MyISAM和InnoDB的区别
一、数据存储引擎
二、为什么最常用的数据库存储引擎是Innodb
Innodb存储引擎提供了事务安全的支持、回滚、行级锁,提高并发量。正是这些特性使得Innodb存储引擎成为最常用的存储引擎。
三、MyISAM和InnoDB的区别
3.1、索引的区别
(1)MyISAM存储引擎的索引
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。通过地址可以快速的获取到对应的记录。并且主键索引和辅助索引没有任何结构上的区别,唯一不同的是辅助索引 的key值可以重复,不具有唯一性。myISAM不存在回表查找。
主键索引的结构
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
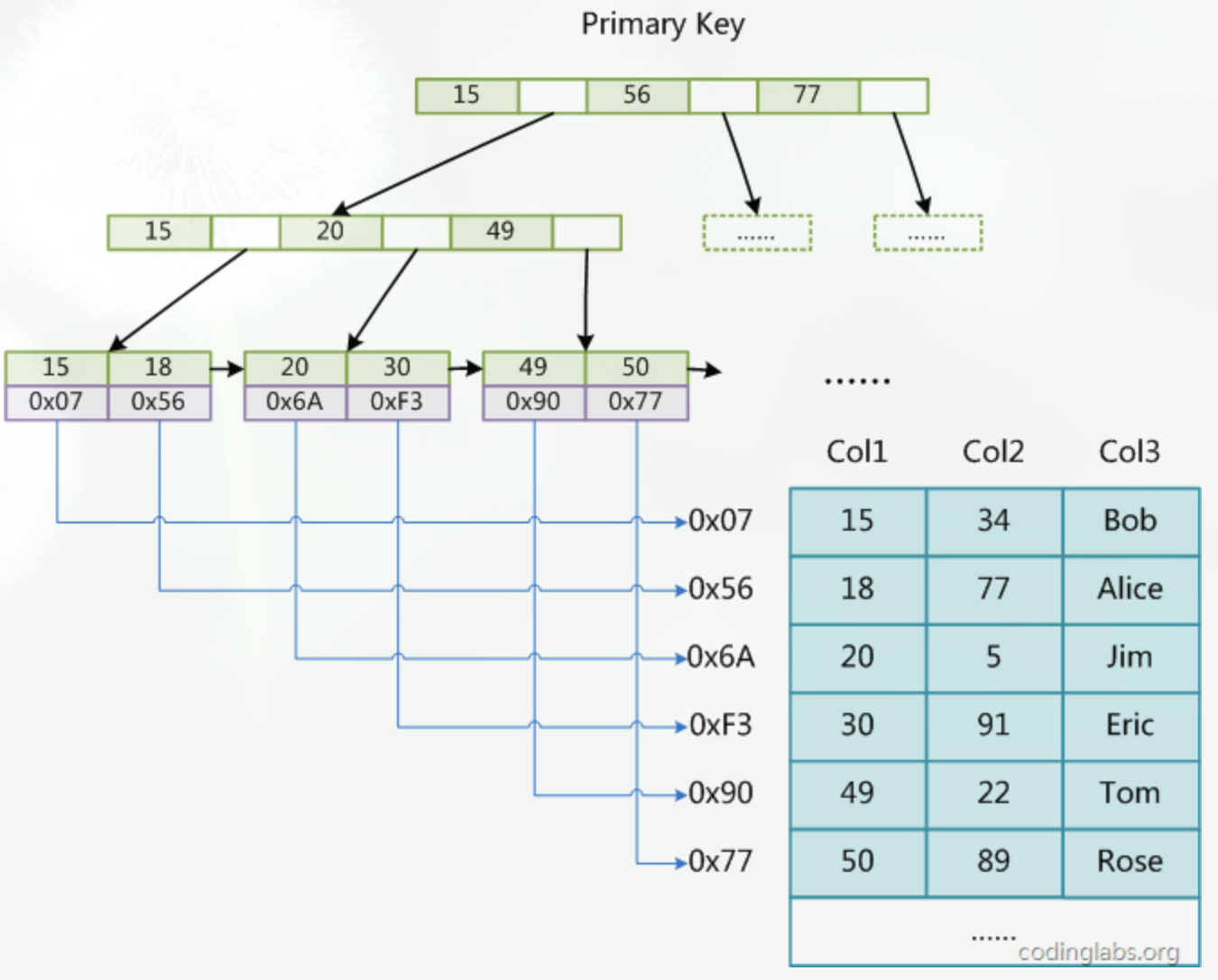
辅助索引的数据结构
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
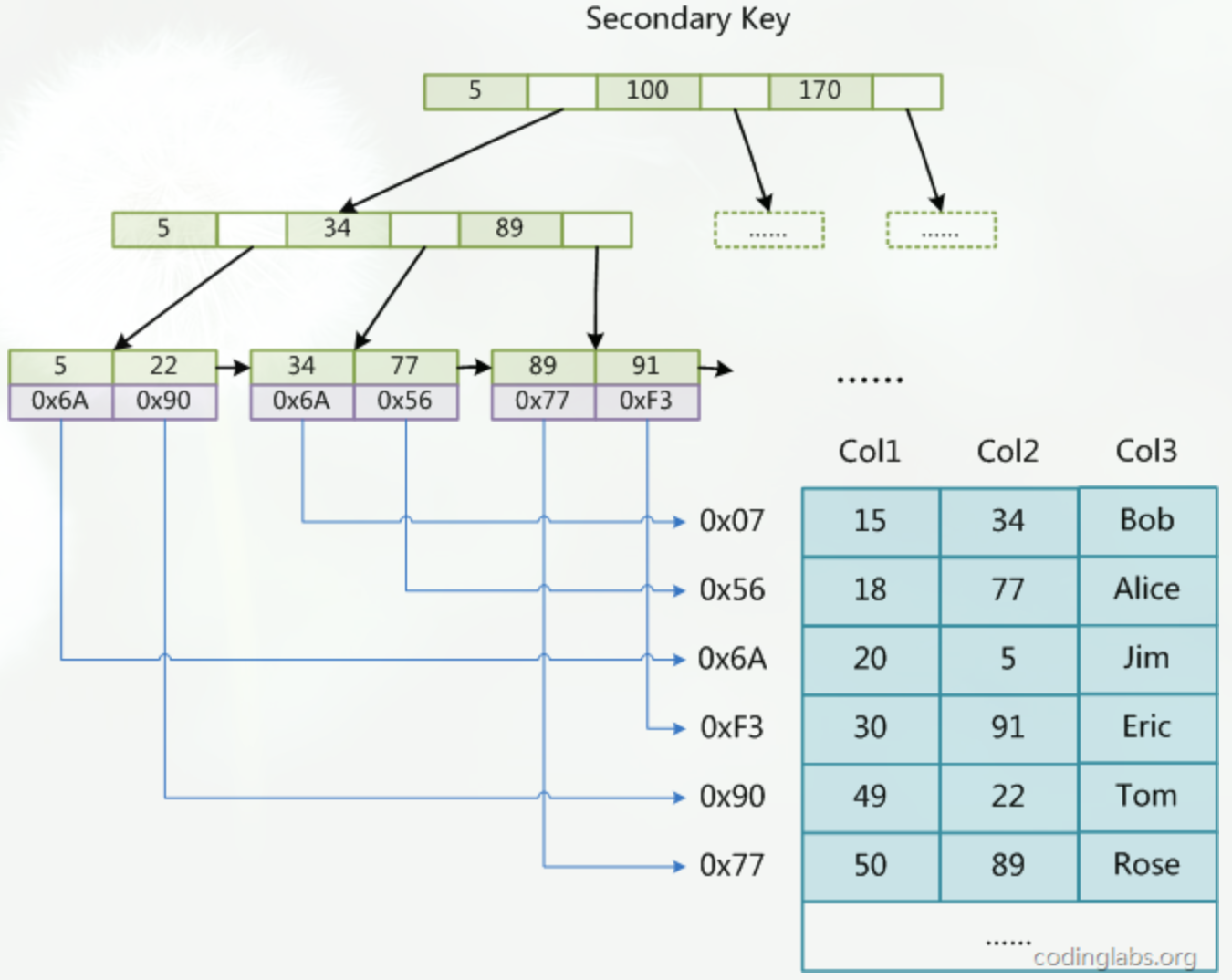
(2)InnoDB存储引擎的索引
相比于MyISAM,InnoDB存储引擎的叶子节点存储数据本身,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引,所以必须有主键,如果没有显示定义,自动为生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。而辅助索引的叶子节点存放了主键值,主键值越大索引就越大,在查询的时候需要先找到主键值在去主索引上去查找数据。
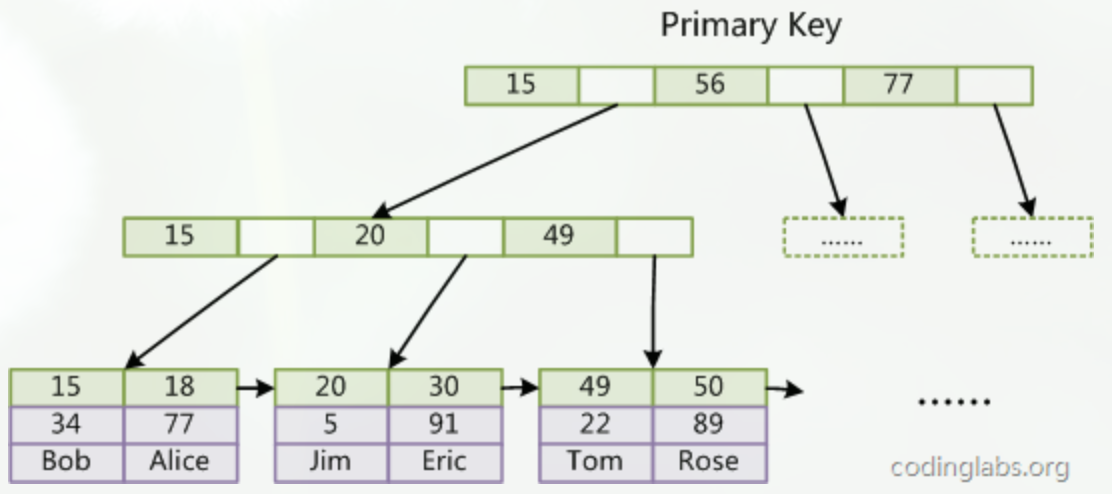
主键索引的结构
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
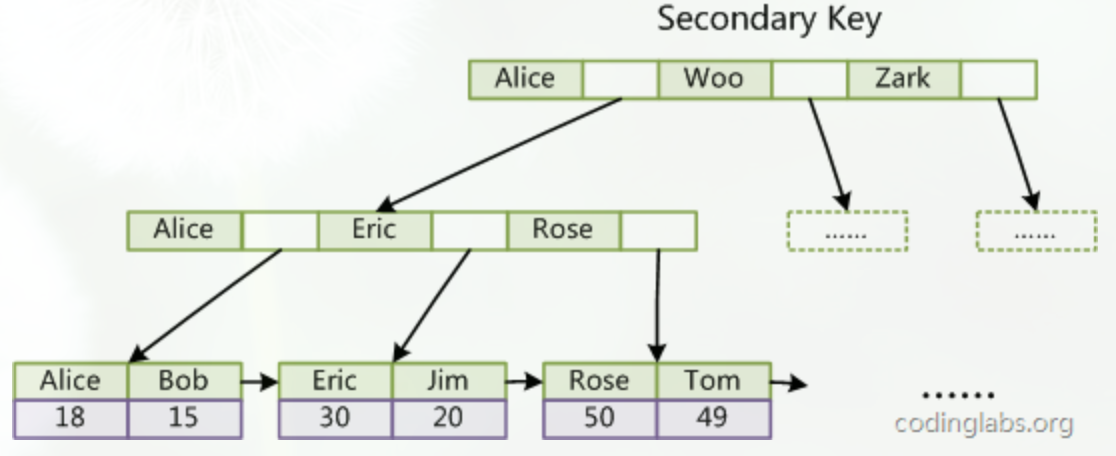
辅助索引的结构
InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
(3)MyISAM和InnoDB关于索引的区别
一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。因此MyISAM辅助索引没有回表操作。
3.2、其他的区别
MyISAM不是事务安全的,而且不支持外键。InnoDB:支持事务安全的引擎,支持外键、行锁、事务是他的最大特点。如果有大量的update和insert,建议使用InnoDB。由于锁的粒度小,写操作是不会锁定全表的,所以特别是针对多个并发和QPS较高的情况。
四、InnoDB的体系结构
(1)Innodb存储引擎主要包括内存池以及后台线程。
- 内存池:多个内存块组成一个内存池,主要维护进程/线程的内部数据、缓存磁盘数据,修改文件前先修改内存、redo log(重做日志)。
- 后台线程:刷新内存池中的数据(插入更新数据)到磁盘中。
- 缓冲池 Innodb的数据以页的形式存储在磁盘,因此采用内存作为缓存页数据。
- 读页数据时,先将磁盘上的页数据“FIX”到缓冲池,下次读即可直接从缓冲池中读。
- 修改数据时,先修改缓冲池中的页数据,然后刷新到磁盘,并不是每次都刷新而是通过Checkpoint机制刷新到磁盘。
- 数据页类型:索引页、数据页、undo页、插入缓冲(insert buffer)、自适应哈希索引、锁信息、数据字典信息等
- 缓存池通过LRU算法管理。
(2)redo log buffer(重做日志缓存)
redo log先都写入该buffer,而后按一定频率刷新到磁盘(1s/次),默认8M。其刷到磁盘主要一下几个情况:
- Master Thread每秒执行一次。
- 事物提交时。
- redo log buffer剩余空间小于1/2。
redo log 日志在数据库意外丢失数据时可以恢复数据。主要备份数据库的物理改变。
binlog日志(二进制日志)功能也可以进行数据恢复(定时全备份+binlog日志恢复增量数据部分),主要备份数据库的逻辑改变。
(3)线程
Master Thread
负责将缓存池中的数据异步刷新到磁盘,包括脏页。合并插入缓存(INSERT BUFFER)、UNDO页的回收等。
IO Thread
Innodb中大量使用AIO处理写请求,IO Thread则主要处理这些请求的回调,包括write、read、insert buffer和log IO Thread。
Purge Thread
主要用来回收undo log(回滚日志),Innodb1.1之前由Master Thread负责。
Page Cleaner Thread
清理已提交事物的UNDO log。
Checkpoint
事务型数据库一般采用Write Ahead Log策略,当事物提交时先写redo log而后修改内存中的页。当数据库宕机对于还未写入磁盘的修改数据可以通过redo log恢复。Checkpoint作用在于保证该点之前的所有修改的页均已刷新到磁盘,这之前的redo log在恢复数据时可以不需要了。
(4)Innodb关键特性
插入缓冲
- 当插入数据需要更新非聚集索引时,如果每次都更新则需要进行多次随机IO,因此将这些值写入缓冲对相同页的进行合并提高IO性能。
- 插入非聚集索引时,先判断该索引页是否在缓冲池中,在则直接插入。否则写入到Insert Buffer对象。
- 条件:二级索引,索引不能是unique(因为如果是unique则必须保证唯一性,此时得检查所有索引页,还是随机IO了)
- Change Buffer:包括Insert Buffer、Delete Buffer、Purge Buffer,update操作包括将记录标记为已删除和真正将记录删除两个过程,对应后两个Buffer。
- Insert Buffer内部是一颗B+树
- Merge Insert Buffer三种情况:
- 对应的索引页被读入缓冲池。
- 对应的索引页的可用空间小于1/32,则强制进行合并。
- Master Thread中的合并插入缓冲。
两次写
在对脏页刷新到磁盘时,如果某一页还没写完就宕机,此时该页数据已经混乱无法通过redo实现恢复。innodb提供了doublewrite机制,其刷新脏页步骤如下:
1. 先将脏页数据复制到doublewrite buffer中(2MB内存)
2. 将doublewrite buffer分两次,每次1MB写入到doublewrite磁盘(2MB)中。
3. 马上同步脏页数据到磁盘。对于数据混乱的页则可以从doublewrite中读取到,该页写到共享表空间。自适应哈希索引
InnoDB存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应(adaptive) 的。自适应哈希索引通过缓冲池的B+树构造而来,因此建立的速度很快。而且不需要将整个表都建哈希索引,InnoDB存储引擎会自动根据访问的频率和模式 来为某些页建立哈希索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号