
使用xinference快速部署本地模型
1. xinference部署
Xinference是一个可以部署本地大模型的平台,类似于ollama、localai,界面简洁操作方便,是一款很好用的本地大模型平台。
部署时可以根据自己本地的硬件条件选择部署cpu版本或者gpu版本。本文介绍使用docker方案进行部署。
cpu部署
docker run -d --restart=always --name=xinference \
-v /opt/xinference:/opt/xinference -e XINFERENCE_HOME=/opt/xinference \
-p 9997:9997 docker-registry.neuedu.com/xprobe/xinference:v0.15.2-cpu xinference-local -H 0.0.0.0
GPU部署
docker run -d --restart=always --name=xinference \
-v /opt/xinference_gpu:/opt/xinference -e XINFERENCE_HOME=/opt/xinference -e XINFERENCE_MODEL_SRC=modelscope \
-p 9998:9997 --gpus all xprobe/xinference:v0.15.3 xinference-local -H 0.0.0.0
注意:
在部署时一定要指定xinference的home文件夹,并挂载到宿主机上,否则会出现模型自己丢失的情况。笔者就遇到了两次,莫名其妙的模型就没有了。
2. 部署模型
部署之后的xinfrenece是长这样子的
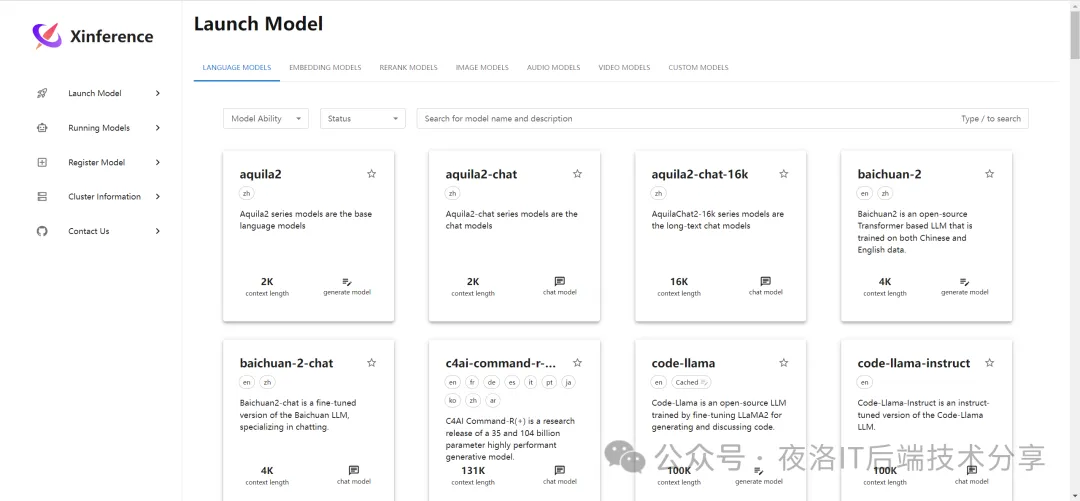
功能说明:
- launch Model:可以发现一些内置的模型,只是这些模型需要下载才可以使用,可以直接在页面上点击下载
- Running Models:正在运行的模型
- Register Model:注册模型,可以将自己微调后的模型在这里注册
- Cluster Information:集群信息,在这里可以看到当前xinference部署的宿主机的硬件信息
内置的模型类型:
- 大语言模型
- 嵌入模型
- 图像模型
- 音频模型
- 重排序模型
- 视频模型
选择自己想用的模型后就可以开始安装了,我这边以codegee4模型做演示
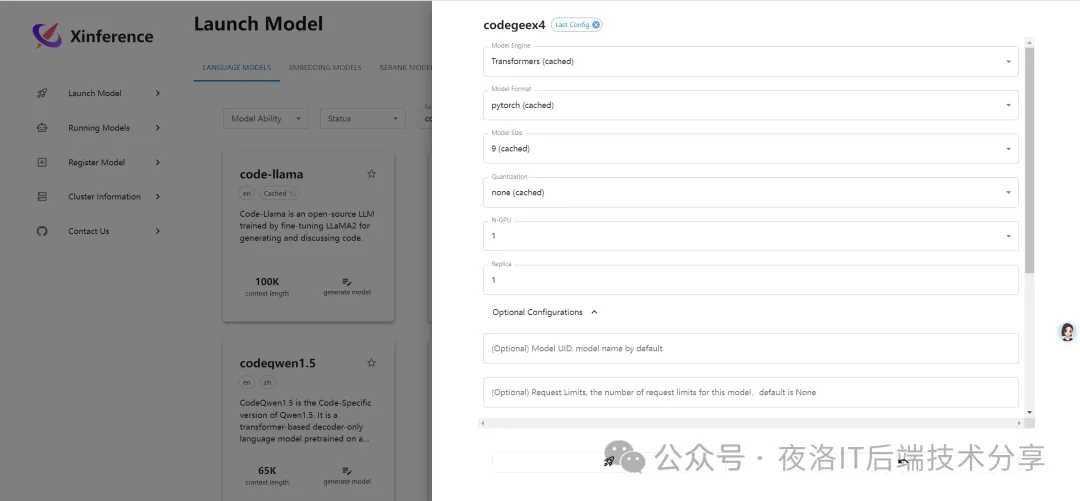
选中模型后,可以看到部署模型需要的参数
- Model Engine (模型引擎):运行模型的引擎或者框架
- Model Format (模型格式):模型训练或推理时使用的底层框架
- Model Size (模型大小):模型越大,所需的内存和计算资源也越多,单位是“十亿”
- Quantization (量化):量化通常用于减小模型大小并加速推理
- N-GPU (GPU数量):模型允许使用几个GPU
- Replica (副本数量):这通常与横向扩展有关,更多副本意味着可以处理更多并发请求。
同时在Optional Configuration中需要选择一下Dowload_hub,笔者这里链接不上huggingface,所以是从modelscope上下载的。
添加完配置后就可以进行下载了
点击部署后,通过日志docker logs -f xinference查看模型安装进度,会在日志里显示进度条
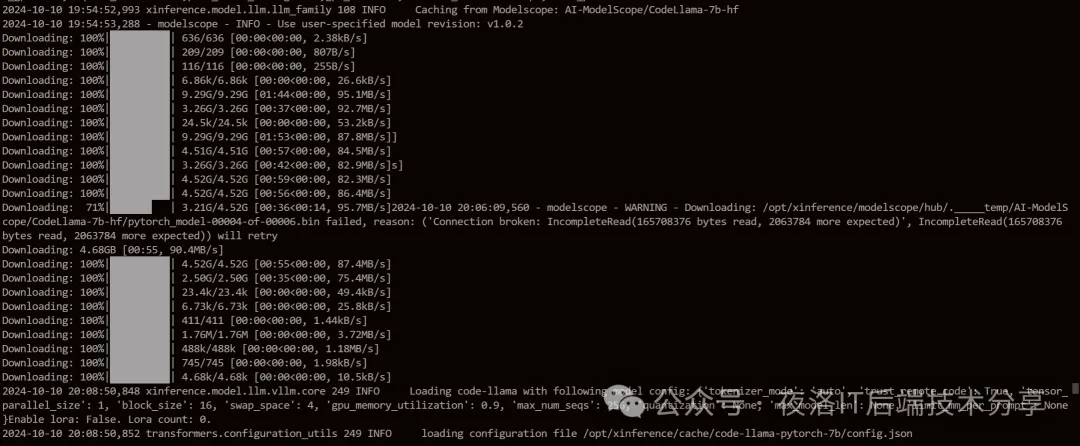
因为一般大语言模型都比较大,所以需要等待较长时间。
3. 模型试用
部署完模型后,可以在Running Model中看到运行的模型
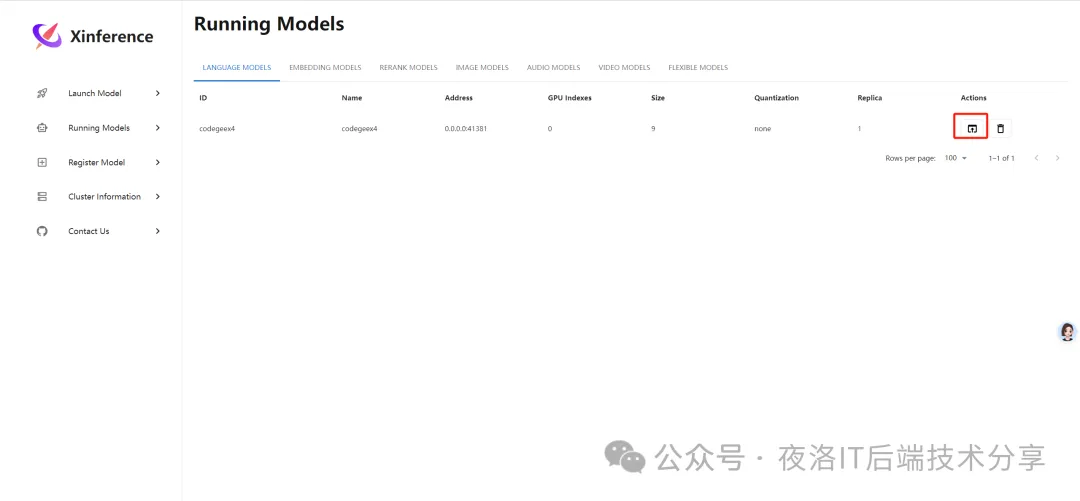
然后点击actions中红框的图标,就可以对模型进行适用啦
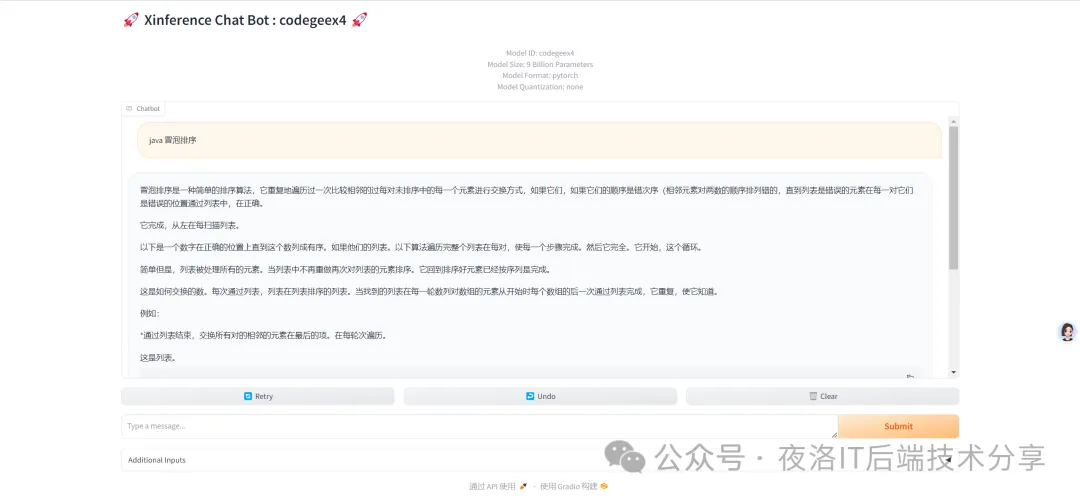
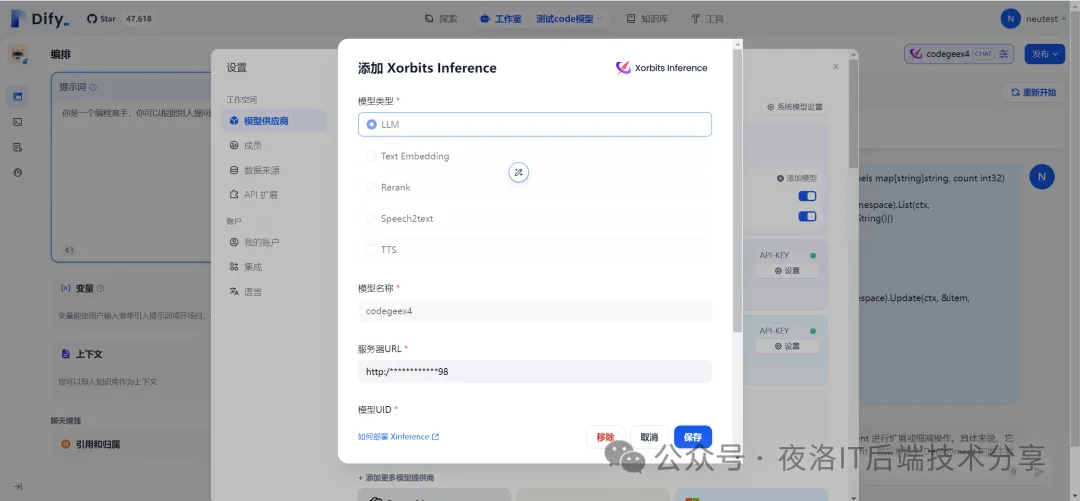
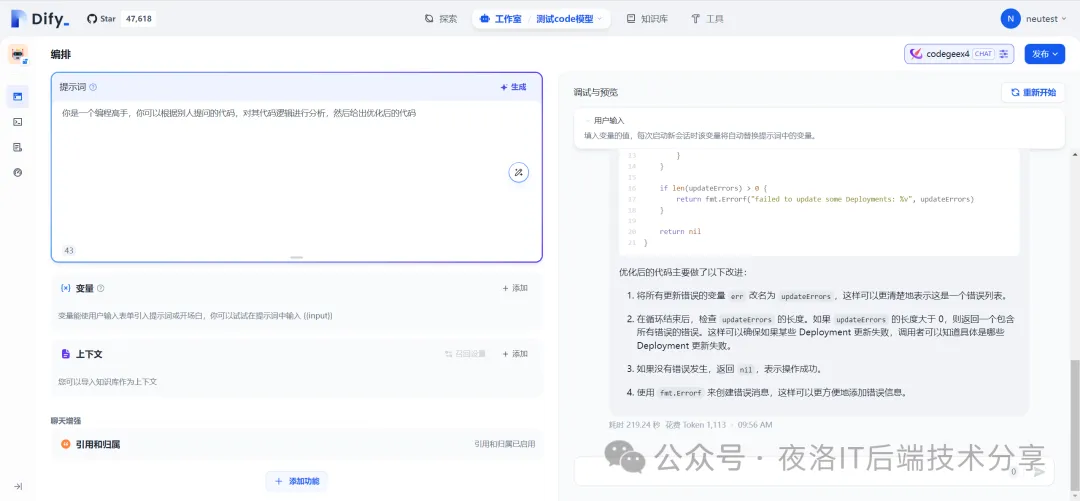
也可以集成到一些对接大模型的AI应用平台上进行更复杂的功能使用,比如笔者这里就是集成到dify中使用的。
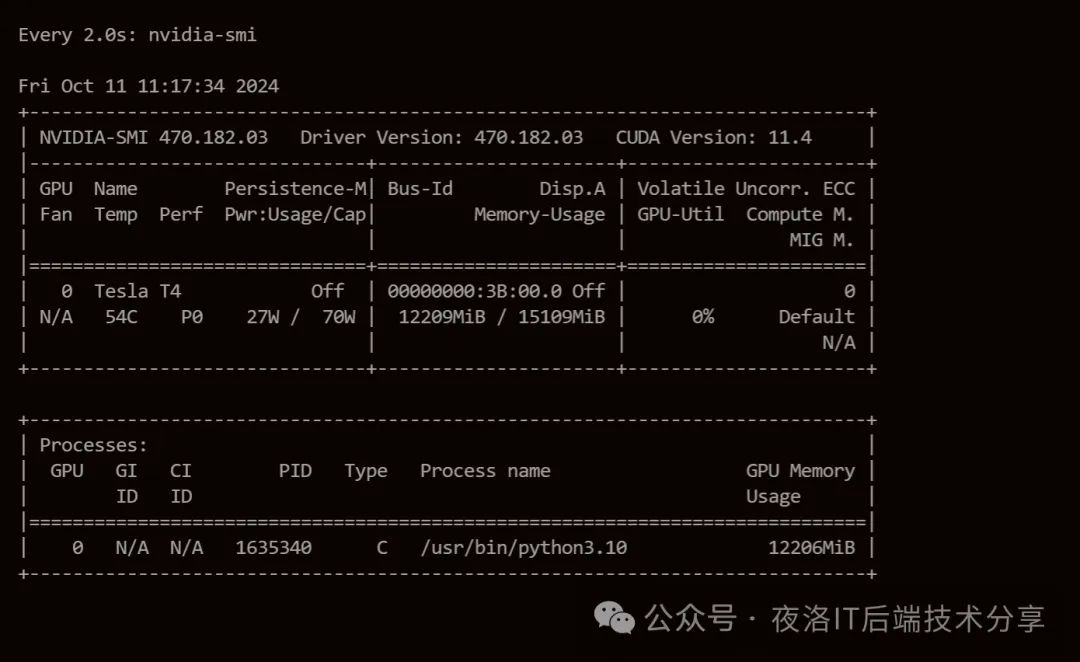
最后提醒大家一下,很多大语言模型所需要的GPU显存都是比较大的,大家在安装过程中,如果发现显存不够用,可能就需要换其他小一点的模型,或者单纯的使用CPU的模型了。
可以通过 watch nvidia-smi 监控一下显存。
参考地址:https://inference.readthedocs.io/zh-cn/latest/index.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号