PE学习
PE文件结构
1.可执行文件
windows平台:PE(Portable Executable)文件结构
- 病毒与反病毒
- 外挂与反外挂
- 加壳与脱壳
- 无源码修改功能、软件汉化等
Linux平台:ELF(Executable and Linking Format)文件结构
2.如何识别PE结构
PE文件的特征(PE指纹)
.exe文件 .dll文件 .sys文件
上图是.exe文件例子,先看开头的4D 5A(MZ)特征,随后找到3C位置的数字为F0,再找到F0位置的50 45(PE)特征,即可判断此文件为PE结构文件。
不能仅仅通过文件后缀名来认定PE文件。
3.PE文件的整体结构
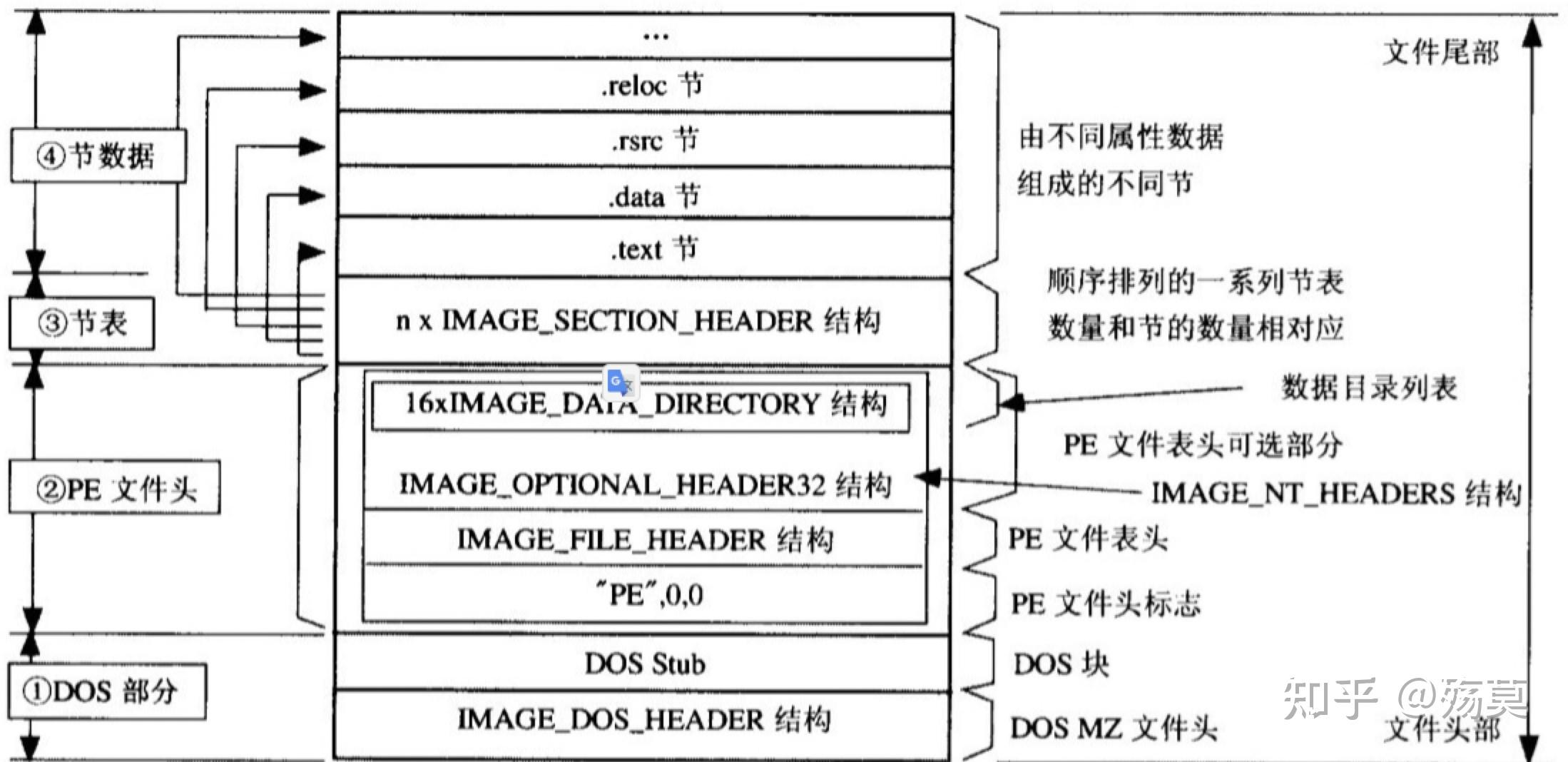
节表就像一个说明书,定义了一个个节,节数据部分存储节的内容。
PE文件的两种状态
1.主要结构体
IMAGE_DOS_HEADER结构体(DOS MZ 文件头)(64)

例子

在目前的32位和64位平台中,只有标红的两个成员有作用,其余的成员即便修改也不影响程序运行。
DOS_STUB(DOS块)

到PE头之前,可以修改,不影响运行
PE头结构体

Signature 占用四个字节,PE标识,不能改动
IMAGE_FILE_HEADER(标准PE头)(20)

characteristics文件特征

IMAGE_OPTIONAL_HEADER(拓展PE头)(224,240)

-拓展PE头大小可以修改
SizeOfHeaders大小一定是FileAlignment(文件对齐)的整数倍
IMAGE_SECTION_HEADERA(节表)(40)

VirtualSize可能比SizeOfRawData大,也可能比它小。
举例:在节中存储的没有初始值的全局变量,在文件中不分配内存,在内存中要分配内存。如果这种无初值全局变量较多,则真实大小会比在文件中对齐的大小要大。在内存中展开时按两者相对较大一方的大小展开。

2.PE文件的两种状态

在程序运行时,块的大小遵循内存对齐(SectionAligmment)。
内存对齐的目的是为了提高CPU读写内存里数据的速度。现代的CPU读取内存并不是一个一个字节挨着读取,这样做的效率非常低。现代的CPU一般以4个字节(32bit数据总线)或者8个字节(64bit数据总线)为一组,一组一组地读写内存里的数据。
内存对齐的目的是以空间换取速度,内存对齐时操作一块只需要一次读取,如果一个块分在两个内存空间,就需要进行两次读取来操作这个块,会大大降低效率。
RVA与FOA的转换
RVA(相对虚拟地址)= 内存地址 - ImageBase
FOA(文件偏移地址)
(1)判断RVA是否在头部,在的话直接返回(或文件对齐和内存对齐相同)
FOA = = RVA
(2)判断RVA位于哪个节
RVA >= 节.VirtualAddress
RVA <= 节.VirtualAddress+当前节内存对齐后的大小
差值 = RVA - 节.VirtualAdress
(3)FOA = 节.PointerToRawData + 差值
空白区添加代码
内存中 E8(call) 要跳转的地址 - E8指令当前地址 - 5
E9(jmp)
(1)构造要写入的代码
(2)在PE的空白区写入构造的代码
(3)修改入口地址为新增代码
(4)新增代码执行后,跳回原入口地址
扩大节
扩大节是为了能在空白区能加入更多的代码。
扩大节一般是扩大最后一个节。
(1)分配一块新的空间,大小为S
(2)将最后一个节的SizeOfRawData和VirtualSize改成N
N=(SizeOfRawData或VirtualSize内存对齐后的值)+ S
(3)修改SizeOfImage大小
如果节没有可执行属性,要在characteristics中修改节属性改为可执行。
SizeOfImage通常是依据VirtualSize来计算的。
新增节
(1)判断是否有足够的空间,可以增加一个节表
(2)在节表中新增一个成员
(3)修改PE头中节的数量
(4)修改SizeOfImage的大小
(5)在原有数据的最后,新增一个节的数据(内存对齐的整数倍)
(6)修正新增节表的属性
合并节
(1)按照内存对齐展开
(2)将第一个节的内存大小、文件大小改成一样
Max = SizeOfRawData > VirtualSize?SizeOfRawData:VirtualSize
SizeOfRawData = VirtualSize =
最后一个节的VirtualAddress + Max - SizeOfHeaders内存对齐后的大小
(3)将第一个节的属性改为包含所有节的属性
(4)修改节的数量为1
导出表
-
一个可执行程序是由一组PE文件组成的
-
.dll是动态链接库
-
.dll还可能用到其他的.dll
-
导出表存储的是当前的PE文件提供了哪些函数给其他文件用
-
通常情况下exe不提供导出表,但是可以提供导出表
-
dll既有导出表也有导入表
(1)如何定位导出表
导出表是PE头拓展头中的IMAGE_DATA_DIRECTORY的第一个结构体数组

导出表结构

序号表中的成员与名称表中的成员相同
序号表成员是word ,地址表和名称表成员都是dword
搜索函数过程
按名字找:函数名称表映射到序号表,再映射到地址表
没名字的函数:由导出函数起始序号向下查询,直接查询地址表

导入表
1 如何通过导入表确定依赖模块
导入表是PE头拓展头中的IMAGE_DATA_DIRECTORY的第二个结构体数组

导入表结构

导入表结束的标志是20个0(00 00 00 00 00 00 00 00 00 00)
Name成员用来描述所依赖的模块名字
Name成员指向的地址 存储模块名字的ASCII码字符串,到0截至
2 确定依赖函数
不仅要确定依赖的模块,还要确定依赖模块中的哪些函数
OriginalFirstThunk和FirstThunk指向的表不一样,但是表中的内容是一样的(pe文件加载前)
以OriginalFirstThunk为例(其中每个结构体占4字节)指向 INT表 0为结束符


Hint可能为空,编译器决定,如果不为空 则是函数在导出表中的地址索引
Name[] 函数名称,以0结尾 (函数名字长度不确定,所以只存储第一个字节)
3 确定函数地址
使用其他dll中的函数时,都使用间接call,call指向IAT表(导入地址表)
在pe文件加载后,IAT表中内容发生变化,直接指向函数地址
4 额外知识
一、结构体struct
各成员各自拥有自己的内存,各自使用互不干涉,同时存在的,遵循内存对齐原则。一个struct变量的总长度等于所有成员的长度之和。
二、联合体union
各成员共用一块内存空间,并且同时只有一个成员可以得到这块内存的使用权(对该内存的读写),各变量共用一个内存首地址。因而,联合体比结构体更节约内存。一个union变量的总长度至少能容纳最大的成员变量,而且要满足是所有成员变量类型大小的整数倍。不允许对联合体变量名U2直接赋值或其他操作。
重定位表
- 重定位表是为了防止 模块在非自身imagebase基础上展开时,模块内部地址无法正确定位
- 重定位表中会记录模块中所有需要修正的地址
- 系统每次加载都是不固定的,有了重定位表,模块就可以在内存不同位置展开,不影响使用
导入表是PE头拓展头中的IMAGE_DATA_DIRECTORY的第六个结构体数组

重定位表结构

SizeOfBlock以字节为单位,代表了当前块的大小
重定位表区以 00 00 00 00结束
每个物理页大小为4kb(2^12),所以搜索地址只需要12个二进制位
注入shellcode
shellcode是不依赖环境,放到任何地方都可以执行的机器码
编写规则:
- 不能有全局变量
- 不能使用常量字符串
- 不能使用系统调用
- 不能嵌套调用其他函数
字符串示例
char szBuffer[] = {'c','h','i','n','a','\0'}; //这样字符串数据会直接生成在堆栈里,而不是在使用时把一整个字符串从另一处mov过来
本文作者:yee-l
本文链接:https://www.cnblogs.com/yee-l/p/18232909
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步