HtmlAgilityPack获取#开头节点的XPath
获取文档的XPath,有些文字元素没有包含在节点里面,
比如
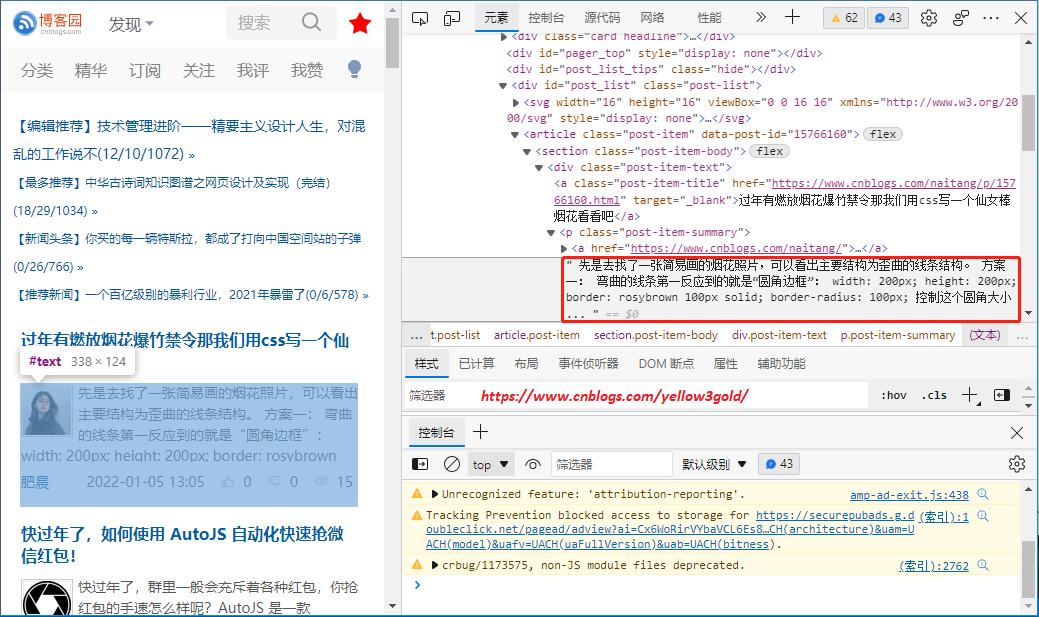
用HtmlAgilityPack获取的XPath如下:
/html[1]/body[1]/div[1]/div[2]/div[1]/div[2]/div[1]/div[4]/article[1]/section[1]/div[1]/p[1]/#text[1]
但是用doc.DocumentNode.SelectSingleNode(xpath);获取就会报错;
xpath改成这样就可以了
/html[1]/body[1]/div[1]/div[2]/div[1]/div[2]/div[1]/div[4]/article[1]/section[1]/div[1]/p[1]/text()[1]
写个方法转换一下:
public static string rexpt(string p) { var resxpath = p; if (Regex.IsMatch(p, @"/#[a-z]+(\[\d+\])?$")) { var end = Regex.Match(p, @"/#[a-z]+(\[\d+\])?$").Value; var rep = Regex.Match(end, @"[a-z]+").Value + "()" + Regex.Match(end, @"\[\d+\]").Value; resxpath = Regex.Replace(resxpath, @"/#[a-z]+(\[\d+\])?$", "/" + rep); } return resxpath; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号