python实现python代码的分析——包含总代码行数,纯注释的行数、空白行数、有效代码行、最大缩进层级、if、for、while、try等语句的数量、函数定义分析、平均每个函数的平均代码行数、列出所有变量名、变量名的平均长度
- 要求完成情况(均已完成)
- 1 文件处理类class FileProcess(object)
- 2 代码分析类class CodeAnalysis(object)
- 2.1 初始化代码分析的属性
- 2.2 统计代码行数方法def count_code(self)
- 2.3 判断是不是有效代码方法def judge_is_effective_code(self, content_str)
- 2.4 分析代码缩进,统计包含的if、for、while、try等语句的数量的方法def analyzing_indentation(self)
- 2.5 分析函数定义的方法def analyzing_functions_definition(self)
- 2.5 分析变量名的方法def analyzing_variables(self)
- 2.6 打印代码分析结果方法def print_information(self)
- 2.7 启动方法def run(self)及其实例化调用示例
- 3 结果展示
要求完成情况(均已完成)
1 文件处理类class FileProcess(object)
1.1 以每行字符串的形式,加载.py文件内容到列表中
根据python文件的路径,把.py的代码内容加载到列表中并return,加载为每一行为字符串的格式
完整代码为:
class FileProcess(object):
"""文件处理的类"""
def __init__(self, file_path):
"""
file_path 为python文件完整的绝对/相对路径,例如"homework1.py”
"""
self.file_path = file_path # 文件路径
def read_py_data(self):
"""加载python数据"""
with open(self.file_path, 'r', encoding='utf-8') as fp:
_content_list = fp.readlines()
print(f"_content_list:{_content_list}")
return _content_list
2 代码分析类class CodeAnalysis(object)
这个类主要用于分析代码,包含了分析代码的各种属性和方法
2.1 初始化代码分析的属性
这一步是初始化代码分析类的属性,传入的参数为1.1中文件处理类加载python数据方法返回的内容列表,包含的属性有:
| 属性 | 含义 | 数据结构类型type |
|---|---|---|
| self.py_content_list | python内容列表 | 列表list |
| self.total_lines | 总代码行数 | 整形Int |
| self.comment_lines | 纯注释行数 | 整形Int |
| self.blank_lines | 空白行数 | 整形Int |
| self.effective_lines | 有效代码行数 | 整形Int |
| self.effective_lines_total_length | 有效代码行的总长度 | 整形Int |
| self.effective_lines_average_length | 有效代码行的平均长度 | 整形Int |
| self.max_indent_level | 最大缩进层级 | 整形Int |
| self.if_number | if语句数量 | 整形Int |
| self.for_number | for语句数量 | 整形Int |
| self.while_number | while语句数量 | 整形Int |
| self.try_number | try语句数量 | 整形Int |
| self.functions_dict= {} | 函数名和代码行数字典,字典的键用来存储函数名,字典的值用来存储对应的代码行数 | 字典dict |
| self.functions_codes_average_lines | 平均每个函数的平均代码行数 | 整形Int |
| self.variable_name_dict = {} | 变量名字典,字典的键用来存储变量名,字典的值用来存储对应的变量名的长度 | 字典dict |
| self.variable_name_average_length | 变量名的平均长度 | 整形Int |
| self.is_multi_line_comment_for_judge | judge_is_effective_code方法要用到的属性 | 刚开始是None,后面是bool类型 |
完整代码为:
def __init__(self, py_content_list):
"""python内容列表"""
self.py_content_list = py_content_list
"""代码行数"""
self.total_lines = 0 # 总代码行数
self.comment_lines = 0 # 纯注释行数
self.blank_lines = 0 # 空白行数
self.effective_lines = 0 # 有效代码行数(非空白、非纯注释),其实可以 有效代码行数=总代码行数-纯注释行数-空白行数
self.effective_lines_total_length = 0 # 有效代码行的总长度
self.effective_lines_average_length = 0 # 有效代码行的平均长度
"""最大缩进层级"""
self.max_indent_level = 0 # 最大缩进层级
"""各语句数量"""
self.if_number = 0 # if语句数量
self.for_number = 0 # for语句数量
self.while_number = 0 # while语句数量
self.try_number = 0 # try语句数量
"""分析函数定义"""
self.functions_dict = {} # 函数名和代码行数字典,字典的键用来存储函数名,字典的值用来存储对应的代码行数
self.functions_codes_average_lines = 0 # 平均每个函数的平均代码行数
"""列出所有变量名,计算变量名的平均长度"""
self.variable_name_dict = {} # 变量名字典,字典的键用来存储变量名,字典的值用来存储对应的变量名的长度
self.variable_name_average_length = 0 # 变量名的平均长度
"""judge_is_effective_code方法要用到的属性"""
self.is_multi_line_comment_for_judge = None
2.2 统计代码行数方法def count_code(self)
这个方法的作业是统计代码行数,判断的方法为:
- 遍历.py文件内容列表,一行一行看,并且移除字符串头尾的空格
- 首先根据"""判断是不是多行注释,如果是多行注释:
- 就一直检测到多行注释结束,并记录为注释行。
- 如果不是多行注释:
- 根据""判断是不是空行
- 根据#判断是不是单行注释
- 如果以上都不是,就是有效代码行
完整代码为:
def count_code(self):
"""统计代码行数"""
is_multi_line_comment = False
for content in self.py_content_list:
content = content.strip() # 移除字符串头尾指定的字符(默认为空格),换行符好像也会被移除
self.total_lines = self.total_lines + 1
# 多行注释"""开始
if is_multi_line_comment:
# 判断多行注释有没有结束
if content.endswith("'''") or content.endswith('"""'):
is_multi_line_comment = False
# 物理多行注释有没有结束,都是注释行
self.comment_lines += 1 # 纯注释行
# 还没开始多行注释
else:
# 如果开始是"""结尾不是“”“,多行注释开始。但要防止一种只有单行“”“的情况
# 单行“”“的情况
if (content.startswith("'''") or content.startswith('"""')) and len(content) == 3:
is_multi_line_comment = True
self.comment_lines += 1 # 纯注释行
else:
# 如果开始是"""结尾不是“”“,多行注释开始。
if (content.startswith("'''") or content.startswith('"""')) and not (
content.endswith("'''") or content.endswith('"""')):
is_multi_line_comment = True
self.comment_lines += 1 # 纯注释行
# 开始是"""结尾是“”“,只能算单行注释
elif (content.startswith("'''") or content.startswith('"""')) and (
content.endswith("'''") or content.endswith('"""')):
self.comment_lines += 1 # 纯注释行
# 判断空白行
elif content == '': # 空白行
self.blank_lines += 1
# 判断#的单行注释
elif content.startswith('#'): # .startswith用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False
self.comment_lines += 1 # 纯注释行
# 剩下的是有效代码行
else: # 有效代码行
self.effective_lines += 1
self.effective_lines_total_length = len(content) + self.effective_lines_total_length # 有效代码行总长度
# 有效代码行的平均长度
self.effective_lines_average_length = int(self.effective_lines_total_length / self.effective_lines)
2.3 判断是不是有效代码方法def judge_is_effective_code(self, content_str)
传入的是每一行的字符串,如果是有效代码返回True,否则返回Flase。这个方法后面的函数会重复调用。
判断方法和2.2类似,只是不需要遍历内容列表,只需要针对一行的内容进行判断。
除了判断到有效代码时返回True,其它情况都返回Flase
完整代码为:
def judge_is_effective_code(self, content_str):
"""
判断是否是有效代码
:param content_str: 一行字符串
:return: 是的话返回True,否则返回Flase
"""
content = content_str
content = content.strip() # 移除字符串头尾指定的字符(默认为空格),换行符好像也会被移除
# 多行注释"""开始
if self.is_multi_line_comment_for_judge:
# 判断多行注释有没有结束
if content.endswith("'''") or content.endswith('"""'):
self.is_multi_line_comment_for_judge = False
return False
# 还没开始多行注释
else:
# 如果开始是"""结尾不是“”“,多行注释开始。但要防止一种只有单行“”“的情况
# 单行“”“的情况
if (content.startswith("'''") or content.startswith('"""')) and len(content) == 3:
self.is_multi_line_comment_for_judge = True
return False
else:
# 如果开始是"""结尾不是“”“,多行注释开始。
if (content.startswith("'''") or content.startswith('"""')) and not (
content.endswith("'''") or content.endswith('"""')):
self.is_multi_line_comment_for_judge = True
return False
# 开始是"""结尾是“”“,只能算单行注释
elif (content.startswith("'''") or content.startswith('"""')) and (
content.endswith("'''") or content.endswith('"""')):
return False
# 判断空白行
elif content == '': # 空白行
return False
# 判断#的单行注释
elif content.startswith('#'): # .startswith用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False
return False
# 剩下的是有效代码行
else: # 有效代码行
return True
2.4 分析代码缩进,统计包含的if、for、while、try等语句的数量的方法def analyzing_indentation(self)
基本的判断流程为:
-
遍历整个内容列表
-
首先确保是有效代码(即2.3的def judge_is_effective_code(self, content_str)方法)
-
然后计算缩进的层级,计算缩进层级的方法为:
先获取缩进的空格数,然后根据缩进的空格数/4就是缩进层级
-
计算完缩进层级后,把字符串首位的空格用strip()都去掉
-
根据startswith()方法检测字符串,注意下面判断字符串时后面要加个空格,不然会判断到别的单词:
- 如果开头字符串是“if ”,就判定为if语句
- 如果开头字符串是“for ”,就判定为for语句
- 如果开头字符串是“while ”,就判定为while语句
- 如果开头字符串是“try ”,就判定为try语句
完整代码为:
def analyzing_indentation(self):
"""分析代码缩进,统计包含的if、for、while、try等语句的数量"""
self.is_multi_line_comment_for_judge = False
for content in self.py_content_list:
# 先确保是有效代码
if self.judge_is_effective_code(content_str=content):
"""缩进层级"""
_indent_blank_length = len(content) - len(content.lstrip())
if int(_indent_blank_length / 4) > self.max_indent_level:
self.max_indent_level = int(_indent_blank_length / 4)
"""各语句数量,记得后面要加个空格,不然会判断到别的语句"""
content = content.strip()
if content.startswith("if "):
self.if_number = self.if_number + 1
elif content.startswith("for "):
self.for_number = self.for_number + 1
elif content.startswith("while "):
self.while_number = self.while_number + 1
elif content.startswith("try "):
self.try_number = self.try_number + 1
else:
pass
2.5 分析函数定义的方法def analyzing_functions_definition(self)
这个函数的方法是分析函数的定义,也就是函数名以及对应的代码行数,以及平均每个函数的平均代码行数,基本流程为:
-
初始化一些变量标记位,包括是否进入了函数、函数代码长度、函数缩进长度、函数名
-
遍历整个py内容列表
-
先计算某一行的代码缩进长度
-
检测是否进入了函数,检测方法如下:
字符串清掉首尾空格,如果字符串开头是以"def "的形式开头,说明是函数名,这时候说明进入了函数,改变是否进入函数的标志位,并且获取到了函数的缩进长度
-
检测是否退出了函数,检测方法如下:
根据每一次记录的某一行的 代码缩进长度和函数缩进长度进行对比,因为函数的缩进比下一行内容的缩进小,则还在函数内,否则就已经不是在这个函数行内。这个时候就把函数名,以及函数代码长度保存到字典中self.functions_dict[f"{function_name}"] = function_code_length。并且重新初始化标志位等等。
注意:因为在同一份代码中,有可能不同的class类中会有相同的方法函数名,所以代码还加了检测字典中已经有了相同函数名的key,来判断是否有重名函数,如果有重名函数还会标记出来。
-
最后是平均每个函数的平均代码行数,这时候把所有函数的代码长度相加/函数个数 即可
完整代码为:
def analyzing_functions_definition(self):
"""分析函数定义"""
self.is_multi_line_comment_for_judge = False
is_enter_function = False # 是否进入了函数
function_code_length = 1 # 函数代码长度,加上定义的一行默认是1开始
function_indent_length = 0 # 函数的缩进长度,用来判断进入函数是否结束
function_name = None # 函数名称
for content in self.py_content_list:
_content_indent_length = len(content) - len(content.lstrip()) # 这一行代码缩进长度
# 如果进入了函数
if is_enter_function:
"""判断函数的代码长度,根据缩进比较判断函数是否结束,不结束就行数+1"""
# 函数的缩进比下一行内容的缩进小,则还在函数内
if function_indent_length < _content_indent_length:
function_code_length = function_code_length + 1
# 否则不在函数内,重新初始化
else:
"""先把函数名和函数长度存到字典"""
# 如果字典中已经有了相同函数名的key
if function_name in self.functions_dict.keys():
self.functions_dict[f"有重名函数,这是第{len(self.functions_dict) + 1}个函数的{function_name}"] = function_code_length
else:
self.functions_dict[f"{function_name}"] = function_code_length
"""然后初始化"""
is_enter_function = False # 是否进入了函数
function_code_length = 1 # 函数代码长度,加上定义的一行默认是1开始
function_indent_length = 0 # 函数的缩进长度,用来判断进入函数是否结束
content = content.strip() # 清掉空格
if content.startswith("def "):
function_name = content # 函数名
is_enter_function = True # 进入了函数
function_indent_length = _content_indent_length # 函数缩进长度
else:
content = content.strip() # 清掉空格
if content.startswith("def "):
function_name = content # 函数名
is_enter_function = True # 进入了函数
function_indent_length = _content_indent_length # 函数缩进长度
# 计算平均每个函数的平均代码行数
functions_codes_total_lines = 0
for key, value in self.functions_dict.items():
functions_codes_total_lines = functions_codes_total_lines + value
self.functions_codes_average_lines = int(functions_codes_total_lines / len(self.functions_dict)) # 平均每个函数的平均代码行数
2.5 分析变量名的方法def analyzing_variables(self)
分析变量名的方法基本流程如下:
- 首先遍历整个py内容列表
- 再判断是否是有效代码(即2.3的def judge_is_effective_code(self, content_str)方法)
- 如果是有效代码,清掉首尾空格,然后获取字符串的“=”个数,注意:包含1个“=”的content说明存在变量名,但是两个“==”的情况是判断语句,这时候不是变量名。如果是相同的变量名直接覆盖即可,不需要重复
- 如果是变量名,根据split("=")分割字符串,再把空格去掉,列表第一个就是变量名了,这时候把变量名和变量名长度保存到字典中self.variable_name_dict[f"{_content_list[0]}"] = len(_content_list[0])
- 最后是计算变量名的平均长度,这时候把所有变量名长度相加/变量名个数 即可
完整代码为:
def analyzing_variables(self):
"""分析变量名"""
self.is_multi_line_comment_for_judge = False
for content in self.py_content_list:
# 先确保是有效代码
if self.judge_is_effective_code(content_str=content):
content = content.strip() # 清掉空格
# 包含1个“=”的content说明存在变量名,但是两个“==”的情况是判断语句,这时候不是变量名。如果是相同的变量名直接覆盖即可,不需要重复
if content.count("=") == 1: # 如果只包含1个"="
_content_list = content.split("=") # 根据=分割字符串,再把空格去掉,列表第一个就是变量名了
_content_list[0] = _content_list[0].strip() # 清掉空格
self.variable_name_dict[f"{_content_list[0]}"] = len(_content_list[0])
# 计算变量名的平均长度
variable_name_total_length = 0
for key, value in self.variable_name_dict.items():
variable_name_total_length = variable_name_total_length + value
self.variable_name_average_length = int(variable_name_total_length / len(self.variable_name_dict)) # 平均每个函数的平均代码行数
2.6 打印代码分析结果方法def print_information(self)
这个方法是把相应的代码分析结果显示在终端上
完整代码为:
def print_information(self):
"""打印代码分析结果"""
print(f"分析的结果为:")
print(
f"总代码行数为:{self.total_lines},纯注释行数为:{self.comment_lines},空白行数为:{self.blank_lines},"
f"有效代码行数为:{self.effective_lines},有效代码行的平均长度:{self.effective_lines_average_length}")
print(f"最大缩进层级为:{self.max_indent_level}")
print(f"if语句数量为:{self.if_number},for语句数量为:{self.for_number},while语句数量为:{self.while_number},"
f"try语句数量为:{self.try_number}")
print(f"\n函数定义情况及其代码行数为:")
for key, value in self.functions_dict.items():
print(f"函数名为:{key},对应的函数代码行数为:{value}")
print(f"平均每个函数的平均代码行数为:{self.functions_codes_average_lines}")
print(f"\n所有的变量名及其变量名长度为:")
for key, value in self.variable_name_dict.items():
print(f"变量名为:{key},对应的变量名长度为:{value}")
print(f"变量名的平均长度为:{self.variable_name_average_length}")
2.7 启动方法def run(self)及其实例化调用示例
为了方便启动各个分析代码,加了个启动方法函数。
启动方法的完整代码:
def run(self):
self.count_code()
self.analyzing_indentation()
self.analyzing_functions_definition()
self.analyzing_variables()
self.print_information()
实例化调用的代码示例:
file_path1 = "..\\homework1\\homework1.py"
print(
f"\n————————————————————————————————————————————python代码{file_path1}分析情况————————————————————————————————————————————")
FileProcess_obj = FileProcess(file_path=file_path1)
content_list = FileProcess_obj.read_py_data()
CodeAnalysis_obj = CodeAnalysis(py_content_list=content_list)
CodeAnalysis_obj.run()
file_path2 = "..\\homework2\\homework2.py"
print(
f"\n————————————————————————————————————————————python代码{file_path2}分析情况————————————————————————————————————————————")
FileProcess_obj2 = FileProcess(file_path=file_path2)
content_list2 = FileProcess_obj2.read_py_data()
CodeAnalysis_obj2 = CodeAnalysis(py_content_list=content_list2)
CodeAnalysis_obj2.run()
file_path3 = "..\\homework3\\homework3.py"
print(
f"\n————————————————————————————————————————————python代码{file_path3}分析情况————————————————————————————————————————————")
FileProcess_obj3 = FileProcess(file_path=file_path3)
content_list3 = FileProcess_obj3.read_py_data()
CodeAnalysis_obj3 = CodeAnalysis(py_content_list=content_list3)
CodeAnalysis_obj3.run()
3 结果展示
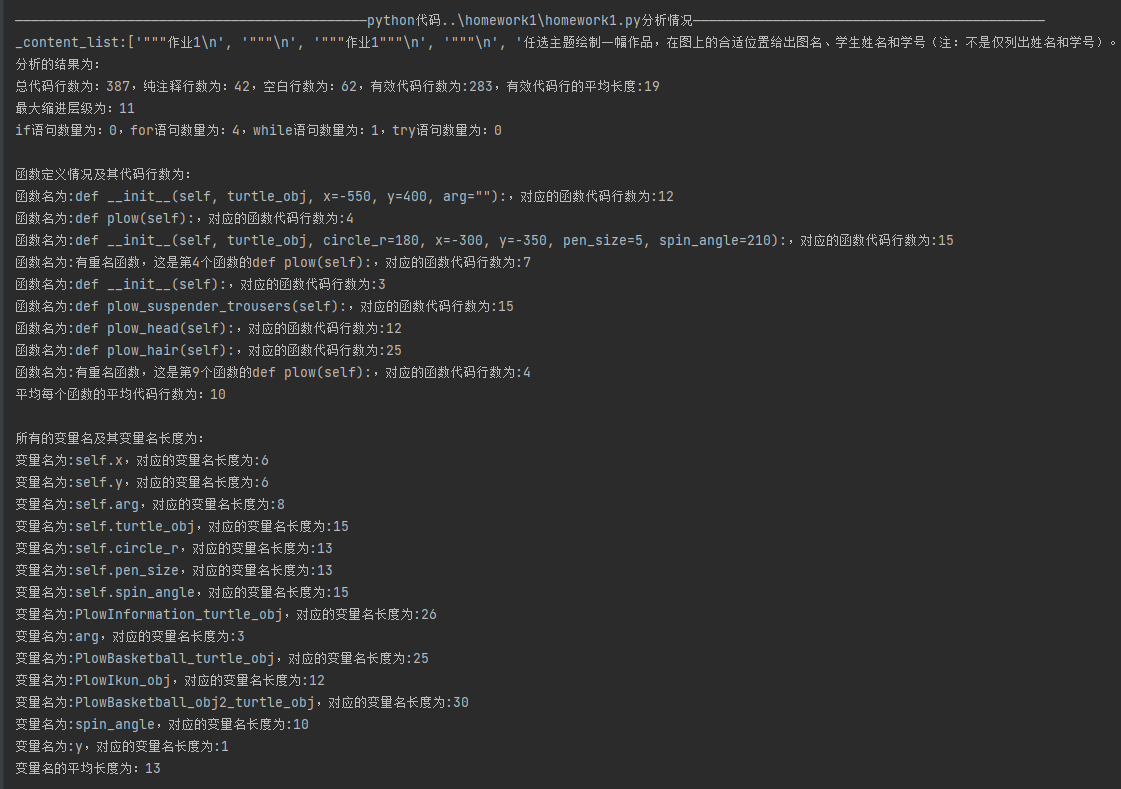
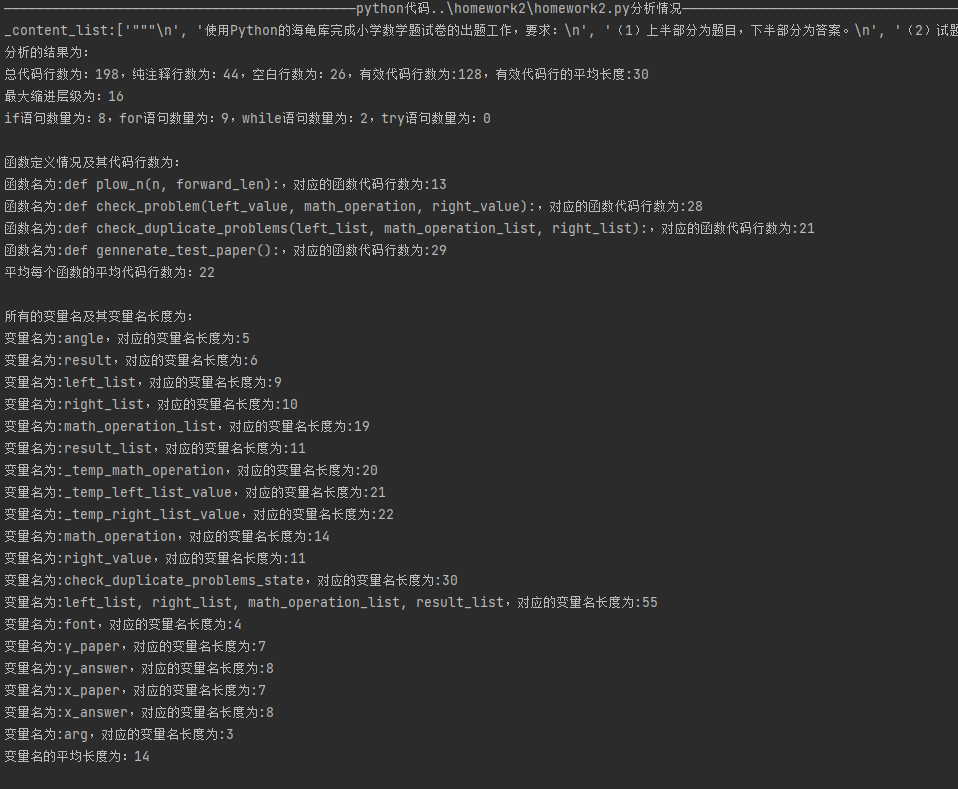
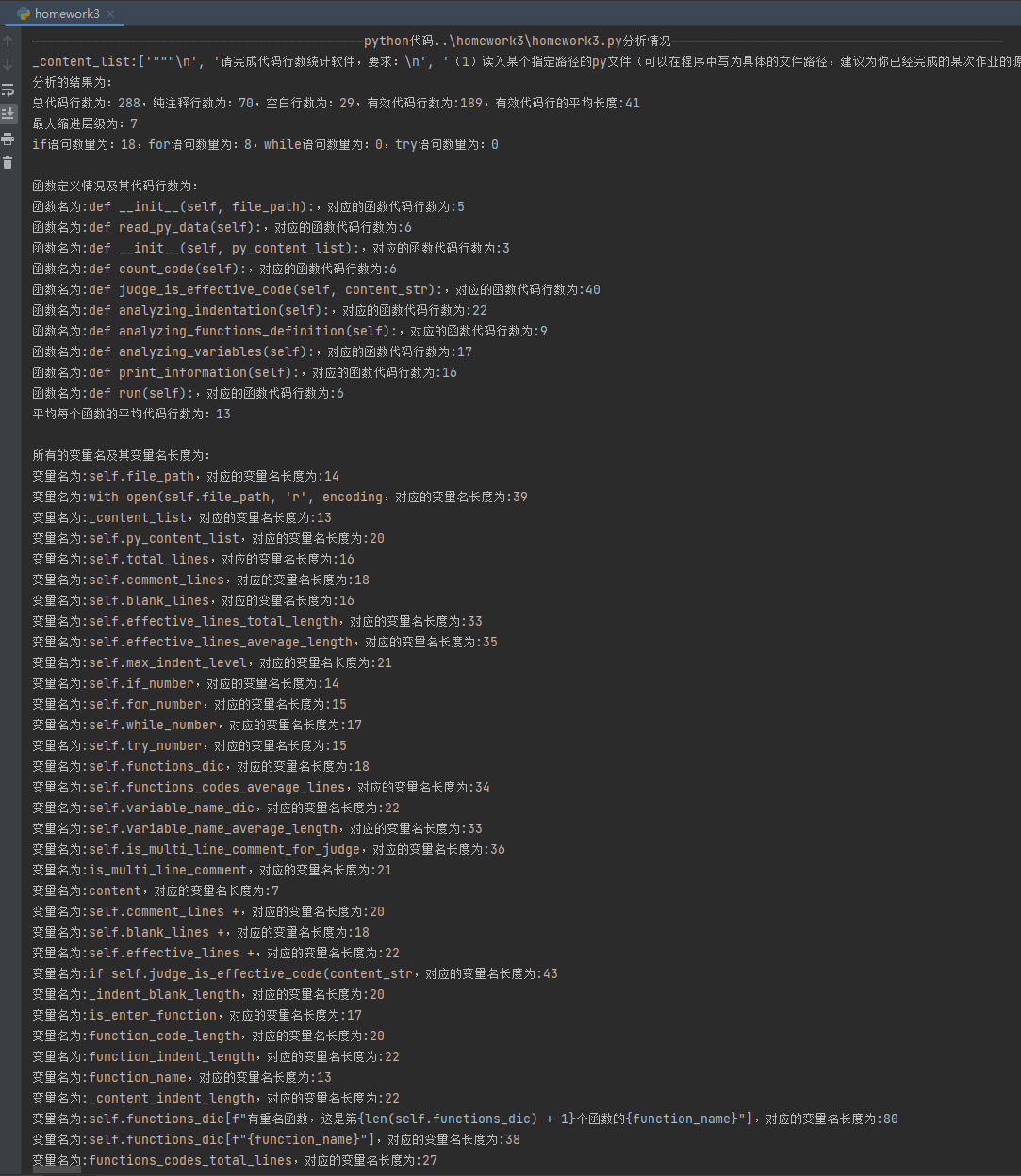
本文来自博客园,作者:JaxonYe,转载请注明原文链接:https://www.cnblogs.com/yechangxin/articles/17259454.html
侵权必究
 浙公网安备 33010602011771号
浙公网安备 33010602011771号