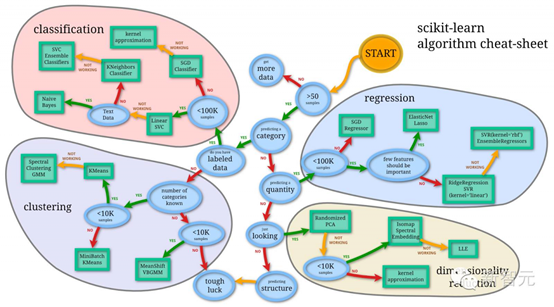
机器学习常用35大算法
本文将带你遍历机器学习领域最受欢迎的算法。系统的了解这些算法有助于进一步掌握机器学习。当然,本文收录的算法并不完全,分类的方式也不唯一。不过,看完这篇文章后,下次再有算法提起,你想不起它长处和用处的可能性就很低了。本文还附有两张算法思维导图供学习使用。
在本文中,我将提供两种分类机器学习算法的方法。一是根据学习方式分类,二是根据类似的形式或功能分类。这两种方法都很有用,不过,本文将侧重后者,也就是根据类似的形式或功能分类。在阅读完本文以后,你将会对监督学习中最受欢迎的机器学习算法,以及它们彼此之间的关系有一个比较深刻的了解。
事先说明一点,我没有涵盖机器学习特殊子领域的算法,比如计算智能(进化算法等)、计算机视觉(CV)、自然语言处理(NLP)、推荐系统、强化学习和图模型。
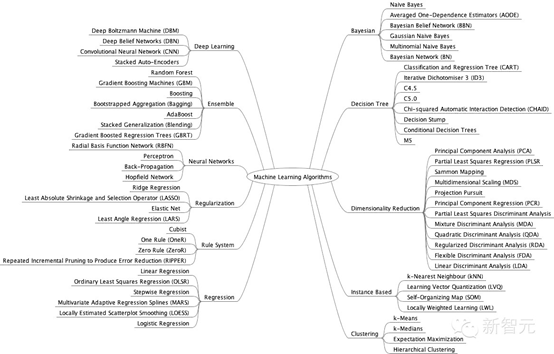
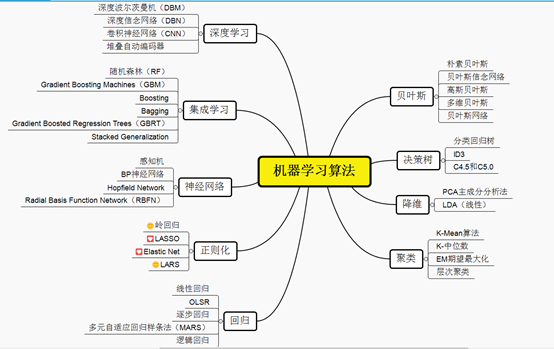
从学习方式分类
算法对一个问题建模的方式很多,可以基于经历、环境,或者任何我们称之为输入数据的东西。机器学习和人工智能的教科书通常会让你首先考虑算法能够采用什么方式学习。实际上,算法能够采用的学习方式或者学习模型只有几种,下面我会一一说明。对机器学习算法进行分类是很有必要的事情,因为这迫使你思考输入数据的作用以及模型准备过程,从而选择一个最适用于你手头问题的算法。
一、五大类别
-
监督学习
输入数据被称为训练数据,并且每一个都带有标签,比如"广告/非广告",或者当时的股票价格。通过训练过程建模,模型需要做出预测,如果预测出错会被修正。直到模型输出准确的结果,训练过程会一直持续。常用于解决的问题有分类和回归。常用的算法包括逻辑回归、随机森林、决策树和BP神经网络等等。
-
无监督学习
输入数据没有标签,输出没有标准答案,就是一系列的样本。无监督学习通过推断输入数据中的结构建模。这可能是提取一般规律,可以是通过数学处理系统地减少冗余,或者根据相似性组织数据。常用于解决的问题有聚类、降维和关联规则的学习。常用的算法包括 Apriori 算法和 K 均值算法。
-
半监督学习
半监督学习的输入数据包含带标签和不带标签的样本。半监督学习的情形是,有一个预期中的预测,但模型必须通过学习结构整理数据从而做出预测。常用于解决的问题是分类和回归。常用的算法是所有对无标签数据建模进行预测的算法(即无监督学习)的延伸。
从功能角度分类
研究人员常常通过功能相似对算法进行分类。例如,基于树的方法和基于神经网络的方法。这种方法也是我个人认为最有用的分类方法。不过,这种方法也并非完美,比如学习矢量量化(LVQ),就既可以被归为神经网络方法,也可以被归为基于实例的方法。此外,像回归和聚类,就既可以形容算法,也可以指代问题。
为了避免重复,本文将只在最适合的地方列举一次。下面的算法和分类都不齐备,但有助于你了解整个领域大概。(说明:用于分类和回归的算法带有很大的个人主观倾向;欢迎补充我遗漏的条目。)
-
强化学习
详解链接:强化学习涉及的学科及其特点http://blog.sciencenet.cn/home.php?mod=space&uid=3360373&do=blog&id=1086532
没有明确的指导信号,reward(奖励)可以看做是指导信号,类比SL是求解函数
y =f(x,z) ,其中x是Agent(代理)的状态(state),z是Agent在该状态获得的奖励reward,f是要求解的策略policy,y则是输出的动作action,即根据状态和奖励序列求解最优策略。reward是指((你给我Reward这个值是什么意思?我到底能不能做的更好?给我100分?我怎么100分的Reward好不好?万一其他Action可以拿到10000分呢?))
强化学习是通过对未知环境一边探索一边建立环境模型以及学得一个最优策略。有监督学习则是事先给你了一批样本,并告诉你哪些样本是优的哪些是劣的(样本的标记信息),通过学习这些样本而建立起对象的模型及其策略。在强化学习中没有人事先告诉你在什么状态下应该做什么,只有在摸索中反思之前的动作是否正确来学习。从这个角度看,可以认为强化学习是有时间延迟标记信息的有监督学习。常见算法包括Q-Learning以及时间差学习(Temporal difference learning)
-
迁移学习
迁移学习(Transfer learning) 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习(starting from scratch,tabula rasa)。
二、各算法介绍
2.1回归算法
监督学习指的是有目标变量或预测目标的机器学习方法。回归与分类的不同,就在于其目标变量是连续数值型。
回归分析是研究自变量和因变量之间关系的一种预测模型技术。这些技术应用于预测时间序列模型和找到变量之间关系。回归分析也是一种常用的统计学方法,经由统计机器学习融入机器学习领域。"回归"既可以指算法也可以指问题,因此在指代的时候容易混淆。实际上,回归就是一个过程而已。
常用的回归算法包括:
-
普通最小二乘回归(OLSR)
-
线性回归
-
逐步回归
-
多元自适应回归样条法(MARS)
-
局部估计平滑散点图(LOESS)
-
逻辑回归(是分类算法)
2.2基于实例的学习算法
基于实例的学习通过训练数据的样本或事例建模,这些样本或事例也被视为建模所必需的。这类模型通常会建一个样本数据库,比较新的数据和数据库里的数据,通过这种方式找到最佳匹配并做出预测。换句话说,这类算法在做预测时,一般会使用相似度准则,比对待预测的样本和原始样本之间的相似度,再做出预测。因此,基于实例的方法也被称之为赢家通吃的方法(winner-take-all)和基于记忆的学习(memory-based learning)。
常用的基于实例的学习算法包括:
-
k-邻近算法(KNN)
-
学习矢量量化算法(LVQ)
-
自组织映射算法(SOM)
-
局部加权学习算法(LWL)
2.3正则化算法
正则化算法背后的思路是,参数值比较小的时候模型更加简单。对模型的复杂度会有一个惩罚值,偏好简单的、更容易泛化的模型,正则化算法可以说是这种方法的延伸。我把正则化算法单独列出来,原因就是我听说它们十分受欢迎、功能强大,而且能够对其他方法进行简单的修饰。常用的正则化算法包括:
-
岭回归
-
LASSO算法
-
Elastic Net
-
最小角回归算法
2.4决策树算法
决策树算法的目标是根据数据属性的实际值,创建一个预测样本目标值的模型。训练时,树状的结构会不断分叉,直到作出最终的决策。也就是说,预测阶段模型会选择路径进行决策。决策树常被用于分类和回归。决策树一般速度快,结果准,因此也属于最受欢迎的机器学习算法之一。
常用的决策树算法包括:
-
分类和回归树(CART)
-
ID3算法
-
C4.5算法和C5.0算法(它们是一种算法的两种不同版本)
-
CHAID算法
-
单层决策树
-
M5算法
-
条件决策树
2.5贝叶斯算法
贝叶斯方法指的是那些明确使用贝叶斯定理解决分类或回归等问题的算法。
常用的贝叶斯算法包括:
-
朴素贝叶斯算法
-
高斯朴素贝叶斯算法
-
多项式朴素贝叶斯算法
-
AODE算法
-
贝叶斯信念网络(BBN)
-
贝叶斯网络(BN)
2.6聚类算法
聚类跟回归一样,既可以用来形容一类问题,也可以指代一组方法。聚类方法通常涉及质心(centroid-based)或层次(hierarchal)等建模方式,所有的方法都与数据固有的结构有关,目标是将数据按照它们之间共性最大的组织方式分成几组。换句话说,算法将输入样本聚成围绕一些中心的数据团,通过这样的方式发现数据分布结构中的规律。
常用的聚类算法包括:
-
K-均值
-
K-中位数
-
EM算法
-
分层聚类算法
2.7关联规则学习
关联规则学习在数据不同变量之间观察到了一些关联,算法要做的就是找出最能描述这些关系的规则,也就是获取一个事件和其他事件之间依赖或关联的知识。常用的关联规则算法有:
-
Apriori算法
-
FP-Growth算法
-
Profixspan算法
-
Eclat算法
2.8人工神经网络
人工神经网络是一类受生物神经网络的结构及/或功能启发而来的模型。它们是一类常用于解决回归和分类等问题的模式匹配,不过,实际上是一个含有成百上千种算法及各种问题变化的子集。注意这里我将深度学习从人工神经网络算法中分离了出去,因为深度学习实在太受欢迎。人工神经网络指的是更加经典的感知方法。
常用的人工神经网络包括:
-
感知机
-
反向传播算法(BP神经网络)
-
Hopfield网络
-
径向基函数网络
2.9深度学习算法
深度学习算法是人工神经网络的升级版,充分利用廉价的计算力。近年来,深度学习得到广泛应用,尤其是语音识别、图像识别。深度学习算法会搭建规模更大、结构更复杂的神经网络,正如上文所说,很多深度学习方法都涉及半监督学习问题,这种问题的数据一般量极大,而且只有很少部分带有标签。
常用的深度学习算法包括:
-
深度玻尔兹曼机(DBM)
-
深度信念网络(DBN)
-
卷积神经网络(CNN)
-
栈式自编码算法(Stacked Auto-Encoder)
2.10降维算法
降维算法和聚类有些类似,也是试图发现数据的固有结构。但是,降维算法采用的是无监督学习的方式,用更少(更低维)的信息进行总结和描述。降维算法可以监督学习的方式,被用于多维数据的可视化或对数据进行简化处理。很多降维算法经过修改后,也被用于分类和回归的问题。
常用的降维算法包括:
-
主成分分析法(PCA)
-
主成分回归(PCR)
-
偏最小二乘回归(PLSR)
-
多维尺度分析法(MDS)
-
线性判别分析法(LDA)
-
二次判别分析法(QDA)
-
投影寻踪法(PP)
2.11模型融合算法
模型融合算法将多个简单的、分别单独训练的弱机器学习算法结合在一起,这些弱机器学习算法的预测以某种方式整合成一个预测。通常这个整合后的预测会比单独的预测要好一些。构建模型融合算法的主要精力一般用于决定将哪些弱机器学习算法以什么样的方式结合在一起。模型融合算法是一类非常强大的算法,因此也很受欢迎。
常用的模型融合增强方法包括:
-
Boosting
-
Bagging
-
AdaBoost
-
堆叠泛化(混合)
-
GBM算法
-
GBRT算法
-
随机森林
2.12其他
还有很多算法都没有涉及。例如,支持向量机(SVM)应该被归为哪一组?还是说它自己单独成一组?
我还没有提到的机器学习算法包括:
-
特征选择算法
-
Algorithm accuracy evaluation
-
Pderformance measures
再附一张思维导图