《高性能MySQL》读书笔记:MySQL里面索引优点和类型
MySQL里面索引优点和类型
主要内容来自《高性能MySQL》“第5章:创建高性能的索引”部分5.1、5.2小节
目录
为什么要用索引?
主要作用是为了:让服务器快速地定位到表的指定位置
其他作用有什么?
-
索引可以帮助服务器避免排序和临时表:树索引可以按照顺序存储数据,那么MySQL 可以用来做 ORDER BY和 GROUP BY操作,因为数据是有序的,所以 B-Tree也就会将相关的列值都存储在一起。
-
索引可以将随机 I/O变为顺序I/O: B树索引里面可以存储实际的列值,某些查询只使用索引就能够完成全部查询
B-Tree 索引
B-Tree 索引索引包含B+树和B树索引
宏观的样子
大多数MySQL引擎都支持使用 B-Tree数据结构来存储数据(但是innodb是B+树, 如下)
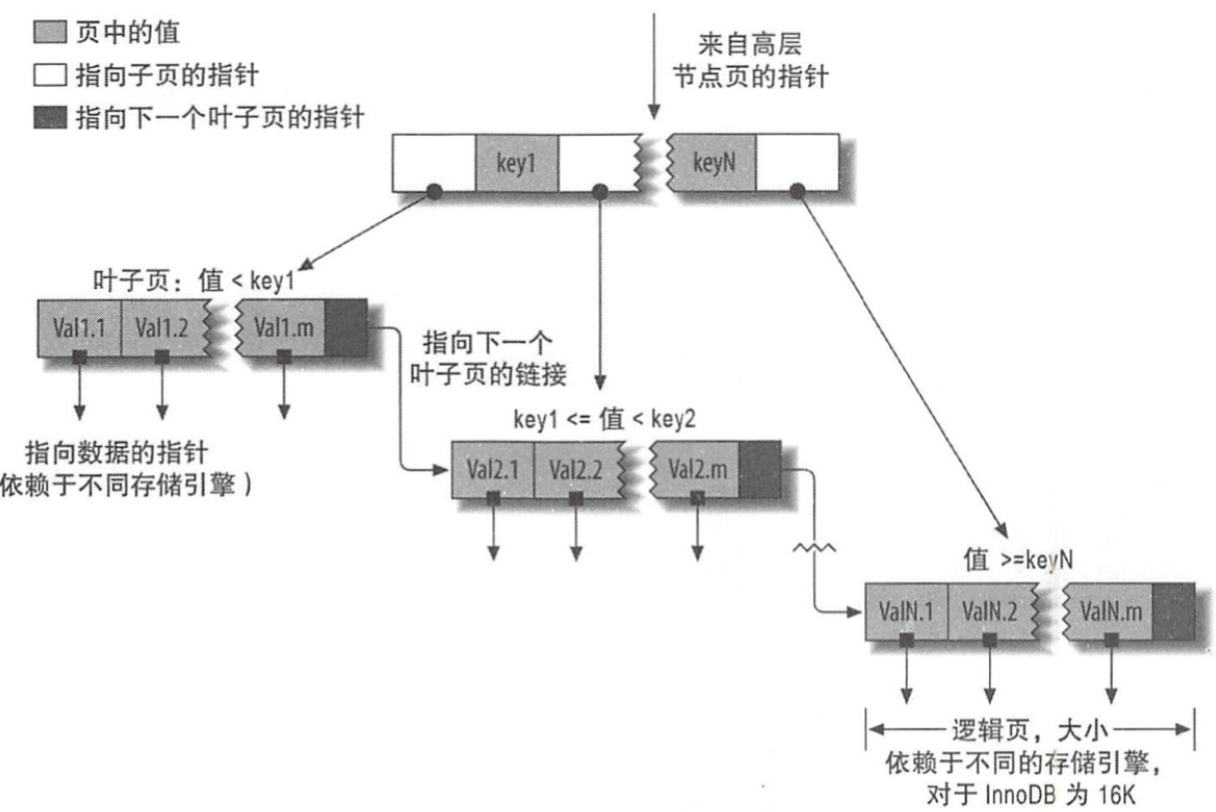
注意:
-
单个指针指向下来的一块链表结构为一个逻辑页,innodb默认一页为16KB数据。
-
指针不存储数据,存储的是子节点页当中值的上下限
-
树的深度和表的大小直接相关。
微观的样子
假如有如下的表格People,建立了联合索引,按照姓、名、生日*(date of birth)* 来索引数据行。

那么在数据库里面数据将会是如下组织的。
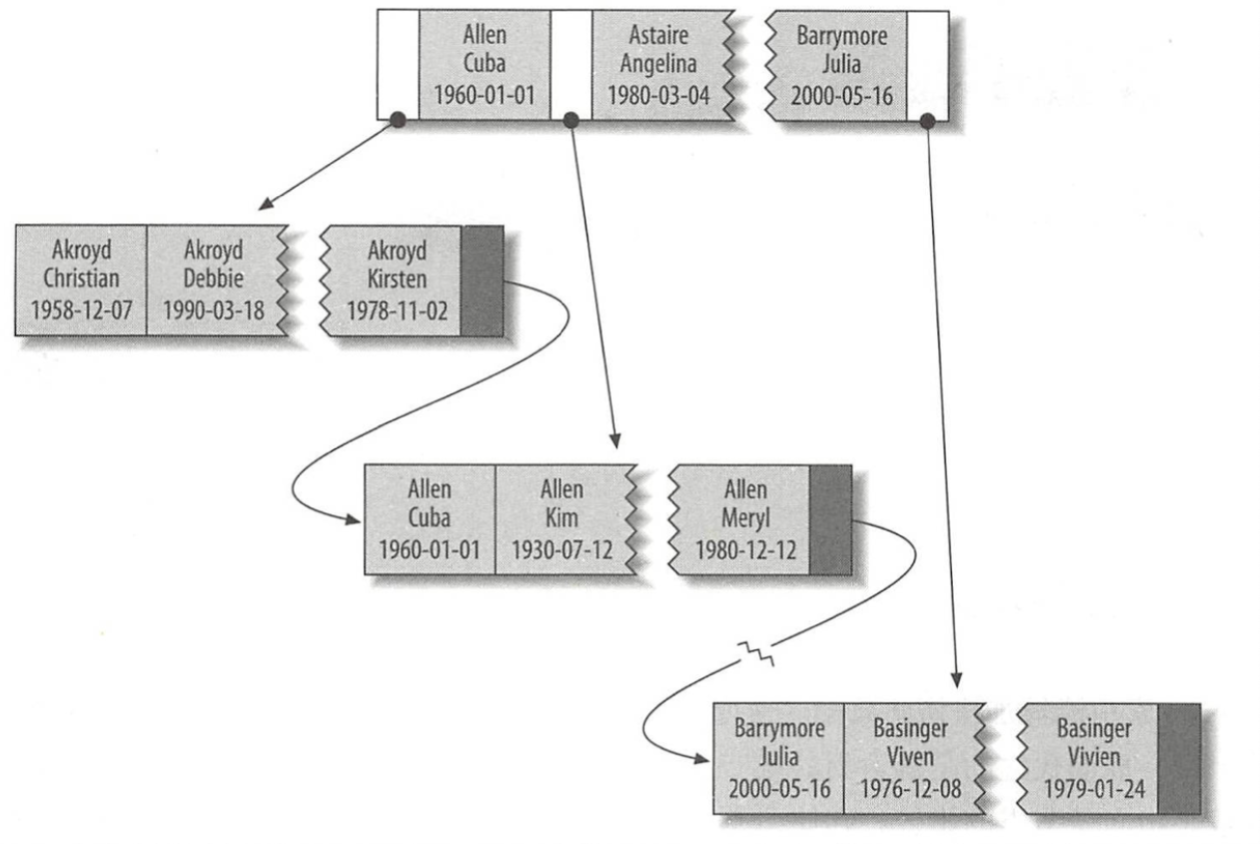
特点是什么?
-
最左的叶子结点存放的是数据里面最小的,可以看见AKROYD这个人的记录的字母序包括生日的日期都是最小的。
-
父节点记录左右两侧会有两个指正,分别指向下面两个链表记录,父节点的数据记录会是右节点的链表第一个记录。
-
前两个索引的值相同,最后一个所有的值不同,则按照最后一个索引值排序(比如最后两个数据 basinger vivien)
什么时候适合使用B树索引
B树索引索引适用于:
-
全键值:
-
where后面的条件个数和字段和索引起来的字段都完全一致
-
只访问索引字段的查询,也就是查询只需要访问索引,不需要查询整行数据。
-
-
键值范围:
-
只匹配第一个索引字段的前提下,范围查找第一个索引字段的内容,比如查询姓名为Allen和 Barrymore之间的数据
-
精确匹配第一索引+范围匹配其他索引: 比如查询姓为Allen,且名为K开头的记录
-
-
键前缀查找:
-
匹配最左前缀: 只适用于根据最左前缀的查找,比如只匹配第一个索引字段
-
只匹配某一列的值的开头部分:只匹配第一个索引字段的前提下,值查询这个索引字段以某段前缀开头的记录。比如查询J开头的姓名
-
什么时候不适合说使用B树索引
下面这些查询会使索引失效、部分失效:
-
不按照索引第一列去查找数据,比如上来直接跨过姓去查找名为“Bill”的记录
-
跨过了中间的几个索引字段:比如查询条件为姓和生日字段但是不限制名字的查询,跨了一列索引字段,就只能利用到一个字段*(姓)*
-
某个索引字段是范围查询:
WHERE last_name=’Smith' AND first_name LIKE 'J%' AND dob = '1976- 12-23’如上SQL,第二个索引开始为一个范围查询,那么只能利用到first_name这个索引字段为止。
总结一下:
不能跨、不能插,范围查询到此为止
哈希索引
哈希索引的基本概念
基于哈希表实现,只有精确匹配索引所有列的查询才有效。每一行数据都有个hashcode,不同键值都有一个hashcode,索引会把这个映射关系保存在索引里面,索引里面存储的是每个数据行的指针。
各个存储引擎里面,只有Memory显式支持哈希索引(设为默认),另外值得一题的是,如果多个列的hashcode是一样的(冲突),那么这些列会下挂在一个节点下称为链表。和HashMap是一致的。
那么在MySQL里面的hash索引到底是怎么样的呢?

上面的语句可以创建一个哈希索引的表,注意engine = memory。
假想的函数是f(fname)=10086,给一个fname的值就能得到一个hashcode。这个hashcode =10086可以在hash索引里面找到对应的值,这个值是一个指向某行记录的指针。hashcode在索引里面也被称为slot(等价于平时称kv键值对里面的key),对应的值就是value,没有别的称呼。
这种索引在数据库里面的使用顺序是什么呢?比如以SQL语句(SELECT lname FROM testhash WHERE fname='Peter';)为例:
-
首先计算f(Peter) = hashcode,获取这个主键的hashcode。
-
在索引中按照上面计算出来的hashcode找到对应的索引项
-
对应的value就是想要找的记录,按照指针地址访问即可。
哈希索引的优缺点
优点
-
索引自身只需存储对应的哈希值,所以索引的结构十分紧凑(意味着占用空间少,不像B树索引那样,索引本身的存储内容就比较大,和数据本身相关的信息占比较多)
-
这也让哈希索引查找的速度非常快。
缺点
-
只包含哈希值和行指针,而不存储字段值。聚簇索引就就可以直接在索引项上直接读取记录,不需要再次访存。
-
哈希表并不按照索引的值排序,所以排序无法使用这中所以
-
哈希所以不支持部分索引列匹配查找,因为hashcode的获取是根据索引列的全部索引内容来计算得到的。如果只查询第一个索引,是无法使用这个哈希索引的。
-
哈希所以在等值比较的时候回使用上索引,否则无法利用。比如 = / in()。范围查询是无法使用哈希索引的。
-
当出现哈希冲突的时候,存储引擎会遍历这个冲突的节点下挂的链表节点,逐行比较。
-
哈希冲突频繁出现,维护索引的代价会很高。举个例子,比如某节点下挂链表很长,一旦要删除某行数据就需要执行On复杂度的遍历+修改引用删除。这是一笔不小的开销。
InnoDB也会创建"伪哈希索引"。
InnoDB 引擎有一个特殊的功能叫做“自适应哈希索引”,某些索引值被频繁使用,就会基于B树引擎之上再建立哈希索引,借助这个索引加速查找操作。这个选项可以关闭
创建的哈希索引和真正的哈希索引不太一样,InnoDB的哈希索引的使用使用的是hashcode,并不是键本身去索引查找。需要在where当中手动执行哈希函数。
如何创建"伪哈希索引"?
给表的字段加上一个字段用于存储想要索引的字段的hash值。
例如需要存储大量的 URL,并需要根据 URL 进行搜索查找。如果使 用 B-Tree 来存储 URL,存储的内容就会很大,因为 URL 本身都很长。
一般情况下是这样查询的:SELECT id FROM url WHERE url=”http://www.mysql.com”;
使用哈希索引可以:
-
删除原来 URL列上的索引
-
新增一个被索引的url列,使用 CRC32做哈希
CRC(Cyclic Redundancy Check)循环冗余校验,数据存储和数据通信领域常用
比如如下SQL去查询:
SELECT id FROM url WHERE url="http://www.mysql.com"
and url_crc = CRC32("http://www.mysql.com")
这样做有什么好处?
MySQL 优化器会使用这个选择性很高而体积很小的基于 url_crc 列的索引来完成查找 。这样查询快速的原因就是:根据hashcode做快速的整数比较,就能找到对应的索引条目,就能找到对应那个节点下挂的所有数据。只需要简单的遍历比较就好。
之前的策略,对完整的url去做索引,这样速度会很慢。
怎么维护索引?
虽然哈希索引被innodb创建之后速度很快,但是需要维护,维护可以手动触发或者使用触发器触发。下面用实例去介绍:

创建一个表,自增id+url字段+crc方式哈希编码之后的url字段。一共三个,其中id是主键。
创建一个触发器如下:
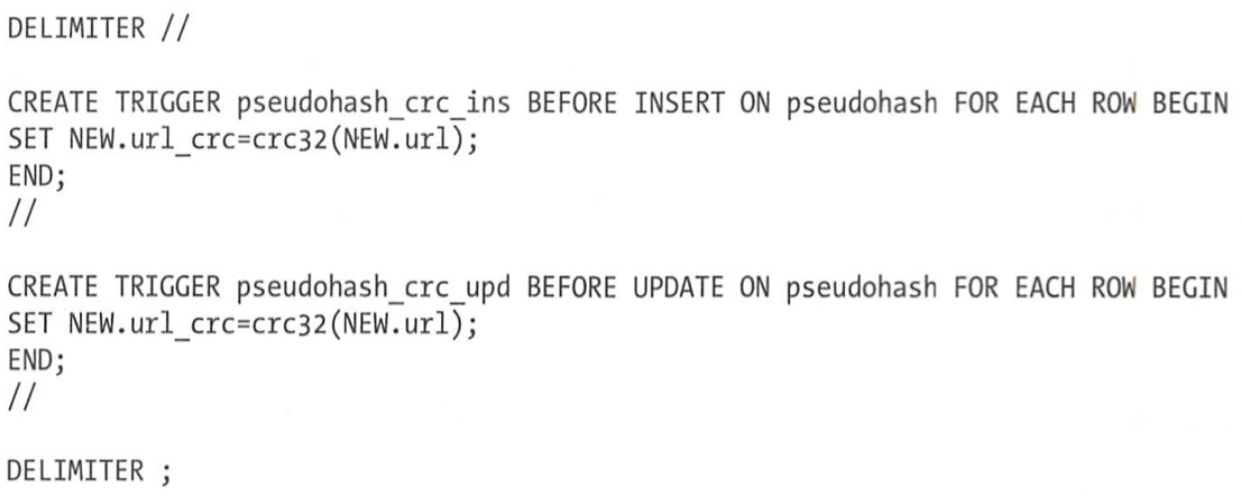
当插入和更新数据的时候,每行将url的值计算crc算法的哈希值并复制给url_crc字段。这样设置之后,每次插入(不带url_crc数据的插入)就会自动补充url_crc字段的值。
注意事项
-
不要使用 SHA()或者MD5() 作为哈希函数 。这两个函数计算 出来的哈希值是非常长的字符串,会浪费大量空间,比较时也会更慢 。
-
目的() 和问DS () 是强加密函数,设计目标是最大限度消除冲突。也就是hash冲突会很小,但是下挂链表的这种类HashMap的设计是允许出现哈希冲突的。有时候需要平衡查询性能和存储空间两个冲突。
-
当表数据够多的时候,可能冲突会非常严重,可以增大这个hashcode的位数(比如通过截断MD5()来自定义一个hash函数),如下实现:
SELECT CONV(RIGHT(MD5('http://www.mysql.com/'), 16), 16, 10) AS HASH64;
处理哈希冲突
当使用哈希索引进行查询的时候,必须在 WHERE子句中包含常量值 ,比如在where子句中包含常量值。
SELECT id FROM url WHERE url_crc=CRC32('http://www.mysql.com')
AND url='http://www.mysql.com';
为什么要这样写?如果不这样的话,你可能会这么写。
SELECT id FROM url WHERE url_crc=CRC32('http://www.mysql.com') ;
去掉常量的url字段值辅助查询,如果出现另外一个值的hashcode一样,那么第二个SQL就无法工作了(返回多个结果)
要避免冲突问题 ,必须在 WHERE 条件中带入哈希值和对应列值 。
另外你还可以在MySQL当中安装插件,使用FNV64()函数作为哈希函数。这个函数来自Percona Server 的函 数,对比CRC32算法,这个速度和冲突方面都优秀一些。
