
面试
神经网络中的超参数主要有哪些?
神经网络中的超参数主要分为2类:
1)网络结构相关:网络中间层数量,类型(全连接、丢弃层、归一化、卷积层、全连接层等)、每层神经元数量、激活函数等。
2)模型训练相关:损失函数、优化方法、批次大小、迭代次数、学习率、正则方法和系数、初始化方法等。
优化器的作用是什么?例举一下神经网络中常用的优化器?
优化器作用:求出让损失函数最小化的参数。
常用优化器:
1、Adam
关联所有样本的梯度,便于求解全局最优解,始终含有前面梯度的信息,把前面的梯度传到后面
优点:自动调节学习率, 速度快, 梯度传导
2、梯度下降SGD
批量梯度下降:用所有的样本更新参数,计算量大
随机梯度下降:每看一个数据更新参数,更准确,但是计算量大
小批量随机下降:按批来更新参数,前两者的折中
缺点:(1)训练速度慢(2)容易陷入局部最优
什么是感受野,感受野如何计算?
一、感受野的概念
感受野(Receptive Field)的定义:卷积神经网络每一层输出的特征图(feature map)上的像素点映射回输入图像上的区域大小。通俗点的解释是,特征图上一点,相对于原图的大小,也是卷积神经网络特征所能看到输入图像的区域。
二、举例说明
(1)若输入图像的尺寸大小是5*5,经过两次3*3的卷积核(其中stride=1,padding=0)后,其感受野大小为5*5,如下图所示:

(由卷积计算公式:N=(W-F+2P)/S+1,得到第一次卷积后的图像大小为3*3,第二次卷积后的图像大小为1*1)
(2)若输入图像的尺寸大小是7*7,经过三次3*3的卷积核(其中stride=1,padding=0)后,其感受野大小为7*7,如下图所示:

(由卷积计算公式:N=(W-F+2P)/S+1,得到第一次卷积后的图像大小为5*5,第二次卷积后的图像大小为3*3,第三次卷积后的图像大小为1*1)
也就是说,随着卷积核的增多(即网络的加深),感受野会越来越大。
三、感受野的计算
1. 从后往前:即先计算最深层在前一层上的感受野,然后以此类推逐层传递到第一层。
(1)计算公式:

其中\(RF_i\), 表示 \(i\) 层感受野大小, \(i\)表示当前特征层的层数, \(stirde\)是卷积的步长, \(K_{sizei}\)是本层卷积核的大小。
(2)注意:
1、感受野大小的计算不考虑padding的大小;
2、最后一层的特征图感受野的大小等于其卷积核的大小,即每个输出特征RF=(1-1)* S + K = K;
3、第i层特征图的感受野大小和第i层的卷积核大小和步长有关系,同时也与第(i+1)层特征图的感受野大小有关。
(3)例子:

从最后一层的Pool3池化层开始计算感受野:
pool3:RF=2(最后一层池化层输出特征图的感受野大小等于卷积核的大小)
conv4:RF=(2-1)*1+3=4
conv3:RF=(4-1)*1+3=6
pool2:RF=(6-1)*2+2=12
conv2:RF=(12-1)*1+3=14
pool1:RF=(14-1)*2+2=28
conv1:RF=(28-1)*1+3=30
因此,pool3输出的特征图在输入图片上的感受野为30*30。
2. 从前往后:从初始图像开始,按照网络的前向传播过程,从前往后一层层计算每层的感受野。
(1)计算公式:

其中:
- \(RF_{i+1}\)表示当前层感受野
- \(RF_i\)表示上一层感受野
- K 表示当前层核大小
- \(S_n\)表示前面几层的步长之积
规定:
- 初始feature map的感受野为1,即\(RF_i=1\)。
- 初始s=1。
(2)例子:


四、感受野的应用
1、小尺寸的卷积代替大尺寸的卷积,可减少网络参数、增加网络深度、扩大感受野(例如:3 个 3 x 3 的卷积层的叠加可以替代7*7的卷积),网络深度越深感受野越大性能越好;
为什么两个3x3卷积等于一个5x5卷积呢?

因为他们感受野相同。
这样做有什么好处呢?
1、增加网络层数,层之间可以加入激活函数,增加了网络的非线性表达能力。
2、参数更少,2个3x3的卷积核有18个参数,1个5x5的卷积核有25个参数。
3、小卷积级联增强了非线性特征表示,因为Conv层后往往还跟着一层非线性变换激活层,2层小卷积比一层大卷积的多了一层非线性变换,因此一定程度上增强了非线性特征表示,使得决策函数更具区分性,一定程度上提升了精度。
2、对于分类任务来说,最后一层特征图的感受野大小要大于等于输入图像大小,否则分类性能会不理想;
3、对于目标检测任务来说,若感受野很小,目标尺寸很大,或者目标尺寸很小,感受野很大,模型收敛困难,会严重影响检测性能;所以一般检测网络anchor的大小的获取都要依赖不同层的特征图,因为不同层次的特征图,其感受野大小不同,这样检测网络才会适应不同尺寸的目标。
卷积、池化输出大小如何计算?
(H,W)的特征图卷积后的大小如何计算:
假设卷积核大小是(f,f),步长是s,填充是p,那么卷积后:

(H,W)的特征图池化后的大小如何计算:

一次卷积的计算量及参数量分析?
假设输入是(H,W,C),使用一个size为(f,f)的卷积核,卷积后的输出特征图size为(H',W'),则乘法计算量为:

具体分析可看图1。

如果使用C'个不同的卷积核,则卷积后的输出特征图的size为:(H',W',C'),那么一次卷积的计算量为:

CNN的参数量主要是卷积核的参数,一次卷积中,N个(f,f)大小的卷积核的参数量为 N * f * f,如果连bias也算上,则总的参数量为 N * f * f + N
卷积层相比FC层有哪些优势?
FC:
- 1*1卷积等价于FC
- 跟原特征图一样大小的卷积核等价于FC
- FC参数多且冗余
卷积层:
- 不全连接+参数共享,减少参数量同时保留空间位置信息
- 不全连接减少了神经元之间的依赖性,从而促使神经元学习更鲁棒的特征。
1*1卷积的作用
- 实现跨通道的交互和信息整合
- 实现卷积核通道数的降维和升维
- 实现与全连接层的等价效果
- 实现多个特征图的线性组合
- 不影响卷积层的感受野,增强决策函数的非线性特征表示能力
对上述每点的解释:假设输入为(H,W,C)的特征图,(1,1)的卷积核能把C个通道的信息进行融合(回忆一下输出特征图中每个像素点是怎么计算的)。使用C'个不同的(1,1)的卷积核,那么输出通道就会变为C',当C'小于C时,那么通道数就得到降维,反之,通道数增加。第三点和第四点意思差不多,(1,1)卷积等价于全连接层,全连接层的作用就是对各个特征进行线性组合。对于最后一点,其实是conv层后会跟着一层激活层,所以能增强非线性表达能力。
卷积层的作用和特性
作用:
- 对原始信号进行特征增强,降低噪声,提取特征
- 不同的卷积核可以提取不同的特征
特性:
- 权值共享,减少参数数量,并利用了图像目标的位置无关性
- 稀疏连接:输出的每个值只依赖于输入的部分值
池化层的作用及反向传播机制
- 压缩特征图,提取主要特征,提高所提取特征的鲁棒性
- 降低模型的过拟合程度

- mean pool : 池化层的每个像素梯度平均分配给前一层卷积层参与该位置计算的像素
- max pool: 池化层每个像素的梯度传给前一层卷积层中得到该像素的像素,其他梯度为0
CNN在处理图像上为什么比DNN好呢?
- CNN保留了位置信息
- CNN保留了多通道信息,DNN加权求和后使得通道信息损失
- CNN在池化操作相当于把局部信息整合,突出显示
RNN、LSTM、GRU区别、优缺点

RNN为什么具有记忆功能
- NN(神经网络)的前一个数据和后一个数据是相互独立的,因此不具有记忆能力。
- 将RNN公式展开,可以看到当前时刻的值除了取决于当前输入外,还取决于前面的所有输入:

RNN为什么每个时间步都使用相同的W
- 参数共享,减少参数量
- 参数共享可以使得网络变为动态结构,能扩展处理不同长度的样本
- 不同的参数不能在时间上共享不同序列长度和不同位置的统计强度
RNN中为什么会出现梯度消失?如何解决?
梯度消失的原因:
sigmoid函数的导数范围是(0,0.25],tanh函数的导数范围是(0,1],他们的导数最大值都不大于1,如果取tanh或sigmoid函数作为激活函数嵌套到RNN中,那么必然是一堆小数再做乘法,结果就是越乘越小。随着时间序列的不断深入,小数的累乘会导致梯度越乘越小,知道接近于0,这就是梯度消失的的原因。
解决方法:
1、更换RNN结构为LSTM或GRU
2、使用Relu激活函数,relu在小于0时梯度为0,大于0时梯度为1,不会产生梯度消失问题
LSTM、GRU如何解决梯度消失问题
1、cell state传播函数中的“加法”结构确实起了一定作用,它使得导数有可能大于1;
2、LSTM中逻辑门的参数可以一定程度控制不同时间序列梯度消失的程度。
LSTM与GRU结构及公式
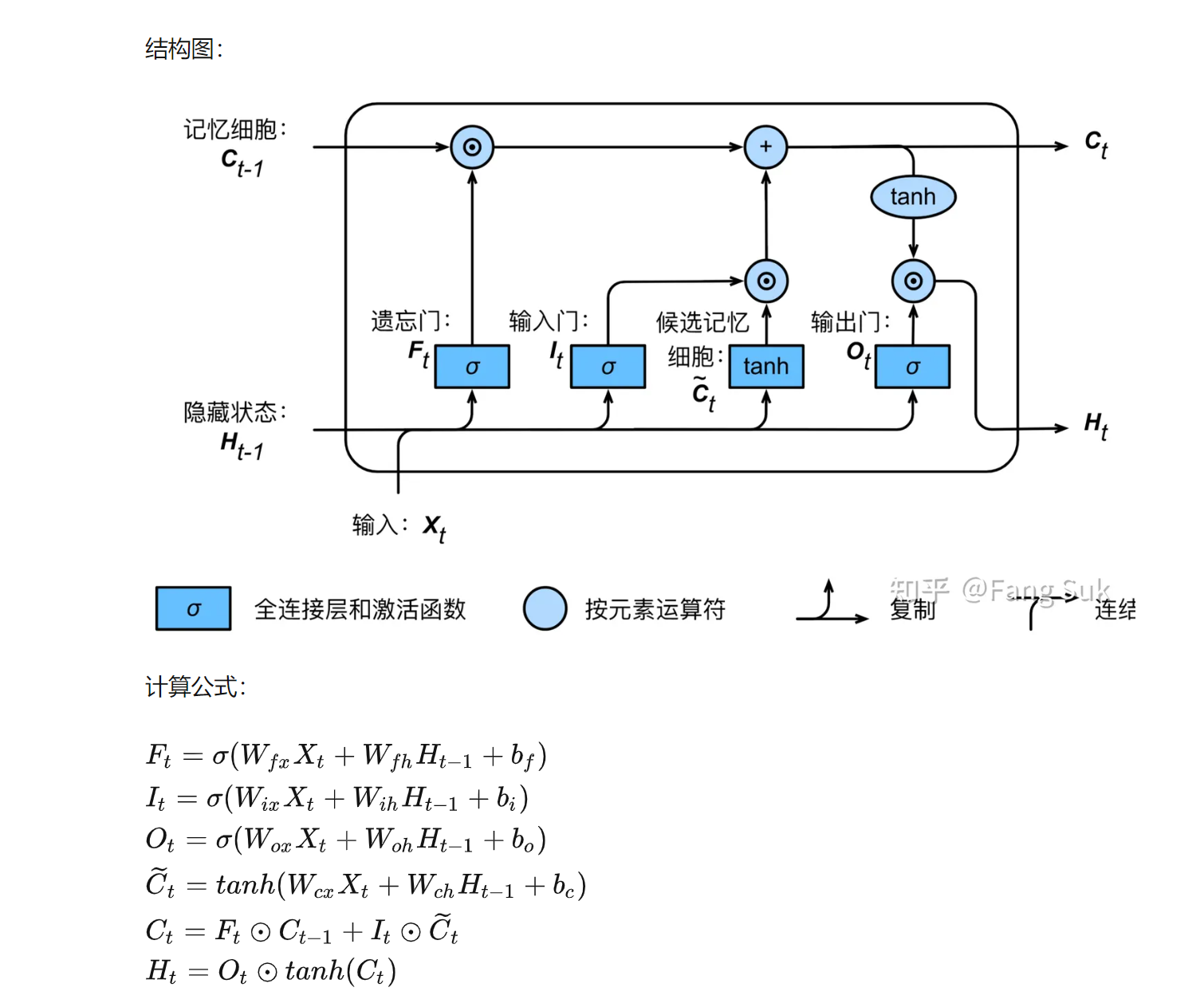

为什么LSTM记忆时间长
因为LSTM加入了门控制和细胞状态,细胞状态类似传送带,信息在上面流动,通过遗忘门去除不必要信息,通过更新门来增加信息。而RNN前面的信息会随着时间的推移,慢慢减少。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号