Jenkins 共享库最佳实践
Jenkins共享库最佳实践
我是一个使用了两年Jenkins的一个运维人员,从Jenkins Freestyle的方式切换到了Jenkins Pipeline的模式,之后因为机缘巧合接触到了Share libs 的方法(一个老大哥教的我),之后又了解到了Share libs 分为共享库与模板库,在最后在google上看到了官方人员推荐的Share libs最佳实践,所以整理一下,说一下为何叫做最佳实践
共享库简介
官方的解释(我没有使用过resources这个目录)
(root)
+- src # Groovy source files
| +- org
| +- foo
| +- Bar.groovy # for org.foo.Bar class
+- vars
| +- foo.groovy # for global 'foo' variable
| +- foo.txt # help for 'foo' variable
+- resources # resource files (external libraries only)
| +- org
| +- foo
| +- bar.json # static helper data for org.foo.Bar
在使用共享库的时候我们会用到两个目录
- src
- var
我的理解
src 定义了一些方法
vars 定义了一些变量
当我们使用src把公共代码编程方式在Jenkinsfile 里调用时,这种方式叫做共享库
当我们使用把所有的逻辑放在了vars 中使用时,这种方式叫做模板库
我喜欢用模板库,因为在我的理解中Devops的职责就是标准化开发流程与规定,而模板库的使用必须要做到标准才有效果,所以我一直工作中使用模板库的方法进行工作
模板库
模板库写法
在vars 下创建一个 TEST.groovy 文件
+- vars
| +- TEST.groovy
模板库代码
#!groovy
def call(String type,Map map) {
if (type == "test") {
pipeline {
agent {
node {
label "${map.node}"
}
}
//步骤设置
stages {
stage('测试') {
steps {
println "test"
}
}
}
}
}
}
}
模板库使用方法
在代码库中放入Jenkinsfile文件
#!groovy
library 'fotoable-libs'
def map = [:]
map.put('node',"master")
TEST("test",map)
以上是最近本的模板库的使用方法,这是一种标准格式的写法,并且我最开始使用的时候也是使用这种方法,但是这种方法会有一些弊端
- 使用方法不利于读写
- 当项目越来越多的时候模板库会产生很多的重复代码
为了解决这几种问题,我进阶了,去google上乱找了一圈,然后就找了一个可扩产,可重复,并且让Jenkinsfile易读的方法
模板库最佳实践
这种方法其实是基于模板库的使用方法做了一些扩展,首先我们让Jenkinsfile 通过一个入口文件去进入到模板库,之后定义个yaml格式的配置文件,在模板库中使用Read Yaml 的方式把它转化成 map后传给模板库,这样我们会得到这种目录结构
代码端
+- vars
| +- runPipeline.groovy # 入口文件
| +- pipelineCfg.groovy # 把yaml 文件转成 map
| +- pythonPipeline.grooy # 按照语言去分类的模板库
使用端
代码库根目录上放两个文件
Jenkinsfile
pipelineCfg.yaml
讲一下这五个文件
runPipeline.groovy
#!groovy
def call() {
node{
stage('Checkout') {
checkout scm
}
def cfg = pipelineCfg()
switch(cfg.type) {
case "python":
pythonPipeline(cfg)
break
case "nodejs":
nodejsPipeline(cfg)
break
}
}
}
pipelineCfg.groovy
def call() {
Map pipelineCfg = readYaml file: "pipelineCfg.yaml"
return pipelineCfg
}
pythonPipeline.grooy
def call(String type,Map map) {
if (type == "test") {
pipeline {
agent {
node {
label "${map.node}"
}
}
//步骤设置
stages {
stage('测试') {
steps {
println "test"
}
}
}
}
}
}
}
Jenkinsfile
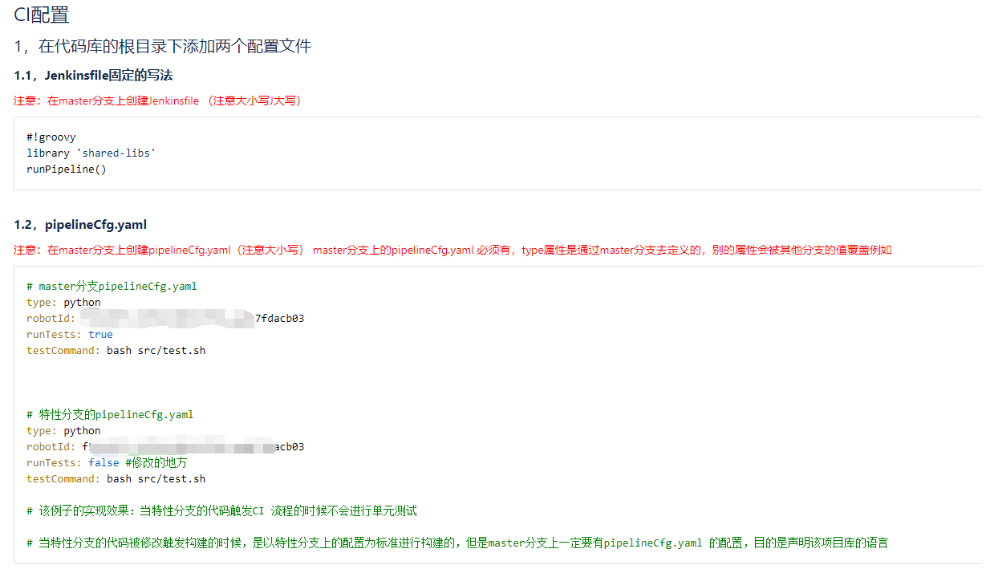
#!groovy
library 'shared-libs'
runPipeline()
pipelineCfg.yaml
type: test
node: master
以上文件就是模板库最佳实践方式,这种方式又显著的优点
- 代码复用率低
- 配置文件与入口文件分离
- 配置文件为Yaml格式,易读性强
- 扩展性强,使用“if when switch”函数可以无限扩展逻辑代码,最终变成一种语言调用一种pipeline
说一下我的实践
我在wiki软件中定义了一个ci/cd 的使用方法,研发通过观看文档去编写自己的pipelineCfg.yaml 文件,编写成功后在通过hubot机器人去创建Jenkins job(Hubot用法之前有写过在Chatops文章中),这样运维只要专注与模板库的逻辑代码编写就好了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号