
一致性的基础:Raft算法
ETCD实现高可靠的基础在于Raft算法,也是理解ETCD工作原理最重要的一部分。类似于zookeeper的zab协议(Paxos算法),Raft也是用于保证分布式环境下多节点数据的一致性,但更易于理解。
看了很多相关Raft算法的技术文章,要么是介绍的过于简单,要么是过于晦涩难懂。最后看了原始的论文In search of an Understandable Consensus Algorithm和infoQ上对应的中文翻译Raft 一致性算法论文译文才对整个逻辑有细致的理解。
首先来看看Raft大致的原理,这是一个选主(leader selection)思想的算法,集群总每个节点都有三种可能的角色:
- leader
对客户端通信的入口,对内数据同步的发起者,一个集群通常只有一个leader节点 - follower:
非leader的节点,被动的接受来自leader的数据请求 - candidate:
一种临时的角色,只存在于leader的选举阶段,某个节点想要变成leader,那么就发起投票请求,同时自己变成candidate。如果选举成功,则变为candidate,否则退回为follower
数据提交的过程
先看前两种角色,leader扮演的是分布式事务中的协调者,每次有数据更新的时候产生二阶段提交(two-phase commit)。在leader收到数据操作的请求,先不着急更新本地数据(数据是持久化在磁盘上的),而是生成对应的log,然后把生成log的请求广播给所有的follower。
每个follower在收到请求之后有两种选择:一种是听从leader的命令,也写入log,然后返回success回去;另一种情况,在某些条件不满足的情况下,follower认为不应该听从leader的命令,返回false。例如下图,leader收到客户端的写请求,我们暂时不考虑请求的具体值,虚线表示leader先写log,
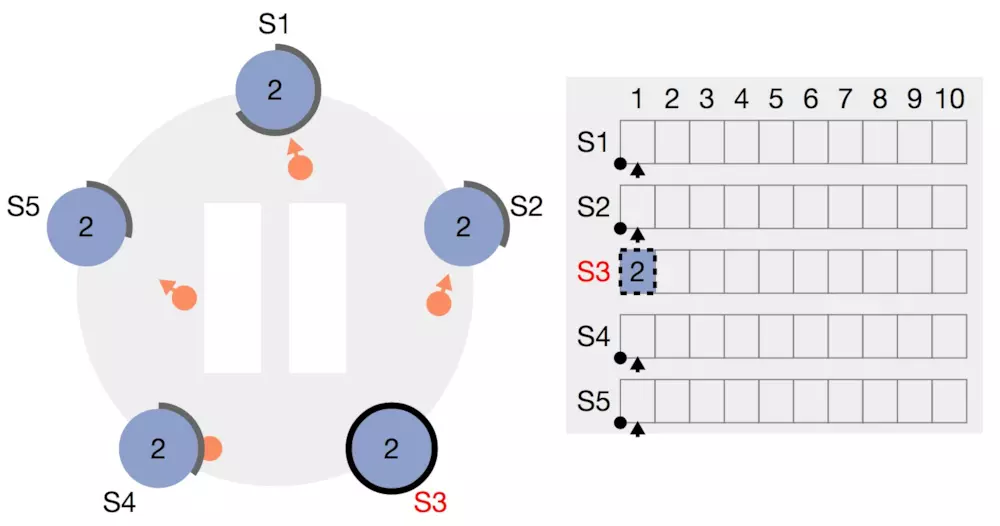
然后告诉所有的follower准备提交数据,先和我一样写log,
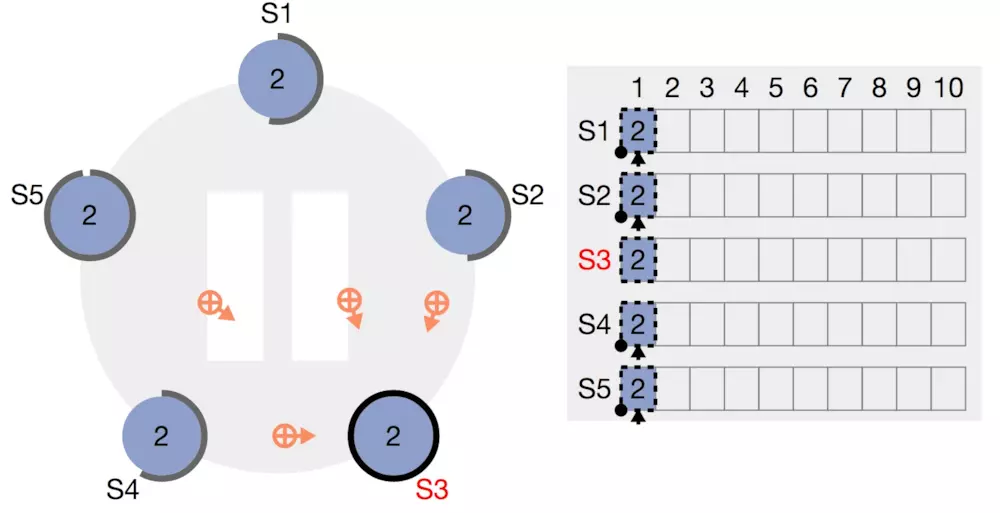
然后回到leader,此时如果超过半数的follower都成功写了log,那么leader开始第二阶段的提交:正式写入数据,然后同样广播给follower,follower也根据自身情况选择写入或者不写入并返回结果给leader。继续上面的例子,leader先写自己的数据,然后告诉follower也开始持久化数据,
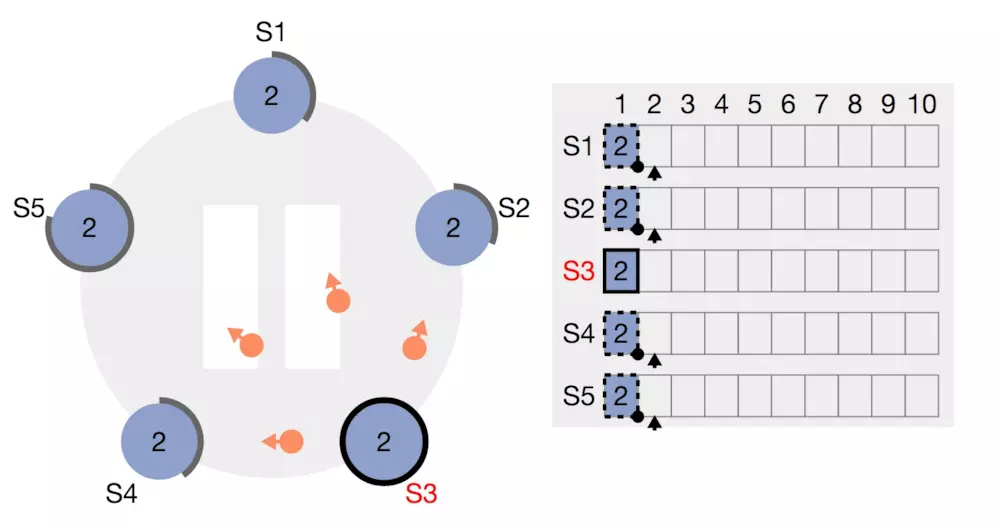
最终所有节点的数据达成一致,图中用实线表示已提交的数据。
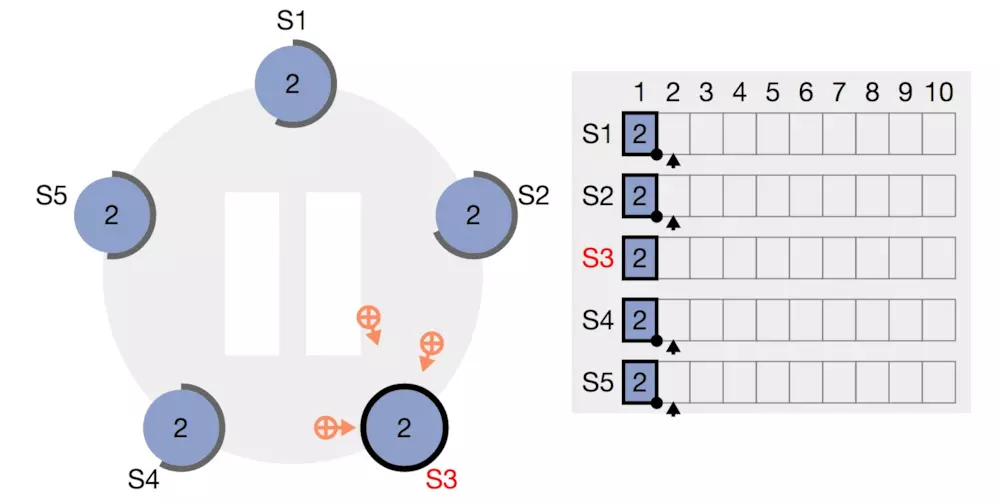
这两阶段中如果任意一个都有超过半数的follower返回false或者根本没有返回,那么这个分布式事务是不成功的。此时虽然不会有回滚的过程,但是由于数据不会真正在多数节点上提交,所以会在之后的过程中被覆盖掉。
选举的过程
上面只说了常规时候两种角色是如何协调工作的,还剩下candidate没说,对,就是一个follower是如何逆袭成为leader的。
初始状态下,大家都是平等的follower,那么follow谁呢,总要选个老大吧。大家都蠢蠢欲动,每个follower内部都维护了一个随机的timer。如下图,
在timer时间到了的时候还没有人主动联系它的话,那它就要变成candidate,同时发出投票请求(RequestVote)给其他人。特殊情况如下图,S1和S3都变成了candidate,
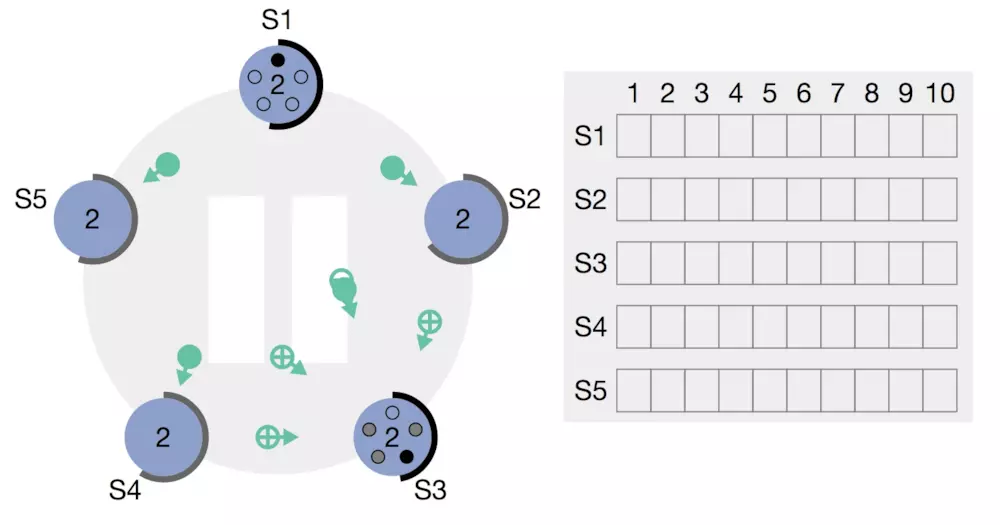
当然选不选就是人家的事了,原则是
每个follower一轮只能投一次票给一个candidate,
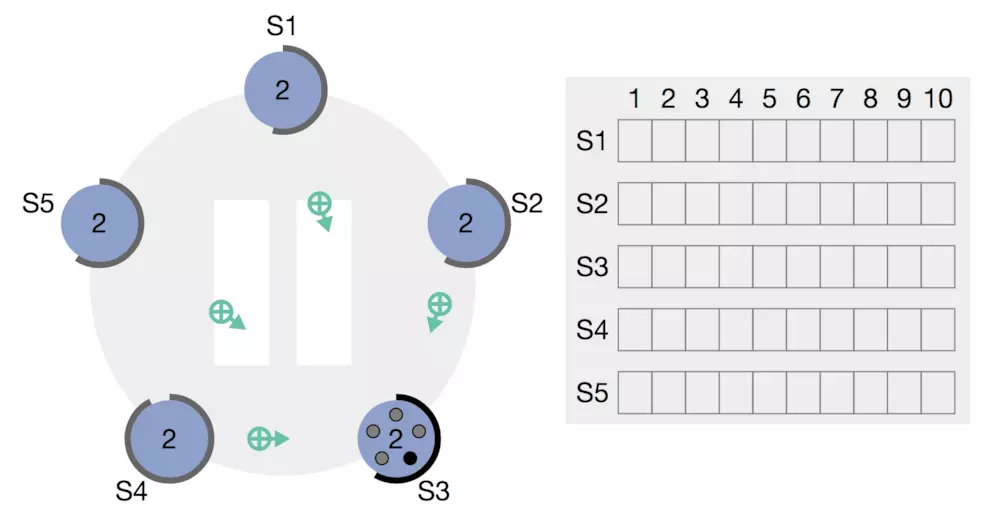
对于相同条件的candidate,follower们采取先来先投票的策略。如果超过半数的follower都认为他是合适做领导的,那么恭喜,新的leader产生了,如下图,S3变成了新一届的大哥,又可以很开心的像上一节一样的正常工作了。
但是如果很不幸,没有人愿意选这个悲剧的candidate,那它只有老老实实的变回小弟的状态。
选举完成之后,leader靠什么来确保小弟是跟着我的呢?答案是定时发送心跳检测(heart beat)。小弟们也是通过心跳来感知大哥的存在的。如下图
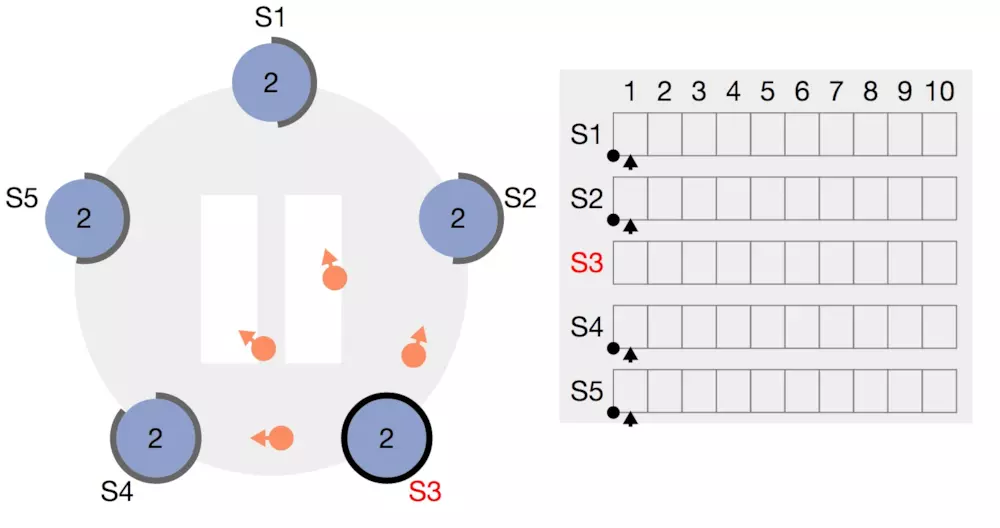
同样的,如果在timer期间内没有收到大哥的联络,这时很可能大哥已经跪了,如下图,所有小弟又开始蠢蠢欲动,新的一轮(term)选举开始了。
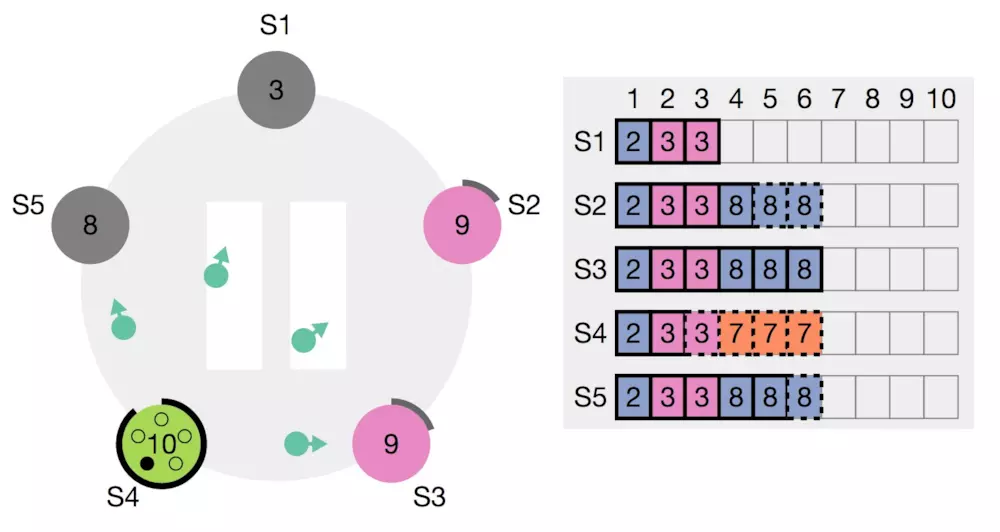
好了,Raft算法的大致原理就是这样了,下面我们来说说一些没说到的细节问题。
选举时会产生的问题
之前说过,在选举阶段,每个follower如果在自身的timer到期之后都会变成candidate去参与选举。所以就这个candidate身份而言,是没有特别条件的,每个follower都有机会参选。但是,在分布式的环境里,每个follower节点存储的数据是不一样的,考虑一下下图的情况,在这些节点经历了一些损坏和恢复。此时S4想当leader,
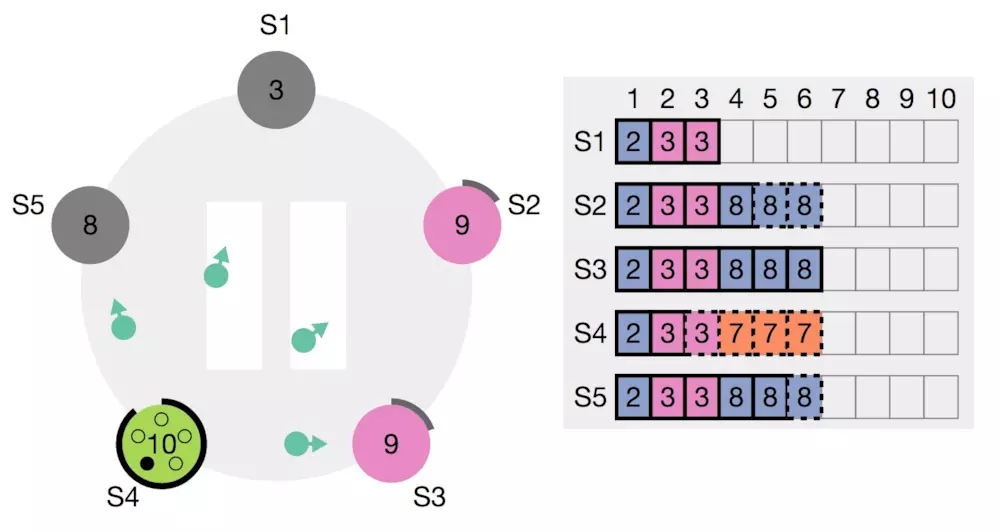
但是如果S4成功当选的话,根据leader为上的原则,S4的log在index为4-7的数据,会覆盖掉S2和S3的8。如何解决这样的冲突的问题呢?有两种方法:第一种是S4在变为大哥之前,先向所有的小弟拿数据来保证自己数据是最全的;第二种方法是其他小弟遇到这样资历不足的大哥想上位的时候,完全不予以理睬。Raft算法认为第一种策略过于复杂,所以选择了第二种,保证数据只从leader流向follower。S4在vote请求中会带上自身数据的描述信息,包括:
- term,自身处于的选举周期
- lastLogIndex,log中最新的index值
- lastLogTerm,log中最近的index是在哪个term中产生的
S2和S3在收到vote请求时候会和自身的情况进行对比,每个节点保存的数据信息包括:
- currentTerm,节点处于的term号
- log[ ],自身的log集合
- commitIndex,log中最后一个被提交的index值
对比的原则有:
- 如果term < currentTerm,也就是说candidate的版本还没我新,返回 false
- 如果已经投票给别的candidate了(votedFor),则返回false
- log匹配,如果和自身的log匹配上了,则返回true
这个log匹配原则(Log Matching Property)具体是:
如果在不同日志中的两个条目有着相同的索引和任期号,则它们所存储的命令是相同的。
如果在不同日志中的两个条目有着相同的索引和任期号,则它们之间的所有条目都是完全一样的。
这样就可以一直等到含有最新数据的candidate被选上,从而保证领导人完全原则(Leader Completeness):
如果一个日志的index在一个给定term内被提交,那么这个index一定会出现在所有term号更大的领导人中。
好了,继续看图说话。S4的vote请求,
| term | lastLogIndex | lastLogTerm |
|---|---|---|
| 10 | 6 | 7 |
被无情的拒绝。接下来S3也变成了candidate,
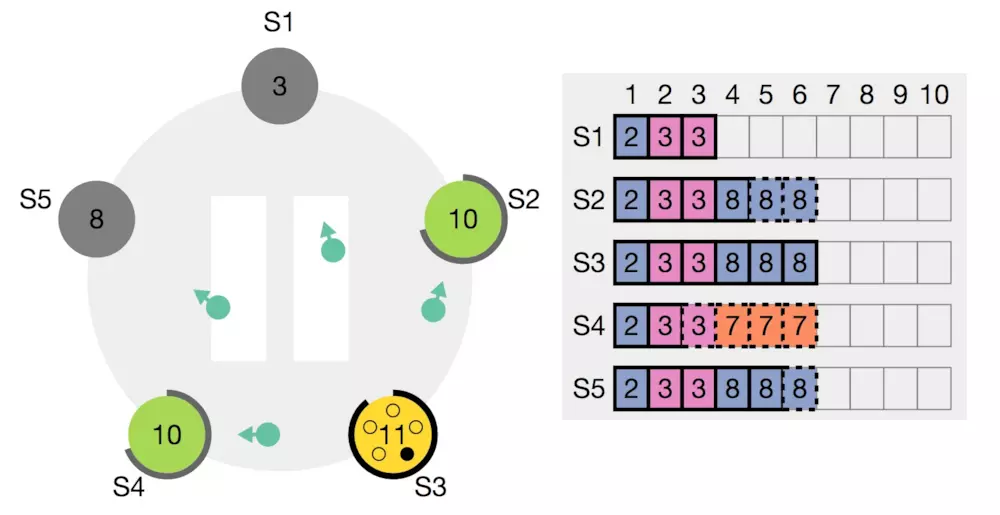
一直等到S3变成了candidate,发出vote请求。
| term | lastLogIndex | lastLogTerm |
|---|---|---|
| 11 | 6 | 8 |
被S4和S10接受,变成新的leader,并初始化两个数组:
- nextIndex[ ],表示需要发给每个follower的下一个日志条目的索引(初始化为leader最新log的index+1,因为leader总是先假定所有的follower和自己是一致的,后面说明当有不一致的时候是如何协商的)
- matchIndex[ ],表示已经复制到每个follower的log的最高index值(从0开始递增)
在这个例子中,S3中的这两个数组会初始化为,
| S1 | S2 | S4 | S5 | |
|---|---|---|---|---|
| nextIndex | 7 | 7 | 7 | 7 |
| matchIndex | 0 | 0 | 0 | 0 |
数据更新的问题
现在新的一届leader选举出来了,虽然选举的过程保证了leader的数据是最新的,但是follower中的数据还是可能存在不一致的情况。比如下图的S4,这就需要一个补偿机制来纠正这个问题。
在正常情况下,S3会给S4发心跳请求(一种名叫AppendEntries请求的特殊格式,entries为空),其中携带一些数据信息,包括,
| term | prevIndex | prevTerm | entries | commitIndex |
|---|---|---|---|---|
| 11 | 6 | 8 | [ ] | 6 |
commitIndex之前已经解释过了,是log中最后一个被提交的index值。prevIndex与lastLogIndex类似,都是最新的日志的index值,只是属于不同的请求类型。
prevTerm也与lastLogTerm类似,是prevLogIndex对应的term号。
S4在接收到该请求之后会做一致性的判断,规则包括,
- 如果 term < currentTerm返回 false
- 如果在prevLogIndex处的log的term号与prevLogTerm不匹配时,返回 false
- 如果一条已经存在的log与新的冲突(index相同但是term号不同),则删除已经存在的日志和它之后所有的日志,返回true
- 添加任何在已有的log中不存在的index,返回true
- 如果请求中leader的commitIndex > 自身的commitIndex,则比较leader的commitIndex和最新log index,将其中较小的赋给自身的commitIndex
结果与规则2不符合,返回false给S3。这时S3需要做一次退让,修改保存的nextIndex数组,将S4的nextIndex退化为6
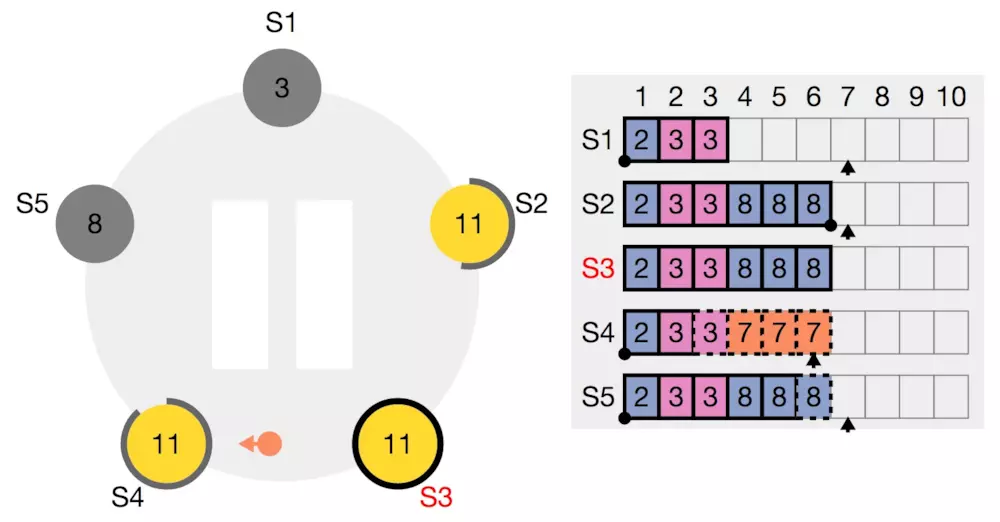
再次发送AppendEntries询问S4
| term | prevIndex | prevTerm | entries | commitIndex |
|---|---|---|---|---|
| 11 | 5 | 8 | [ ] | 5 |
如此循环的退让,一直到nextIndex减小到4
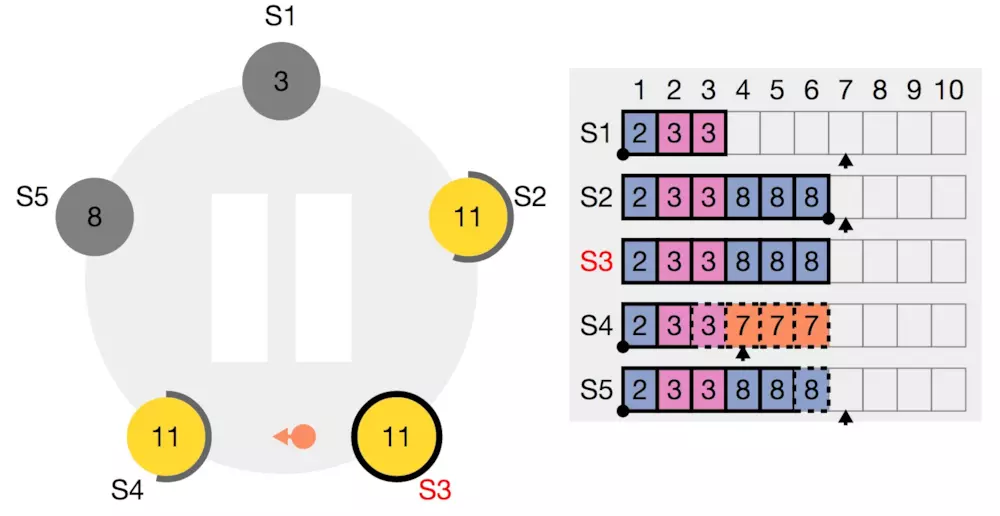
S3此时发送的请求为,
| term | prevIndex | prevTerm | entries | commitIndex |
|---|---|---|---|---|
| 11 | 3 | 3 | [ ] | 3 |
S4和自己的log匹配成功,返回true,并告诉leader,当前的matchIndex等于3。S3收到之后更新matchIndex数组,
| S1 | S2 | S4 | S5 | |
|---|---|---|---|---|
| nextIndex | 7 | 7 | 4 | 7 |
| matchIndex | 0 | 6 | 3 | 0 |
并发送从nextIndex之后的数据(entries),
| term | prevIndex | prevTerm | entries | commitIndex |
|---|---|---|---|---|
| 11 | 3 | 3 | [8] | 4 |
S4再根据覆盖的原则,把自身的数据追平leader,并抛弃之后的数据
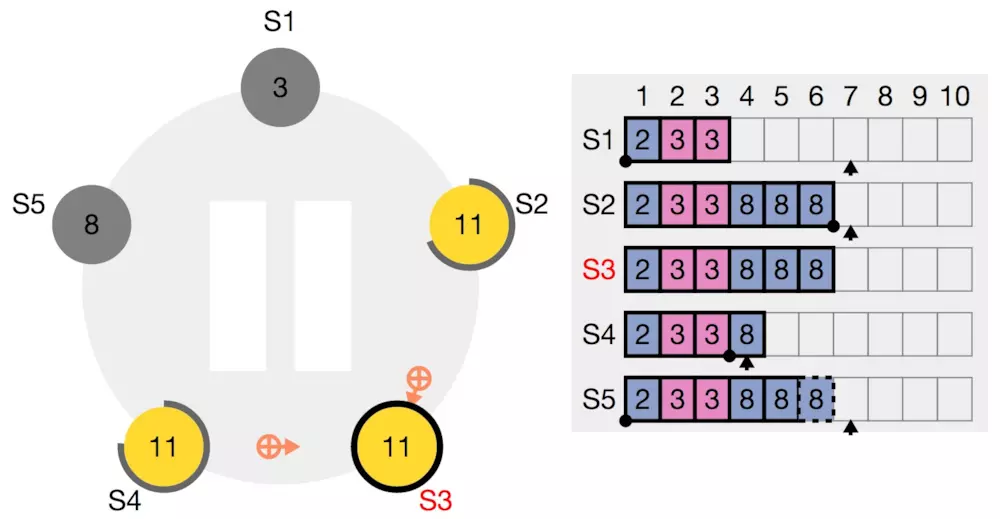
这样消息往复,数据最终一致。
一些其他的问题
还有一些值得注意的特殊情况,比如log的清理。log是以追加的方式递增的,随着系统的不断运行,log会越来越大。Raft通过log的snapshot方式,可以定期压缩log为一个snapshot,并且清除之前的log。压缩的具体策略可以参考原论文。
还有集群节点的增减。当网络发生波动的时候,节点可能需要增减甚至发生网络分区。
总结
Raft是一种基于leader选举的算法,用于保证分布式数据的一致性。所有节点在三个角色(leader, follower和candidate)之中切换。选举阶段candidate向其他节点发送vote请求,但是只有包括所有最新数据的节点可以变为leader。
在数据同步阶段,leader通过一些标记(commitIndex,term,prevTerm,prevIndex等等)与follower不断协商最终达成一致。当有新的数据产生时,采用二阶段(twp-phase)提交,先更新log,等大多数节点都做完之后再正式提交数据。
以上的图片来自github上raft算法的算法动画的截图。
