
scrapy的项目详解
1.scrapy安装好后,即可在终端中输入“scrapy”,这样将会显示帮助信息。
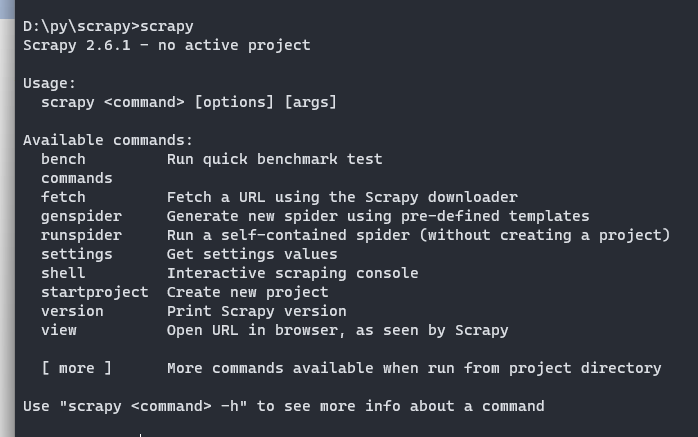
bench:是 Scrapy 的基准测试工具,它可以用于测试 Scrapy 在不同设置下的性能表现和吞吐量等。
bench 工具会模拟网络环境和网站数据,对 Scrapy 进行压力测试,并输出测试结果。
使用 bench 工具可以帮助开发者找出性能瓶颈和优化空间,提高爬虫的效率和稳定性。commands:
1.startproject:创建一个新的 Scrapy 项目,指定项目名称和起始目录。例如:scrapy startproject myproject。
2.genspider:创造一个新的 Spider,指定 Spider 名称和爬取的域名。例如:scrapy genspider myspider example.com。
3.crawl:启动指定的 Spider 进行数据爬取。例如:scrapy crawl myspider。
4.list:列出当前 Scrapy 项目中所有可用的 Spider。例如:scrapy list。
5.shell:使用交互式 Shell 测试某些代码或者 XPath 表达式。例如:scrapy shell "https://www.example.com"。
6.fetch:获取某个 URL 的响应并输出到屏幕上,主要用于测试。例如:scrapy fetch "https://www.example.com"。
7.view:在浏览器中查看某个 URL 的页面。例如:scrapy view "https://www.example.com"。
8.version:显示当前安装的 Scrapy 版本号。例如:scrapy version。
2.使用 Scrapy 创建的爬虫程序通常有以下目录结构:
scrapy_project/ # 项目目录
├── scrapy.cfg # Scrapy 项目配置文件
└── scrapy_project/ # Scrapy 项目的根目录。
├── __init__.py # Python 包的标识文件
├── items.py # 定义数据模型的文件,即定义需要从网页上抓取的字段。
├── middlewares.py # 存放中间件的文件,中间件可以在爬取数据的过程中进行一些额外的处理,例如更改请求头、请求体等。
├── pipelines.py # 存放管道的文件,管道用于处理 Spider 提取到的数据,可以进行数据清洗、去重、存储等操作。
├── settings.py # 存放 Scrapy 项目的设置,例如爬虫的超时时间、请求头信息等。
└── spiders/ # 存放 Spider 的目录
├── __init__.py
└── spider_name.py # 自定义的 Spider 类所在文件,定义如何爬取网页、如何解析网页等。
# 这些文件和目录是 Scrapy 爬虫程序的基本组成部分,爬虫程序的其他文件和目录可以根据实际需求进行添加或修改。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号