公开的,能不能选个隐蔽的字段作为 client_hash 的盐?
DK 泄露
DK 诞生于前端,后端对其 Hash 之后就不复存在了,所以它是个临时值。理想情况下,它是不会泄露的。

但在某些场合,DK 还是有可能泄露的。例如服务器中毒、网络传输被窃听等,都能导致 DK 泄露。
DK 泄露后,攻击者就能控制该账号了,这是无法避免的。但幸运的是,DK 只是个无意义的长串而已,攻击者并不知道其背后的那个有意义的“口令”是什么。因此其他使用类似口令的账号,就幸免于难了!
攻击者若要通过 DK 还原口令,就得用 client_hash 算法跑字典 —— 这个成本依然很大。相比之前的“最终函数 F”,只是少算一次 server_hash 而已。(server_hash 本来就很快,可以忽略不计)。所以即使 DK 泄露,破解口令难度基本没降低。
“账号被盗,口令拿不到”,这就是“前端 Hash”的意义。
额外意义
前端的拉伸计算,使得用户登陆时会耗费一定的系统资源。这个副作用,事实上也能起到一定的防御效果。
对于普通用户来说,登陆时额外花费几秒时间,或许影响不大;但对于频繁登录的人来说,将是一个极大的开销。有谁会极其频繁的登录?这很可能就是“撞库攻击者” —— 他们从其他地方弄到一堆账号口令,然后来这里撞运气,看看能成功登上多少。
由于我们是用 DK 登录的,因此攻击者也必须将待测的口令,先算出 DK 再提交,于是会增加不少计算成本。这和上一篇的 Proof-of-Work 有点类似。
如同拉伸弹簧需要付出能量,拉伸 Hash 同样需要投入实实在在的算力。
优化体验
事实上只要设计的合理,完全可以将“拉伸计算”的等待降到最小。例如,当用户输完账号和密码后,程序立即开始计算 DK,而不是等到提交时才开始计算。如果网站有验证码的话,即可在用户输入的同时进行计算。这样就能大幅提升用户体验。
小结
本篇提到的 3 类密码:
| 类型 | 安全性 | 易用性 | 说明 |
|---|---|---|---|
| 无意义的长串 | 高 | 差 | 很难记住,只能储存在外部,增加了保管成本 |
| 有规律的口令 | 低 | 好 | 容易记住,但也容易被“跑字典”攻击 |
| 口令转成秘钥 | 中 | 好 | 同上。但转换过程很耗时,提高跑字典的成本 |
两种 Hash 函数:
-
快函数(MD5、SHA256 等,输入数据“很长很没规律”时使用)
-
慢函数(PBKDF2、bcrypt 等,输入数据“容易猜到”时使用)
关于“前端 Hash”,其实算是 “零知识证明”(zero-knowledge proof)的一种。什么是零知识证明,这里套用一个经典的例子:
你拥有一个宝库,可以通过念咒语来开门。有天你想在朋友面前证明你能打开宝库,但又不想让他听到咒语。这该如何解决?
正好,他知道你的宝库里有个独一无二的宝物,如果能取出来给他看,自然就能证明你能打开。这样就无需带他到场,自己单独打开取出宝物,然后拿给他看就行了。于是,就可以在不暴露咒语的同时,证明你能打开。
这就是零知识证明 —— 证明者在不透露“任何有用信息”的情况下,使验证者相信某个论断是正确的。
实际应用
“前端 Hash”的做法在“密码管理插件”中很常见:用户的口令不再发往后端,而是仅仅用于生成 DK。然后再根据 DK,给不同账号生成不同的密码。这样就算遇到最坏的情况(例如服务器中毒、传输窃听、后端明文存储等)导致密码泄露,也不会暴露你的口令。最多损失某个账号,而不影响其他账号!
(另外,口令也不再填写于原先的文本框中,而是填在插件的界面上,插件算出 DK 后自动填到原先的文本框。这样可以降低口令泄露的风险,例如网页中可能潜伏着恶意脚本)
Web 应用
不过现实中,天生内置了前端 KDF 计算的网站并不多。不像插件可以调用本地程序,性能高且稳定,浏览器则是良莠不齐,不同的版本性能差异很大,因此计算时间很不稳定。
另外,在曾经很长一段时间里(IE 时代),浏览器的计算力都十分低下,以至于大家都保留了前端计算意义不大、“一切都由后端计算”的观念。不过如今主流浏览器的性能已得到大幅提升,甚至 HTML5 还引入了 WebCrypto 规范,JS 可直接调用浏览器内置的密码学算法库,其中就包括了 PBKDF2。由于是原生实现的,因此性能非常的高。这里有个简单的演示:
https://etherdream.github.io/FunnyScript/pbkdf2/test.html
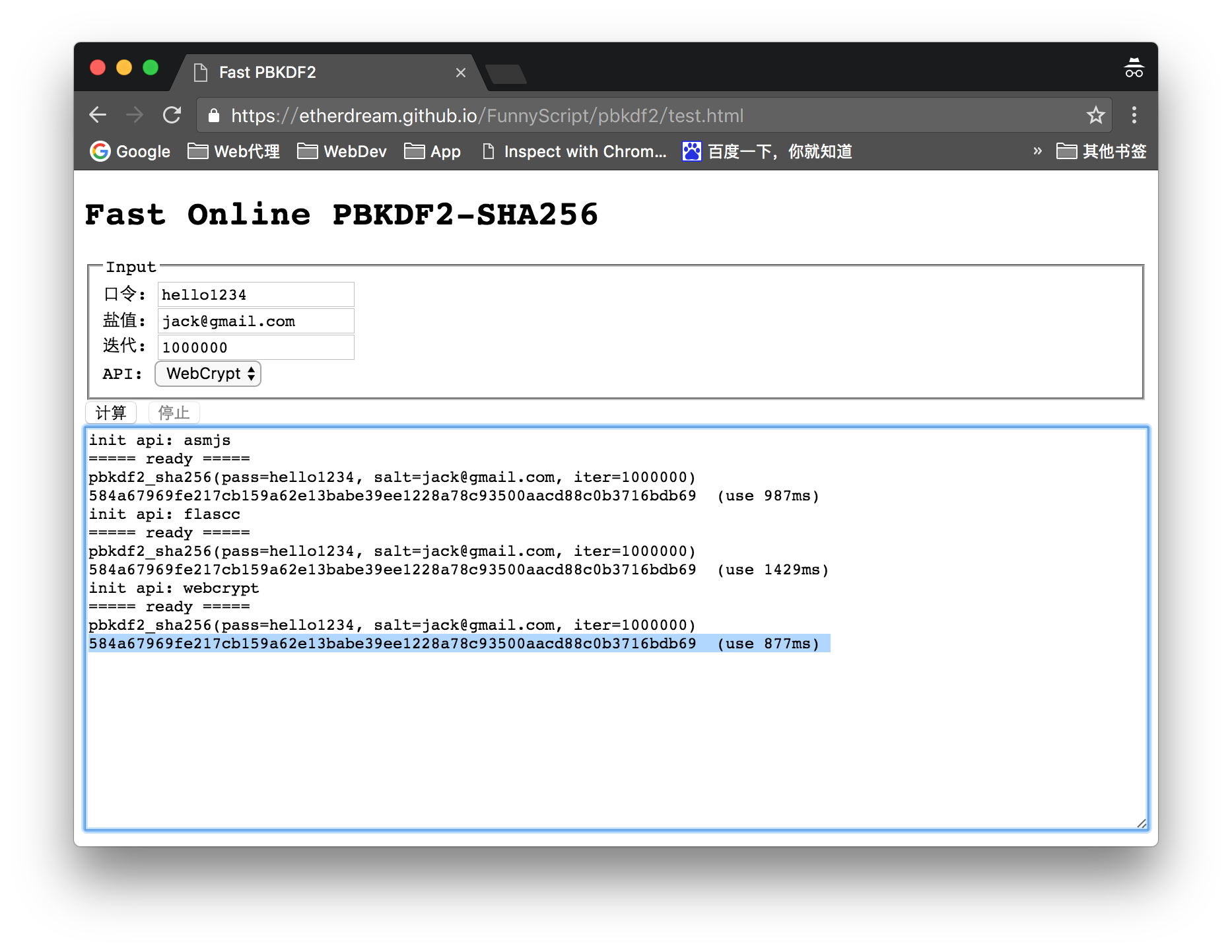
(分别使用 asm.js、Flash、WebCrypto 几种方案,计算 100 万次迭代的测试)
更好的 KDF
当然,作为口令 Hash 函数,PBKDF2 还不是最好的,因为它只是简单地套用了现有的 Hash 函数而已,而非针对性的进行设计。
2015 年 Password Hashing Competition 的胜出者 —— argon2,就非常先进了。它不仅可设置时间成本(迭代次数),还能设置空间成本(内存占用)。并且还支持多线程计算,让攻击者也必须投入同样多的算力进行破解!
当然 argon2 还太新,目前尚未收录到 WebCrypto 里。不过已有人将其移植成 JavaScrpt 版本,不妨值得一试。


